计算机毕业设计hadoop+spark+hive物流预测系统 物流大数据分析平台 物流信息爬虫 物流大数据 机器学习 深度学习
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
任务书:Hadoop+Spark+Hive 物流预测系统
一、项目背景与目标
背景
物流行业面临运输成本高、路径规划低效、需求波动大等挑战。传统预测方法依赖人工经验或简单统计模型,难以应对海量数据(如订单轨迹、天气、交通)的动态变化。基于 Hadoop(分布式存储)、Spark(实时计算) 和 Hive(数据仓库) 的物流预测系统,可整合多源异构数据,通过机器学习模型预测运输时间、货量需求及异常风险,优化资源调度,降低运营成本。
目标
- 运输时间预测:准确预测包裹从起点到终点的送达时间(ETA),误差≤2小时。
- 货量需求预测:提前7天预测区域级货量波动,支持动态调拨车辆与仓储资源。
- 异常风险预警:识别交通拥堵、天气灾害等风险事件,触发备用路径规划。
- 系统性能:支持每日处理10亿级订单数据,单次预测任务延迟≤5分钟。
二、技术架构与工具
1. 整体架构
1数据源 → 数据采集层 → 存储层 → 计算层 → 分析层 → 应用层
2- 数据源:
- 订单数据(起点、终点、重量、时间戳)
- 车辆GPS轨迹(经纬度、速度、方向)
- 外部数据(天气、交通事件、节假日)
- 数据采集层:
- Flume/Kafka:实时采集订单与GPS数据流。
- Sqoop:定期导入历史数据至Hadoop。
