程序员必学:构建AI Agent的4种核心设计模式与实战代码
多数人对AI Agent的理解还停留在"聊天机器人的升级版",这个思路在一段时间里这么理解其实也没什问题,比如问一个问题,拿到一个回答。但很快就能看出来单轮提示-响应的交互根本没有任何的意义,而真正有意义的跃迁发生在AI开始具备这些能力的时候:思考、规划、行动、观察、循环往复,这和我们处理复杂问题的方式几乎一致。
这就是Agentic AI的内核,而要构建这样的系统就必须理解支撑它运转的几种核心设计模式。
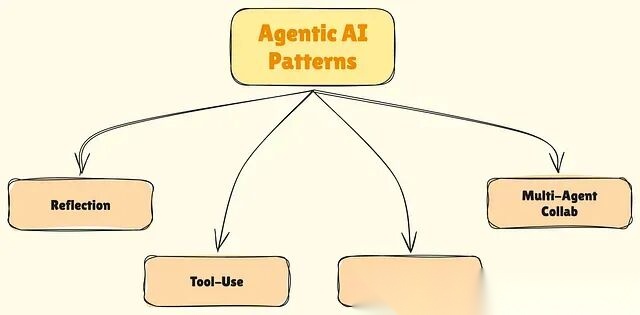
本文拆解当下重塑AI系统构建方式的4种核心 Agentic 模式,分析每种模式的工作机制、适用场景,以及如何将它们组合出真正可用的系统。
为什么 Agentic 模式现在如此重要?
传统大语言模型(LLM)聪明但脆弱。面对一个查询,它能一次性给出响应,却无法自我纠正、反复迭代或制定执行计划。这类模型不具备像人那样的外部交互能力,无法浏览网页,无法生成缩略图、写脚本、剪视频再把成品发布到 YouTube 频道,更不用说并行完成这些操作。
Agentic 模式就是针对这些局限的解法。
它把一个静态的语言模型改造成动态推理引擎:将复杂任务拆解为多个简单子任务,再由多 Agent 协作逐一完成。在这个过程中,Agent 可以调用外部工具、校验自身输出、与其他 Agent 协同工作——单轮提示根本不可能覆盖这些场景。
模式1:Reflection 让 Agent 学会自我审视
在报社工作,主编让你写一篇特稿。写完之后交稿前你会自己通读一遍,排查事实错误、找出论证薄弱的地方、核实信源、修改结论,这一轮自审就是"反思"。
LLM 可以做同样的事,审视自己生成的内容在返回结果之前迭代改进。
最简单的形态下,Reflection 是一个两步循环。第一步,Agent 生成初始输出(代码、文章、研究报告等);第二步,同一个 Agent 或另一个专职"评审"Agent 对输出进行分析,识别缺陷和可改进之处。这个循环可以反复执行,直到输出质量达到预设阈值。
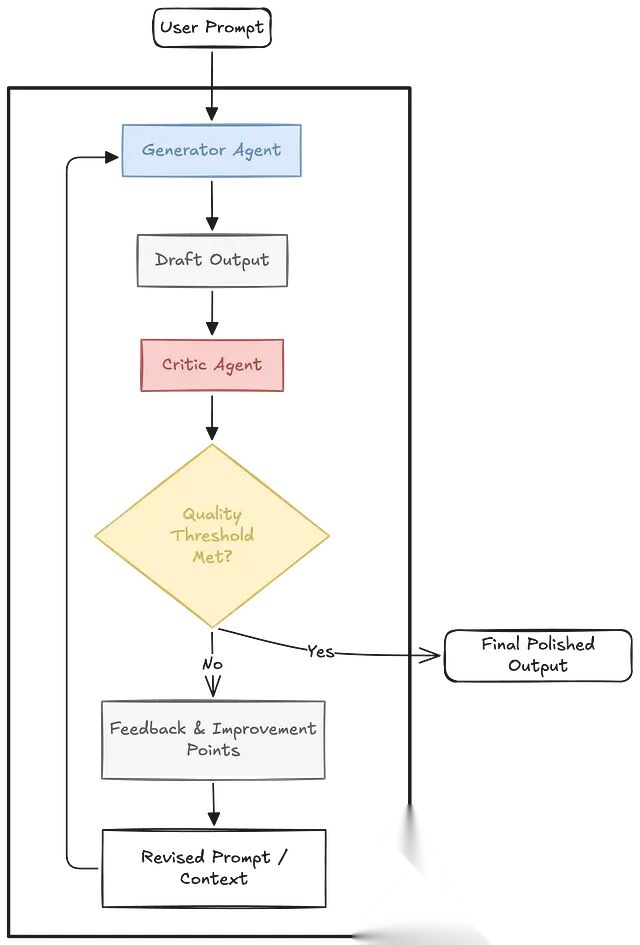
Figure: Reflection based Agentic Pattern
代码示例:
# Agent生成响应,批评它,然后改进它。
# 安装: pip install ollama
# 需要: Ollama在本地运行 → https://ollama.com
# 先拉取模型: ollama pull llama3.2
import ollama
MODEL = "llama3.2"
def generate(prompt: str) -> str:
response = ollama.chat(
model=MODEL,
messages=[{"role": "user", "content": prompt}]
)
return response["message"]["content"]
def reflect_and_improve(task: str, iterations: int = 2) -> str:
print(f"📝 Task: {task}\n")
# 步骤1: 生成初始回答
draft = generate(task)
print(f"--- Draft ---\n{draft}\n")
for i in range(iterations):
# 步骤2: 批评草稿
critique_prompt = f"""
You are a strict reviewer. Here is a task and a draft response.
