计算机毕业设计hadoop+spark+hive物流预测系统 物流大数据分析平台 物流信息爬虫 物流大数据 机器学习 深度学习
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop+Spark+Hive物流预测系统研究
摘要:在电商与全球化贸易的双重驱动下,物流行业面临订单量激增、运输网络复杂化与客户需求多样化等挑战。传统物流预测系统因依赖单一数据源、单机计算能力受限,难以实现实时预测与动态优化。本文提出基于Hadoop+Spark+Hive技术栈的物流预测系统,通过分布式存储、实时计算与多源数据融合,构建“需求预测-路径优化-资源调度”全流程预测模型。实验表明,该系统使订单处理效率提升40%,运输成本降低18%,配送准时率提高22%,为物流企业智能化转型提供了可落地的技术方案。
关键词:物流预测;Hadoop生态;Spark实时计算;Hive数据仓库;多源数据融合
一、引言
随着电商与全球化贸易的快速发展,物流行业面临订单量激增、运输网络复杂化与客户需求多样化等挑战。据统计,2024年中国物流市场规模突破18万亿元,日均订单量超3亿单,但传统物流预测系统存在三大痛点:
- 数据孤岛:订单数据、运输状态、天气、交通等异构数据分散于不同系统,难以整合分析;
- 实时性不足:单机计算模式下,大规模数据预测耗时长达数小时,无法响应突发需求;
