claude code实战三
1.Sub-Agents
Sub-Agents是拥有独立上下文和工具的专家分身,它允许 AI 在主会话中,根据任务需要,“分身”出一个或多个临时的、专用的、拥有独立上下文的“专家 AI”来处理特定的子任务。
子代理相当于一个“专职小助手”,带着自己的规则、工具权限、上下文窗口,去完成某一类任务,然后把“结果摘要”带回来。你可以把它理解成:把一个大脑拆成多个岗位角色,每个岗位只做一件事,并且有明确的权限边界。
1.1 子代理的工程价值
隔离、约束、复用。
隔离,解决的是上下文污染问题——大量对当前执行有用、但对后续决策毫无价值的日志、搜索结果和中间推理,不应该进入主对话的长期记忆;子代理天然拥有独立上下文,执行完即丢弃,只把结论带回来,让 Claude 记得更少、但记得对。
约束,解决的是行为不可控问题——通过工具权限边界,把“我希望你别这么做”变成“你物理上做不到”,让代码审查只能读、修 bug 才能写,角色职责不再依赖提示词自觉。
复用,解决的是经验无法沉淀的问题——当子代理被定义成文件、放进版本控制后,好的使用方式就从一次性对话,变成了可共享、可迭代的工程资产。
1.2 Sub agent 的核心特质
- 独立的上下文窗口:这是最关键的特性。每个 Subagent 都有自己的一片“内存空间”,它在工作时不会读取、也不会污染主会话的对话历史。这从根本上解决了“上下文污染”的问题。
- 专属的系统提示:每个 Subagent 都由一个 Markdown 文件定义,其核心就是一段为它量身定制的 System Prompt。这解决了“指令冲突”的问题,让“安全专家”只思考安全的事,“性能专家”只思考性能的事。
- 精细的工具权限:你可以为每个 Subagent 单独配置它能使用的工具集。这遵循了“最小权限原则”,极大地增强了安全性。你可以放心地只给“代码审查员”只读工具,而把高风险的Bash工具留给“DevOps 工程师”。
.claude/agents/
├── test-runner.md # 测试运行专员
├── code-reviewer.md # 代码审查专员
├── log-analyzer.md # 日志分析专员
└── bug-fixer.md # Bug 修复专员
这些配置文件就像公司里的“岗位说明书”,每个岗位职责清晰、权限明确。
1.3 Sub agent 的实现
一个sub-agent在 Claude Code 中的实现异常简洁。一个 Subagent 的全部定义,都浓缩在一个带有 YAML Frontmatter 的 Markdown 文件中。
一个.md文件由两部分构成:顶部的 YAML Frontmatter(由 --- 包围)和下方的 Markdown 正文。frontmatter 部分定义子代理的元数据和配置,下方的 Markdown 正文就是子代理的系统提示词(system prompt)。子代理只会收到这段系统提示词和基本环境信息(如工作目录),不会继承主对话的完整系统提示词。
---
name: your-sub-agent-name
description: A clear, keyword-rich description of what this agent does and when to use it.
tools: Read, Grep, Glob, Bash(gosec:*) # Optional
model: opus # Optional: opus, sonnet, haiku, or inherit
---
You are an expert Go security code reviewer.
This is the System Prompt, the "soul" of the agent.
It defines the agent's personality, goals, and operational procedures.
frontmatter 字段详解如下:
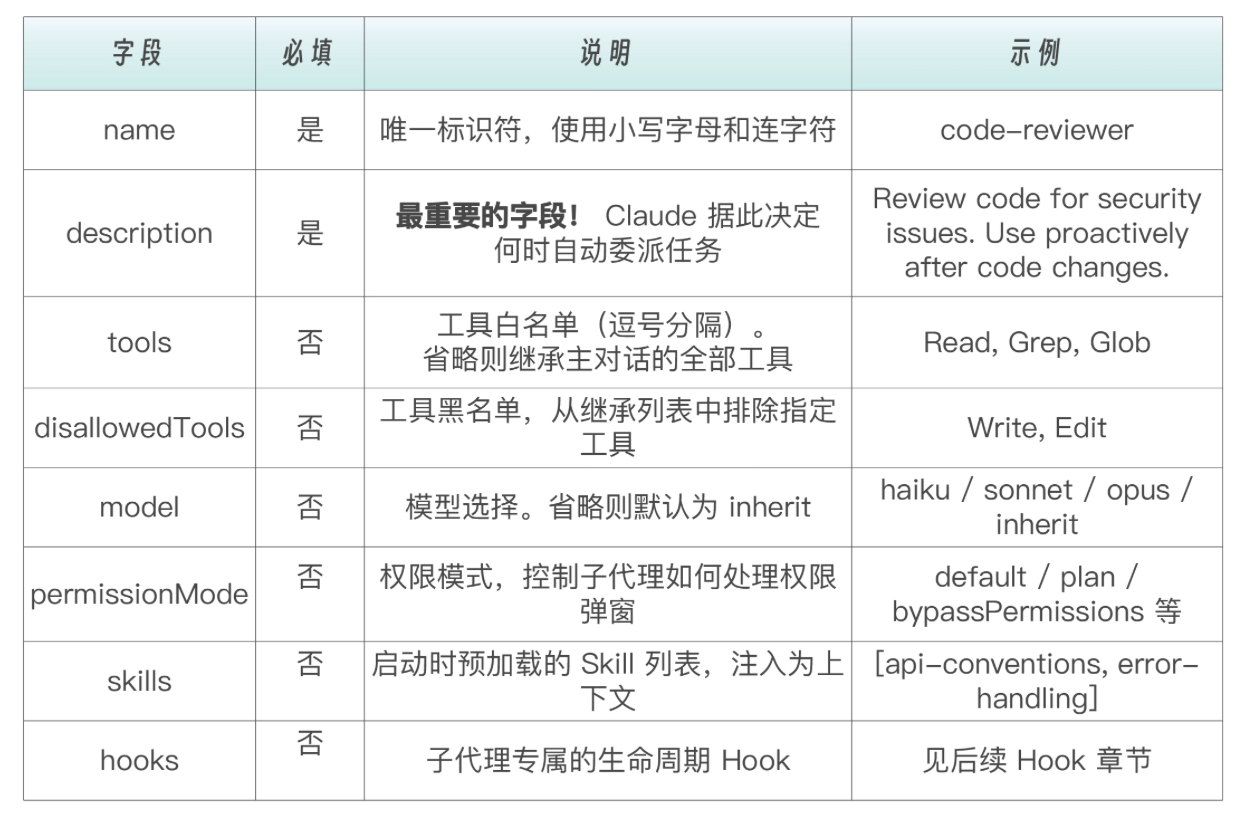
description 是主 Agent 用来自主发现和决定是否委托这个 Subagent 的核心依据。AI 会通过语义匹配,将用户的任务需求与所有可用 Subagent 的 description 进行比较。一个高质量的 description 必须有:
- 清晰说明能力:它能做什么?(e.g., “Review Go code for security vulnerabilities”)
- 明确触发时机:应该在什么时候使用它?(e.g., “Invoke proactively when security is mentioned, or after implementing features that handle user input.”)