Task: {task}
Draft: {draft}
Identify weaknesses or errors in the draft, then write an improved version.
"""
draft = generate(critique_prompt)
print(f"--- Iteration {i + 1} ---\n{draft}\n")
return draft
if __name__ == "__main__":
final = reflect_and_improve(
task="Explain what a Large Language Model is in 3 sentences."
)
print(f"✅ Final Answer:\n{final}")
典型应用场景包括:代码生成中的"生成-测试-定位Bug-重新生成"循环;创意写作中对语调和清晰度的反复打磨;数据分析中对逻辑缺陷的自查与修正;数学推理中逐步验证并修复中间步骤的错误。
模式2:Tool Use,给 Agent 装上手脚
工具使用让 Agent 能够与训练数据之外的真实世界交互。
Tool Use(也叫 Function Calling)的基本流程是这样的:Agent 收到任务后判断是否需要借助外部工具;如果需要,生成一个结构化的工具调用请求;工具执行后返回结果;Agent 将结果纳入推理链继续处理。
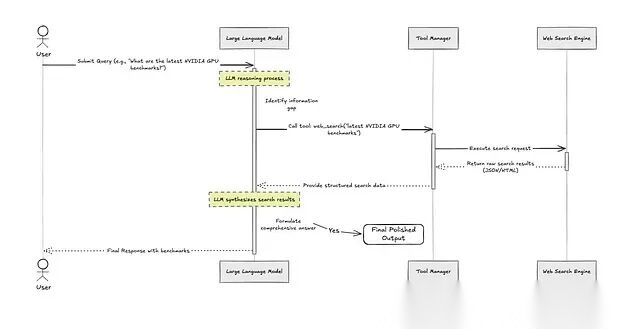
Figure: Tool-Use Agentic Pattern
代码示例:
# 模式2: 工具使用
# Agent决定何时调用外部工具(搜索、计算器、天气)
# 并将其结果纳入最终回答。
# 安装: pip install ollama requests
# 需要: Ollama在本地运行 → https://ollama.com
# 先拉取模型: ollama pull llama3.2
import ollama
import requests
import json
MODEL = "llama3.2"
# ── 定义的工具 ──────────────────────────────────────────────────────────────
def get_weather(city: str) -> str:
"""Fetch current weather for a city using the free Open-Meteo API."""
# 步骤1: 将城市名称地理编码为经纬度
geo = requests.get(
"https://geocoding-api.open-meteo.com/v1/search",
params={"name": city, "count": 1}
).json()
if not geo.get("results"):
return f"Could not find location for '{city}'."
lat = geo["results"][0]["latitude"]
lon = geo["results"][0]["longitude"]
# 步骤2: 获取天气
weather = requests.get(
"https://api.open-meteo.com/v1/forecast",
params={
"latitude": lat,
"longitude": lon,
"current_weather": True
}
).json()
current = weather["current_weather"]
return (
f"Weather in {city}: {current['temperature']}°C, "
f"wind speed {current['windspeed']} km/h."