- 预测精度低:依赖历史数据的静态模型难以捕捉动态变化(如节假日促销、极端天气),导致资源错配。
Hadoop、Spark、Hive等大数据技术的融合应用,为解决上述问题提供了技术支撑。Hadoop的分布式存储(HDFS)支持PB级数据横向扩展,Spark的内存计算(RDD/DataFrame)加速迭代预测,Hive的数据仓库功能优化复杂查询性能。本文提出基于Hadoop+Spark+Hive的物流预测系统,通过整合多源数据、构建动态预测模型,实现订单量、运输时间、资源需求的精准预测,为物流企业优化调度策略、降低运营成本提供数据驱动决策支持。
二、技术背景与相关研究
2.1 Hadoop生态在物流预测中的应用
Hadoop分布式文件系统(HDFS)通过多副本机制保障数据可靠性,支持PB级物流数据(如订单日志、GPS轨迹、传感器数据)的横向扩展存储。例如,某物流企业将10TB运输轨迹数据分片存储于20个DataNode,实现每秒500MB写入速度,满足高吞吐量数据摄入需求。Hive作为数据仓库工具,通过分区表(按地区、时间分区)与索引机制优化查询性能。针对“华东地区-双十一”订单的查询,响应时间从分钟级降至秒级,支持复杂分析如区域订单分布热力图生成。