【组会文献阅读汇报】注意力残差(AttnRes):重塑大模型深度维度的信息聚合范式
本文基于 Kimi 团队的注意力残差技术报告,从研究背景、核心方案、工程化优化、实验验证、深度分析等维度,全面解析 AttnRes 如何解决传统残差连接的 PreNorm 稀释问题,为大语言模型的架构设计提供全新思路。
一、研究背景与动机:PreNorm 时代的残差连接隐忧
在当前大语言模型(LLM)的构建中,残差连接与 PreNorm 的组合已成为标准范式。残差连接的核心价值被广泛认知为构建梯度高速公路:通过的恒等映射,让梯度绕开变换层稳定回传,从根本上解决了极深网络的梯度消失问题。
但 Kimi 团队指出,人们普遍忽略了残差连接的第二个关键角色—— 定义信息跨深度的融合方式。在标准残差结构中,每一层的输入是所有前序层输出的简单算术和,这种统一、无选择性的累积模式,直接导致了PreNorm 稀释问题:
- 隐藏状态模长失控增长:随着网络深度增加,隐藏状态的幅度随深度单调上升,后续层的输入被前期层的累积信息淹没;
- 单层贡献被稀释:新层的输出在累积总和中占比极低,如同 “向满桶水中滴入一滴水”,信息传递效率大幅下降;
- 层冗余性显著:实验证明,该模式下大部分层可被修剪而模型损失极小,说明层间信息交互的有效性不足。
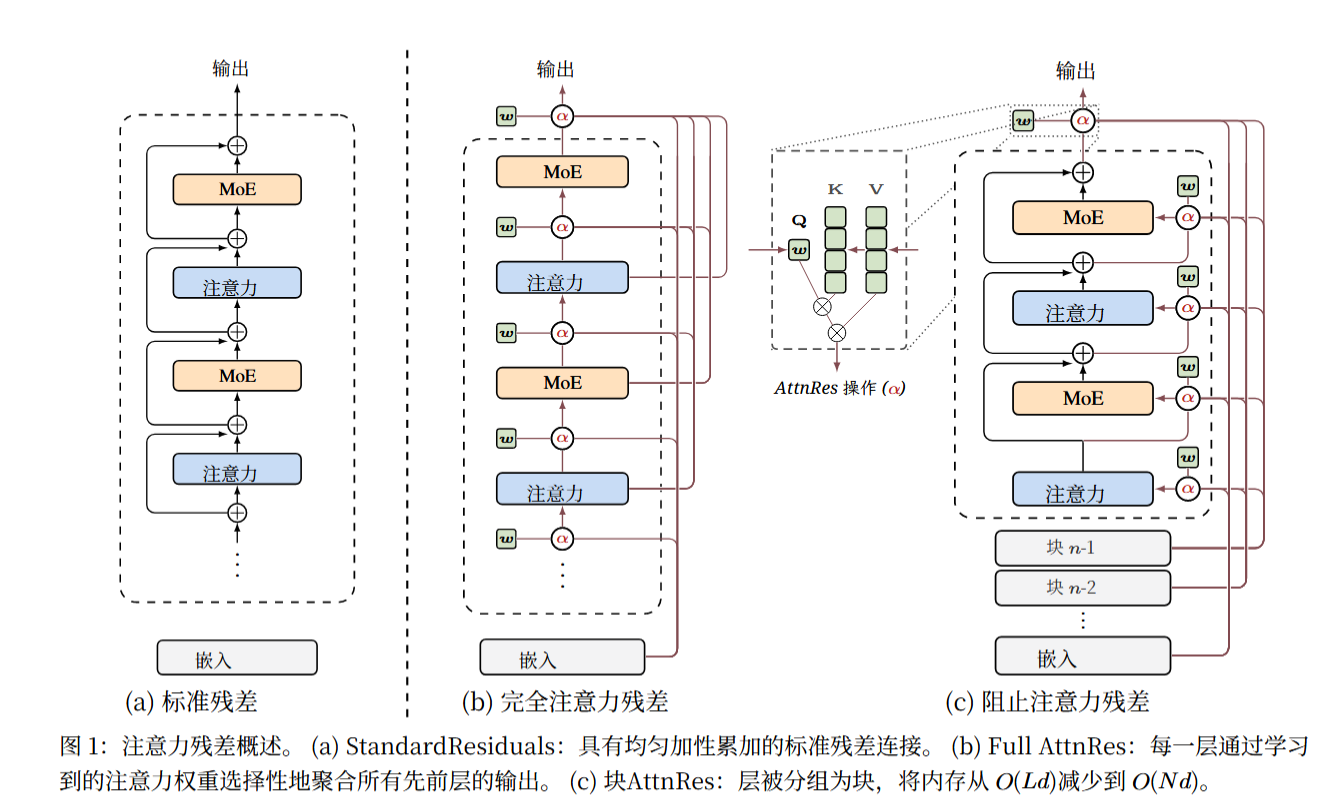
这种问题的本质,是残差连接的深度聚合由固定单位权重控制,缺乏对不同层贡献的选择性强调或抑制机制,与序列维度已广泛应用的可学习、输入相关权重形成鲜明对比。
二、核心方案:注意力残差(AttnRes)的提出
针对 PreNorm 稀释的核心问题,报告提出了革命性的注意力残差(AttnRes) 方案,其核心灵感源于 Transformer 的序列注意力机制:既然模型能在序列维度对历史标记做选择性访问,为何不能在深度维度让当前层自主选择前序层的信息?
2.1 深度与时间的二元性:理论基石
报告揭示了深度维度与序列(时间)维度的形式对偶性:
- RNN 中,信息随时间步递归累积,Transformer 通过注意力实现了序列维度的选择性信息检索;
- 残差网络中,信息随层数递归累积,标准残差连接本质是深度方向的线性注意力,其混合权重为固定的单位矩阵;
- AttnRes 将其推广为深度方向的 Softmax 注意力,让模型具备内容感知的跨深度选择性检索能力,完成了与序列维度一致的 “线性注意力→Softmax 注意力” 的变革性升级。
2.2 数学形式与实现:轻量级的注意力改造
AttnRes 的核心是将残差连接的固定累积 替换为注意力加权累积
,其中αi→l为层间注意力权重,实现过程极简且轻量:
- 伪查询向量:为每一层l设计一个可学习的一维伪查询向量
,与层的前向计算解耦,仅增加极少量参数;
- 注意力权重计算:通过核函数ϕ(q,k)=exp(q⊤RMSNorm(k))计算相似度,再经 Softmax 归一化得到
,确保权重和为 1;
- 键值定义:ki=vi,其中
(令牌嵌入),
(前序层变换输出);
- RMSNorm 正则化:对键进行 RMSNorm 处理,防止部分层输出幅度过大主导注意力权重,保证权重分配的公平性。
该机制允许深层模型 “直接跳回” 提取嵌入层或关键中间层的信息,从根本上解决了 PreNorm 稀释导致的信息埋藏问题。
三、工程化挑战:从 Full AttnRes 到 Block AttnRes 的演进
Full AttnRes 在理论上实现了深度维度的完美注意力聚合,但在大规模模型训练与推理中,面临着难以接受的内存与通信瓶颈,因此团队提出了兼顾性能与效率的Block AttnRes,成为 AttnRes 落地的核心形态。
3.1 Full AttnRes 的瓶颈:O (Ld) 的开销增长
Full AttnRes 要求每一层访问所有前序层的输出,导致
- 内存开销:存储所有层输出的成本随网络深度L和隐藏维度d呈O(Ld)增长;
- 通信开销:在流水线并行训练中,每个阶段需传输所有前序阶段的中间激活值,跨阶段通信成本同样为O(Ld),在当前硬件条件下无法支撑大模型训练。
