收藏学习 | ReAct架构详解:让AI智能体拥有动态规划能力,解决复杂问题不再难
还在让你的智能体“一次搜索定终身”?面对复杂问题时,它的答案往往前言不搭后语。今天,我们聊聊ReAct,一个能让AI像人一样“边想边做”的架构,彻底终结这种尴尬。
写在前面
这就像你让一个新手员工去查资料,他直接打开百度,把老板的问题原样输入,然后把搜出来的第一页结果直接甩给你。你肯定会说:“能有点逻辑吗?不能分步拆解一下吗?”
这就是我们今天的主角——ReAct 要解决的问题。ReAct,全称是“推理+行动”(Reason + Act),它的核心思想无比朴素:让智能体在执行每个行动前,先动脑子想一想;看到行动结果后,再想一想下一步该干什么。
它把智能体从一个只会机械执行指令的工具人,变成了一个能动态规划、随机应变的解题高手。这篇文章,我们会先动手写一个“有手无脑”的基础版智能体,看看它在复杂任务面前如何翻车。然后,我们会用 LangGraph 亲手搭建一个完整的 ReAct 智能体,并一步步展示它如何通过“思考 → 行动 → 观察”的循环,优雅地完成那些让基础版望而却步的任务。
什么是 ReAct?
我们先用一个生活化的类比来理解它。假设你要写一篇关于“国产AI芯片最新进展”的深度报告。
- 基础智能体:相当于你打开谷歌,输入“国产AI芯片最新进展”,然后把排在前面的几篇文章复制粘贴,拼凑出一份报告。结果很可能信息陈旧、观点片面。
- ReAct 智能体:则像一位经验丰富的研究员。他会先想:“要写这个报告,我得先确定最近有哪些主要玩家。” 于是他搜索“2026年国产AI芯片厂商排名”,看到了“寒武纪”、“壁仞科技”等名字。接着他又想:“光有厂商不行,还得看看他们的核心技术。” 于是他针对每个厂商,搜索“壁仞科技 BR100 技术解析”。得到信息后,他又想:“这些技术在业界的评价如何?和国外竞品比呢?” 于是再次搜索“壁仞科技 BR100 性能评测 对比 Nvidia H100”……如此循环,直到信息足够支撑一份有深度、有观点的报告。
这就是 ReAct 的精髓:推理(Reason)驱动行动(Act),行动的结果又反过来促成下一步的推理。
正式定义:ReAct 是一种智能体设计模式,它要求大语言模型在每一步都生成思考(推理下一步做什么)和行动(如调用工具)。模型观察行动结果后,将其作为新的上下文,再次进行思考,如此形成一个动态、自适应的闭环,直到完成任务。
ReAct 工作流程
这个流程就像你平时解决复杂问题的思维过程,完全可以带入进去理解。
- 接收目标:智能体收到一个复杂任务,比如“帮我查查XX”。
- 思考:智能体开始“自言自语”:“要回答这个问题,我首先得找到X信息,然后才能用X去找Y。”
- 行动:基于思考,智能体执行一个动作,通常是调用一个工具,比如执行一次网络搜索
web_search("X")。 - 观察:智能体收到工具的返回结果。
- 循环:智能体将观察结果融入上下文,然后返回第2步,基于新的信息产生新的思考,例如:“好,现在我知道X了,下一步需要用X去搜索Y。”
- 完成:循环持续进行,直到智能体认为信息足够,能给出最终答案。
什么时候该用它?
ReAct 特别适合以下场景:
- 多跳问答:需要按顺序查找多条信息才能回答的问题,比如我们开头的例子。
- 网页导航与研究:需要像人一样,先搜一个起点,阅读内容,再根据内容决定下一个搜索词,逐步深入。
- 交互式工作流:任何环境动态变化,无法预先规划所有步骤的任务。比如运维排错、代码调试等。
优点和缺点
- 优点
- 自适应与动态:计划可以随时根据新信息调整,而不是一条路走到黑。
- 处理复杂任务:能轻松驾驭那些需要多个依赖步骤才能解决的问题。
- 缺点
- 更高延迟与成本:因为涉及多次大语言模型调用(思考+行动),速度会更慢,成本也更高。
- 循环风险:如果思考指令写得不清晰,智能体可能会陷入重复、无效的“思考-行动”死循环,需要开发者设计好退出机制。
基础与环境准备
老规矩,我们先搭好环境。这次我们会用到 Nebius、LangSmith 和 Tavily 网络搜索工具。
安装核心库
# !pip install -q -U langchain-nebius langchain langgraph rich python-dotenv tavily-python
导入库并设置密钥
在项目根目录下创建 .env 文件,填入你的密钥:
NEBIUS_API_KEY="你的_nebius_api_key"LANGCHAIN_API_KEY="你的_langsmith_api_key"TAVILY_API_KEY="你的_tavily_api_key"
``````plaintext
import osfrom typing import Annotatedfrom dotenv import load_dotenv# LangChain 组件from langchain_nebius import ChatNebiusfrom langchain_community.tools.tavily_search import TavilySearchResultsfrom langchain_core.messages import BaseMessagefrom pydantic import BaseModel, Field# LangGraph 组件from langgraph.graph import StateGraph, ENDfrom langgraph.graph.message import AnyMessage, add_messagesfrom langgraph.prebuilt import ToolNode, tools_condition# 用于美化打印from rich.console import Consolefrom rich.markdown import Markdown# --- API 密钥与追踪设置 ---load_dotenv()os.environ["LANGCHAIN_TRACING_V2"] = "true"os.environ["LANGCHAIN_PROJECT"] = "Agentic Architecture - ReAct (Nebius)"# 检查密钥是否已设置for key in ["NEBIUS_API_KEY", "LANGCHAIN_API_KEY", "TAVILY_API_KEY"]: ifnot os.environ.get(key): print(f"{key} 未找到,请在 .env 文件中设置。")print("环境变量加载完成,追踪已开启。")
``````plaintext