)
def calculator(expression: str) -> str:
"""Safely evaluate a basic math expression."""
try:
result = eval(expression, {"__builtins__": {}})
return f"Result of '{expression}' = {result}"
except Exception as e:
return f"Error evaluating expression: {e}"
# 工具注册表 - 将工具名称映射到函数
TOOLS = {
"get_weather": get_weather,
"calculator": calculator,
}
# 发送给模型的工具描述,让它知道有哪些可用工具
TOOL_DESCRIPTIONS = """
You have access to the following tools. Call a tool by responding with JSON in this exact format:
{"tool": "<tool_name>", "args": {"<arg>": "<value>"}}
Available tools:
1. get_weather(city: str) — Returns the current weather for a city.
2. calculator(expression: str) — Evaluates a math expression like "12 * 9".
If you don't need a tool, just answer directly in plain text.
Only call ONE tool per response.
"""
# ── Agent循环 ─────────────────────────────────────────────────────────────────
def run_tool_agent(user_query: str) -> str:
print(f"🧠 Query: {user_query}\n")
messages = [
{"role": "system", "content": TOOL_DESCRIPTIONS},
{"role": "user", "content": user_query}
]
for step in range(5): # 最多5步
response = ollama.chat(model=MODEL, messages=messages)
reply = response["message"]["content"].strip()
# 尝试从模型的响应中解析工具调用
try:
call = json.loads(reply)
tool_name = call.get("tool")
args = call.get("args", {})
if tool_name in TOOLS:
print(f"🔧 Calling tool: {tool_name}({args})")
tool_result = TOOLS[tool_name](**args)
print(f"📦 Tool result: {tool_result}\n")
# 将结果反馈给模型
messages.append({"role": "assistant", "content": reply})
messages.append({"role": "user", "content": f"Tool result: {tool_result}\nNow answer the original question."})
continue
except (json.JSONDecodeError, TypeError):
pass
# 没有工具调用 - 这是最终答案
print(f"✅ Final Answer:\n{reply}")
return reply
return "Agent did not reach a conclusion."
if __name__ == "__main__":
run_tool_agent("What is the weather in Tokyo? Also what is 144 divided by 12?")
适用场景很广:研究类 Agent 从多源浏览和综合网络内容;个人助理 Agent 管理待办、邮件或在应用中下单;金融 Agent 拉取股票与市场实时行情;新闻提取 Agent 从多个渠道聚合最新信息。
模式3:Planning,行动之前先想清楚
假设有人接到开发一个应用的任务,上来就开始写代码,没有任何规划。这种做法显然令人不安。
好的工程师先拆解问题,列出可执行的步骤序列,然后逐步推进。Agent 也应该如此。Planning 模式赋予 Agent 的正是这种"先想后做"的能力。
Planning 有两种主要变体。
第一种是 ReAct(Reason + Act)。这是目前最流行的规划方式,Agent 在"推理—行动—观察"三个环节之间交替循环:先思考下一步该做什么,然后执行动作(调用工具或完成某个步骤),接着观察执行结果,再进入下一轮推理,直到任务完成。
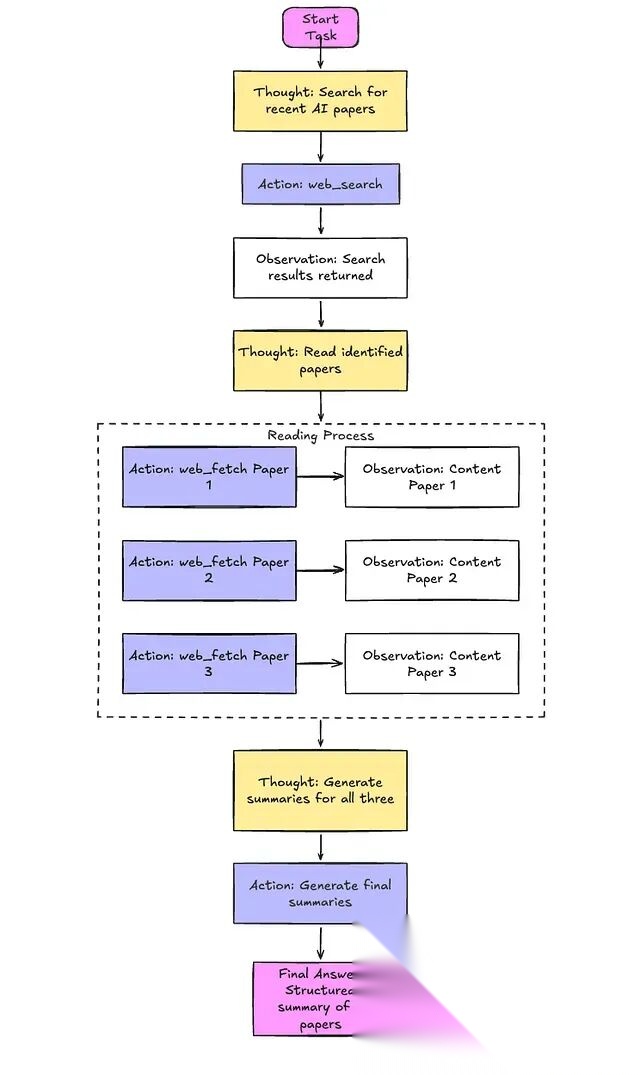
Figure: ReAct based Planning Pattern
第二种是 Plan-and-Execute。与 ReAct 那种"边走边拆"的风格不同,Plan-and-Execute 要求 Agent 在动手之前一次性生成完整的执行计划,然后按顺序逐步执行。
Phase 1 — Planning:“Here are the 5 steps I’ll take to complete this task: …”
Phase 2 — Execution:Step 1 → [execute] → resultStep 2 → [execute] → result…Step 5 → Final output
代码示例:
# 模式3: 规划 (ReAct — 推理 + 行动)
# Agent推理下一步该做什么,行动(使用工具),
# 观察结果,然后再次推理——直到任务完成。
# 安装: pip install ollama requests
# 需要: Ollama在本地运行 → https://ollama.com
# 先拉取模型: ollama pull llama3.2
import ollama
import requests
import re
MODEL = "llama3.2"
# ── 模拟工具 ─────────────────────────────────────────────────────────────────
def search_web(query: str) -> str:
