【AI大模型前沿】微软VibeVoice-ASR技术解析:支持60分钟长音频端到端识别的开源语音识别新标杆
系列篇章💥
前言
在远程办公与多媒体内容爆发式增长的当下,传统语音识别系统面临严峻挑战:音频切分导致上下文断裂、说话人追踪混乱、专业术语识别率低。微软研究院于2026年1月开源的VibeVoice-ASR,以单次处理60分钟长音频的能力破局而出,重新定义了端到端语音识别的技术边界。本文将深度解析其架构原理与工程实践,为开发者提供全面的技术参考。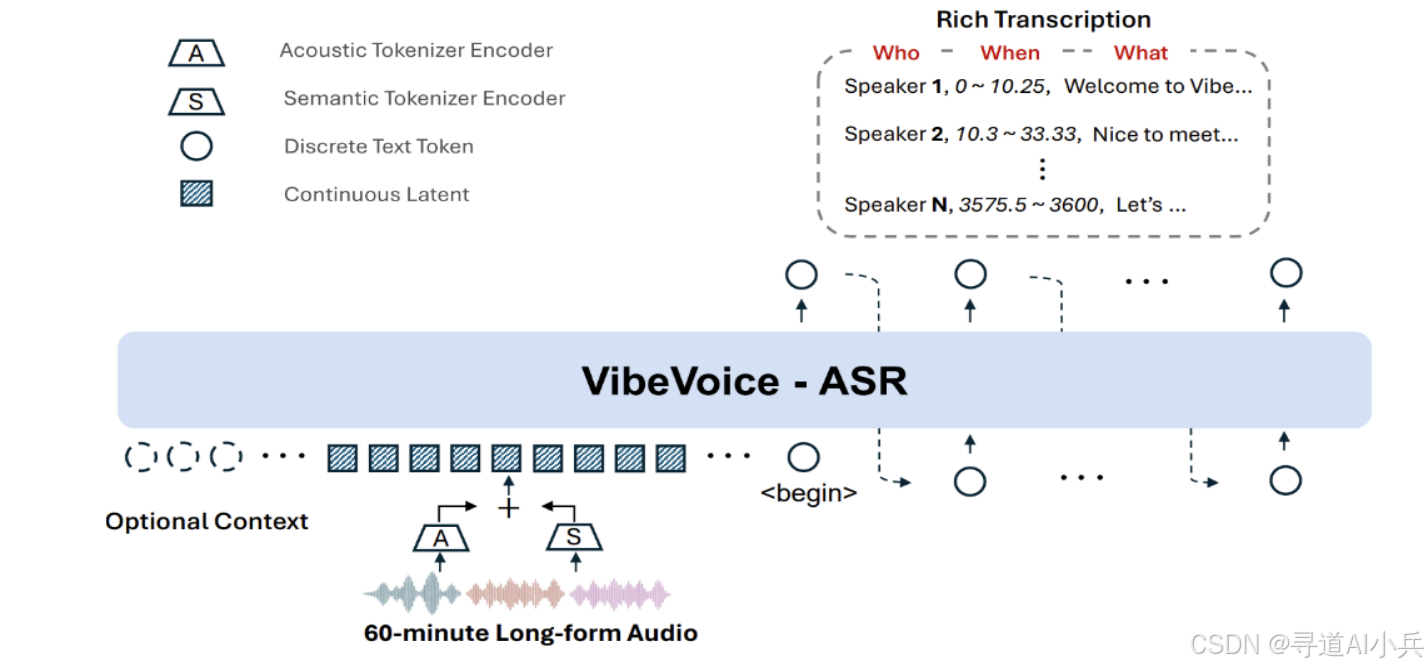
一、项目概述
VibeVoice-ASR是微软开源的90亿参数统一语音识别模型,基于Qwen2 Decoder架构,采用64K token超长上下文窗口与7.5 Hz超低帧率语音分词技术,实现了ASR(自动语音识别)、说话人分离(Diarization)和时间戳标注(Timestamping)三大任务的端到端联合建模。该模型支持中英双语,可单次处理长达60分钟的连续音频,输出"Who-When-What"结构化转录结果,并通过自定义热词功能适配医疗、法律等专业领域,采用MIT协议开源,支持免费商用与二次开发。
二、核心功能
(一)、60分钟超长音频单次处理
传统ASR系统将长音频切分为30秒片段分别处理,导致跨片段语义丢失与说话人ID错乱。VibeVoice-ASR通过64K token上下文窗口与流式分块编码技术,将60分钟音频(约5.76亿采样点)压缩为约27K token,实现全局上下文的一次性建模。这种设计避免了传统方案中"分段-识别-拼接"流程带来的信息损失,确保长篇会议、播客访谈等场景的语义连贯性。
(二)、三位一体结构化输出
模型原生输出包含三大要素的结构化文本:
- Who(说话人标识):自动区分不同说话人,支持多说话人场景下的声纹识别
- When(时间戳标注):精确到秒级的发言时间标记,便于内容回溯
- What(文本内容):高质量转录文本,支持中英夹杂与专业术语
这种"会议纪要"式输出格式,直接满足企业会议记录、法庭庭审记录等场景的结构化需求,无需后处理流水线。
(三)、自定义热词增强识别
针对医疗、法律、技术会议等专业场景,VibeVoice-ASR支持热词注入机制。用户可预先提供专有名词、技术术语或人名列表,模型通过注意力引导与词汇表偏置技术,将热词召回率提升15-20%。这一功能有效解决了传统ASR对低频专业词汇识别准确率低的问题,显著降低后期人工校对成本。
(四)、流式处理与内存优化
通过VibeVoiceTokenizerStreamingCache缓存机制,模型在处理超长音频时采用分块编码策略:将60分钟音频切分为60秒块流式处理,缓存卷积层状态,最终统一采样确保块间一致性。配合FlashAttention-2技术,内存复杂度从O(N²)降至O(N),使得90亿参数模型可在单卡24GB显存环境下运行。
三、技术揭秘
(一)、双编码器架构设计
VibeVoice-ASR采用声学-语义双编码器架构:
- 声学编码器:基于VAE结构,将16kHz音频压缩为7.5 Hz离散token(码本大小8K),捕捉音色、语调等声学细节
- 语义编码器:类似HuBERT架构,提取语音的语义表示,确保内容理解准确性
双编码器特征融合后,通过**声学连接器(Acoustic Connector)**映射至LLM语义空间,实现声学信息与语言知识的深度耦合。
(二)、7.5 Hz超低帧率分词技术
传统梅尔频谱以50 Hz帧率提取特征,1小时音频产生18万帧,超出Transformer处理能力。VibeVoice创新性地采用7.5 Hz帧率,压缩比高达2133:1,将长音频转化为LLM可处理的token序列。这种超低帧率设计不仅解决长度瓶颈,更通过连续语音分词器保留韵律与语气信息,为后续TTS任务提供统一表征基础。
(三)、Next-Token Diffusion生成框架
模型基于Qwen2.5-7B骨干网络,引入扩散头(Diffusion Head)生成声学细节。在ASR任务中,LLM负责理解音频语义与对话结构,预测文本token;在TTS任务中,扩散头通过多步去噪生成声学token,再经声码器还原为波形。这种统一框架使ASR与TTS共享 tokenizer 与骨干网络,实现多任务协同学习。
(四)、多任务联合训练策略