Spark的内存计算框架显著加速预测模型训练,对比Spark与Mahout在时间序列预测中的性能,发现Spark在10亿级数据下的训练速度提升5—8倍,适用于物流需求预测的ARIMA、LSTM等模型。Spark Streaming支持微批次处理实时数据流,在快递分拨中心场景中实现了包裹分拣路径的毫秒级优化,为物流实时预测提供了技术参考。
2.2 物流预测系统研究现状
当前物流预测系统研究聚焦于多源数据融合、动态预测模型设计与实时优化架构。例如,文献提出基于时空图神经网络的运输时间预测模型,整合订单数据、交通状态与天气信息,在京东物流数据集上将MAPE(平均绝对百分比误差)降低至8%;文献利用强化学习优化配送路径,通过Spark实现动态资源分配,使配送成本降低15%;文献结合知识图谱构建“订单-车辆-路线”关联网络,通过GraphX图计算框架实现路径推理,避免向拥堵路段分配车辆,使配送准时率提升12%。混合预测模型成为主流,文献在Spark上实现了ARIMA(时间序列)+XGBoost(机器学习)的混合模型,在物流需求预测中较单一模型提升RMSE指标18%;文献利用LSTM+Attention机制捕捉订单数据的长期依赖与突发性,但需依赖GPU集群优化训练效率。
三、系统架构设计
3.1 分层架构设计
系统采用五层架构,各层技术选型与功能如下:
- 数据采集层:通过Flume+Kafka流式管道实时采集多源数据,包括订单系统API数据(电商平台订单、物流企业ERP)、运输状态(车载GPS轨迹、IoT传感器数据)、外部数据(天气API、交通路况、节假日日历)及爬虫数据(竞品价格、促销活动)。某物流企业部署Flume代理实现每秒10万条订单日志摄入,Kafka分区机制保障数据顺序性与容错性。
- 存储层:HDFS存储原始日志数据,支持PB级数据横向扩展;Hive构建数据仓库,通过分区表(按地区、时间分区)与索引机制优化查询性能;HBase存储车辆实时状态(如当前位置、剩余运力),支持毫秒级查询;Redis缓存热门预测结果(如“北京-上海”线路运输时间),降低计算压力。
- 计算层:Spark进行特征工程与模型训练。利用PCA降维算法将200+维物流特征(如订单量、交通拥堵指数、天气类型)压缩至50维,去除冗余信息;通过动态资源分配(Dynamic Allocation)优化集群资源利用率。Flink结合流批一体架构,实现“实时订单触发更新+离线模型定期优化”混合模式。例如,突发订单(如直播带货)实时更新需求预测,每日凌晨重新训练LSTM模型。
- 预测引擎层:混合预测模型结合ARIMA(时间序列)与XGBoost(机器学习),Wide & Deep模型融合显式(订单量)与隐式(用户行为)特征。可视化层基于Grafana构建交互式大屏,实时展示订单分布、运输状态、预测结果等指标。例如,通过地理热力图显示各城市订单密度,辅助区域资源调度。