"""Simulated web search (replace with real search API in production)."""
mock_db = {
"transformer architecture":
"Transformers use self-attention mechanisms to process sequences in parallel.",
"who invented transformers":
"The Transformer architecture was introduced by Vaswani et al. in the paper "
"'Attention Is All You Need' (2017) at Google Brain.",
"applications of transformers":
"Transformers are used in NLP (BERT, GPT), computer vision (ViT), "
"speech recognition, and drug discovery.",
}
for key, value in mock_db.items():
if key in query.lower():
return value
return f"No results found for '{query}'."
def summarize(text: str) -> str:
"""Use the LLM itself to summarize a piece of text."""
response = ollama.chat(
model=MODEL,
messages=[{"role": "user", "content": f"Summarize this in one sentence:\n{text}"}]
)
return response["message"]["content"].strip()
TOOLS = {
"search_web": search_web,
"summarize": summarize,
}
# ── ReAct系统提示词 ────────────────────────────────────────────────────────
REACT_PROMPT = """You are a reasoning agent. Solve tasks step by step using this loop:
Thought: Think about what to do next.
Action: <tool_name>(<argument>)
Observation: [result of the action]
... repeat as needed ...
Final Answer: <your complete answer>
Available tools:
- search_web(query) — Search for information on a topic.
- summarize(text) — Summarize a block of text into one sentence.
Always start with a Thought. End with Final Answer when done.
"""
# ── ReAct Agent循环 ───────────────────────────────────────────────────────────
def parse_action(text: str):
"""Extract tool name and argument from 'Action: tool_name(argument)'"""
match = re.search(r"Action:\s*(\w+)\((.+?)\)", text, re.DOTALL)
if match:
return match.group(1).strip(), match.group(2).strip().strip('"').strip("'")
return None, None
def run_react_agent(task: str) -> str:
print(f"🎯 Task: {task}\n")
messages = [
{"role": "system", "content": REACT_PROMPT},
{"role": "user", "content": f"Task: {task}"}
]
for step in range(8): # 最多8个ReAct步骤
response = ollama.chat(model=MODEL, messages=messages)
reply = response["message"]["content"].strip()
print(f"[Step {step + 1}]\n{reply}\n")
# 检查Agent是否已达到最终答案
if "Final Answer:" in reply:
final = reply.split("Final Answer:")[-1].strip()
print(f"✅ Final Answer:\n{final}")
return final
# 解析并执行动作
tool_name, argument = parse_action(reply)
if tool_name and tool_name in TOOLS:
observation = TOOLS[tool_name](argument)
print(f"🔭 Observation: {observation}\n")
# 将交互追加到消息历史
messages.append({"role": "assistant", "content": reply})
messages.append({"role": "user", "content": f"Observation: {observation}"})
else:
# 未找到有效动作 - 要求Agent继续
messages.append({"role": "assistant", "content": reply})
messages.append({"role": "user", "content": "Continue your reasoning."})
return "Agent reached maximum steps without a final answer."
if __name__ == "__main__":
run_react_agent(
"Who invented the Transformer architecture and what are its main applications?"