针对ASR、说话人分离、时间戳预测的任务冲突,采用三阶段渐进训练:
- 阶段一:预训练纯ASR能力,建立音频-文本映射
- 阶段二:引入说话人嵌入,学习声纹区分
- 阶段三:加入时间戳预测,优化 temporal 对齐
通过特殊token(如<|transcribe|>、<|diarize|>)进行任务提示,动态调整损失权重,实现端到端优化。
(五)、长上下文一致性保障
为解决流式分块处理的边界效应,模型采用延迟采样机制:分块编码仅计算均值(mean)与标准差(std),缓存至全部块处理完毕后统一采样。这种"先编码后采样"策略确保全局token分布一致性,避免传统流式方案中的块间跳变问题。
四、应用场景
(一)、企业会议智能记录
在1小时以上的部门会议或项目评审中,VibeVoice-ASR可实时生成带发言人标识的会议纪要。相比传统方案,其说话人分离错误率(DER)降低至4-5%,时间戳约束词错误率(tcpWER)显著优于Whisper+Pyannote流水线,直接输出可用于归档与行动项跟进的结构化文档。
(二)、播客与访谈内容生产
针对播客、媒体访谈等长音频内容,模型支持一次性转录并自动区分主持人与嘉宾。内容创作者可直接获取带时间轴的文本稿,快速定位精彩片段进行剪辑,或生成SEO友好的文字摘要与字幕文件,大幅提升内容生产效率。
(三)、客服质检与合规审查
在金融、电信行业的客服场景中,VibeVoice-ASR的结构化输出(说话人+时间戳+内容)支持精准追溯服务过程。通过注入业务热词(如产品名称、合规术语),可自动标记风险对话片段,辅助质检人员高效完成合规审查。
(四)、在线教育与学术记录
对于在线课程、学术讲座等场景,模型自动生成带时间戳的字幕与讲稿,支持学生快速检索知识点。多语言混合处理能力(中英夹杂)适配国际化教学环境,热词功能可针对学科术语(如医学名词、法律条文)进行优化。
(五)、医疗与法律专业文档
在医疗会诊、法庭庭审等专业场景中,通过注入领域热词(如药品名称、法律条款),模型可提升专业词汇识别准确率。端到端架构避免了传统方案中多模型串联导致的误差累积,确保关键信息的完整记录。
五、快速使用
(一)、环境准备
VibeVoice-ASR基于PyTorch框架,推荐在NVIDIA PyTorch Container(24.07-25.12版本验证)中运行。基础环境要求:
- GPU:NVIDIA GPU,显存≥16GB(推荐24GB以上)
- Python:3.10+
- 依赖:Transformers、PyTorch、FlashAttention-2(可选,用于RTX 30/40/50系列加速)
# 安装核心依赖
pip install torch transformers accelerate
pip install flash-attn --no-build-isolation # 可选,加速推理
(二)、模型下载与加载
通过Hugging Face或ModelScope下载模型:
from transformers import AutoModelForCausalLM, AutoProcessor
import torch
# 加载模型(自动分配多GPU)
model = AutoModelForCausalLM.from_pretrained(
"microsoft/VibeVoice-ASR",
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
# 加载处理器
processor = AutoProcessor.from_pretrained(
"microsoft/VibeVoice-ASR",
trust_remote_code=True
)
(三)、基础推理示例
处理本地音频文件并生成结构化转录:
import torchaudio
# 加载音频(支持wav、mp3等格式)
audio, sr = torchaudio.load("meeting_60min.wav")
audio = torchaudio.functional.resample(audio, sr, 24000) # 重采样至24kHz
audio = audio.mean(dim=0) # 转为单声道
# 准备输入(带热词)
inputs = processor(