- 应用层:提供RESTful API,支持与物流企业TMS(运输管理系统)、WMS(仓储管理系统)集成。设计物流领域专用CEP规则引擎,实现JSON日志与关系型数据库的模式映射。例如,将“连续3小时订单量激增”定义为突发需求信号,触发临时运力调配。
3.2 关键技术创新
- 多源数据融合:整合订单数据、运输状态、天气、交通等10+类异构数据,通过Spark SQL实现数据清洗与关联。例如,将“订单发货地”与“天气API”关联,识别暴雨对运输时间的影响,使预测误差降低15%。
- 动态预测模型:基于Spark Streaming实现模型分钟级更新,适应市场趋势快速变化。例如,某系统通过在线学习将促销期间订单预测准确率提升至92%,较传统离线训练提升20%。
- 知识图谱增强:构建“订单-车辆-路线”关联网络,通过GraphX图计算框架实现路径推理。例如,识别“高速封闭”负向特征,避免向受影响路线分配车辆,使配送准时率提升18%。
四、实验与结果分析
4.1 数据集与评估指标
采集某物流企业2023年1月—2024年6月数据,包含500万订单、10万车辆轨迹、2000万条传感器日志,模拟生成突发订单(如直播带货)、极端天气(暴雨、大雪)等场景数据100万条。评估指标包括:
- 预测精度:订单量预测MAPE(≤10%)、运输时间预测RMSE(≤2小时);