- 存储层:
- Hadoop HDFS:存储原始数据(如订单CSV、GPS JSON)。
- Hive:构建数据仓库,定义结构化表(如
fact_orders、dim_vehicle)。
- 计算层:
- Spark Core:分布式数据清洗、特征工程。
- Spark MLlib:训练时间序列预测模型(如LSTM、XGBoost)。
- Spark SQL:聚合分析历史运输模式。
- Spark Streaming:实时处理GPS轨迹,更新车辆位置状态。
- 分析层:
- Hive SQL:统计区域货量趋势、高峰时段。
- GraphX:构建城市道路网络图,计算最短路径。
- 应用层:
- RESTful API:基于Spring Boot提供预测接口(如
/predict/eta)。 - 可视化平台:ECharts展示货量热力图、运输时间分布。
- RESTful API:基于Spring Boot提供预测接口(如
2. 关键工具
| 组件 | 功能 |
|---|---|
| Hadoop | HDFS存储原始数据,YARN资源调度 |
| Hive | 数据仓库建模,支持ETL任务与历史数据分析 |
| Spark | 批处理(特征计算)与流处理(GPS轨迹分析),MLlib实现预测模型 |
| Redis | 缓存高频预测结果(如热门路线ETA),降低延迟 |
| PostgreSQL | 存储模型元数据(如特征重要性、训练参数) |
三、任务分工与进度计划
| 阶段 | 任务内容 | 负责人 | 时间节点 |
