AI生成ER图 SQL生成ER图
工具地址:https://draw.anqstar.com/
一、技术背景与问题引入:ER图绘制的痛点与破局方向
在数据库设计、系统开发与学业实践中,ER图(实体-关系图)是连接需求与落地的核心载体——它将抽象的业务逻辑、数据关联转化为直观的可视化图形,是计算机专业学生完成作业、企业技术团队推进项目、个人开发者搭建应用、技术研究者探索模型的必备工具。但长期以来,ER图绘制始终面临着“适配难、效率低、门槛高”的共性痛点,不同人群的需求难以被单一工具满足。
对于计算机专业学生而言,数据库课程作业、课程设计、毕设论文中,ER图是高频需求,但手工绘制需反复梳理实体、属性、关系,一旦逻辑调整就要全盘重画,往往花费大量时间却难以保证规范,甚至影响学业任务的提交效率;企业技术从业者(研发、测试、运维)在项目迭代中,需频繁根据业务需求调整数据库结构,传统工具绘制ER图不仅耗时,且难以快速同步SQL代码与图表,跨岗位协作时还存在格式不兼容、版本混乱的问题,增加了开发成本与沟通成本;个人开发者面对小型应用、技术练习场景,追求高效便捷,无需复杂的专业工具,却苦于找不到上手简单、能快速生成规范ER图的解决方案;技术研究者在探索数据建模、AI与数据库融合的过程中,需要可落地、可拆解的技术实现思路,而非单纯的绘图工具,传统ER图工具难以满足其技术深度探索的需求。
随着AI技术在编程领域的深度渗透,以及SQL语言在数据库操作中的核心地位,“AI生成ER图”“SQL生成ER图”的需求日益凸显。传统手工绘制、单一功能工具已无法适配多人群、多场景的使用需求,一款能兼顾专业性与易用性、覆盖全人群、支持多格式导出的ER图生成方案,成为破解行业痛点的关键。今天,我们就来拆解一款集AI与SQL双驱动于一体的ER图生成工具,看看它如何适配不同人群需求,实现ER图绘制的高效化、规范化、轻量化。
二、功能介绍:全人群适配,多场景覆盖的ER图生成方案
这款ER图生成工具的核心优势的是“双驱动生成+全格式导出”,无需复杂安装与专业技能,既能让小白快速上手,也能满足专业开发者、研究者的深度需求,潜移默化解决不同人群的核心痛点,适配学生学业、企业开发、个人实践、技术研究等多类场景。
2.1 核心模块一:SQL生成ER图——精准解析,同步落地
该模块的核心作用是直接解析SQL语句,自动生成规范ER图,完美解决“SQL与ER图不同步”的痛点,适配多类SQL语法场景。无论是学生提交数据库作业时的简单建表语句,还是企业研发人员编写的复杂多表关联SQL,工具都能精准识别、高效转化。
对于学生群体,只需将课程作业、毕设中的MySQL、SQL Server等建表语句复制粘贴,工具就能自动提取实体、属性、主键、外键及关联关系,10秒内生成规范ER图,无需手动梳理关系、绘制图形,避免因手工绘制失误影响作业质量;对于企业技术从业者,面对项目中频繁的SQL调整,只需更新SQL语句,ER图就能自动同步更新,无需重新绘制,大幅提升研发、测试、运维的协作效率,尤其适用于数据库结构迭代频繁的项目场景;对于个人开发者,在进行小型应用开发时,可通过编写简单SQL快速生成ER图,清晰梳理数据关联,降低数据建模的难度;对于技术研究者,可通过SQL解析的底层逻辑,探索“SQL语法与ER图映射”的核心机制,为数据建模优化提供实践参考。
2.2 核心模块二:AI生成ER图——自然语言驱动,零门槛上手
该模块主打“零代码、零门槛”,无需掌握SQL语法或绘图技巧,只需用自然语言描述业务需求,AI就能自动识别实体、属性与关系,生成符合规范的ER图,打破了ER图绘制的技术门槛。