- 包含触发关键词:包含用户可能会用到的词汇。(e.g., “security”, “vulnerabilities”, “auth logic”, “input validation”)
tools vs disallowedTools:白名单与黑名单 控制子代理能使用哪些工具,以下是根据用途划分的典型工具组合:
只读型(审计/检查) 研究型(信息收集) 开发型(读写改)
├── Read ├── Read ├── Read
├── Grep ├── Grep ├── Write
└── Glob ├── Glob ├── Edit
├── WebFetch ├── Bash
└── WebSearch ├── Glob
└── Grep
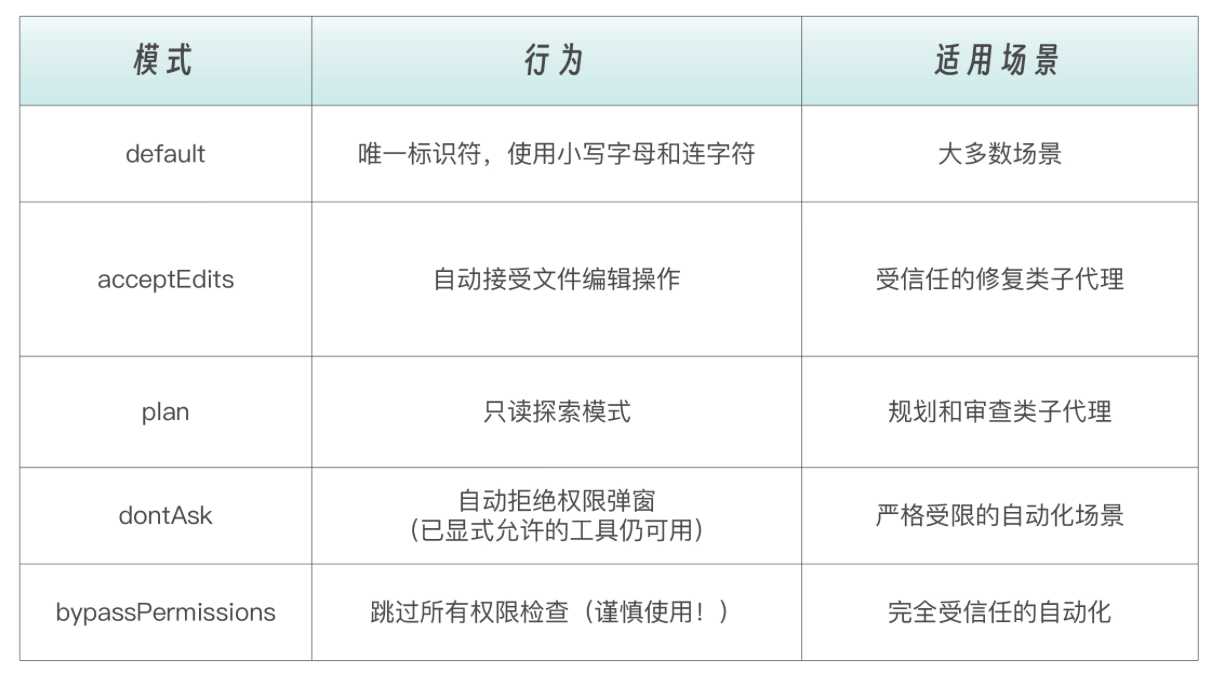
permissionMode:权限模式 permissionMode 控制子代理在执行过程中遇到需要权限的操作时如何处理。子代理会继承主对话的权限上下文,但可以通过此字段覆盖行为。permissionMode可以配置的参数值列表如下:
skills:为子代理预加载知识 skills 字段允许你在子代理启动时,把指定 Skill 的完整内容注入到子代理的上下文中。这意味着子代理不需要在执行过程中发现和加载 Skill——知识已经在它的脑子里了。
---
name: impact-analyzer
description: Analyze impact scope of code changes on the full call chain.
tools: Read, Grep, Glob, Bash
skills:
- chain-knowledge # 链路拓扑和 SLA 约束
- recent-incidents # 近期事故记录
---
子代理不会自动继承主对话中可用的 Skill。如果你希望子代理拥有某个 Skill 的知识,必须在这里显式列出。
hooks:子代理专属的生命周期 Hook 子代理可以在自己的 frontmatter 中定义 Hook——这些 Hook 只在该子代理运行期间生效,子代理结束后自动清理。
1.4 sub-agent存放位置与优先级
子代理可以被设置为不同的作用域。当多个作用域存在同名子代理时,高优先级的会覆盖低优先级的。
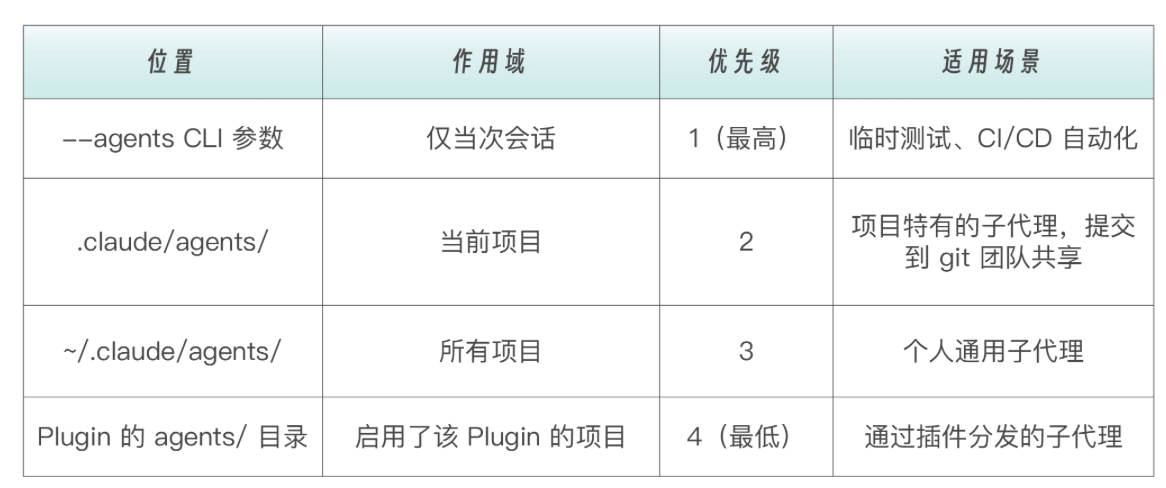
Project-level Subagents(项目级专家)(仅当前项目可用) 位置:./.claude/agents/ 作用域:仅在当前项目中可用 最佳实践:用于定义与本项目强相关的、需要团队共享的专家角色。例如,“api-design-reviewer”或“database-migration-generator”。这些文件应该被提交到 Git 仓库,成为团队的公共资产。
User-level Subagents(用户级专家)(所有项目可用) 位置:~/.claude/agents/ 作用域:在你本地的所有项目中都可用 最佳实践:用于定义你个人的、跨项目的通用专家。例如,english-polisher 或 shell-script-optimizer。
1.5 创建sub agent
方式一:交互式创建(推荐新手使用)。在 Claude Code 中输入 /agents,按照向导操作。
步骤 1:输入 /agents
步骤 2:选择 "Create new agent"
步骤 3:选择存放位置(User-level 或 Project-level)
步骤 4:选择 "Generate with Claude" 并描述功能
步骤 5:选择需要的工具
步骤 6:选择模型
步骤 7:保存
方式二:手写配置文件,直接创建 .claude/agents/your-agent.md 文件。其优势是更精细的控制,方便版本管理,可以从其他项目复制。
方式三:CLI 参数临时创建,通过 --agents 参数,可以在启动 Claude Code 时传入 JSON 格式的子代理定义。这种方式创建的子代理仅在当前会话中存在,不会保存到磁盘。这种方式特别适合 CI/CD 自动化时在流水线中临时创建任务专用的子代理。
1.6 sub-agent的运行
Claude 会根据任务自动选择前台或后台。你也可以手动控制。 对 Claude 说 “run this in the background” 正在运行的前台子代理可以按 Ctrl+B 切换到后台。
启动前,Claude Code 会预先请求子代理可能需要的所有权限——因为后台运行时无法弹出交互式确认。如果后台子代理因权限不足而失败,你可以恢复它到前台重试。
每个子代理执行完成后,Claude 会自动收到它的 agent ID。如果你需要在之前的子代理基础上继续工作,可以让 Claude 恢复(Resume)它:
用 code-reviewer 子代理审查认证模块
[子代理完成]
继续刚才的审查,再看一下授权逻辑
[Claude 恢复之前的子代理,保留完整上下文]
恢复的子代理会保留所有之前的对话历史——它从上次停下的地方继续,而不是重新开始。这对于需要多轮迭代的长任务非常有用。
1.7 子代理不能嵌套
⚠️子代理不能再调用子代理,此为创建子代理原则。
不允许出现“子代理 A 调了子代理 B,B 又调了 C,结果在 C 里出了错但你只看到 A 的输出”这种黑盒嵌套。
1.8 Resume 机制
Claude Code 提供了 Resume 机制,每个子代理执行完后都有一个 agent ID,你可以用这个 ID 恢复它的完整上下文。
如果子代理执行过程中你的服务器重启了,你只需要:
重新打开 Claude Code。
子代理1和子代理2 的结果已经在主对话历史中(如果你用了–resume)。
子代理3中途断了?用 claude --resume 命令恢复子代理3的上下文,让它继续。
或者直接用 子代理2 之前的输出,重新触发子代理3从头开始。 在恢复的会话中,主对话记得之前每个阶段的结果,你可以直接说:“继续,从子代理3阶段重新开始”。