text="<|transcribe|>", # 任务提示
speech=audio,
hotwords=["Project Phoenix", "Dr. Smith", "Q4 Revenue"], # 自定义热词
return_tensors="pt"
).to(model.device)
# 生成转录(流式处理自动启用)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=10000,
temperature=0.2,
repetition_penalty=1.1
)
# 解码输出
transcription = processor.decode(outputs[0], skip_special_tokens=False)
print(transcription)
# 输出示例:[SPK:Alice][00:05:23] Let's discuss the Q4 revenue projections...
(四)、Gradio可视化界面部署
微软提供开箱即用的Gradio演示脚本,适合快速体验:
# 下载演示脚本
wget https://raw.githubusercontent.com/microsoft/VibeVoice/main/demo/vibevoice_asr_gradio_demo.py
# 启动Web界面
python vibevoice_asr_gradio_demo.py \
--model_path microsoft/VibeVoice-ASR \
--share # 生成公网访问链接
启动后访问本地或公网地址,即可通过浏览器上传音频、设置热词并查看结构化转录结果。
(五)、vLLM生产级API部署
针对高并发场景,可使用vLLM部署为OpenAI兼容的API服务:
# 使用Docker部署
docker run -d --gpus all --name vibevoice-asr \
-p 8000:8000 \
-v $(pwd)/models:/models \
vllm/vllm-openai:latest \
--model microsoft/VibeVoice-ASR \
--tensor-parallel-size 2 # 根据GPU数量调整
部署后可通过标准HTTP接口调用:
import requests
response = requests.post("http://localhost:8000/v1/completions", json={
"model": "microsoft/VibeVoice-ASR",
"prompt": "<|transcribe|>",
"audio_url": "https://example.com/audio.wav",
"hotwords": ["Technical Term"]
})
print(response.json())
六、结语
VibeVoice-ASR的发布标志着语音识别技术从"分段拼接"迈向"端到端长上下文"的新纪元。其7.5 Hz超低帧率分词、三位一体结构化输出与统一生成框架三大创新,不仅突破了60分钟音频处理的技术瓶颈,更为多模态语音交互提供了可扩展的架构范式。对于开发者而言,MIT开源协议与完善的vLLM部署支持,意味着可快速集成至企业级应用;对于研究者,双编码器与扩散头的协同设计为语音-语言联合建模提供了新思路。
随着VibeVoice系列(ASR、TTS、Realtime)的逐步完善,微软正推动语音AI向"统一建模、高效部署、专业适配"的方向演进。建议开发者关注其GitHub仓库的更新,及时获取量化部署、模型蒸馏等后续优化方案。
项目地址
- 技术报告:https://arxiv.org/pdf/2601.18184
- GitHub仓库:https://github.com/microsoft/VibeVoice
- Hugging Face模型:https://huggingface.co/microsoft/VibeVoice-ASR
- 在线演示:https://huggingface.co/spaces/microsoft/VibeVoice-ASR-Demo

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)