学生群体可通过自然语言描述课设、毕设的需求(如“设计一个学生选课系统,包含学生、课程、教师、成绩4个实体,学生可选多门课,教师可教多门课”),AI就能快速生成ER图,还能帮助学生理解实体与关系的对应逻辑,辅助完成课程学习;个人开发者在进行技术练习、小型项目开发时,无需提前编写SQL,通过自然语言快速生成ER图原型,节省数据建模时间;企业技术从业者在需求评审阶段,可通过自然语言快速生成ER图原型,直观呈现数据逻辑,提升跨部门沟通效率;技术研究者可深入探索AI解析自然语言、映射数据模型的底层逻辑,为AI与数据库融合的技术探索提供实践场景。
2.3 核心模块三:多格式导出——无缝适配,全场景复用
工具支持PNG、JPG、SVG、Visio等多种主流格式导出,完美适配不同人群、不同场景的复用需求,解决了传统工具导出格式单一、兼容性差的问题。
学生可将ER图导出为PNG、JPG格式,插入课程论文、毕设报告中,保证排版美观、清晰可辨;企业技术从业者可根据项目需求,将ER图导出为SVG格式(支持无限放大不失真,适配专业排版)、Visio格式(适配企业常用的办公、建模流程),方便嵌入项目文档、汇报材料,实现跨工具复用;个人开发者可导出PNG格式用于项目文档归档、技术分享;技术研究者可导出SVG格式进行图形分析,或导出源文件用于技术原理拆解与优化。
2.4 门槛适配:小白易上手,专业可定制
工具采用“分层适配”设计,无需安装客户端,网页端即可直接使用,零门槛上手。小白用户(学生、入门级开发者)可通过简单的“复制粘贴SQL”“输入自然语言”两步操作,快速生成ER图;专业用户(企业开发者、技术研究者)可深度定制ER图样式、实体属性、关系标注,甚至可接入自定义AI模型、SQL解析规则,满足个性化需求,实现“轻量化使用”与“深度定制”的双向兼容。
三、原理说明:AI与SQL双驱动的ER图生成核心拆解
这款ER图生成工具的核心技术支撑是AI技术与SQL解析技术的深度融合,底层逻辑可分为“基础原理(适配小白、学生)”与“深层细节(适配开发者、研究者)”两部分,兼顾易懂性与专业性,结合具体场景拆解,让不同人群都能理解其核心价值。
3.1 基础原理:通俗理解“AI+SQL如何生成ER图”
无论是SQL生成ER图,还是AI生成ER图,核心逻辑都是“提取数据逻辑→映射实体关系→可视化渲染”,相当于让工具替代人工,完成“梳理逻辑→绘制图形”的过程,具体可分为三个简单步骤,适配学生、小白用户理解:
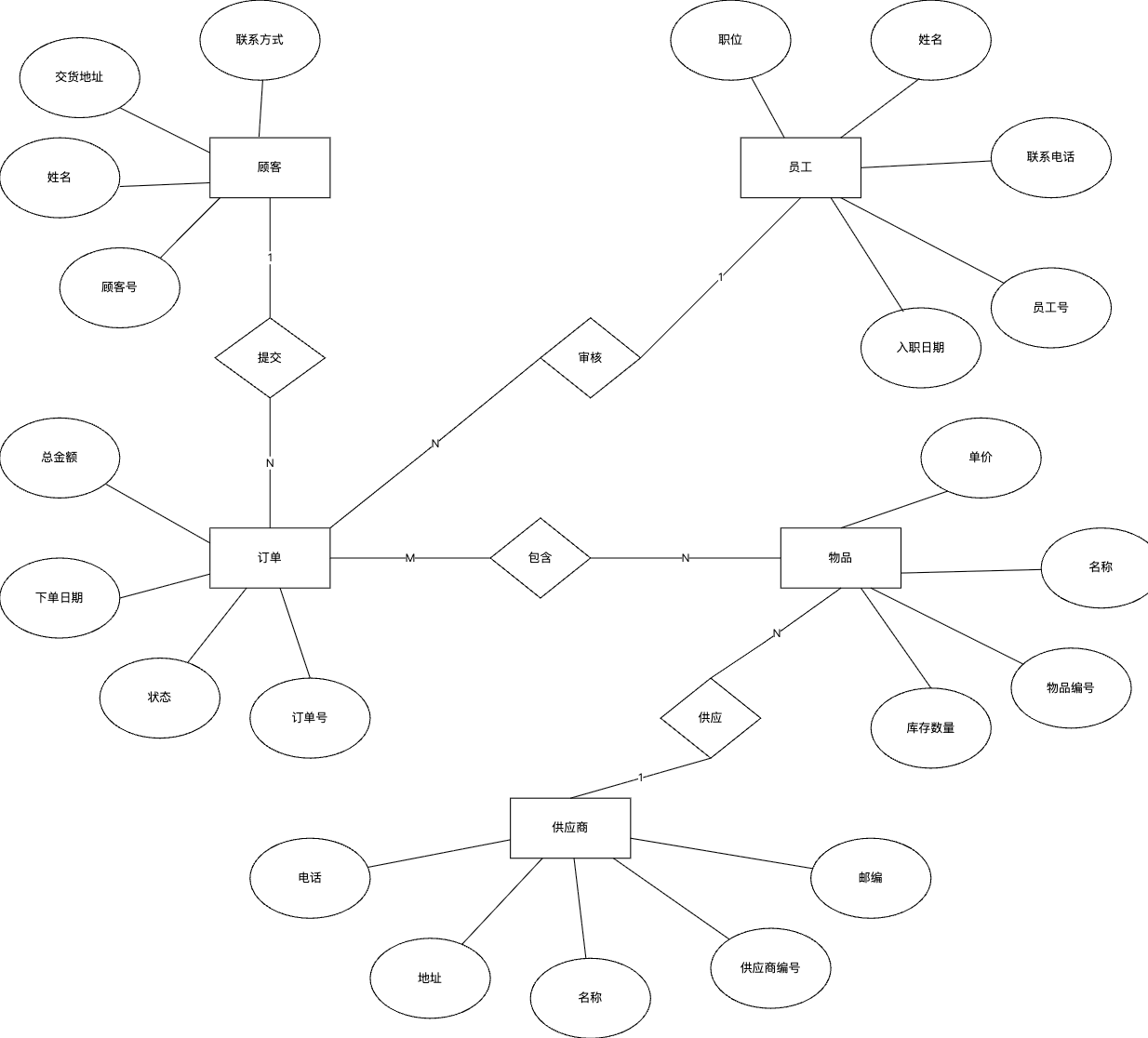
第一步:数据逻辑提取——工具通过SQL解析器或AI自然语言处理,提取核心信息:SQL生成模式下,解析SQL语句中的建表语句、字段信息、约束条件(主键、外键),确定实体(表)、属性(字段)、关系(外键关联);AI生成模式下,通过自然语言处理,识别用户描述中的实体关键词(如“学生”“课程”)、属性描述(如“学生有学号、姓名”)、关系描述(如“选修”“包含”),转化为结构化数据。
第二步:实体关系映射——工具根据提取的信息,按照ER图规范,将数据逻辑转化为图形元素:实体对应矩形,属性对应椭圆,关系对应菱形,同时根据约束条件(如外键关联)确定关系类型(一对一、一对多、多对多),比如学生与课程的“选修”关系,会被映射为多对多关系,并自动生成中间关联实体。
第三步:可视化渲染与导出——工具通过布局引擎(自动调整实体位置,避免线条交叉),将映射后的图形元素渲染为直观的ER图,同时支持多种格式导出,满足不同场景复用需求。