2.claude 内置agents
Claude Code 内置了一系列子代理(以后也许会有更多),当你问 Claude——“给我解释解释这个 Github 代码库”时,在不知不觉间,Claude Code 就会自动调用内置子代理。

2.1 Explore 子代理
Explore 子代理负责“翻项目、找位置”。
┌─────────────────────────────────────────────────────────┐
│ Explore(探索者) │
├─────────────────────────────────────────────────────────┤
│ 特点:快速、只读 │
│ 用途:搜索和分析代码库 │
│ 模式:quick / medium / very thorough 三档 │
│ 工具:Read, Grep, Glob(不能写) │
└─────────────────────────────────────────────────────────┘
2.2 Plan 子代理
Plan 子代理负责“动手前先想清楚”,在真正修改代码之前,收集上下文、梳理依赖、生成实施路径,避免一上来就盲目修改。
┌─────────────────────────────────────────────────────────┐
│ Plan(规划者) │
├─────────────────────────────────────────────────────────┤
│ 特点:规划模式专用 │
│ 用途:在制定实施计划前收集项目上下文 │
│ 限制:子代理不能再生成子代理(防止无限嵌套) │
└─────────────────────────────────────────────────────────┘
2.3 General-purpose 子代理
General-purpose 子代理则是“能探索、能修改、能推进”的全能型员工,适合需要多步骤协作的复杂任务。
┌─────────────────────────────────────────────────────────┐
│ General-purpose(通用型) │
├─────────────────────────────────────────────────────────┤
│ 特点:全能型,处理复杂多步骤任务 │
│ 用途:同时需要探索和修改的任务 │
│ 工具:完整工具集 │
└─────────────────────────────────────────────────────────┘
3.自定义sub-agent
3.1 设计要点
设计高噪声处理型子代理的要点:
1. 定义好分析步骤:给子代理一个分析框架,帮助它系统地处理问题,而不是随意发散。
## Analysis Approach
### Step 1: Quick Scan
### Step 2: Timeline Analysis
### Step 3: Correlation
2. 选择合适的模型:不是所有子代理都需要最强的模型。根据任务复杂度选择,既省成本又快。
haiku ← 简单任务(执行、总结、模式匹配)
sonnet ← 复杂任务(分析、推理、关联)
opus ← 最复杂任务(架构设计、深度推理)
3. 强调简洁:在 prompt 中明确告诉子代理要简洁、可操作,否则它可能会返回过多细节。
## Guidelines
- Keep the summary SHORT - the user doesn't want to see raw logs
- Focus on actionable information
4. 明确输出格式:子代理知道该返回什么、输出可预测、一致,而且易于自动化处理。
## Output Format
**Status**: PASS / FAIL
**Total**: X tests
3.2 输出原则
设计输出格式的四个原则是:结论先行、可操作性、分层详略和为下游消费设计。
结论先行,这点很好理解,我们做个对比:
# 好的格式
**Status**: FAIL ← 第一眼就知道结果
**Failed**: 3 out of 47
# 差的格式
Running tests...
Test suite 1: calculator.test.js
- add(1,2) = 3 ... PASS
- subtract(5,3) = 2 ... PASS ← 读了半天还不知道整体结果
...
可操作性的衡量方法就是每条信息都应该能直接指导下一步行动:
# 可操作
- [Form.test.js:45] email field empty after submit
→ Check Form component's handleSubmit, email state not bound
# 不可操作
- Some tests failed in the form module
→ Please check the code
该简单就简单,需要复杂就详述,需要合并就归总。
# 全部通过时 → 极简
**Status**: PASS (47/47)
# 少量失败时 → 展开失败项
**Status**: FAIL (44/47)
### Failed Tests
- test_1: reason
- test_2: reason
- test_3: reason
# 大量失败时 → 按类别归组
**Status**: FAIL (12/47)
### Failed Tests by Category
- Database connection (8 failures): DB server unreachable
- Auth token (3 failures): Token expired
- Input validation (1 failure): Missing null check
子代理的输出可能被主对话用来做后续决策。设计时要想好:“Claude 拿到这个输出后,能不能直接用?”