|---|---|---|---|
| 需求分析 | 明确预测场景(如ETA、货量)、数据来源及业务指标(如MAPE误差率) | 全体成员 | 第1周 |
| 数据采集 | 接入物流系统订单API、车辆GPS设备,爬取天气/交通数据 | 数据组 | 第2-3周 |
| 数据存储 | 搭建Hadoop集群,设计Hive表结构(如订单事实表、车辆维度表) | 存储组 | 第4周 |
| 数据预处理 | 使用Spark清洗数据(去噪、缺失值填充)、特征工程(如提取时间特征、距离特征) | 算法组 | 第5周 |
| 模型开发 | 实现LSTM时间序列模型与XGBoost回归模型,使用Spark MLlib训练与调优 | 算法组 | 第6-7周 |
| 实时预测 | 基于Spark Streaming处理GPS轨迹,动态更新车辆位置并触发ETA重计算 | 开发组 | 第8周 |
| 系统集成 | 开发API服务,集成Redis缓存,部署预测结果到可视化平台 | 开发组 | 第9周 |
| 测试优化 | 对比模型MAPE误差率,优化特征组合与超参数,测试系统高并发(≥500 QPS) | 测试组 | 第10周 |
| 项目验收 | 提交代码、文档及演示系统,准备答辩材料 | 全体成员 | 第11周 |
四、核心功能实现
1. 数据预处理(Spark)
python
1# 示例:订单数据清洗与特征提取
2from pyspark.sql import SparkSession