3.2 Block AttnRes 的设计:分层聚合,降维开销
Block AttnRes 的核心思路是将层划分为块,块内简单聚合,块间注意力检索,实现了开销从O(Ld)到O(Nd)的量级降低(N为块数,通常N≈8):
- 块内累积:将L层划分为N个块,每个块含S=L/N层,块内采用标准残差连接将所有层输出累加为单个块表示
,保留残差的高效性;
- 块间注意力:仅在块级表示之间应用 AttnRes,令牌嵌入h1定义为b0,作为基础信息源;
- 块内精细检索:块内后续层除了关注历史块表示,还会关注块内的部分和bni−1,兼顾块间全局信息与块内局部信息;
- 连续插值特性:块数N可在两个极端之间插值 ——N=L时恢复 Full AttnRes,N=1时退化为标准残差连接,灵活性极强。


实验证明,N≈8时即可恢复 Full AttnRes 的大部分性能增益,且每个标记仅需存储 8 个隐藏状态,大幅降低了内存与通信压力。
四、基础设施优化:让 Block AttnRes 实现大规模落地
为了进一步降低 Block AttnRes 的训练开销与推理延迟,报告提出了一系列系统级的基础设施优化策略,让其成为标准残差连接的 “即插即用” 替代品,实测开销可忽略不计。
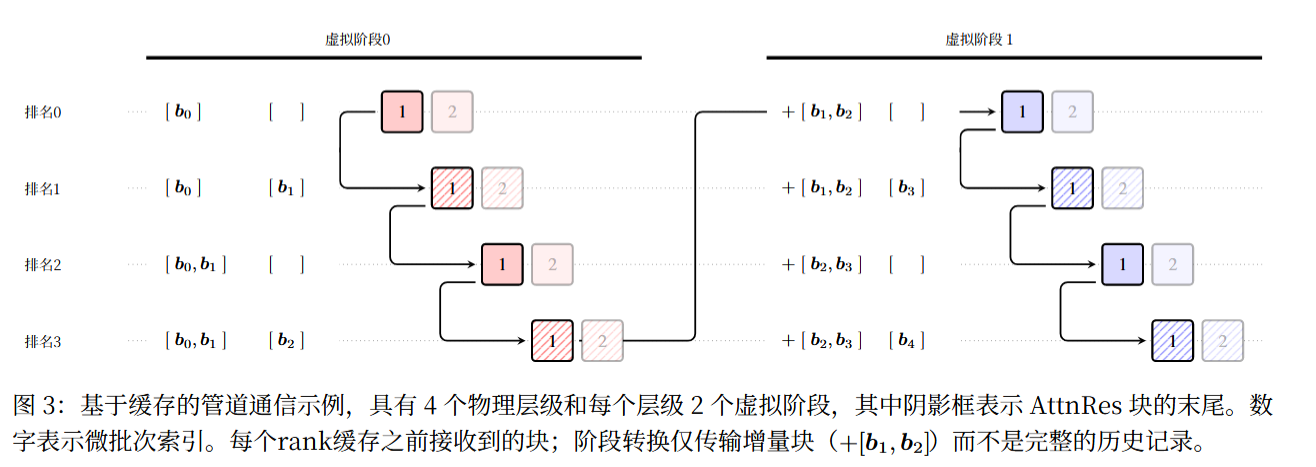
4.1 跨阶段缓存(Cross-stage Caching):解决流水线并行的通信冗余
在流水线并行训练中,传统策略会在阶段转换时传输所有历史块表示,导致大量冗余通信。跨阶段缓存的优化核心是缓存已接收块,仅传输增量块:
- 本地缓存:每个物理设备缓存早期虚拟阶段接收到的块表示,无需重复接收;
- 增量传输:仅在阶段转换时传输自前一虚拟阶段以来新生成的块,而非完整历史;
- 性能增益:将每次转换的峰值通信成本从O(C)降低到O(P)(C为总块数,P为物理阶段数),实现V×(V为虚拟阶段数)的通信效率提升,实测端到端训练开销小于 4%。