举个学生课设场景的例子:当学生输入SQL建表语句(CREATE TABLE student(id INT PRIMARY KEY, name VARCHAR(50), class VARCHAR(20)); CREATE TABLE course(id INT PRIMARY KEY, name VARCHAR(50), teacher VARCHAR(50)); CREATE TABLE score(student_id INT, course_id INT, score INT, FOREIGN KEY(student_id) REFERENCES student(id), FOREIGN KEY(course_id) REFERENCES course(id));),工具会自动提取3个实体(student、course、score),识别student与score、course与score的一对多关系,快速生成规范ER图,学生无需手动梳理关系,直接导出即可用于课设报告。
3.2 深层细节:技术原理拆解(适配开发者、研究者)
从技术实现层面,工具的核心是“SQL解析引擎+AI自然语言处理模块+可视化渲染引擎”的协同工作,结合具体技术细节与代码片段,拆解其实现逻辑,为开发者、研究者提供可参考的技术思路。
3.2.1 SQL生成ER图的核心技术:SQL解析引擎
SQL解析引擎是SQL生成ER图的核心,基于ANTLR(语法分析器生成器)构建,支持MySQL、SQL Server、Oracle等多种主流数据库的SQL语法解析,核心作用是精准提取SQL语句中的实体、属性、关系信息,避免解析偏差,其核心逻辑分为三个阶段:
1. 语法词法分析:通过ANTLR定义SQL语法规则,将输入的SQL语句拆解为词法单元(如关键词、表名、字段名、约束条件),排除注释、冗余空格等干扰信息,生成抽象语法树(AST),这是解析的基础。
2. 核心信息提取:遍历抽象语法树,提取关键信息——实体识别(每个CREATE TABLE语句对应一个实体,表名即为实体名)、属性提取(解析字段名、数据类型、约束条件,如NOT NULL、UNIQUE)、关系识别(通过FOREIGN KEY约束识别实体间的关联,同时根据基数约束推导关系类型)。
核心代码片段(关键逻辑,非完整项目代码):
// 简化的SQL解析核心逻辑,提取实体与属性 public class SqlParserUtil { // 解析CREATE TABLE语句,提取实体(表)和属性(字段) public Entity parseCreateTable(String sql) { // 1. 词法分析,生成抽象语法树 ANTLRInputStream input = new ANTLRInputStream(sql); SqlLexer lexer = new SqlLexer(input); CommonTokenStream tokens = new CommonTokenStream(lexer); SqlParser parser = new SqlParser(tokens); ParseTree tree = parser.createTableStmt(); // 2. 遍历语法树,提取表名(实体名) String entityName = extractTableName(tree); // 3. 提取字段信息(属性) List<Attribute> attributes = extractAttributes(tree); // 4. 提取外键约束(关系信息) List<ForeignKey> foreignKeys = extractForeignKeys(tree); return new Entity(entityName, attributes, foreignKeys); } // 推导关系类型(一对一、一对多、多对多) public RelationshipType getRelationshipType(ForeignKey foreignKey) { // 根据外键是否有UNIQUE约束判断关系类型 if (foreignKey.isUnique()) { return RelationshipType.ONE_TO_ONE; // 一对一 } else if (isMiddleTable(foreignKey.getSourceTable())) { return RelationshipType.MANY_TO_MANY; // 多对多(中间表) } else { return RelationshipType.ONE_TO_MANY; // 一对多 } } }