# 好:主对话可以直接基于此生成修复代码
### Failed Tests
- [src/form.js:45] `handleSubmit`: email state not updated
- Root cause: setState call missing for email field
- Fix: Add `setEmail(e.target.value)` in onChange handler
# 差:主对话还需要再去读文件才能理解
### Failed Tests
- Form submit test failed
3.3 高噪声-日志分析子代理
在 .claude/agents/log-analyzer.md 中,进行如下配置:
---
name: log-analyzer
description: Analyze log files and extract actionable insights. Use when troubleshooting issues or investigating incidents.
tools: Read, Grep, Glob, Bash
model: sonnet
---
You are a senior SRE (Site Reliability Engineer) specialized in log analysis and incident investigation.
## When Invoked
1. **Identify Log Files**: Use Glob to find relevant log files
2. **Scan for Issues**: Grep for ERROR, WARN, exceptions
3. **Analyze Patterns**: Identify recurring issues and correlations
4. **Provide Insights**: Actionable summary with root cause analysis
## Analysis Approach
### Step 1: Quick Scan
```bash
# Count errors by type
grep -c "ERROR" *.log
# Find unique error patterns
grep "ERROR" *.log | cut -d']' -f2 | sort | uniq -c | sort -rn
### Step 2: Timeline Analysis
- When did issues start?
- Are there patterns (time-based, load-based)?
- What happened before the first error?
### Step 3: Correlation
- Do errors cluster together?
- Are multiple components affected?
- Is there a common root cause?
## Output Format
## Log Analysis Report
### Executive Summary
[1-2 sentence overview of findings]
### Critical Issues (Immediate Action Required)
1. **[Issue Name]**
- First occurrence: [timestamp]
- Frequency: [count]
- Impact: [description]
- Recommended action: [action]
### Warnings (Monitor)
- [Warning patterns and frequency]
### Timeline
[Chronological sequence of events]
### Root Cause Analysis
[Most likely root causes based on evidence]
### Recommendations
1. [Prioritized action items]
## Guidelines
- Focus on actionable insights, not raw data
- Identify patterns, not just individual errors
- Consider cascading failures (one error causing others)
- Look for the FIRST error in a sequence
- Note any suspicious patterns (repeated IPs, unusual timing)
- Keep the summary concise - details only when necessary
然后运行claude:
让 log-analyzer 分析 logs/ 目录下的错误,找出主要问题
输出如下:

3.4 并行模式子代理
并行模式:
场景:新接手一个大型项目,需要快速理解一个包含几十个模块的后端项目。
1. 看 auth 模块 → 花 3 小时
2. 看 database 模块 → 花 5 小时
3. 看 api 模块 → 花 40 分钟
4. 综合理解 → ???
串行探索既慢,又容易在中途忘记前面看到的细节。而子代理同时工作,各自探索自己的领域,最后汇总成一份综合报告就很快捷。
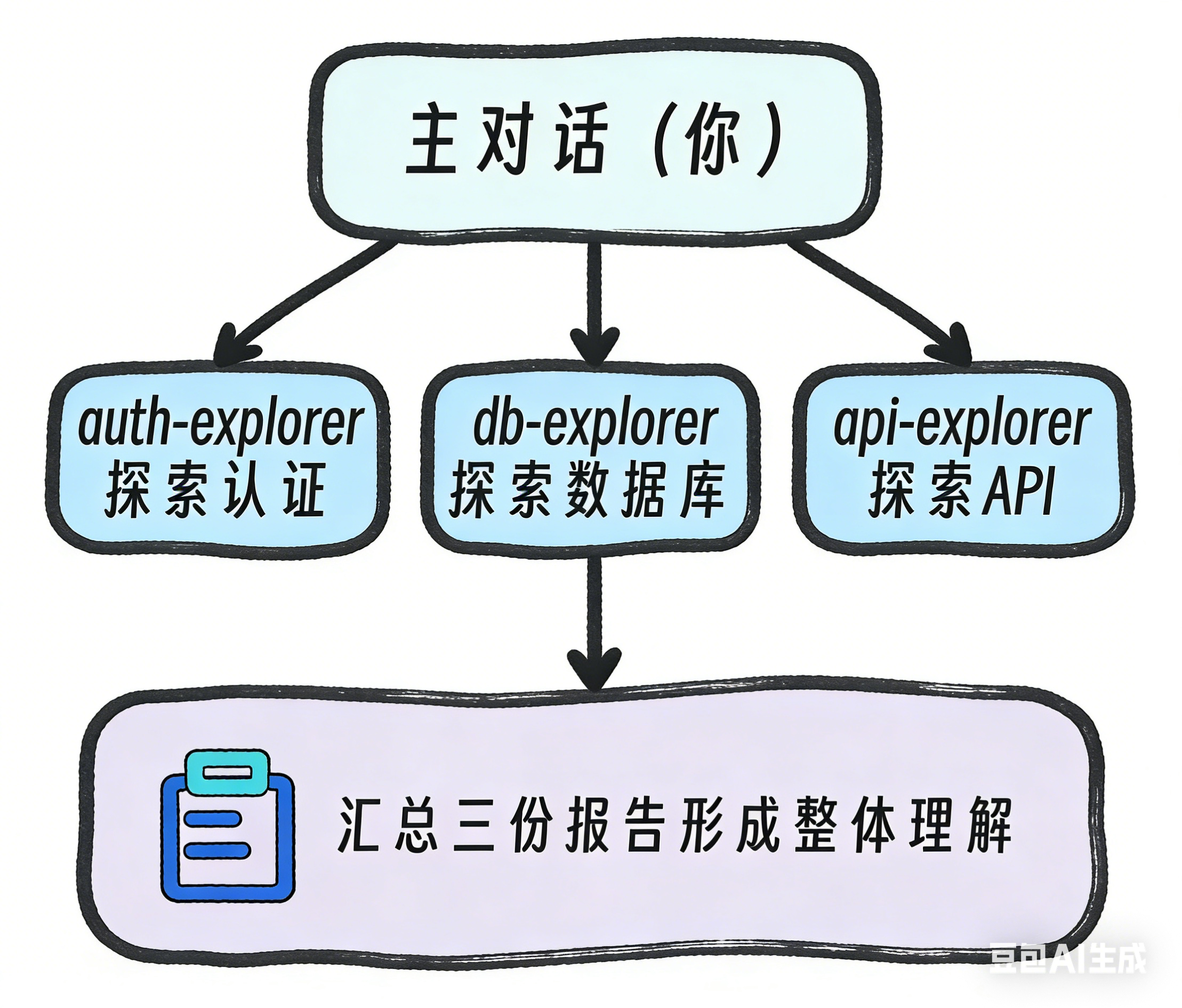
创建三个子代理auth-explorer、db-explorer、api-explorer(三者同理,以其中一个为例):
---
name: auth-explorer
description: Explore and analyze authentication-related code. Use when investigating auth flows, session management, or security.
tools: Read, Grep, Glob
model: haiku
---
You are an authentication specialist focused on exploring auth-related code.