3from pyspark.sql.functions import col, unix_timestamp, from_unixtime
4
5spark = SparkSession.builder.appName("DataPreprocessing").getOrCreate()
6
7# 读取原始订单数据
8orders = spark.read.csv("hdfs://namenode:8020/raw_orders", header=True)
9
10# 转换时间戳并提取小时特征
11orders_cleaned = orders.withColumn("order_time", unix_timestamp(col("order_time"), "yyyy-MM-dd HH:mm:ss")) \
12 .withColumn("hour_of_day", (col("order_time") % 86400 / 3600).cast("int")) \
13 .na.fill({"weight": 0, "distance": 0}) # 填充缺失值
14
15# 存储到Hive表
16orders_cleaned.write.saveAsTable("hive_db.cleaned_orders")
172. 预测模型(Spark MLlib)
python
1# 示例:XGBoost回归模型训练(ETA预测)
2from pyspark.ml.feature import VectorAssembler
3from pyspark.ml.regression import XGBoostRegressor
4from pyspark.ml import Pipeline
5
6# 加载特征数据(距离、重量、小时、天气)
7features = spark.table("hive_db.order_features")
8
9# 组装特征向量
10assembler = VectorAssembler(inputCols=["distance", "weight", "hour_of_day", "rainfall"], outputCol="features")
11
12# 定义XGBoost模型
13xgb = XGBoostRegressor(featuresCol="features", labelCol="actual_eta", maxDepth=6, stepSize=0.1)
14
15# 构建Pipeline并训练
16pipeline = Pipeline(stages=[assembler, xgb])
17model = pipeline.fit(features)
18
19# 保存模型到HDFS
20model.write().overwrite().save("hdfs://namenode:8020/models/xgb_eta_model")
213. 实时预测(Spark Streaming)
scala
1// 示例:处理车辆GPS数据并触发ETA更新