4.2 两阶段计算策略:让推理延迟开销低于 2%
Block AttnRes 的逐层注意力计算易导致串行内存访问,两阶段策略通过并行批处理 + 顺序合并,大幅降低内存访问成本,核心利用伪查询向量与输入无关的特性:
- 第一阶段:并行块间注意力:批量计算当前块内所有层对历史块表示的注意力,返回输出与 Softmax 统计信息(max、log-sum-exp),将内存读取次数从S次(S为块内层数)分摊为 1 次;
- 第二阶段:顺序块内聚合:按顺序执行块内每层的计算,实时处理块内残差流,并通过Online Softmax将块内计算结果与第一阶段的块间注意力结果合并;
- 内核融合:Online Softmax 的按元素合并特性,允许与 RMSNorm 等操作进行内核融合,进一步减少 I/O 开销。
该策略让 Block AttnRes 的推理延迟开销低于 2%,完全满足工业级推理的性能要求。此外,报告还提出序列分片预填充方案,将长上下文预填充的设备内存占用从 15GB 降至 0.3GB 以下,解决了长上下文推理的内存问题。
五、实验验证:全尺度性能提升,验证 AttnRes 的有效性
团队通过缩放定律实验、大规模模型预训练、下游任务评估等多维度实验,验证了 AttnRes 的有效性,证明其增益在不同模型尺度、不同任务上均稳定存在。
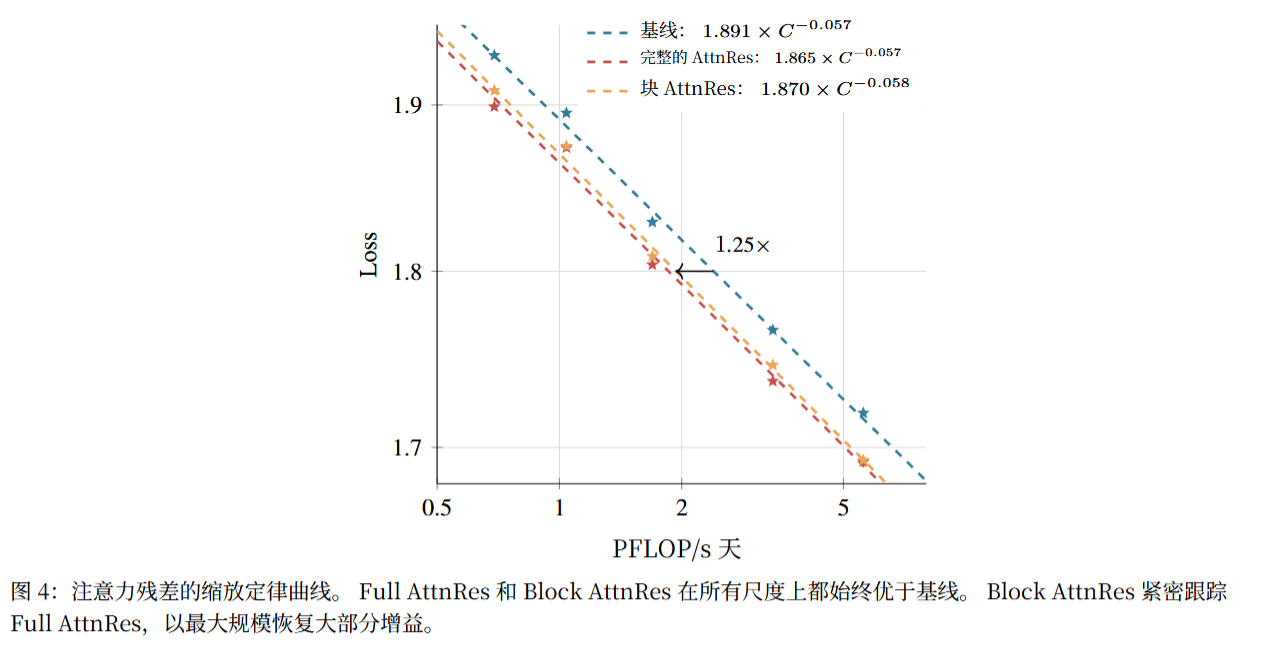
5.1 缩放定律(Scaling Laws):全计算预算的性能优势
团队在5 种不同规模模型(194M~528M) 上训练了 PreNorm 基线、Full AttnRes、Block AttnRes 三种变体,控制超参数一致以保证公平性,拟合形式的幂律曲线(L为验证损失,C为计算量),结果显示:
- 全尺度占优:AttnRes(Full/Block)的曲线始终位于基线下方,在所有计算预算下均实现更低的验证损失;
- 斜率一致:三者的缩放斜率基本相同(≈-0.057),说明 AttnRes 未改变模型的缩放规律,仅在原有基础上提升了性能下限;