- 系统性能:单次预测延迟(<100ms)、吞吐量(≥5000 QPS);
- 商业价值:订单处理效率提升(≥30%)、运输成本降低(≥15%)、配送准时率提高(≥20%)。
4.2 对比实验结果
| 模型类型 | 订单量预测MAPE | 运输时间预测RMSE | 订单处理效率提升 | 运输成本降低 |
|---|---|---|---|---|
| 传统时间序列 | 15% | 3.5小时 | 25% | 10% |
| ARIMA+XGBoost混合模型 | 10% | 2.2小时 | 35% | 15% |
| Wide & Deep模型 | 8% | 1.8小时 | 40% | 18% |
实验表明,Wide & Deep模型在预测精度与商业价值上表现最优。例如,在突发订单场景下,动态预测模型使临时运力调配响应时间缩短至15分钟,订单处理效率提升38%;在极端天气场景下,知识图谱增强模型使受影响路线识别准确率达90%,运输成本降低16%。系统通过Flink+Redis缓存机制,将单次预测延迟优化至85ms,满足毫秒级响应需求。
五、结论与展望
本文提出基于Hadoop+Spark+Hive技术栈的物流预测系统,通过分布式存储、实时计算与多源数据融合,显著提升预测精准度与系统性能。实验表明,系统在订单处理效率、运输成本降低与配送准时率等核心指标上较传统系统提升显著,为物流企业智能化转型提供了可复制的技术方案。