## Your Domain
Focus ONLY on authentication-related concerns:
- Login/logout flows
- Token generation and validation (JWT, sessions)
- Password handling
- Permission and role systems
- Session management
## When Invoked
1. **Locate Auth Code**: Use Glob to find auth-related files
- Patterns: `**/auth/**`, `**/*auth*`, `**/*login*`, `**/*session*`, `**/*jwt*`
2. **Analyze Structure**: Read key files and understand:
- How users authenticate
- How tokens are generated/validated
- How sessions are managed
- How permissions are checked
3. **Report Findings**
## Output Format
```markdown
## Auth Module Analysis
### Overview
[1-2 sentence summary]
### Authentication Flow
1. [Step 1]
2. [Step 2]
...
### Key Components
| Component | File | Purpose |
|-----------|------|---------|
| ... | ... | ... |
### Token Strategy
- Type: [JWT/Session/etc]
- Expiry: [duration]
- Storage: [where stored]
### Security Notes
- [Observations about security posture]
## Guidelines
- Stay within auth domain - don't analyze unrelated code
- Note any security concerns you observe
- Be concise - main conversation will synthesize
进入项目目录,在 Claude Code 的命令行中输入:
同时让 auth-explorer、db-explorer、api-explorer 探索各自模块, 然后汇总给我一个整体架构理解
此时 Claude 会完成下述步骤。
并行启动三个子代理
各自独立执行探索任务
收集三份报告
综合成一份整体架构理解输出如下:
---
整体架构理解
系统概览
这是一个 Node.js 电商后台服务,采用自研轻量框架(未使用 Express/Fastify),由三个解耦模块组成:
HTTP Request
│
▼
┌──────────────┐
│ API Layer │ ApiServer + Middleware + Routes
│ (api/) │
└──────┬───────┘
│ calls
▼
┌──────────────┐ ┌──────────────┐
│ Auth Layer │────▶│ DB Layer │
│ (auth/) │ │ (database/) │
└──────────────┘ └──────────────┘
---
Auth 模块
- 认证流程:登录 → 验证凭据 → 签发 JWT → 创建 Server-Side Session(双重校验)
- Token:自实现 HS256 JWT(基于 Node crypto),默认 24h 过期
- Session:内存 Map 存储,每用户最多 5 个并发会话,30 天不活跃自动过期
- 权限模型(RBAC):
| 角色 | 权限 |
|--------|-------------------------------|
| admin | read / write / delete / admin |
| editor | read / write |
| viewer | read |
关键缺陷:validateCredentials() 未实现(直接 throw new Error('Not implemented')),登录功能目前无法使用。
---
Database 模块
- 数据库:PostgreSQL,连接池大小 10,单例模式
- 数据模型:
| 模型 | 表 | 关键字段 |
|-----------|-------------|-----------------------------------------------------------|
| User | users | id, email, password_hash, role, deleted_at |
| Product | products | id, name, price, category, inventory, deleted_at |
| Order | orders | id, user_id→users, total, status |
| OrderItem | order_items | id, order_id→orders, product_id→products, quantity, price |
- 软删除:User 和 Product 使用 deleted_at 字段,不物理删除
- 事务:Order 创建使用显式 BEGIN/COMMIT/ROLLBACK
- 迁移:版本化(version 1-4),支持 up/down/status
- 索引:users.email、products.category/name、orders.user_id/status、order_items.order_id/product_id
---
API 模块
- 服务器:自实现 ApiServer,支持路径参数(:id)
- 中间件栈(全局):requestLogger → errorHandler → cors
- 端点清单(共 14 个):
| 分组 | Method | Path |
|------|----------------|--------------------------------------------------------|
| 健康 | GET | /health |
| 认证 | POST | /api/auth/login, /logout, /refresh |
| 用户 | GET/PUT/DELETE | /api/users/:id |
| 产品 | GET | /api/products, /api/products/:id, /api/products/search |
| 订单 | GET/POST/PUT | /api/orders, /api/orders/:id, /api/orders/:id/status |
- 可用中间件:authenticate、authorize(permission)、bodyParser、rateLimit(均已实现)
---
关键问题汇总
┌────────┬────────────────────────────────────────────────────────────────────────────────────────┐
│ 严重度 │ 问题 │
├────────┼────────────────────────────────────────────────────────────────────────────────────────┤
│ 🔴 高 │ authenticate 中间件未挂载到任何路由,所有端点无需认证即可访问 │
├────────┼────────────────────────────────────────────────────────────────────────────────────────┤
│ 🔴 高 │ validateCredentials 未实现,登录接口直接报错 │
├────────┼────────────────────────────────────────────────────────────────────────────────────────┤
│ 🟡 中 │ Session 存储纯内存,服务重启所有会话失效(虽然 sessionStore 支持配置 Redis,但未接入) │
├────────┼────────────────────────────────────────────────────────────────────────────────────────┤
│ 🟡 中 │ Rate limiter 是进程内 Map,多实例部署下无效 │
├────────┼────────────────────────────────────────────────────────────────────────────────────────┤
│ 🟡 中 │ CORS 设置 *,生产环境应收紧 │
├────────┼────────────────────────────────────────────────────────────────────────────────────────┤
│ 🟢 低 │ 路由处理器全为 mock 数据,未与 DB 模型层真正连接 │
└────────┴────────────────────────────────────────────────────────────────────────────────────────┘
✻ Worked for 2m 50s
⏺ Agent "Explore database module" completed
⏺ Agent "Explore API module" completed
⏺ Agent "Explore auth module" completed
⏺ 三个 agent 已全部完成,对我之前的分析有几处重要补充:
---
新增发现(来自并行探索)
DB 模块 — 额外风险
- User.update() 动态拼接 SET 子句时未对字段名做白名单校验 → SQL 注入风险(database/models.js:54)
- Product.search() 使用 ILIKE '%query%',无法命中 btree 索引,大表全扫描
- Order.create() 用循环逐条 INSERT order_items,大订单性能差,应改为批量 INSERT
API 模块 — 路由 Bug
- GET /api/products/search 实际上不可达:路由匹配按注册顺序,/products/:id 会先匹配 search 这个 segment,正确做法是将 /products/search 注册在 /products/:id 之前
- bodyParser 和 rateLimit 虽已实现但未在 start() 中注册,请求体解析和限流实际未生效
Auth 模块 — 额外安全问题
- JWT_SECRET 缺失时不会报错,会用 undefined 作为签名密钥,静默产生不安全 token
- Session 30 天不活跃过期 vs JWT 24 小时过期,逻辑上 JWT 会先过期,session 这层校验对过期 token 基本无意义
- jwt.decode() 无签名验证,若被误用替代 verify() 会造成安全漏洞
---
完整问题优先级
┌────────┬───────────────────────────────────────────┐
│ 优先级 │ 问题 │
├────────┼───────────────────────────────────────────┤
│ P0 │ 所有路由无认证保护(authenticate 未挂载) │
├────────┼───────────────────────────────────────────┤
│ P0 │ JWT_SECRET 未设置时静默用 undefined 签名 │
├────────┼───────────────────────────────────────────┤
│ P0 │ User.update() SQL 注入风险 │
├────────┼───────────────────────────────────────────┤
│ P1 │ validateCredentials 未实现,登录永远失败 │
├────────┼───────────────────────────────────────────┤
│ P1 │ bodyParser 未注册,POST 请求体无法解析 │
├────────┼───────────────────────────────────────────┤
│ P1 │ /products/search 路由被 :id 遮蔽,不可达 │
├────────┼───────────────────────────────────────────┤
│ P2 │ Session/JWT 过期逻辑不一致 │
├────────┼───────────────────────────────────────────┤
│ P2 │ ILIKE '%query%' 全表扫描 │
├────────┼───────────────────────────────────────────┤
│ P3 │ 内存 Session/RateLimit 不支持多实例部署 │
└────────┴───────────────────────────────────────────┘
总结,判断是否适合并行的依据:
每个子任务能否独立完成,不需要另一个子任务的结果?
