洪水内涝暴雨预测模型探索:基于机器学习算法
洪水内涝暴雨预测模型,其他技能服务 使用Kerala洪水数据集,输入是降雨量,输出是洪水风险,基于机器学习算法预测洪水发生的可能性。 该模型采用5种机器学习算法,分别是KNN分类、逻辑回归、支持向量机、决策树和随机森林,利用Kerala降雨数据进行洪水预测以获取最佳模型。 考虑清楚,和arcgis那种不一样,这个偏数学建模 附源码,数据以及注释 python
在面对洪水内涝这样的自然灾害时,提前准确预测显得尤为重要。今天我们就来聊聊基于机器学习算法构建的洪水内涝暴雨预测模型,用数据的力量助力防灾减灾。
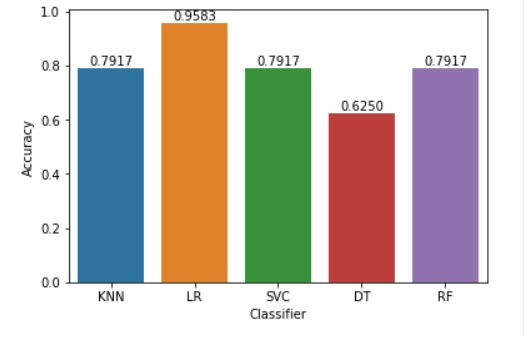
我们使用的是Kerala洪水数据集,输入数据为降雨量,而输出则是洪水风险,也就是预测洪水发生的可能性。整个模型构建采用了5种常见的机器学习算法,分别是KNN分类、逻辑回归、支持向量机、决策树和随机森林。最终目的是利用Kerala降雨数据进行洪水预测,从中获取最佳模型。
KNN分类算法
KNN(K - Nearest Neighbors),即K近邻算法,是一种基本分类与回归方法。其核心思想是如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
# 假设我们已经从数据集中提取了特征(降雨量)和标签(洪水风险)
data = pd.read_csv('kerala_flood_data.csv')
X = data[['rainfall']]
y = data['flood_risk']
knn = KNeighborsClassifier(n_neighbors = 5)
knn.fit(X, y)这段代码首先导入了KNeighborsClassifier类,这是scikit - learn库中实现KNN分类算法的类。然后读取数据集,将降雨量作为特征X,洪水风险作为标签y。最后创建一个KNN分类器实例,这里设置n_neighbors为5,表示考虑5个最近邻,并且使用数据对模型进行拟合。
逻辑回归
逻辑回归虽然名字里有“回归”,但它实际上是一种分类算法。它通过构建逻辑回归模型,将线性回归的结果通过Sigmoid函数映射到0到1之间,从而实现对样本的分类预测。
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
logreg.fit(X, y)这里从sklearn.linear_model导入LogisticRegression类,创建逻辑回归模型实例,并使用数据进行拟合。逻辑回归的优势在于计算简单,可解释性强,在许多分类问题中都有不错的表现。
支持向量机(SVM)
支持向量机是一种有监督的机器学习算法,它试图找到一个超平面来最大限度地分离不同类别的数据点。对于非线性可分的数据,还可以通过核函数将数据映射到高维空间,从而找到合适的超平面。
from sklearn.svm import SVC
svm = SVC(kernel='rbf')
svm.fit(X, y)从sklearn.svm导入SVC类,这里我们使用高斯核函数rbf创建SVM分类器实例,然后对数据进行拟合。rbf核函数在处理复杂的非线性数据时通常能取得较好的效果。
决策树
决策树是一种基于树结构进行决策的算法,它通过对数据的特征进行不断的分裂,构建一棵决策树,每个内部节点表示一个特征上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
dt.fit(X, y)从sklearn.tree导入DecisionTreeClassifier类,创建决策树分类器实例并拟合数据。决策树的优点是易于理解和解释,构建速度快,但也容易出现过拟合的问题。
随机森林
随机森林是基于决策树的一种集成学习算法,它通过构建多个决策树,然后综合这些决策树的预测结果来进行最终的预测。通常采用Bagging的策略来训练多个决策树,并且在构建决策树时,对特征进行随机选择。
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators = 100)
rf.fit(X, y)从sklearn.ensemble导入RandomForestClassifier类,这里设置n_estimators为100,表示构建100棵决策树。通过拟合数据,随机森林可以利用多个决策树的优势,提升模型的泛化能力,减少过拟合的风险。
洪水内涝暴雨预测模型,其他技能服务 使用Kerala洪水数据集,输入是降雨量,输出是洪水风险,基于机器学习算法预测洪水发生的可能性。 该模型采用5种机器学习算法,分别是KNN分类、逻辑回归、支持向量机、决策树和随机森林,利用Kerala降雨数据进行洪水预测以获取最佳模型。 考虑清楚,和arcgis那种不一样,这个偏数学建模 附源码,数据以及注释 python
通过对这5种机器学习算法的实现和比较,我们可以评估它们在洪水内涝暴雨预测任务中的性能,找出最佳模型,为实际的洪水风险预测提供有力支持。希望这篇文章能让你对基于机器学习的洪水预测模型有更深入的了解。
数据集和完整代码获取:你可以在[具体数据集和代码存放地址]获取本文所用到的Kerala洪水数据集以及完整带注释的代码,快来一起探索吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)