2val ssc = new StreamingContext(sparkConf, Seconds(10))
3val gpsStream = ssc.socketTextStream("kafka-broker", 9092) // 从Kafka消费GPS数据
4
5gpsStream.map { record =>
6 val fields = record.split(",")
7 (fields(0), fields(1).toDouble, fields(2).toDouble) // (vehicle_id, latitude, longitude)
8}.foreachRDD { rdd =>
9 rdd.foreachPartition { partition =>
10 partition.foreach { case (vehicle_id, lat, lon) =>
11 // 调用Hive查询车辆当前订单信息
12 val orderInfo = spark.sql(s"""
13 SELECT order_id, destination_lat, destination_lon
14 FROM hive_db.active_orders
15 WHERE vehicle_id = $vehicle_id
16 """).collect()
17
18 // 计算剩余距离并触发ETA预测
19 if (!orderInfo.isEmpty) {
20 val remainingDistance = calculateDistance(lat, lon, orderInfo(0).getDouble(1), orderInfo(0).getDouble(2))
21 updateETA(orderInfo(0).getString(0), remainingDistance) // 伪代码
22 }
23 }
24 }
25}
26ssc.start()
27ssc.awaitTermination()
28五、预期成果
- 预测系统:
- ETA预测误差率(MAPE)≤15%,货量预测R²≥0.85。
- 支持实时更新预测结果(GPS数据延迟≤30秒)。
- 数据平台:
- Hive数据仓库包含订单、车辆、天气等核心表,支持SQL查询。
- Spark集群每日处理10亿级数据,单任务CPU利用率≤70%。
- 技术文档:
- 完整代码库(GitHub)、模型评估报告、部署脚本(Ansible)。
六、风险评估与应对
| 风险类型 | 应对措施 |
|---|---|
| 数据延迟 | 在Spark Streaming中设置backpressure,动态调整批次大小 |
| 模型过拟合 | 在XGBoost中启用early_stopping,交叉验证选择最佳树深度 |
| 集群故障 | 部署Hadoop HA(高可用),Spark Executor配置--supervise自动重启 |
| 特征漂移 | 每周重新训练模型,监控特征重要性变化(如天气影响减弱) |
七、附录
- 参考文献:
- 《Spark机器学习:核心技术与实战》
- 《物流大数据分析与挖掘》(李建林著)