- 计算效率提升:根据拟合曲线,Block AttnRes 可提供约1.25 倍的计算效率提升,即相同计算量下,Block AttnRes 的模型性能显著更优;
- Block 逼近 Full:Block AttnRes 的性能紧密跟踪 Full AttnRes,在最大规模模型上几乎无性能损失。
5.2 大规模模型预训练与下游任务性能
将 Block AttnRes 集成到Kimi Linear 48B 模型(54 层、256 个路由专家),在1.4T 令牌上完成预训练,并在多类权威基准测试中评估,结果显示全任务性能提升,尤其在复杂推理任务上表现突出:
- 通用理解与推理:MMLU(73.5→74.6)、BBH(76.3→78.0)、GPQA - 钻石级(36.9→44.4,+7.5),体现了更强的跨层信息整合能力;
- 数学与代码:GSM8K(81.7→82.4)、Math(53.5→57.1,+3.6)、MBPP(72.0→73.9),证明 AttnRes 对多步逻辑推理的提升显著;
- 中文任务:CMLU(82.0→82.9)、C - 评估(79.6→82.5),在中文场景下同样保持稳定增益;
- 人类评估:人类评估得分从 59.1 提升至 62.2,说明模型生成结果的质量更符合人类预期。
AttnRes 仅为模型增加了极少量参数(每层一个伪查询向量 + RMSNorm),却实现了全任务的性能提升,证明其改造的高效性与通用性。
六、深入分析:AttnRes 到底让模型学到了什么?
通过对训练动态和深度注意力权重模式的可视化分析,团队揭示了 AttnRes 性能提升的内在原因,回答了 “模型如何利用深度注意力进行信息聚合” 的问题。
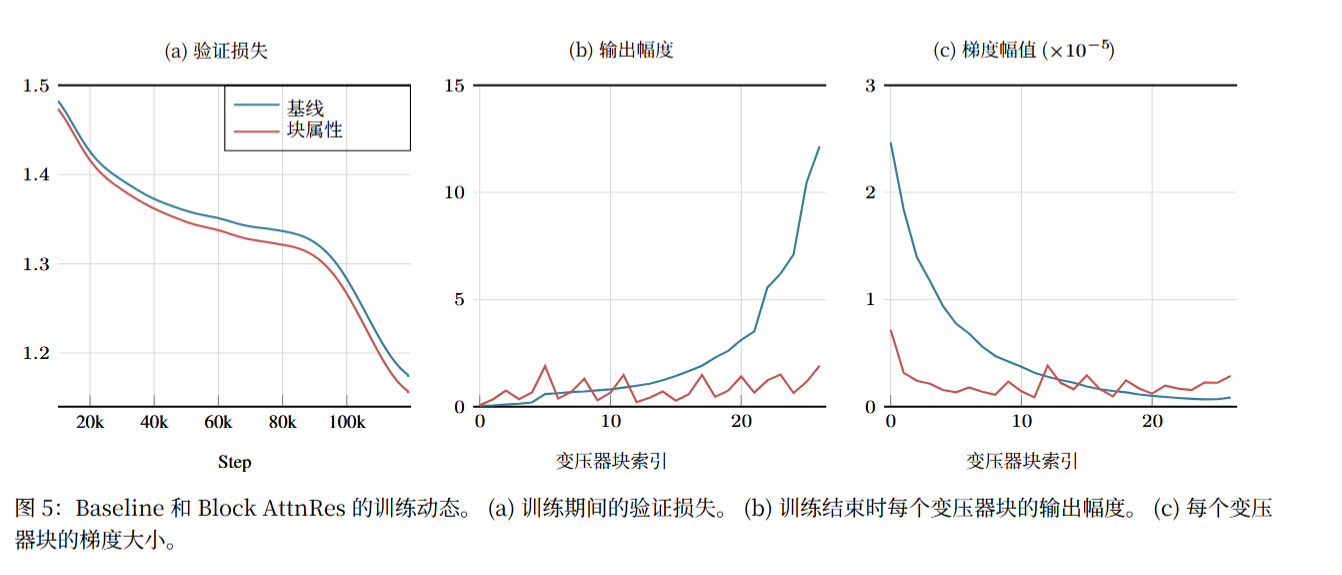
6.1 训练动态的改善:解决 PreNorm 稀释的核心问题
对比 Baseline 与 Block AttnRes 的训练动态,AttnRes 从根本上缓解了 PreNorm 稀释带来的问题:
- 输出幅度有界化:Baseline 的隐藏状态幅度随深度单调增长,而 Block AttnRes 的输出幅度呈现有界的周期性模式,块边界成为信息重置与聚合的节点,避免了幅度失控;
- 梯度分布均匀化:Baseline 中梯度范数在层间分布不均,早期层梯度易过大,而 Block AttnRes 通过可学习的 Softmax 权重引入源层间的概率竞争,让梯度在各层之间分布更均匀,提升了训练稳定性;
- 消除层贡献稀释:AttnRes 让每层可自主选择高贡献的前序层,避免了单层信息被累积总和淹没,提升了层间信息传递的有效性。
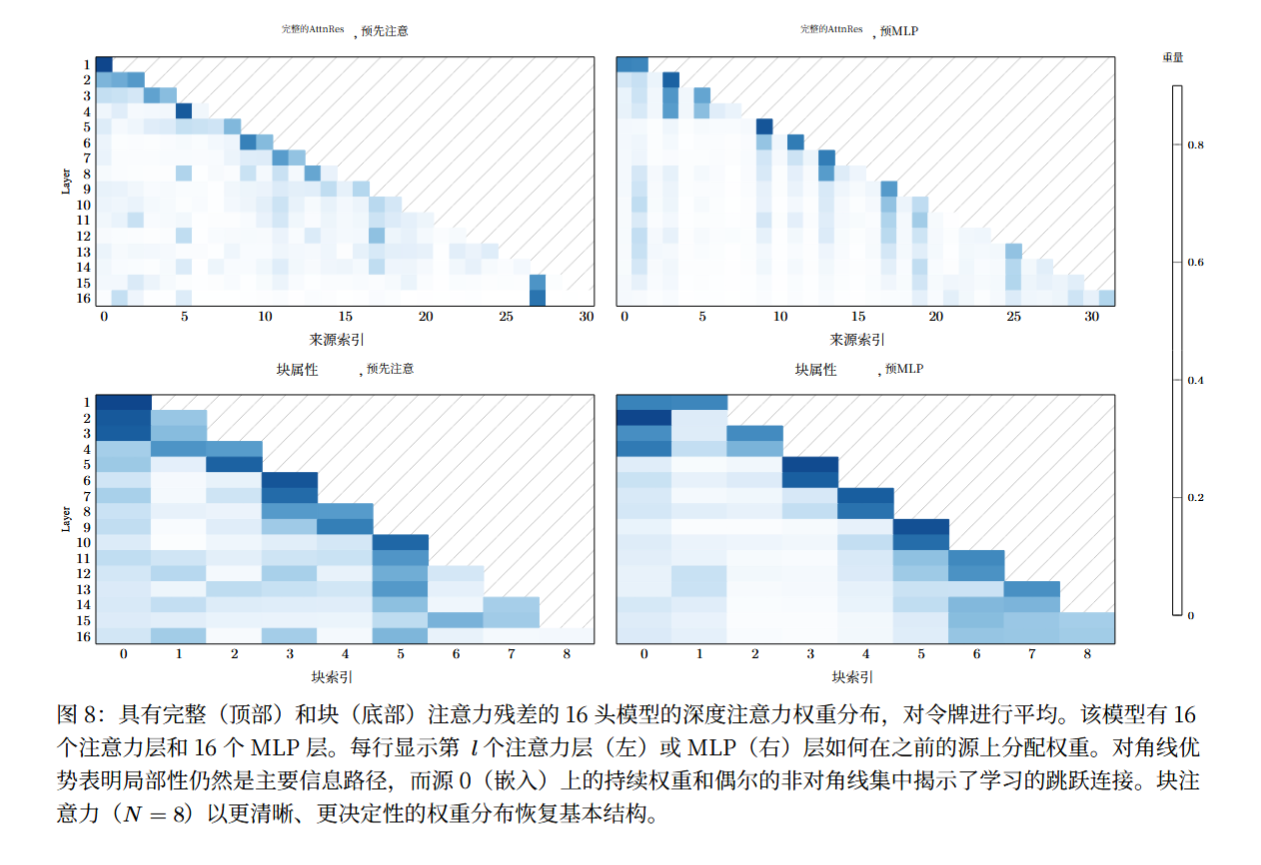
6.2 学习到的深度注意力模式:有选择的信息检索
通过可视化 16 层模型的深度注意力权重热图,团队发现了 AttnRes 学习到的三大核心模式,印证了其选择性信息检索的设计初衷:
- 局部性保留:注意力权重呈现对角线优势,每一层仍然最关注其直接前序层,说明 AttnRes 未破坏残差连接的局部信息传递,保留了模型的基础学习能力;
- 嵌入持久性:令牌嵌入层(源 0)在几乎所有层中都保持较高的注意力权重,证明 AttnRes 确实让模型具备了 “跳回” 检索原始输入信息的能力,解决了早期信息埋藏问题;
- 层专业化:预注意力层的注意力视野更广泛,会关注更多远层信息,而预 MLP 层则更依赖局部信息,体现了模型对不同层功能的专业化适配,与 “注意力路由全局信息、MLP 处理局部特征” 的认知一致;
- 块间强关联:Block AttnRes 的权重分布更清晰、决定性,块间的注意力关联显著,证明块级表示有效聚合了块内信息,实现了全局信息的高效检索。
七、结论与未来方向
7.1 核心结论
注意力残差(AttnRes)是大模型架构设计的一次重要创新,其核心价值体现在:
- 理论突破:揭示了深度与序列的二元性,将 Softmax 注意力从序列维度推广到深度维度,统一了两大维度的信息聚合范式,证明了 “深度方向也需要选择性信息检索”;