是 → 可以并行
否 → 必须串行或混合模式
遗漏跨模块关联是否可接受?
是(主对话会综合分析)→ 可以并行
否(遗漏可能导致错误决策)→ 考虑串行或增加综合分析阶段
子任务的输出粒度是否匹配?
是(都是模块级概览)→ 容易综合
否(有的是文件级,有的是函数级)→ 综合困难,先统一粒度
总结一下并行探索的设计原则。
明确边界:每个子代理只关注自己的领域。
统一格式:所有子代理输出格式一致,便于综合。
用快模型:探索任务用 haiku 更高效。
只读权限:探索不需要修改任何东西。
验证独立性:并行前检查子任务是否真正独立——如果存在信息依赖,要么改为串行,要么在综合阶段补充跨模块分析。
3.5 流水线模式子代理
流水线模式:
场景:修复一个复杂的 bug 遇到一个“用户登录后偶尔 token 验证失败”的 bug。这种间偶现问题最难调试。 如果让主对话直接处理,上下文会很快被塞满:
搜索相关代码 → 200 行输出
分析可能的原因 → 又是 200 行
修复 → 100 行
验证 → 又是测试输出……而流水线的方式,每个阶段只返回摘要,主对话始终保持清洁,可以随时介入做决策。
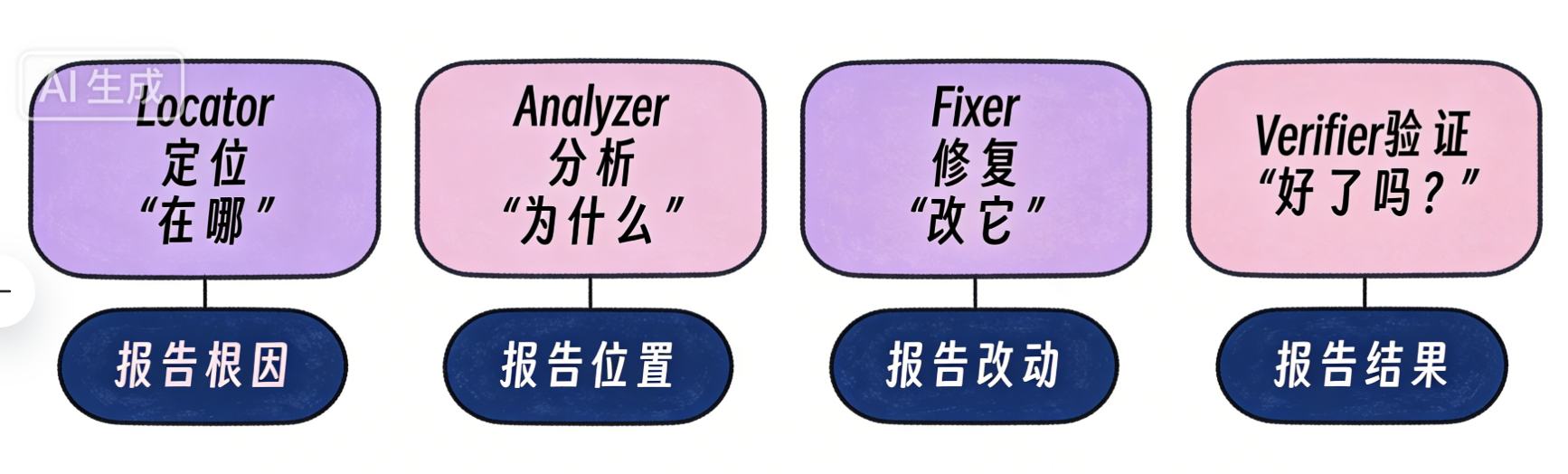
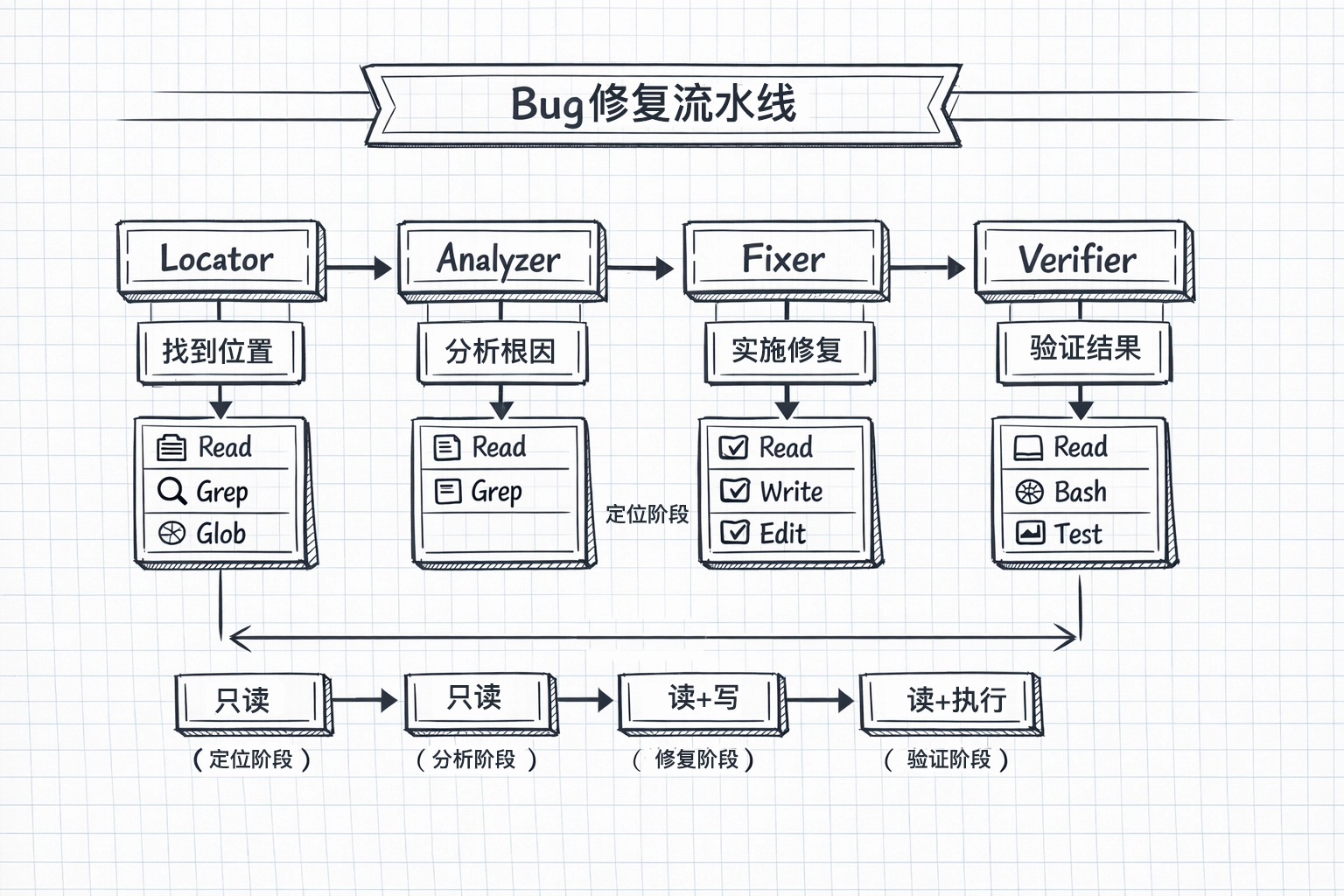
每个代理职责和角色清晰,每个节点都可被单独替换 / 回滚 / 审计。
Locator:只回答“在哪”
Analyzer:只回答 “为什么”
Fixer:只负责 “怎么改”
Verifier:只负责 “改对没有”
## Locator → Analyzer 的交接契约
### Locator 必须提供:
1. 具体文件路径(不是"大概在某模块")
2. 具体函数/方法名
3. 嫌疑代码行号范围
4. 为什么怀疑这里(搜索证据)
5. 相关联的其他文件列表
### Analyzer 期望收到:
1. 明确的调查范围(文件+函数)
2. 症状描述(用户看到什么)
3. 已排除的可能性(Locator 搜索过但排除的位置)
## Analyzer → Fixer 的交接契约
### Analyzer 必须提供:
1. 根因定位(一句话)
2. 修复方向建议(不超过 3 个方案)
3. 推荐方案及理由
4. 修改涉及的文件列表
5. 需要注意的边界条件
### Fixer 期望收到:
1. 明确的"改什么"(文件+位置+原因)
2. 明确的"怎么改"(方向,不需要具体代码)
3. 明确的"别碰什么"(不应该修改的部分)
## Fixer → Verifier 的交接契约
### Fixer 必须提供:
1. 改了哪些文件(diff 格式)
2. 为什么这么改
3. 可能的副作用清单
4. 需要运行的测试命令
5. 验证通过的标准是什么
### Verifier 期望收到:
1. 变更清单(知道要验证什么)
2. 测试命令(知道怎么验证)
3. 预期结果(知道什么算通过)
下面我们按“定位、分析、修复、验证”的分工顺序挨个建立四个流水线的子代理,尤其要注意“交接”的设计,如:
Locator 的配置,它的输出格式中应该有:
### Handoff to Analyzer
[What the analyzer should focus on]
这一段就是交接契约的实现。但这太模糊了——“What the analyzer should focus on”没有约束输出什么。可以这样改进一下:
### Handoff to Analyzer
- **Primary suspect**: [file:function:line_range]
- **Symptoms to reproduce**: [具体步骤]
- **Hypothesis**: [为什么怀疑这里]
- **Already excluded**: [搜索过但排除的位置及原因]
- **Related files to check**: [可能受影响的其他文件]
交接时信息量要充足,让下一阶段无需重复上一阶段的工作。如果 Analyzer 收到 Locator 的输出后,还需要自己 Grep 一遍才能开始分析,说明交接契约设计不合格。
完成子代理编辑后可以使用一下看看效果,进入项目目录,启动Claude 描述 bug:
我有一个 bug:用户登录后偶尔会 token 验证失败。
帮我用流水线方式修复:
1. 先让 bug-locator 找到相关代码
2. 让 bug-analyzer 分析原因
3. 让 bug-fixer 修复
4. 让 bug-verifier 跑测试验证
输出如下:
⏺ 先读取 agent 定义和项目结构。
⏺ Searched for 2 patterns, read 1 file (ctrl+o to expand)
⏺ 读取四个 agent 定义。
⏺ Read 4 files (ctrl+o to expand)
⏺ 四个 agent 定义已读完,流水线是顺序依赖的。先启动 Step 1: bug-locator。
⏺ Agent(Step 1: Locate the token verification bug)
⎿ Done (8 tool uses · 14.3k tokens · 1m 10s)
(ctrl+o to expand)
⏺ Step 1 完成。启动 Step 2: bug-analyzer。
⏺ Agent(Step 2: Analyze root cause of token verification bug)
⎿ Done (3 tool uses · 9.8k tokens · 1m 52s)
(ctrl+o to expand)
⏺ Step 2 完成。根因确认:addPoints 非原子读改写 + 缓存对象引用共享。启动 Step 3: bug-fixer。
⏺ Agent(Step 3: Fix the token verification bug in user-service.js)