环境变量加载完成,追踪已开启。
基础方法——单次工具调用智能体
在见识 ReAct 的强大之前,我们先亲手写一个“有手无脑”的智能体。它能用工具,但只能用一次。它会分析用户的问题,调用一次搜索,然后凭借这次搜索得到的信息,强行给出最终答案。这个设计,就是为了让它暴露缺点。
构建基础智能体
我们用 LangGraph 构建一个简单的线性图:智能体节点 agent 负责决定调用什么工具(只能一次),然后执行工具,最后结束。
from typing import TypedDictconsole = Console()# 定义图谱的状态class AgentState(TypedDict): messages: Annotated[list[AnyMessage], add_messages]# 定义工具和大语言模型search_tool = TavilySearchResults(max_results=2, name="web_search")llm = ChatNebius(model="meta-llama/Meta-Llama-3.1-8B-Instruct", temperature=0)llm_with_tools = llm.bind_tools([search_tool])# 为基础智能体定义 agent 节点def basic_agent_node(state: AgentState): console.print("--- 基础智能体:思考中... ---") # 关键提示:强制它在一次工具调用后给出答案 system_prompt = "你是一个有用的助手。你可以使用网络搜索工具。请基于工具结果回答用户问题。你必须在一次工具调用后给出最终答案。" messages = [("system", system_prompt)] + state["messages"] response = llm_with_tools.invoke(messages) return {"messages": [response]}# 定义基础的线性图basic_graph_builder = StateGraph(AgentState)basic_graph_builder.add_node("agent", basic_agent_node)basic_graph_builder.add_node("tools", ToolNode([search_tool]))basic_graph_builder.set_entry_point("agent")# agent 之后,如果调用了工具就去 tools,否则直接结束basic_graph_builder.add_conditional_edges("agent", tools_condition, {"tools": "tools", "__end__": "__end__"})basic_graph_builder.add_edge("tools", END)basic_tool_agent_app = basic_graph_builder.compile()print("基础单次工具调用智能体编译成功。")
``````plaintext
基础单次工具调用智能体编译成功。
在多步问题上测试基础智能体
现在,我们用那个经典的“多跳”问题来考验它,看看它如何翻车。
multi_step_query = "谁是科幻电影《沙丘》制作公司的现任 CEO,那家公司最近一部电影的预算是多少?"console.print(f"[bold yellow]在多步查询上测试基础智能体:[/bold yellow] '{multi_step_query}'\n")basic_agent_output = basic_tool_agent_app.invoke({"messages": [("user", multi_step_query)]})console.print("\n--- [bold red]基础智能体最终输出[/bold red] ---")console.print(Markdown(basic_agent_output['messages'][-1].content))
输出讨论:不出所料,基础智能体大概率会输出一个错误或不完整的答案。它的一次搜索可能搜到了关于《沙丘》票房的信息,但没找到制片公司;或者搜到了制片公司,但忽略了CEO和最近一部电影的预算。它缺乏“拆解问题”和“利用中间结果”的能力,这个失败完美地铺垫了我们引入 ReAct 的必要性。
进阶方法——实现 ReAct
现在,我们来构建真正的 ReAct 智能体。核心区别就在图的结构里:我们会引入一个循环,让智能体可以反复进行“思考、行动、观察”。
构建 ReAct 智能体图
我们定义两个核心节点:agent(思考+行动决策)和 tools(执行工具)。关键的路由逻辑是:如果 agent 决定调用工具,就走 tools 节点,**然后必须从 tools 再回到 agent**,让智能体带着工具结果继续思考。
def react_agent_node(state: AgentState): console.print("--- REACT 智能体:思考中... ---") response = llm_with_tools.invoke(state["messages"]) return {"messages": [response]}# ToolNode 与之前相同react_tool_node = ToolNode([search_tool])# 路由逻辑也相同def react_router(state: AgentState): last_message = state["messages"][-1] if last_message.tool_calls: console.print("--- 路由:决定调用工具。 ---") return"tools" console.print("--- 路由:决定结束。 ---") return"__end__"# 现在定义包含关键循环的图react_graph_builder = StateGraph(AgentState)react_graph_builder.add_node("agent", react_agent_node)react_graph_builder.add_node("tools", react_tool_node)react_graph_builder.set_entry_point("agent")react_graph_builder.add_conditional_edges("agent", react_router, {"tools": "tools", "__end__": "__end__"})# 关键区别:边从 tools 回到 agent,形成闭环react_graph_builder.add_edge("tools", "agent")react_agent_app = react_graph_builder.compile()print("包含推理循环的 ReAct 智能体编译成功。")