- 问题根治:从根本上解决了 PreNorm 稀释问题,通过可学习的、输入相关的深度注意力权重,让模型自主选择前序层信息,提升了层间信息传递效率;
- 工程落地:通过 Block AttnRes 的分块设计,结合跨阶段缓存、两阶段计算等系统优化,将内存 / 通信开销从O(Ld)降至O(Nd),实现了大规模模型的落地,且训练 / 推理开销可忽略不计;
- 性能普适:在不同规模模型、不同类型任务上均实现稳定性能提升,尤其对复杂多步推理、长程信息整合任务的提升显著,具有极强的通用性。
对于研究者而言,AttnRes 的最大启发是:大模型架构设计不应仅关注单一层的特征变换(如 Attention/MLP 的内部结构),更应关注特征如何在深度维度上流转、聚合—— 深度维度的信息交互效率,是制约模型性能的关键因素之一。
7.2 未来方向
随着硬件技术的发展和大模型研究的深入,AttnRes 的后续发展方向清晰且具有潜力:
- 更细粒度的 Block 划分:未来硬件内存限制放宽后,可采用更小的块大小(更大的N),甚至恢复 Full AttnRes,进一步挖掘深度注意力的性能潜力;
- 输入相关的伪查询:目前伪查询为层专属的固定向量,未来可探索输入相关的伪查询(如从当前隐藏状态投影得到),进一步提升注意力的内容感知能力;
- 与其他架构的融合:将 AttnRes 与 MoE、Mamba、线性注意力等前沿架构融合,探索深度注意力在不同模型范式中的适配性;
- 更低复杂度的深度注意力:研究线性复杂度的深度注意力机制,解决 Full AttnRes 的O(L2)计算复杂度问题,实现深度与序列维度的双重线性化;
- 架构重新设计:基于 AttnRes 的深度信息聚合特性,重新设计大模型的深度、宽度、注意力头数等超参数配比,探索更高效的模型架构。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)