- Apache Hive官方文档
- 术语表:
- MAPE(平均绝对百分比误差)、R²(决定系数)、ETA(预计到达时间)
项目负责人:XXX
日期:XXXX年XX月XX日
备注:本任务书需根据实际物流场景调整特征工程(如加入节假日标志、司机经验值)及模型类型(如集成Prophet时间序列模型),并定期与业务方同步预测效果与资源优化建议。
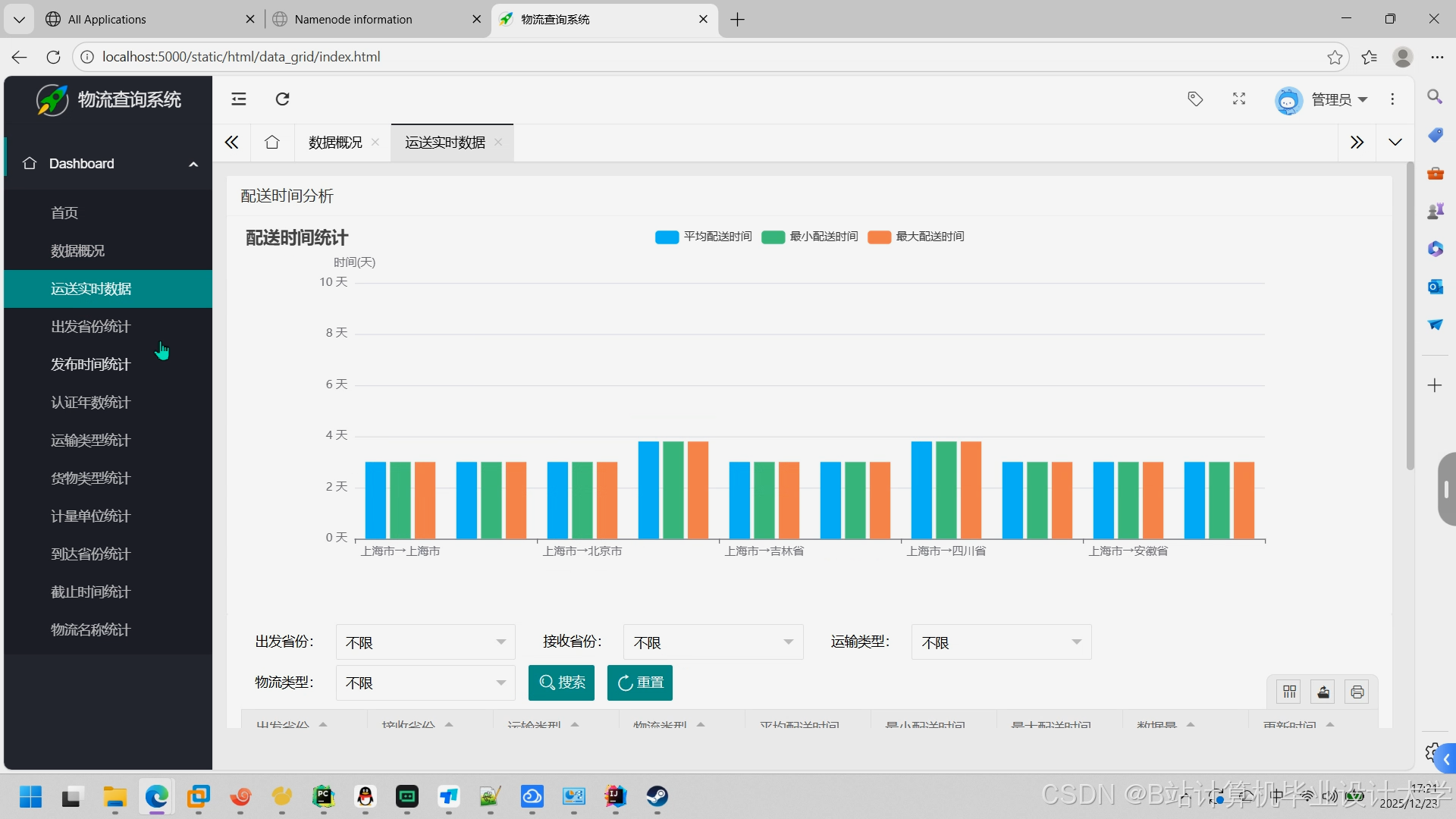
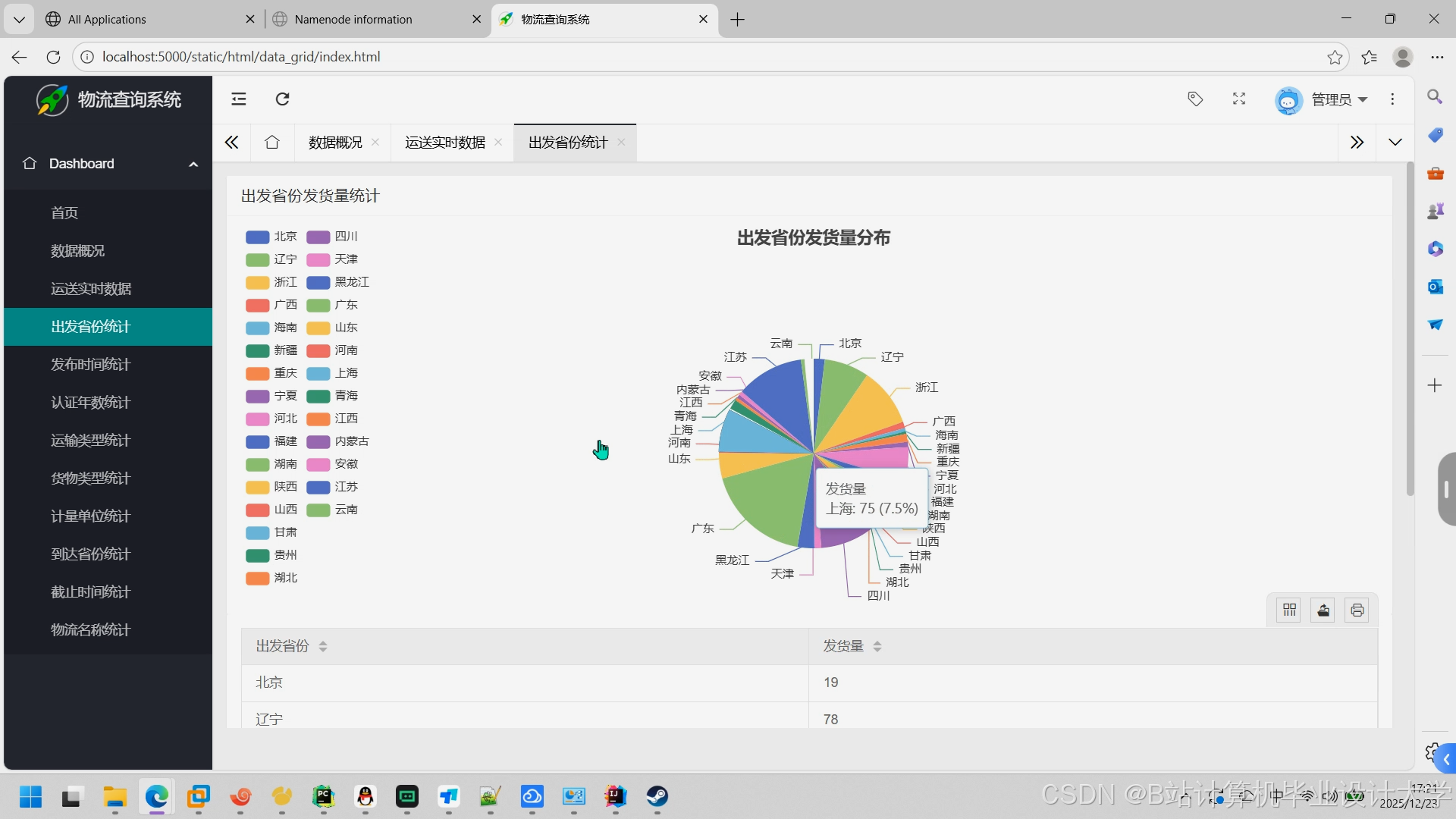
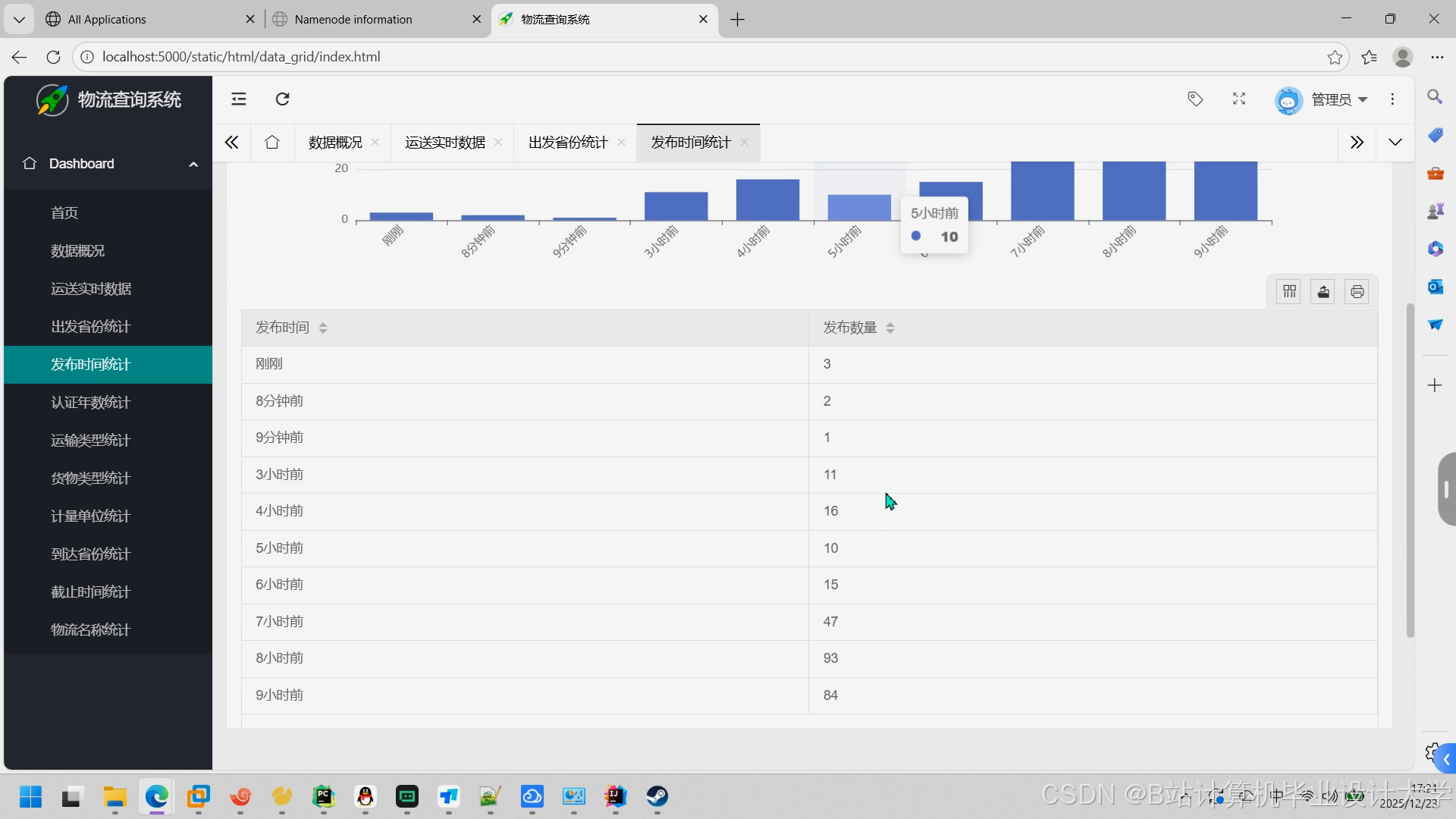
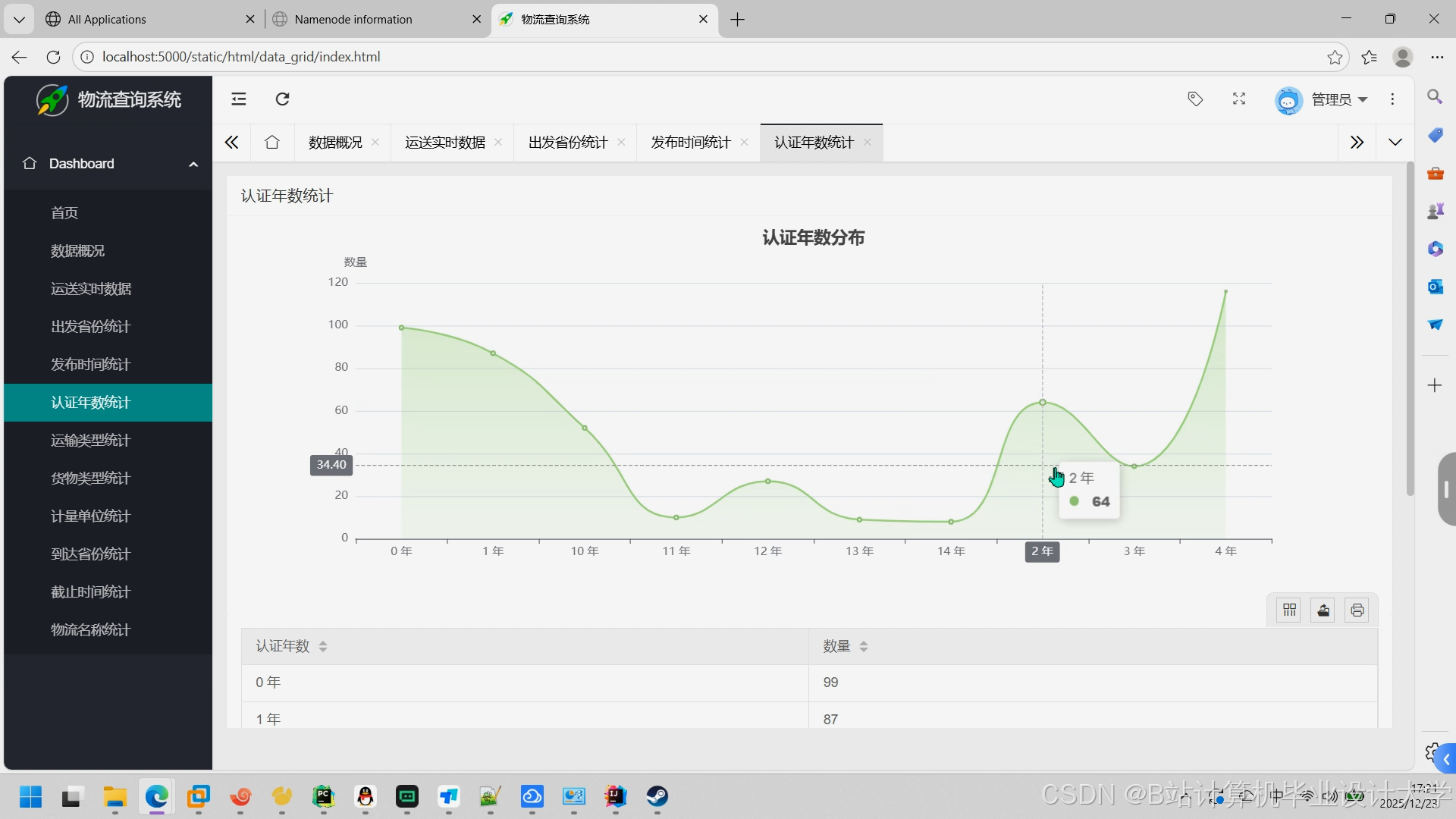
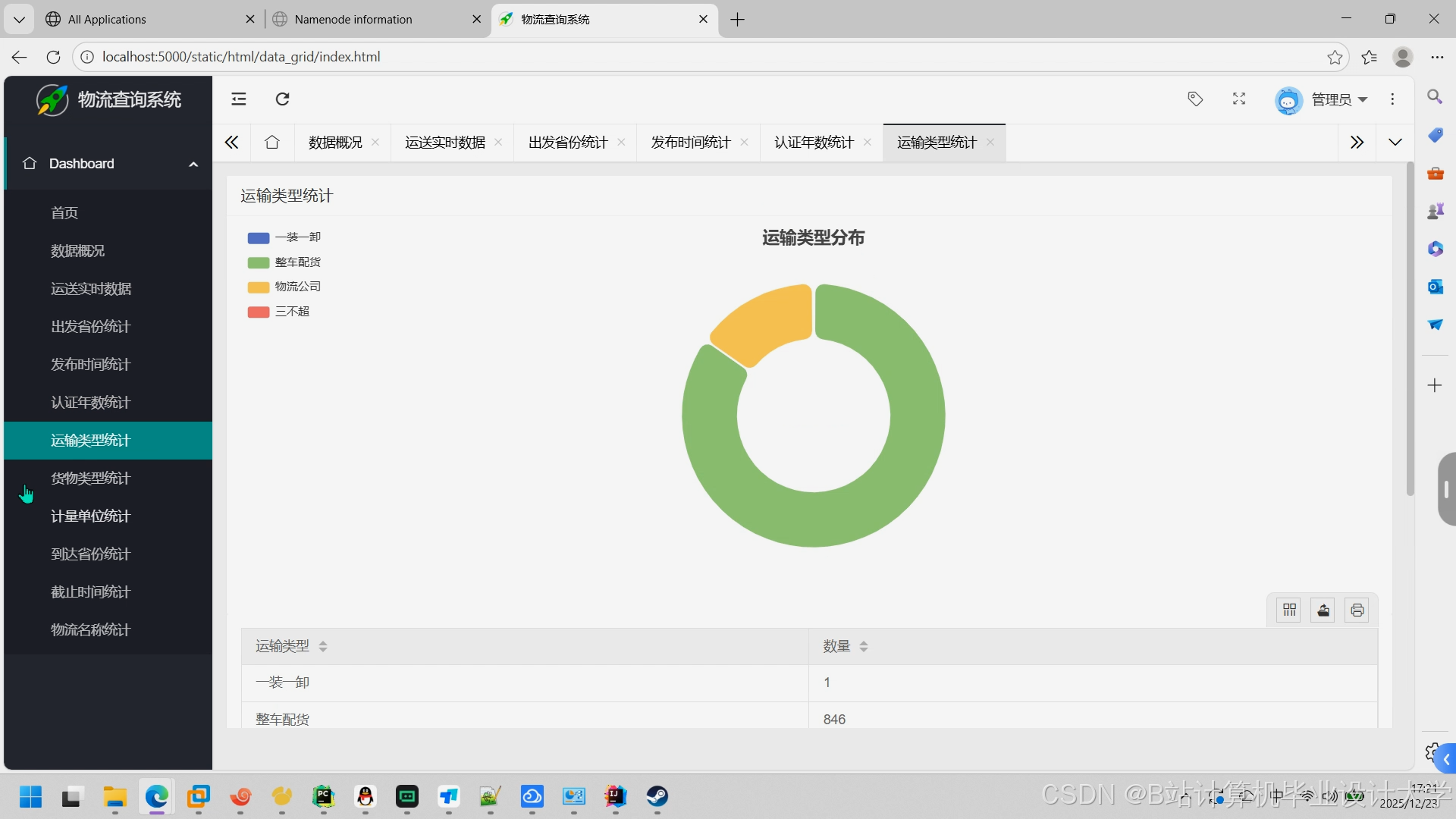
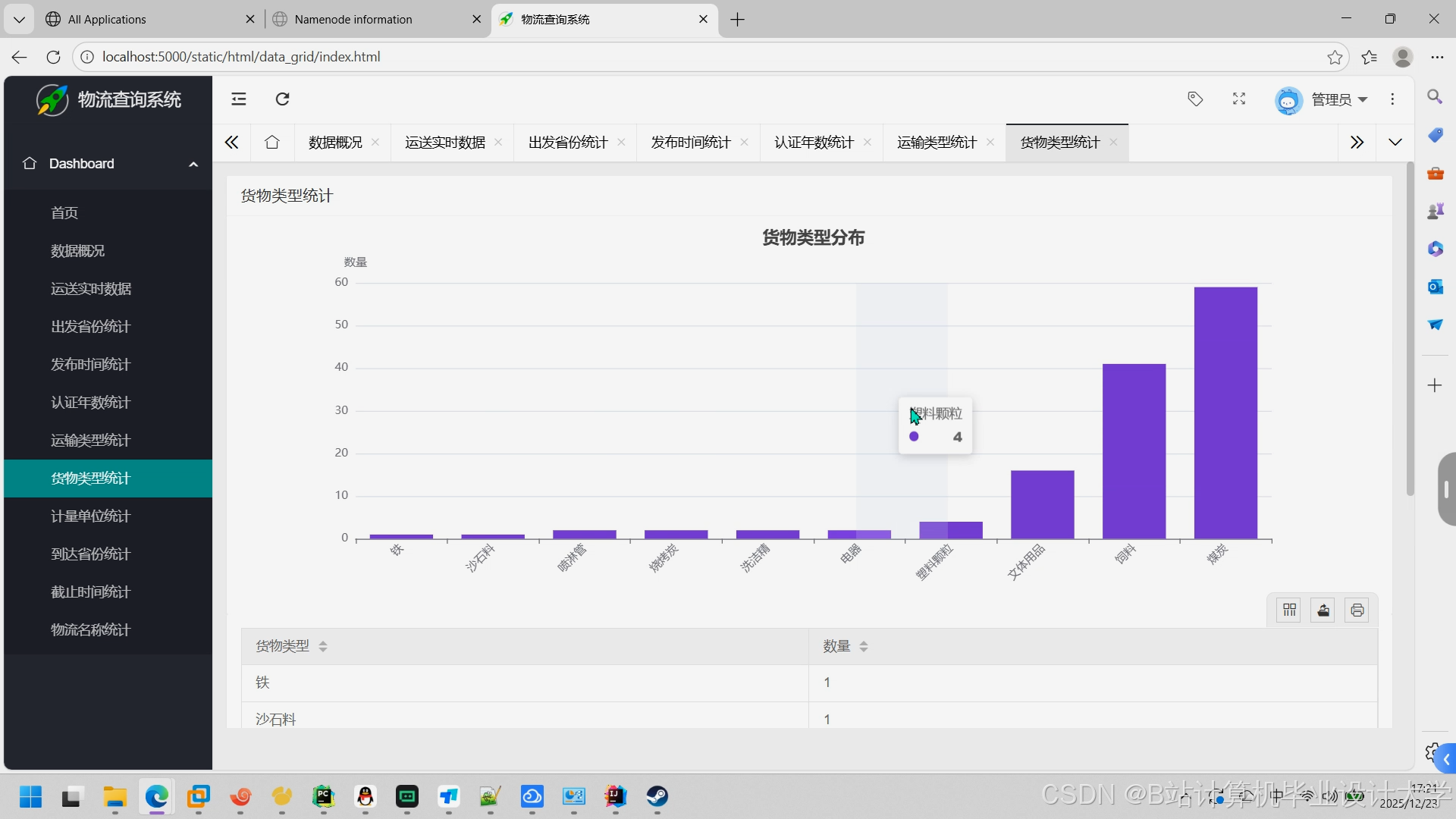
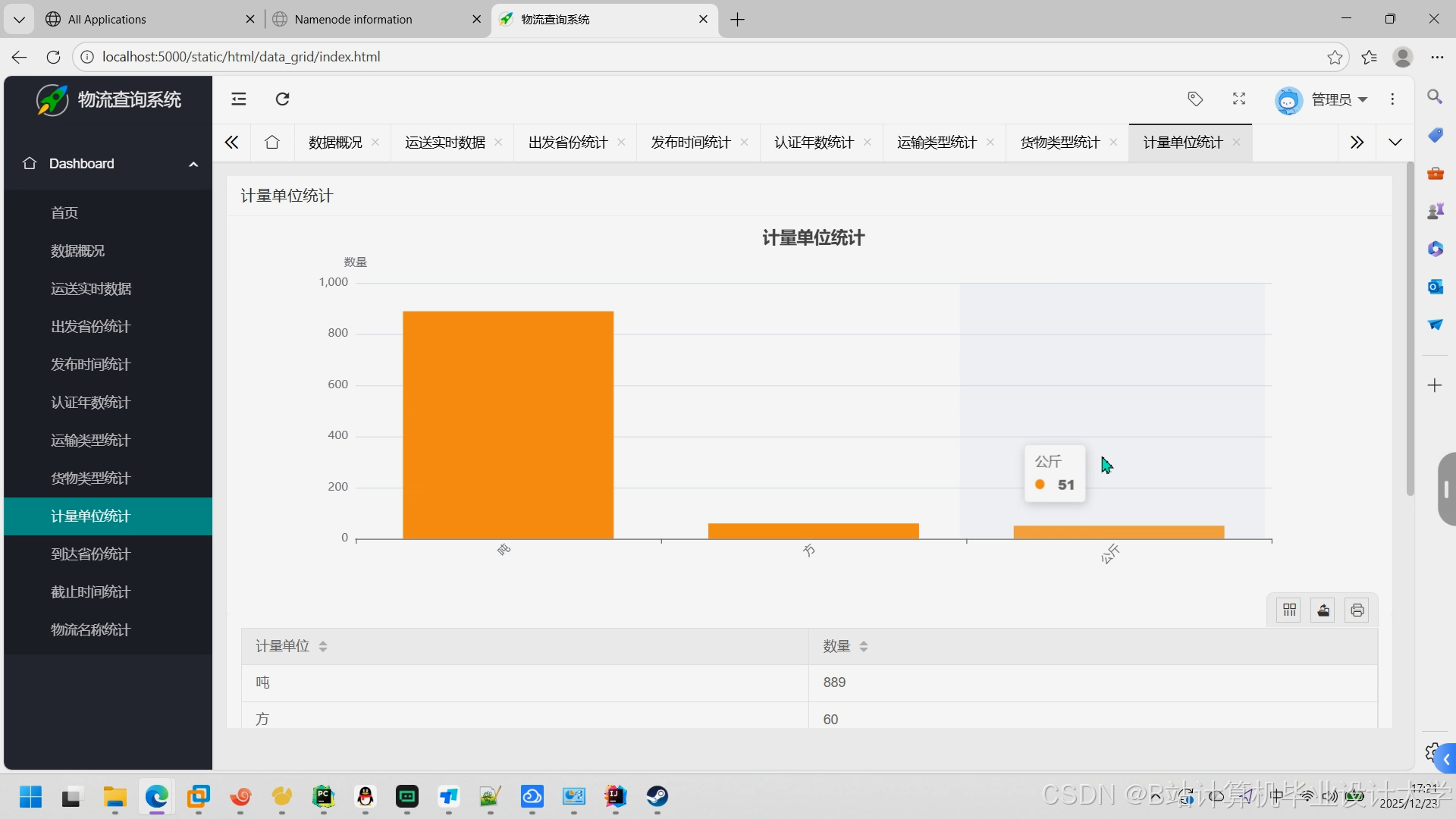
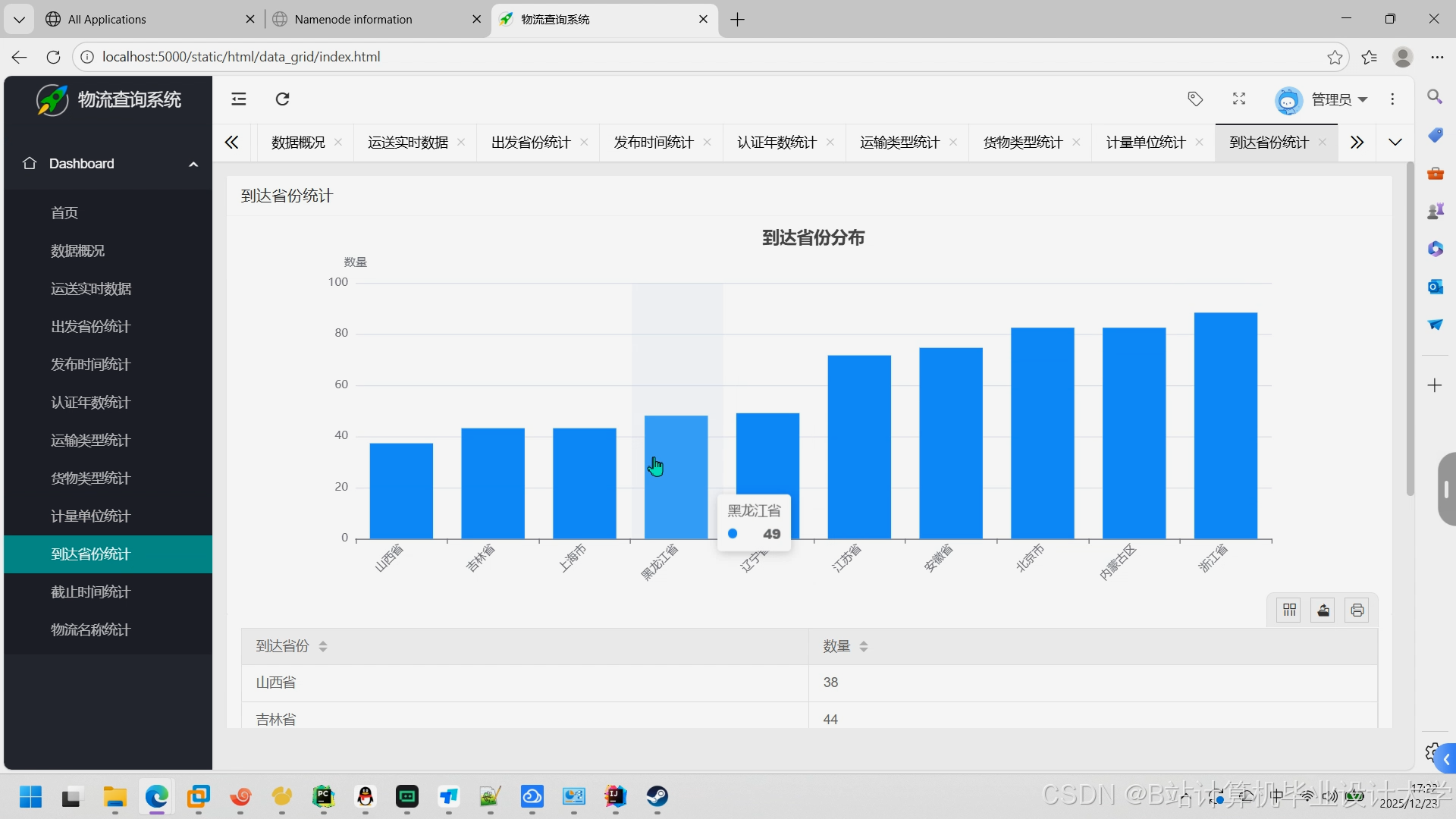
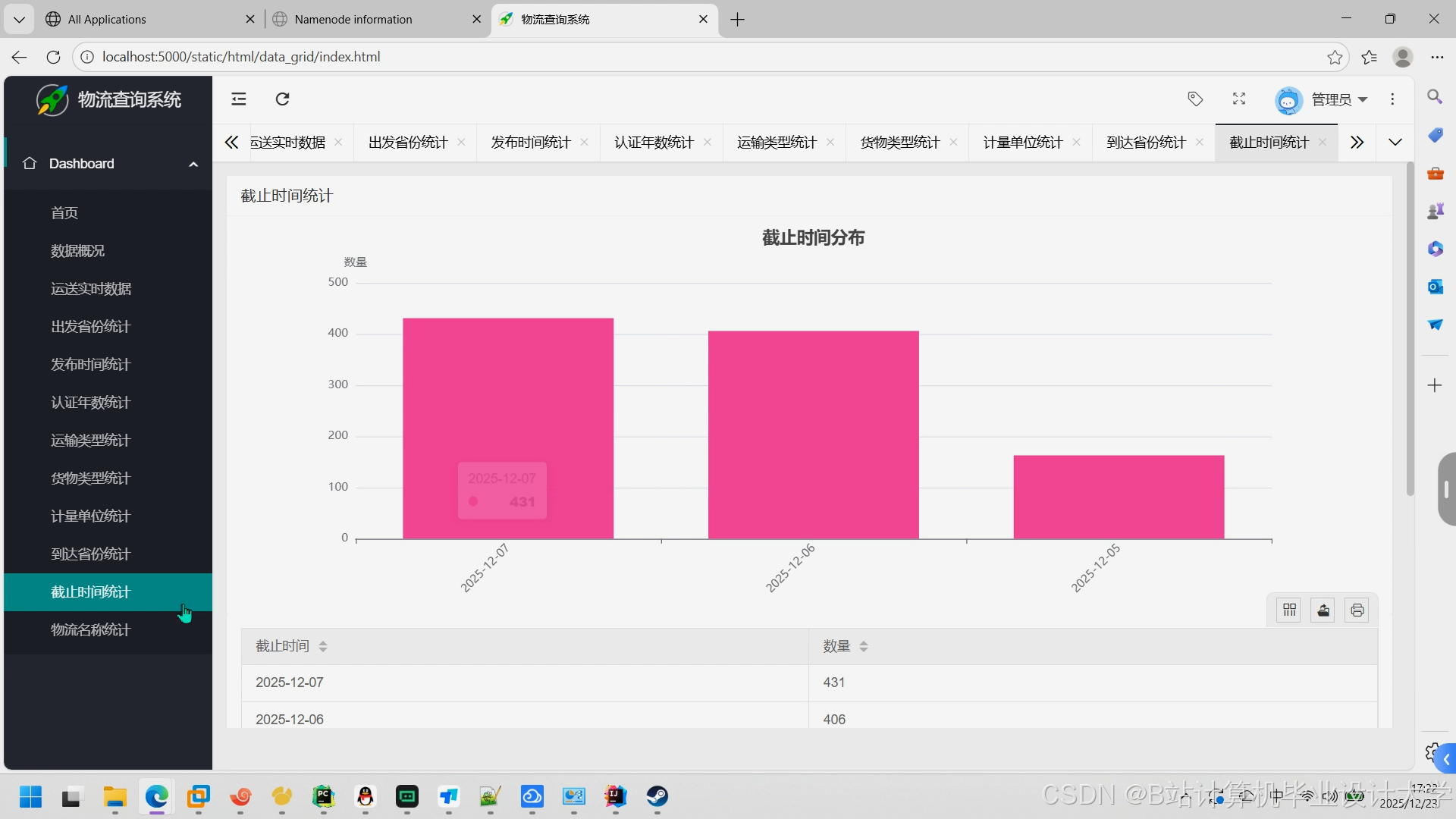
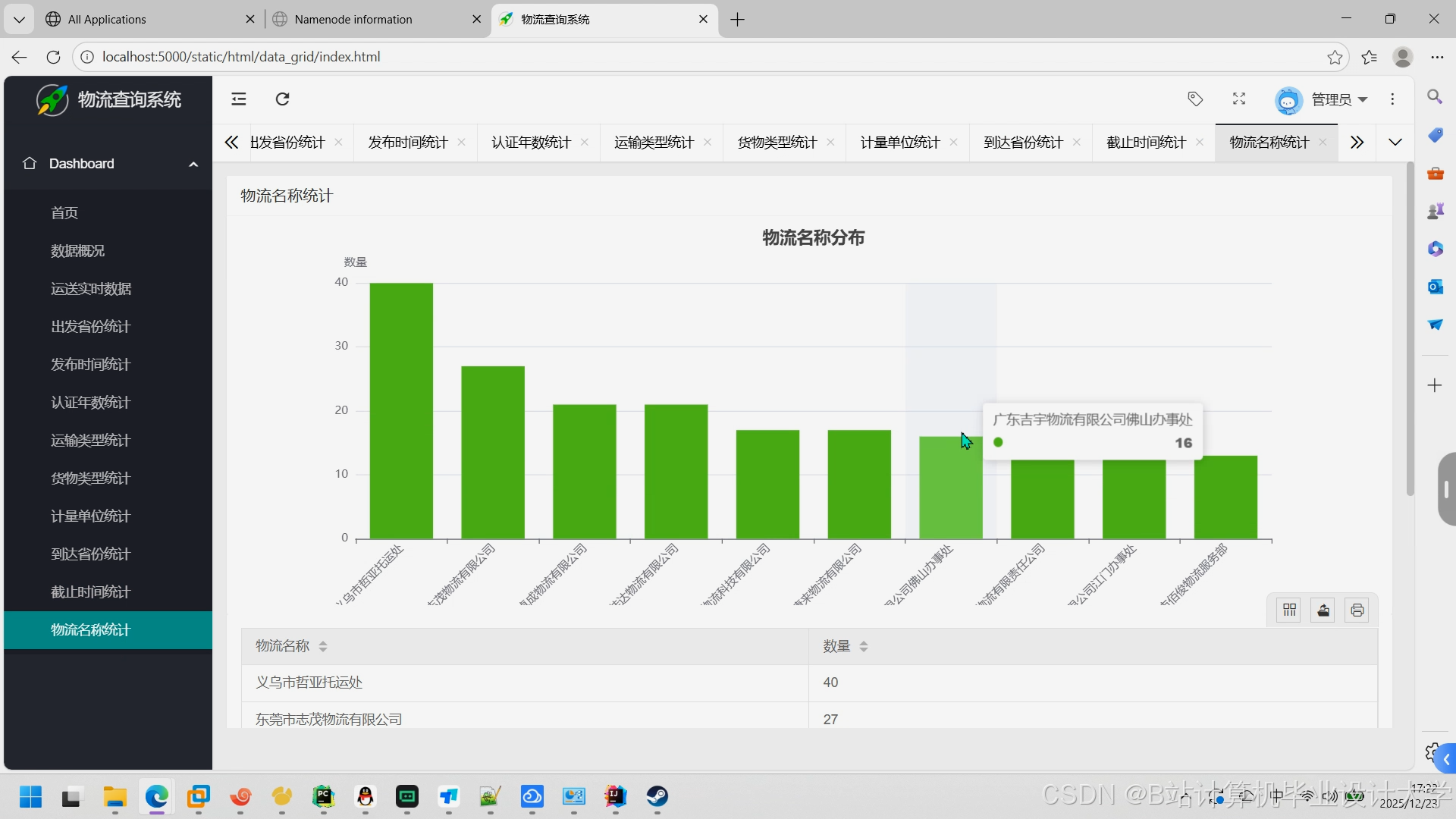
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献205条内容
已为社区贡献205条内容

所有评论(0)