3. 数据标准化:将提取的信息标准化处理,统一实体、属性、关系的命名规范,避免因SQL语法差异(如MySQL的AUTO_INCREMENT与SQL Server的IDENTITY)导致的解析偏差,确保生成的ER图符合行业规范。
对于企业技术从业者而言,这一解析逻辑可适配复杂项目中的多数据库场景,解决跨数据库SQL解析的兼容性问题;对于技术研究者,可基于这一逻辑优化解析算法,提升复杂SQL(如包含JOIN、子查询的建表语句)的解析效率与准确性。
3.2.2 AI生成ER图的核心技术:自然语言处理(NLP)与数据模型映射
AI生成ER图的核心是“自然语言语义理解→结构化数据映射→SQL生成→ER图渲染”的全流程自动化,底层采用微调后的大语言模型(LLM),专门针对数据库设计场景优化,其核心技术拆解如下:
1. 自然语言语义理解:通过微调后的LLM模型,识别用户输入的自然语言中的核心信息,采用实体识别(NER)、关系抽取(RE)技术,提取实体、属性、关系。例如,用户输入“设计一个图书馆管理系统,读者可以借多本书,每本书有书名、ISBN、作者,读者有读者号、姓名、联系方式”,模型会通过NER识别出“读者”“书籍”两个实体,通过RE识别出“借”这一多对多关系,同时提取双方的属性信息。
核心优化点:针对数据库设计场景,模型增加了“实体-属性-关系”的专属训练数据,优化了歧义识别能力,比如区分“学生”作为实体与“学生”作为属性的不同场景,避免语义误解,这也是其能精准生成ER图的关键。
2. 数据模型映射:将自然语言提取的结构化信息,映射为符合数据库规范的建表语句(SQL),核心逻辑是根据实体属性自动匹配数据类型(如“学号”映射为INT类型,“姓名”映射为VARCHAR类型),根据关系类型自动生成关联约束(如多对多关系自动生成中间表)。
核心代码片段(关键逻辑,非完整项目代码):
# 简化的AI生成SQL核心逻辑 def nl_to_sql(natural_language): # 1. 自然语言解析,提取实体、属性、关系 entities, relationships = llm_extract_info(natural_language) # 2. 生成建表语句 sql_list = [] for entity in entities: # 匹配属性数据类型 attributes_sql = [] for attr in entity["attributes"]: attr_type = get_attr_type(attr) # 根据属性名自动匹配类型 attributes_sql.append(f"{attr} {attr_type}") # 生成CREATE TABLE语句 sql = f"CREATE TABLE {entity['name']} (id INT PRIMARY KEY AUTO_INCREMENT, {','.join(attributes_sql)})" sql_list.append(sql) # 3. 