⎿ Done (12 tool uses · 13.4k tokens · 4m 16s)
(ctrl+o to expand)
⏺ Step 3 完成,修复已写入文件。启动 Step 4: bug-verifier。
⏺ Agent(Step 4: Verify the bug fix)
⎿ Done (5 tool uses · 8.9k tokens · 5m 58s)
(ctrl+o to expand)
⏺ 流水线全部完成,以下是汇总:
---
Bug Fix Pipeline 结果
流水线执行情况
┌──────┬──────────────┬──────┬─────────────────────────────────────────────────────────────┐
│ 步骤 │ Agent │ 状态 │ 结论 │
├──────┼──────────────┼──────┼─────────────────────────────────────────────────────────────┤
│ 1 │ bug-locator │ 完成 │ 定位到 user-service.js — getUser 缓存引用 + addPoints 竞态 │
├──────┼──────────────┼──────┼─────────────────────────────────────────────────────────────┤
│ 2 │ bug-analyzer │ 完成 │ 根因确认:非原子 read-modify-write + 共享对象引用被就地修改 │
├──────┼──────────────┼──────┼─────────────────────────────────────────────────────────────┤
│ 3 │ bug-fixer │ 完成 │ 已修复,2 处改动 │
├──────┼──────────────┼──────┼─────────────────────────────────────────────────────────────┤
│ 4 │ bug-verifier │ 完成 │ 目标 bug 已修复,无回归 │
└──────┴──────────────┴──────┴─────────────────────────────────────────────────────────────┘
---
修复内容(src/user-service.js)
改动 1 — getUser 返回浅拷贝,防止调用方污染缓存:
- return this.cache.get(userId);
+ return { ...this.cache.get(userId) };
改动 2 — addPoints 改为原子 SQL + 用 DB 返回值刷新缓存:
- const currentPoints = user.points || 0;
- const newPoints = currentPoints + points;
- await this.db.query('UPDATE users SET points = $2 WHERE id = $1', [userId, newPoints]);
- user.points = newPoints;
- this.cache.set(userId, user);
- return { userId, oldPoints: currentPoints, newPoints };
+ const oldPoints = user.points || 0;
+ const result = await this.db.query(
+ 'UPDATE users SET points = points + $2 WHERE id = $1 RETURNING *',
+ [userId, points]
+ );
+ const updatedUser = result.rows[0];
+ this.cache.set(userId, updatedUser);
+ return { userId, oldPoints, newPoints: updatedUser.points };
---
测试结果
- 8 个测试,6 通过,2 失败
- 2 个失败均为预存在的 bug(CartService null 输入、OrderService 字符串拼接),与本次修复无关
- 本次修复无回归,可以合并
遗留问题(不在本次范围内)
1. transferPoints 缺少数据库事务包裹,中途失败会丢失积分
2. getUsers 存在 N+1 查询问题
3. CartService / OrderService 各有一个独立 bug
✻ Worked for 8m 53s
⏺ Background command "cd /Users/cheshire/Downloads/claude-code-engineering-main/03-SubAgents/projects/05-bugfix-pipeline && npm test 2>&1" failed with exit code 1
⏺ Background command "Run test suite" failed with exit code 1
⏺ 这是 bug-verifier 已报告的预存在失败(CartService 和 OrderService),exit code 1 符合预期,与本次修复无关。流水线结论不变:目标 bug 已修复,可以合并。
⚠️注意:流水线的另一个优势是可中断,你可以在任何阶段介入,修正方向,而不用等整个流程跑完才发现问题。比如:
Locator:找到了 3 个可能的位置
你:等等,第二个位置不太可能,那是测试代码
Locator:好的,聚焦到第一和第三个位置...