``````plaintext
包含推理循环的 ReAct 智能体编译成功。
对比测试
我们再次用同一个复杂查询考验我们的 ReAct 智能体,这次我们重点关注它的“思考过程”。
在多步问题上测试 ReAct 智能体
我们用流式方式输出,这样就可以清晰地看到它是如何一步步迭代推理的。
console.print(f"[bold green]在同样的多步查询上测试 ReAct 智能体:[/bold green] '{multi_step_query}'\n")final_react_output = Nonefor chunk in react_agent_app.stream({"messages": [("user", multi_step_query)]}, stream_mode="values"): final_react_output = chunk console.print(f"--- [bold purple]当前状态[/bold purple] ---") chunk['messages'][-1].pretty_print() console.print("\n")console.print("\n--- [bold green]ReAct 智能体最终输出[/bold green] ---")console.print(Markdown(final_react_output['messages'][-1].content))
输出讨论:大功告成!看看智能体的“内心独白”:
- 思考 1:“要回答这个问题,我需要先找出《沙丘》的制作公司。”
- 行动 1:调用
web_search,搜索“《沙丘》电影制作公司”。 - 观察 1:搜索结果明确指向“传奇影业”。
- 思考 2:“知道了制作公司是传奇影业,下一步我需要找出它的现任CEO。”
- 行动 2:再次调用
web_search,搜索“传奇影业 CEO”。 - 观察 2:得到“乔什·格罗德”等信息。
- 思考 3:“还差一个问题,需要找到传奇影业最近一部电影的预算。”
- 行动 3:第三次调用
web_search,搜索“传奇影业 最近电影 预算”。 - 观察 3:得到相关数据。
- 整合:最后,智能体将收集到的所有信息,整合成一个完整、准确的答案。
这个清晰的“思考-行动-观察”循环,完美展示了 ReAct 模式在解决复杂、多步问题上的绝对优势。
定量评估
为了让对比更客观,我们请出“大语言模型裁判”,分别给两个智能体的表现打分。
class TaskEvaluation(BaseModel): """评估智能体完成任务能力的评分模式。""" task_completion_score: int = Field(description="1-10分,智能体是否成功完成了用户请求的所有部分。") reasoning_quality_score: int = Field(description="1-10分,智能体展现的逻辑流程与推理质量。") justification: str = Field(description="分数的简要理由。")judge_llm = llm.with_structured_output(TaskEvaluation)def evaluate_agent_output(query: str, agent_output: dict): trace = "\n".join([f"{m.type}: {m.content}"for m in agent_output['messages']]) prompt = f"""你是一位专门评估 AI 智能体的裁判。请为以下智能体在给定任务上的表现打分,1-10分。10分表示任务完成完美,1分表示完全失败。**用户任务:**{query}**完整智能体对话追踪:**{trace}""" return judge_llm.invoke(prompt)console.print("--- 评估基础智能体的输出 ---")basic_agent_evaluation = evaluate_agent_output(multi_step_query, basic_agent_output)console.print(basic_agent_evaluation.model_dump())console.print("\n--- 评估 ReAct 智能体的输出 ---")react_agent_evaluation = evaluate_agent_output(multi_step_query, final_react_output)console.print(react_agent_evaluation.model_dump())
输出讨论:裁判的评分让差距一目了然。
- 基础智能体:
task_completion_score和reasoning_quality_score双双低分。因为它没能收集齐所有信息,过程缺乏逻辑性。 - ReAct 智能体:获得了近乎满分的评价。裁判认可了它的迭代式推理过程,并成功完成了任务的所有部分。
这个量化的结果,确凿地证明了 ReAct 架构的价值——它是解锁智能体解决复杂、多跳问题能力的钥匙。
本章总结
在这篇笔记中,我们不仅亲手用 LangGraph 实现了 ReAct 架构,更重要的是,我们通过一个直观的对比实验,清晰地展示了它相对于基础单次调用方法的绝对优势。
三个核心记忆点:
- 核心原理:ReAct 通过“推理 → 行动 → 观察”的循环,让智能体能够动态规划,解决需要多步推理的复杂问题。
- 实践关键:用 LangGraph 实现 ReAct 的核心,是在图中构建从
tools节点回到agent节点的循环边。- 避坑指南:ReAct 虽然强大,但要警惕无限循环的风险,需要在系统提示词或代码逻辑中设置合理的停止条件。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
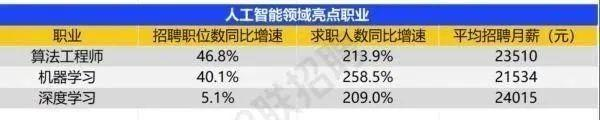
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)