根据关系生成外键约束或中间表 for rel in relationships: if rel["type"] == "many_to_many": # 生成中间表 middle_table = f"{rel['entity1']}_{rel['entity2']}" sql = f"CREATE TABLE {middle_table} (id INT PRIMARY KEY AUTO_INCREMENT, {rel['entity1']}_id INT, {rel['entity2']}_id INT, FOREIGN KEY({rel['entity1']}_id) REFERENCES {rel['entity1']}(id), FOREIGN KEY({rel['entity2']}_id) REFERENCES {rel['entity2']}(id))" sql_list.append(sql) else: # 生成外键约束(简化逻辑) sql = f"ALTER TABLE {rel['target_entity']} ADD FOREIGN KEY({rel['foreign_key']}) REFERENCES {rel['source_entity']}(id)" sql_list.append(sql) return sql_list
3. 与SQL生成模块协同:生成SQL语句后,调用SQL解析引擎,按照SQL生成ER图的流程,完成可视化渲染,实现“自然语言→SQL→ER图”的全自动化转化。
对于个人开发者而言,这一流程无需手动编写SQL,大幅降低了数据建模的门槛;对于技术研究者,可深入探索LLM在数据库设计场景的微调方法、实体关系抽取的优化思路,为AI与数据建模的融合提供实践参考。
3.2.3 可视化渲染与多格式导出原理
可视化渲染引擎采用基于力导向布局(Force-directed Layout)的算法,核心作用是自动调整实体、关系的位置,避免线条交叉,保证ER图的整洁美观,同时支持自定义样式(如实体颜色、线条粗细)。其核心逻辑是通过计算实体间的排斥力与吸引力,自动优化布局,适配不同数量实体的场景——无论是学生课设中的3-5个实体,还是企业项目中的数十个实体,都能保持图形清晰。
多格式导出的核心是基于不同格式的特性,实现图形数据的转换:PNG、JPG格式采用无损压缩算法,适配日常文档插入、分享场景,保证图片清晰且文件体积适中;SVG格式采用矢量图形技术,支持无限放大不失真,适配专业排版、印刷场景;Visio格式则通过兼容微软Visio的文件协议,实现与企业常用办公工具的无缝对接,方便项目文档的统一管理。这一设计完美解决了不同人群的复用需求,让ER图能够快速融入各类场景。
四、总结:全人群、多场景的ER图高效生成解决方案
ER图的绘制效率与规范性,直接影响学业任务的完成质量、企业项目的推进效率、个人开发的落地速度与技术研究的探索深度。这款AI+SQL双驱动的ER图生成工具,没有生硬的推销,而是通过解决不同人群的核心痛点,将推广属性潜移默化融入技术干货中——它让学生摆脱手工绘制的繁琐,高效完成学业任务;让企业技术从业者降低开发成本,提升协作效率;让个人开发者实现零门槛数据建模;让技术研究者获得可落地的技术实践思路。
无论是SQL生成ER图的精准高效,还是AI生成ER图的零门槛便捷,亦或是多格式导出的全场景适配,本质上都是为了让“ER图绘制”回归核心需求——聚焦数据逻辑,降低技术门槛,提升效率。对于计算机专业学生,它是学业路上的好帮手;对于企业技术从业者,它是项目迭代的效率工具;对于个人开发者,它是快速落地的便捷助手;对于技术研究者,它是技术探索的实践载体。
无需复杂的专业技能,无需繁琐的操作流程,只需简单几步,就能生成规范、美观、可复用的ER图,适配从学业到工作、从入门到专业的全场景需求,这正是这款ER图生成工具的核心价值所在。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)