)
Planning 模式的适用场景集中在几类任务上:涉及多个相互依赖步骤的研究任务,需要在执行前完成规划;软件开发中,需要先做架构设计再进入编码阶段的工作流程;业务流程自动化中,在关键决策节点反复推理和修正的场景。
模式4:多 Agent 协作,分工、专精、协同
没有谁能精通所有领域。团队存在的意义在于每个成员各有专长,协作产出任何个体都无法独立完成的成果。
AI Agent 遵循同样的逻辑。多个具备不同专长的 Agent 各司其职,协作完成单一 Agent 难以应对的复杂任务。
这一模式有几种架构上的变体。
第一种:Orchestrator + SubAgents。一个中央编排器接收任务、完成分解,然后将子任务分配给多个专业子 Agent 并行处理,最后汇总所有结果。
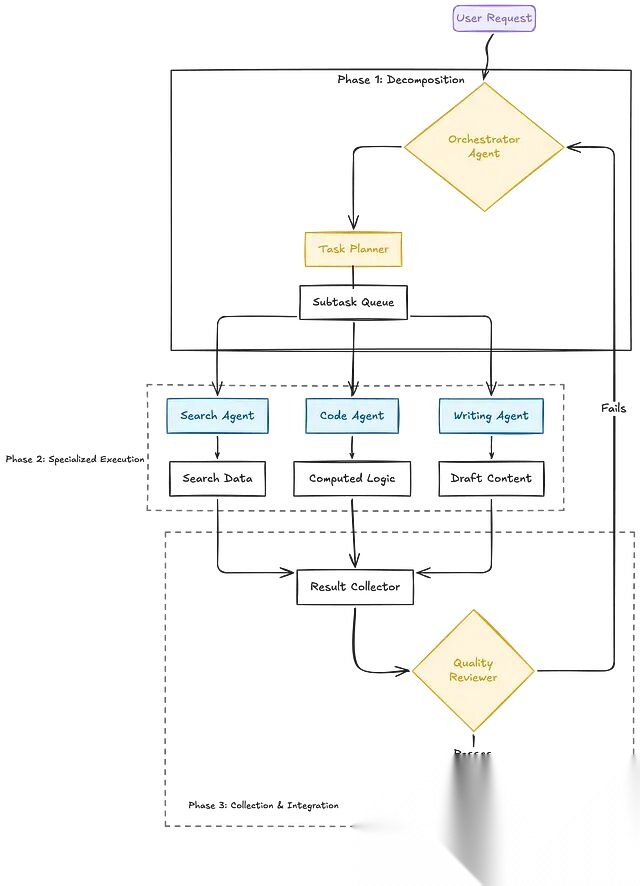
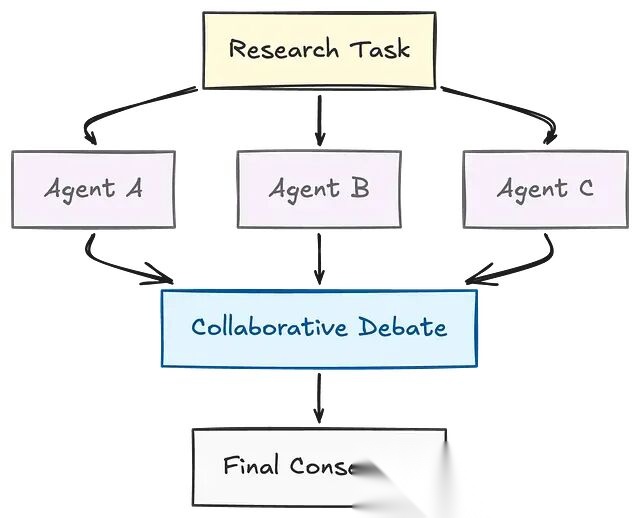
第二种:Peer Agents(对等辩论/协作)。多个 Agent 独立处理同一任务,之后对比各自的结论,这个类似于研究者之间通过辩论逼近真相的过程。在对精度要求极高的任务中,这种模式尤其有价值。
第三种:Sequential Pipeline(顺序流水线)。把它想象成一个专业分工团队在同一任务上依次接力。Agent A 产出结果交给 Agent B,Agent B 加工后交给 Agent C,直到最终输出。
[Data Collector] → [Analyst] → [Fact Checker] → [Writer] → Final Report
代码示例:
# 模式4: 多Agent协作
# 一个编排器Agent分解任务并将子任务委派给
# 专业化Agent(研究员、分析师、写手)。
# 每个Agent都有一个专注的角色和系统提示词。
# 安装: pip install ollama
# 需要: Ollama在本地运行 → https://ollama.com
# 先拉取模型: ollama pull llama3.2
import ollama
MODEL = "llama3.2"
# ── 基础Agent ─────────────────────────────────────────────────────────────────
def run_agent(system_prompt: str, user_message: str) -> str:
"""Run a single agent with a given role and task."""