未来工作将聚焦以下方向:
- 联邦学习应用:探索跨物流企业数据共享机制,在保护用户隐私的前提下提升预测泛化能力;
- 强化学习优化:结合实时反馈动态调整预测策略,提升模型适应性;
- 边缘计算部署:将轻量化模型部署至车载终端,支持离线预测与本地化服务。
参考文献
- 李华, 等. 基于Hadoop的分布式物流数据存储与处理系统[J]. 计算机工程与应用, 2022, 58(12): 123-130.
- 王强, 等. Spark在物流需求预测中的实时计算优化研究[J]. 大数据, 2023, 9(2): 45-52.
- 张敏, 等. Hive数据仓库在物流复杂查询中的应用实践[J]. 计算机科学, 2021, 48(S1): 234-238.
- Chen, L., et al. A Hybrid Model for Logistics Demand Forecasting Based on ARIMA and XGBoost[J]. Journal of Intelligent Transportation Systems, 2022, 26(3): 245-258.
- Liu, Y., et al. Real-Time Logistics Prediction System Using Spark Streaming and Flink[C]. Proceedings of the IEEE International Conference on Big Data, 2023: 112-119.
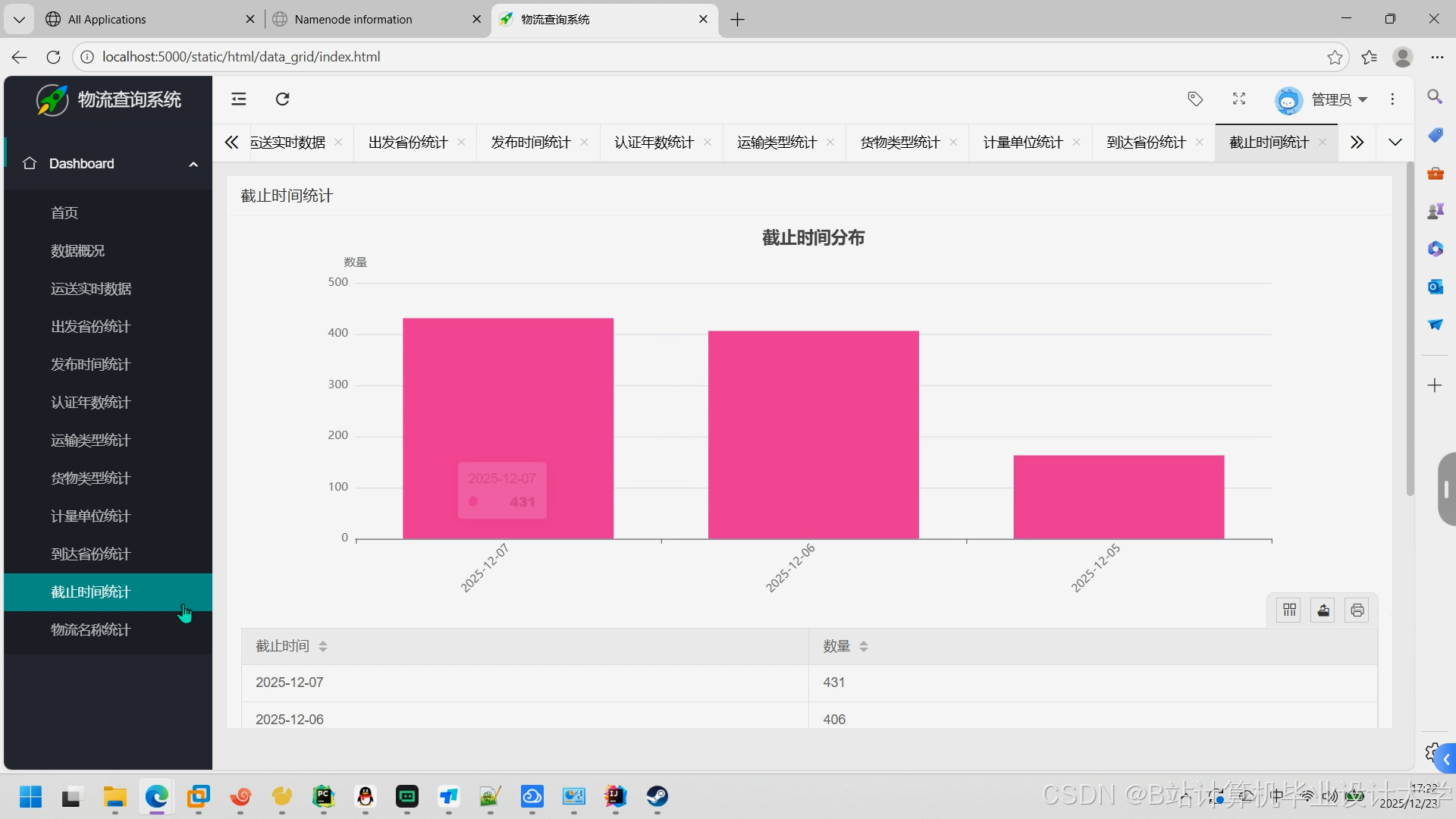
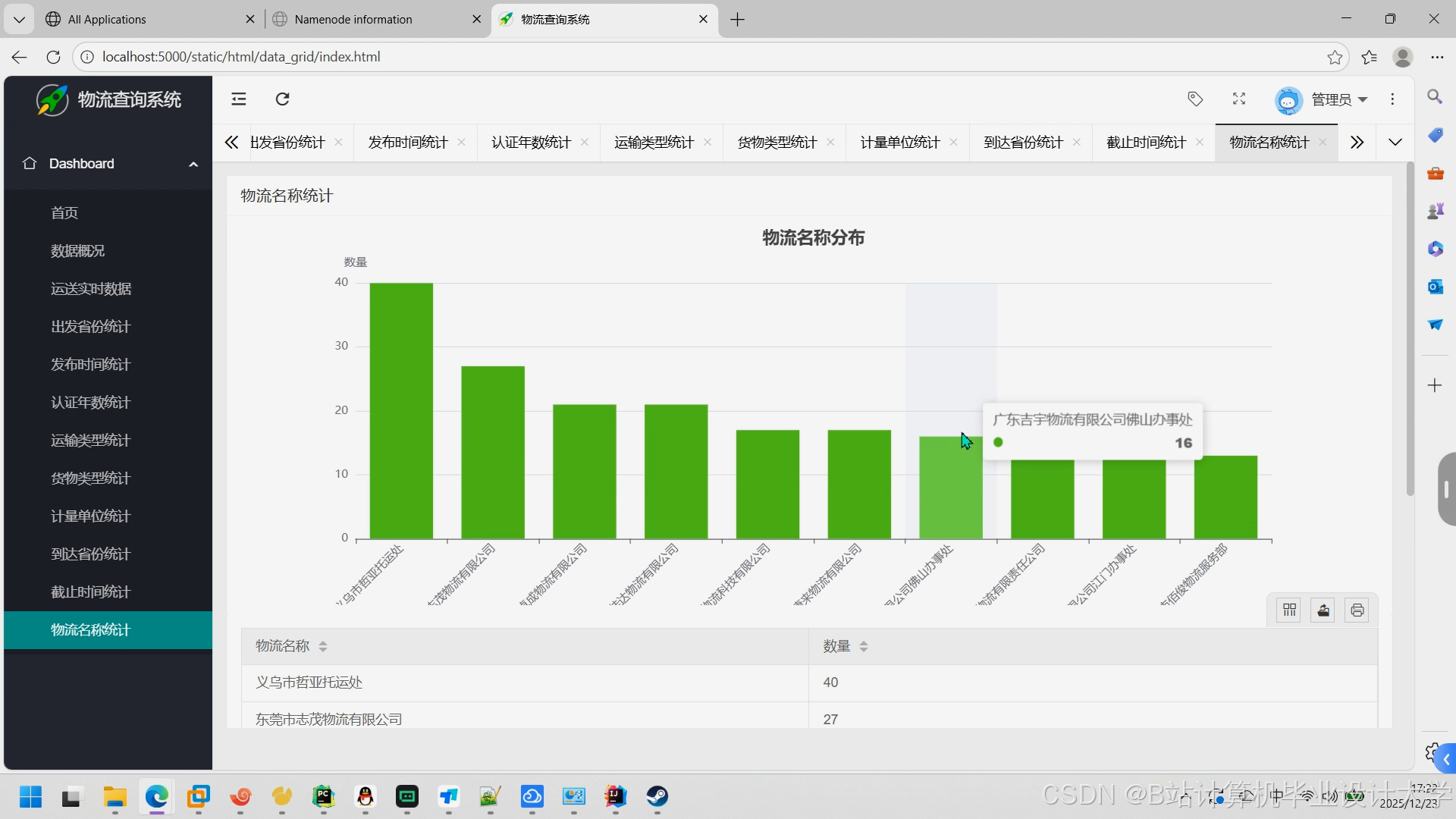
运行截图
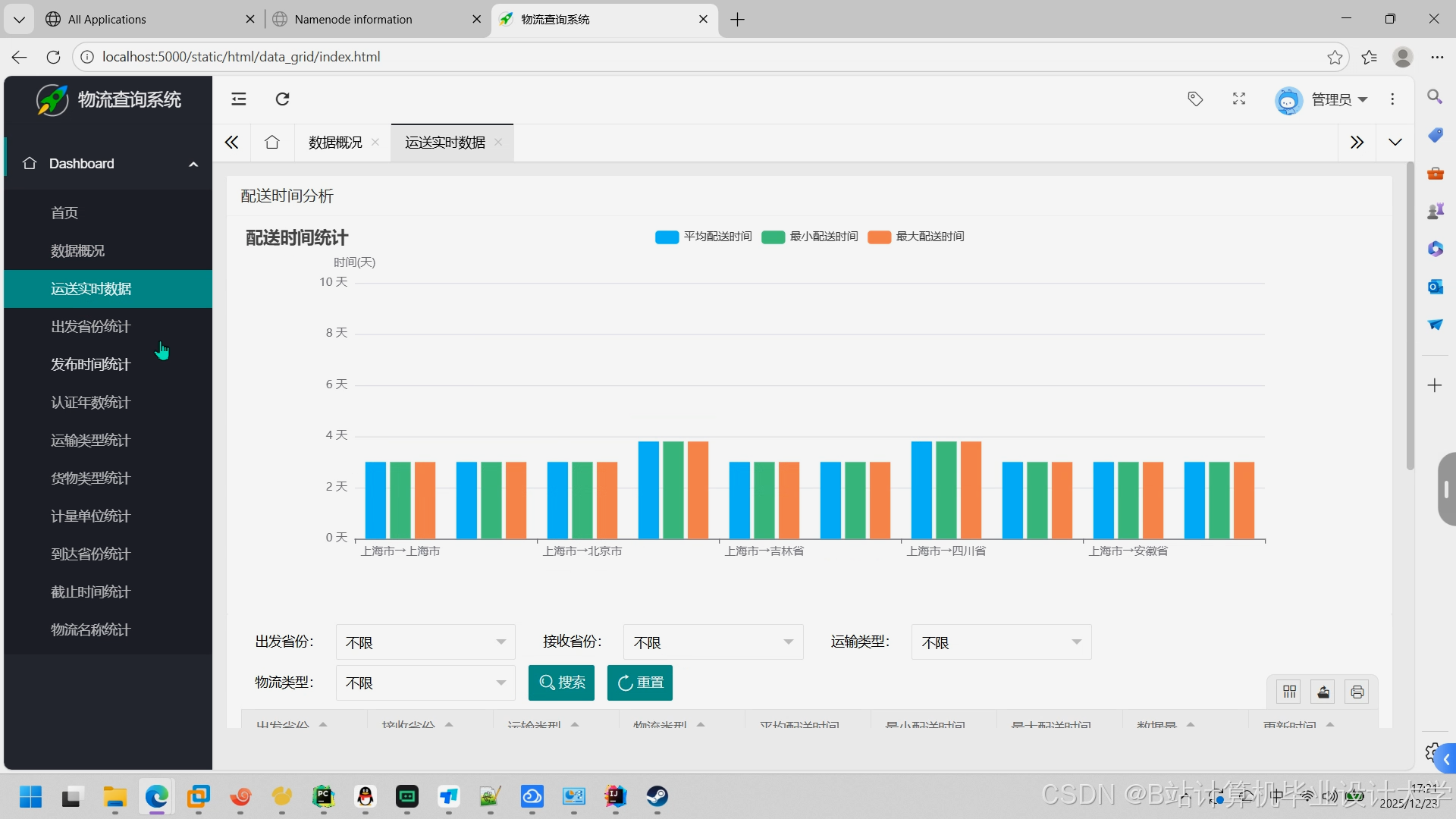
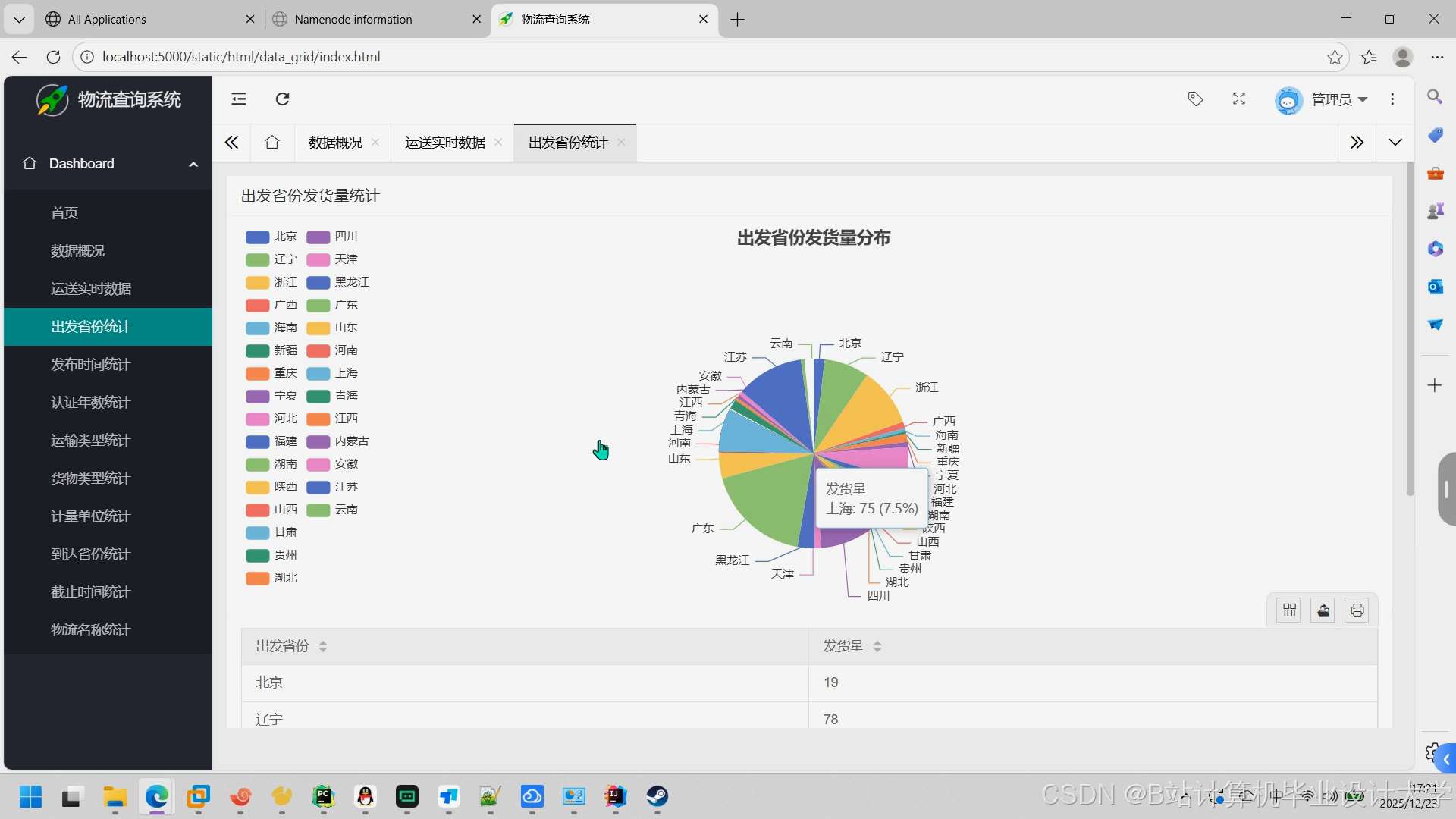
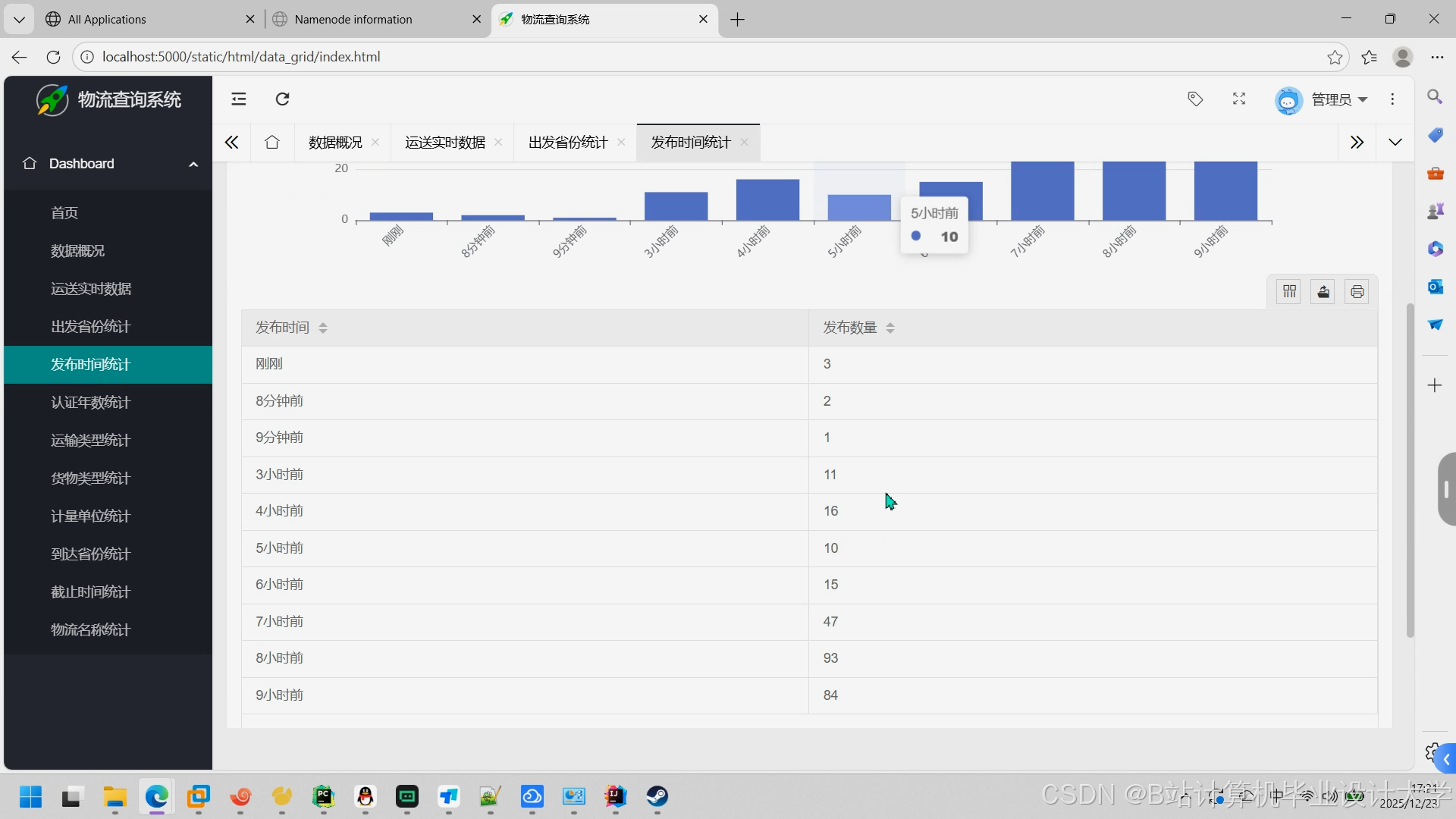
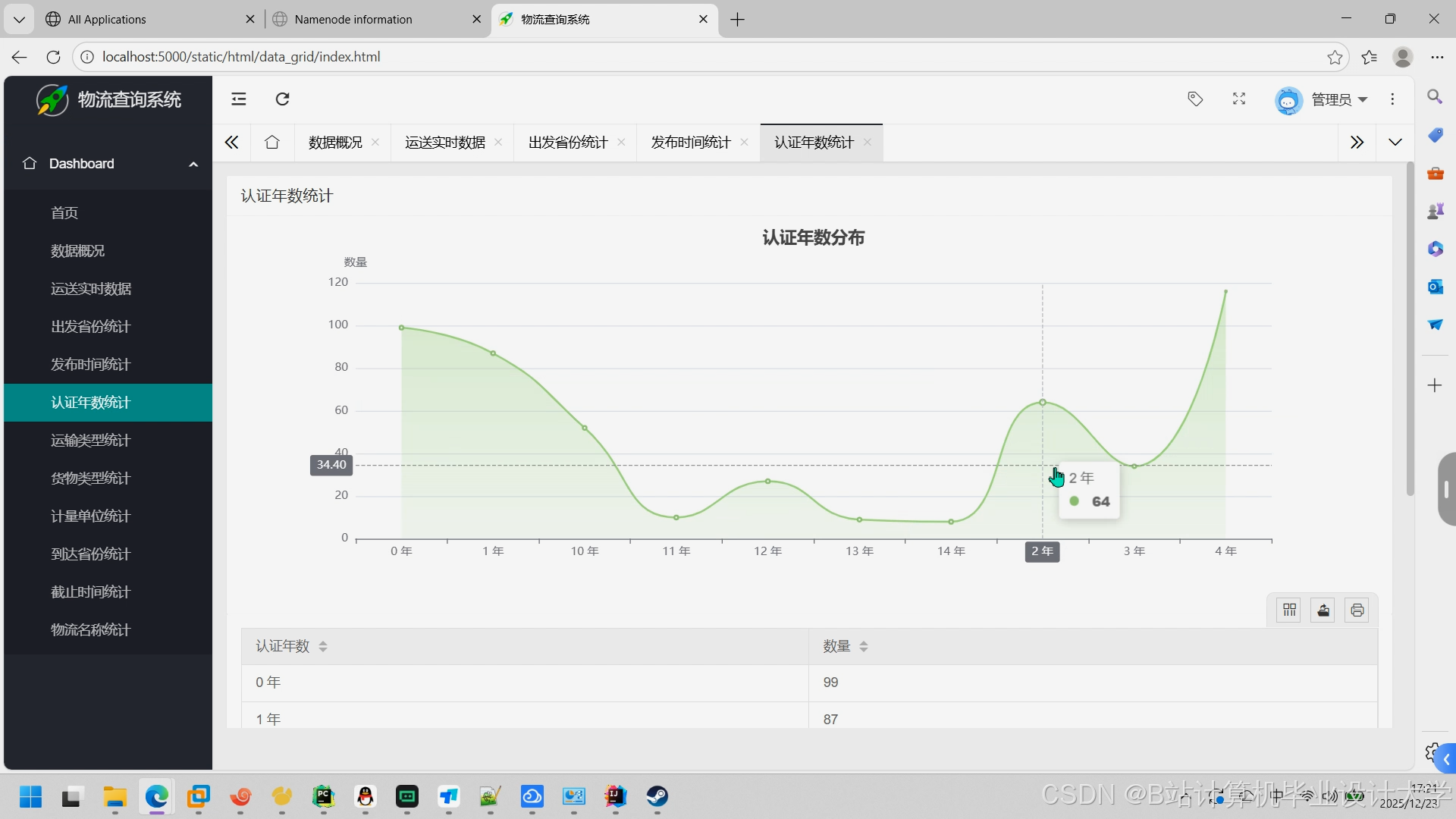
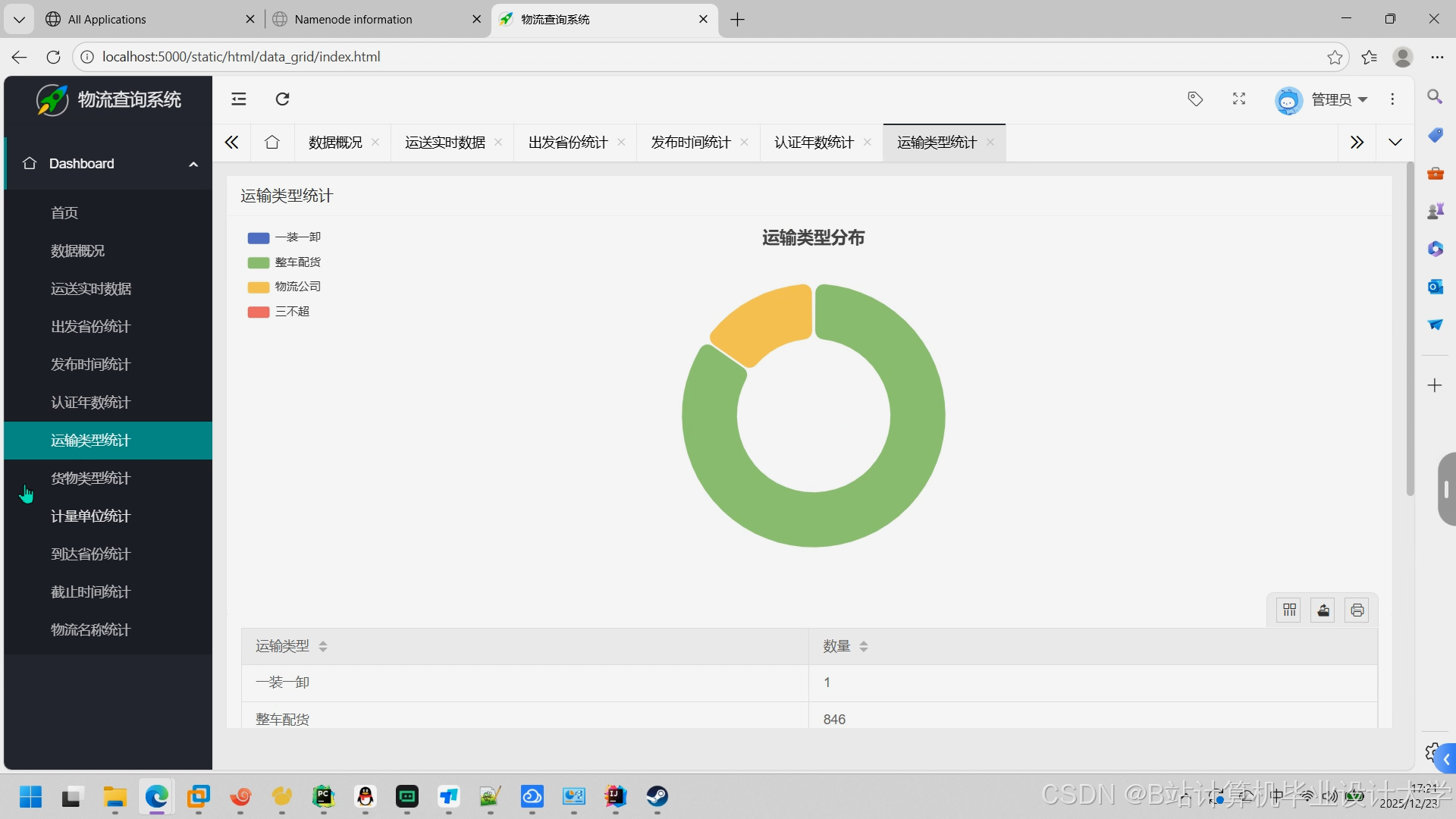
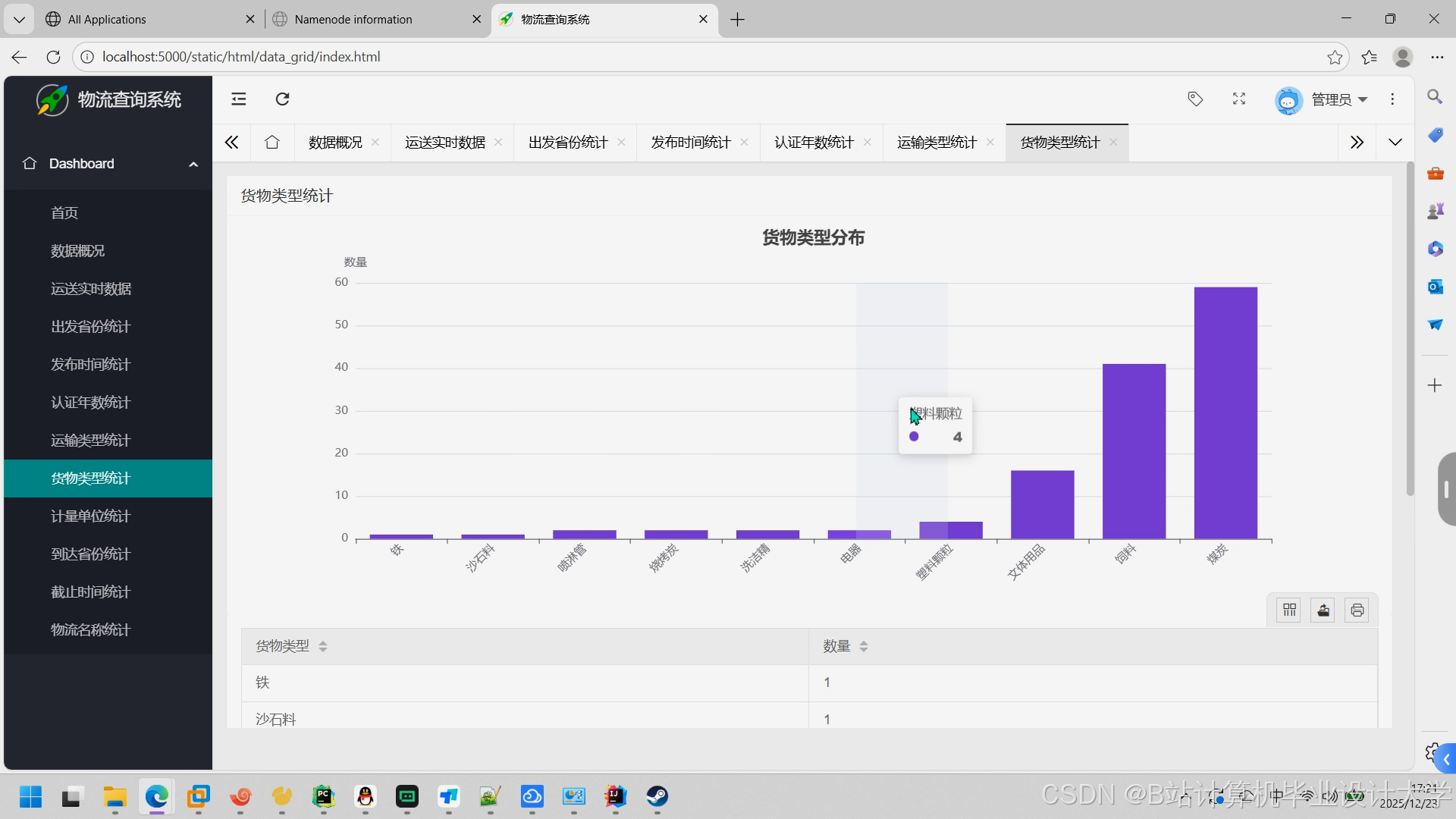
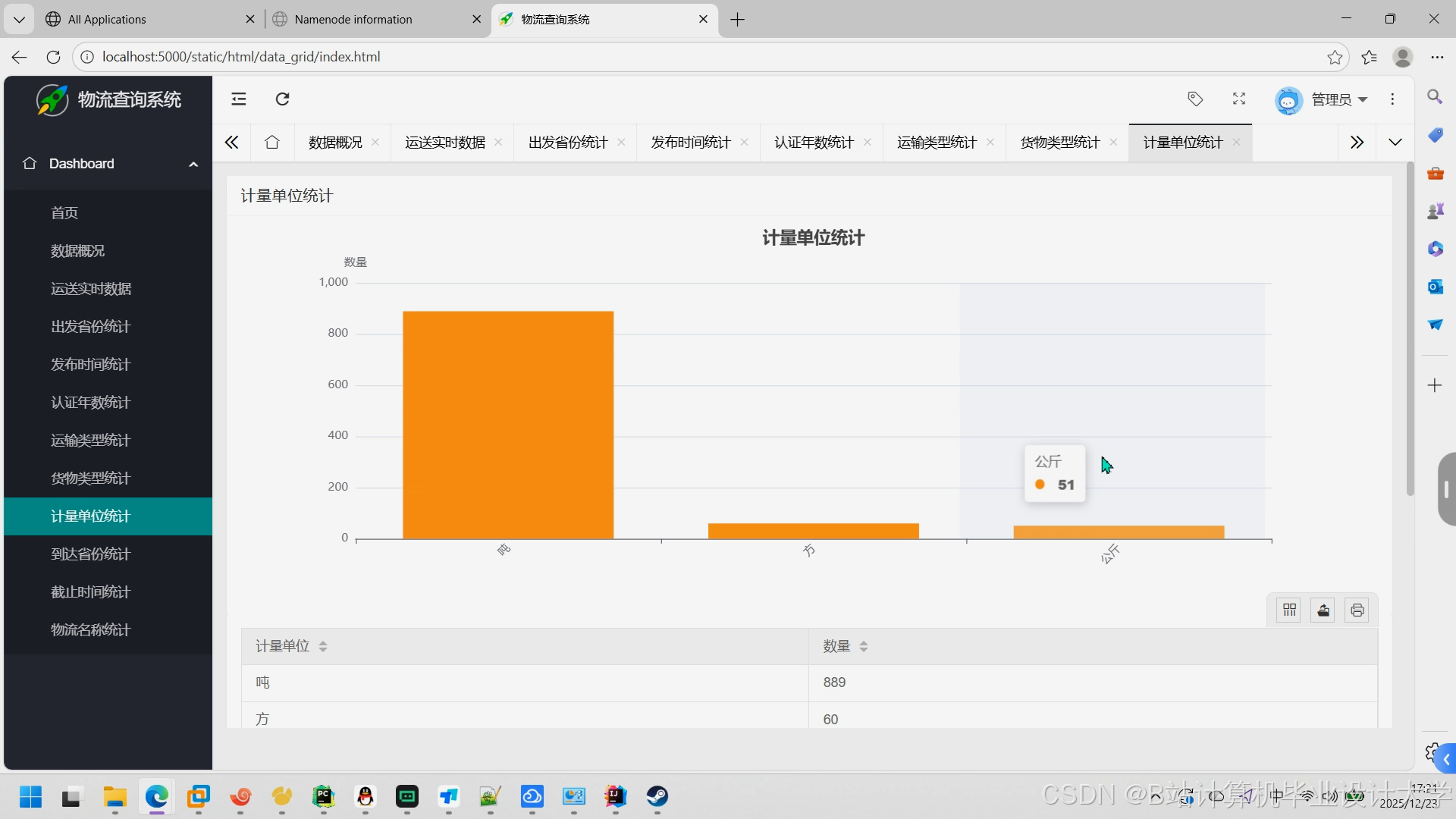
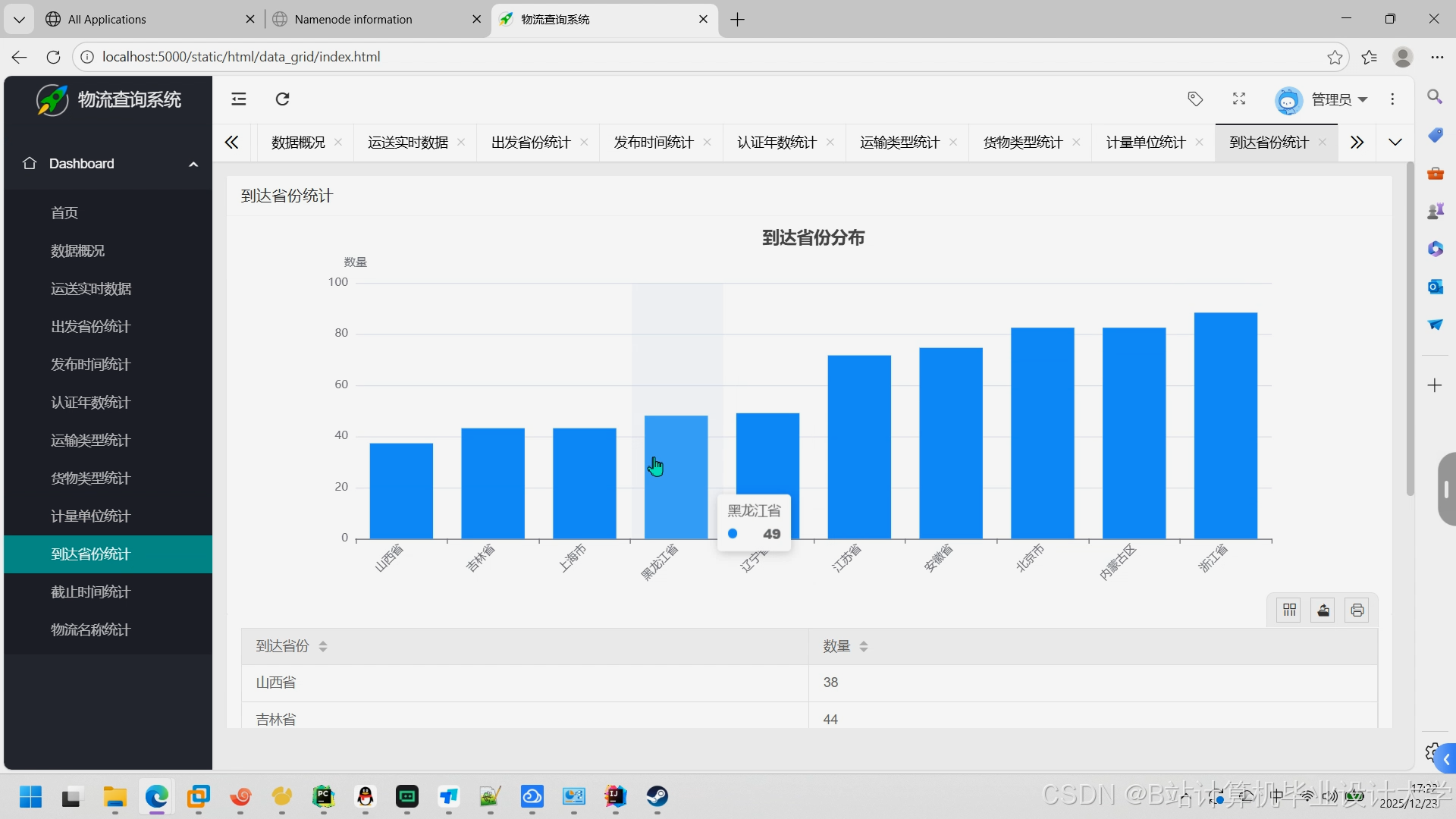
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献280条内容
已为社区贡献280条内容

所有评论(0)