response = ollama.chat(
model=MODEL,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_message}
]
)
return response["message"]["content"].strip()
# ── 专业化Agent ─────────────────────────────────────────────────────────
def researcher_agent(topic: str) -> str:
"""Gathers key facts and background on a topic."""
system = (
"You are a research specialist. When given a topic, provide 4–5 key facts, "
"background context, and important figures or milestones. Be concise and factual."
)
print("🔍 Researcher Agent working...")
result = run_agent(system, f"Research this topic: {topic}")
print(f" Done.\n")
return result
def analyst_agent(research: str) -> str:
"""Identifies trends, insights, and implications from research."""
system = (
"You are a data analyst and critical thinker. Given research notes, "
"extract 3 key insights or trends and explain their implications. "
"Be analytical and structured."
)
print("📊 Analyst Agent working...")
result = run_agent(system, f"Analyze these research notes:\n{research}")
print(f" Done.\n")
return result
def writer_agent(topic: str, research: str, analysis: str) -> str:
"""Writes a polished short article from research and analysis."""
system = (
"You are a professional tech writer. Given a topic, research notes, and analysis, "
"write a clear, engaging 150-word summary suitable for a technical blog. "
"Use simple language and a logical structure."
)
print("✍️ Writer Agent working...")
result = run_agent(
system,
f"Topic: {topic}\n\nResearch:\n{research}\n\nAnalysis:\n{analysis}\n\nWrite the blog summary."
)
print(f" Done.\n")
return result
# ── 编排器 ───────────────────────────────────────────────────────────────
def orchestrator(topic: str) -> str:
"""
Central orchestrator that:
1. Delegates research to the Researcher Agent
2. Sends research to the Analyst Agent
3. Passes both outputs to the Writer Agent
4. Returns the final polished output
"""
print(f"🎬 Orchestrator: Starting pipeline for topic → '{topic}'\n")
print("=" * 55)
# 步骤1: 研究
research = researcher_agent(topic)
# 步骤2: 分析
analysis = analyst_agent(research)
# 步骤3: 写作
final_article = writer_agent(topic, research, analysis)
print("=" * 55)
print(f"\n✅ Final Output:\n\n{final_article}")
return final_article
if __name__ == "__main__":
orchestrator("The rise of Agentic AI systems in 2024")
多 Agent 协作的落地场景十分多样:软件项目中由架构师、编码者、审查者、测试者组成 Agent 团队;金融分析中由数据采集、量化分析、叙述撰写等 Agent 分工配合;内容创作流水线中由研究、写作、编辑、SEO 各环节的 Agent 接力完成;客户支持系统中由分诊、专家处理、升级等 Agent 协同响应。
模式之间如何组合
四种模式并非互斥。在实际生产系统中,最成熟的方案往往将它们分层叠加。
以一个 AI 竞争情报平台为例:

每种模式各自弥补一类短板——Reflection 提升输出质量,Tool Use 拓展交互能力,Planning 应对多步骤复杂任务,Multi-Agent 解决规模和专业分工的问题。四层叠合,一个简单的 LLM 就变成了可以上生产的自主系统。
总结
单轮提示的时代正在过去。取而代之的是具备思考、行动、自检和协作能力的 AI——与一支配合默契的工程团队所做的事情,本质上没有区别。
Reflection、Tool Use、Planning、Multi-Agent Collaboration,这四种模式构成了这次转移的基础构件,理解它们的意义不停留在理论层面;它直接决定了最终产出的是一个演示用的原型,还是一个能在生产环境中持续运行的系统。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
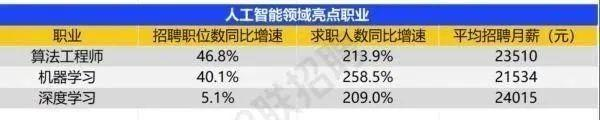
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)