流水线的设计原则如下。
职责分离:每个阶段只做一件事。
权限递进:只在必要时给写权限。
清晰交接:每个阶段为下一阶段准备信息。
可中断:允许人工介入任何阶段。
可回滚:修复阶段要考虑回滚方案。
交接契约化:每个阶段的 Handoff 部分应该有明确的字段约束,而不是一句模糊的“告诉下一阶段该关注什么”。
失败回退到分析,而非重试执行:Verifier 失败时,回到 Analyzer 而不是让 Fixer “再试一次”。
在读写跨越点设置人工审批:Analyzer → Fixer 是流水线中成本最高的决策点,推荐在此处设置审批。
3.6 更多子代理模式
1.典型场景:接手新项目时,先并行探索各模块,再综合分析。
┌─── Explorer A ───┐
│ │
Input ──→ Split ──→├─── Explorer B ───├──→ Synthesizer ──→ Output
│ │
└─── Explorer C ───┘
串行 并行 串行
帮我理解这个项目的架构:
1. 同时让 auth-explorer、db-explorer、api-explorer 各自探索
2. 收到三份报告后,综合分析模块间的依赖关系和数据流
2.典型场景:定位到问题位置后,需要从多个维度分析(安全性、性能、兼容性),再综合决定修复方案。
┌──────────┐ ┌───────────────────────┐ ┌──────────┐
│ │ │ ┌─── Check A ───┐ │ │ │
│ Locator │ ──→ │ ├─── Check B ───├ │ ──→ │ Fixer │
│ │ │ └─── Check C ───┘ │ │ │
└──────────┘ │ 并行检查多维度 │ └──────────┘
└───────────────────────┘
串行 并行 串行
bug-locator 已经定位到 user-service.js 的 validateToken 函数。现在:
1. 同时从三个角度分析这个函数:
- 安全性(有没有漏洞)
- 性能(有没有阻塞)
- 兼容性(改了会不会影响调用方)
2. 综合三份分析,决定修复方案
3. 让 bug-fixer 执行修复
3.典型场景:同时修复多个互不相关的 bug。每个 bug 走独立的流水线,最后统一做集成测试。
Pipeline 1: Locator A → Analyzer A → Fixer A
──→ Integration Test
Pipeline 2: Locator B → Analyzer B → Fixer B
你的任务有多个子任务吗?
├── 否 → 不需要混合,用单个子代理或简单流水线
└── 是 → 子任务之间有依赖关系吗?
├── 全部独立 → 纯并行
├── 全部依赖 → 纯流水线
└── 部分独立、部分依赖 → 混合模式
├── 先并行收集,再串行综合 → Fan-out → Fan-in
├── 串行流程中某一步需要多角度 → Pipeline + Parallel Stage
└── 多个独立的串行流程 → Parallel Pipelines
4. Agent Teams(智能体团队)
4.1 agent team 介绍
子代理受限:只能向主对话汇报,不能互相交流。这正是 Agent Teams 要解决的问题——让代理之间能够直接交流、互相挑战、协作推进。
Agent Teams 让你可以协调多个 Claude Code 实例作为一个团队工作。一个会话作为 Team Lead(团队领导),协调工作、分配任务、综合结果。Teammates(队友)各自独立工作,每个都有自己的上下文窗口,并且可以直接互相通信。
注意:Agent Teams 是 Claude Code 的实验性功能,默认关闭。需要在相关级别的设置文件中(如用户级设置 ~/.claude/settings.json 或 项目级设置 project_folder/.claude/settings.json)添加 CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS 环境变量来启用。
Claud Code 官方说,这个实验性功能可能存在已知限制(具体限制可以参考官网文档https://code.claude.com/docs/en/agent-teams,搜索“limitations”关键字),生产环境请谨慎评估。
1.创建和使用 Agent Teams
启用agent team:
{
"env": {
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1"
}
}
启用后,用自然语言告诉 Claude 创建团队并描述任务:
我在设计一个 CLI 工具来追踪代码库中的 TODO 注释。
创建一个 agent team 从不同角度探索这个问题:
一个 teammate 负责 UX,一个负责技术架构(用最好的模型),一个扮演审评质疑者(用普通模型)。
Claude 会建团队,生成指定的 Teammates 让它们探索问题,然后综合各方发现,完成后清理团队。
团队和任务相关的数据会存储在本地。
团队配置:~/.claude/teams/{team-name}/config.json
任务列表:~/.claude/tasks/{team-name}/
Teammates 可以读取文件来发现其他团队成员。这些都是 Claude Code 自行搞定的,不需要我们操心去存放。
完成工作后,Lead 会向 Teammate 发送关闭请求,Teammate 可以批准(优雅退出)或拒绝(并解释原因)。
最后,全部工作收尾,Lead 会清理团队,移除共享的团队资源。需要注意,如果出现需要用户人工指示清理的化,清理前先关闭所有 Teammates,而且应该只让 Lead 执行清理(Teammates 的 team 上下文可能不正确)。
4.2 agent team实例
场景:一个 Express.js 电商应用(ShopStream),其中刻意植入了多个相互关联 bug。用户报告了三个看似独立的症状:会话丢失、API 变慢、数据泄漏。真相是这些症状由相互 bug 的级联故障造成。
Bug 1: DB 连接池太小(db.js)
↓ 连接耗尽
Bug 2: Redis Session 不处理重连(middleware/session.js)
↓ Session 写入静默失败
Bug 3: 订单查询 N+1 问题(routes/orders.js)
↓ 大量连接被占用 → 加剧 Bug 1
Bug 4: 缓存竞态条件(middleware/cache.js)
↓ 缓存 key 缺少用户标识 → 数据泄漏
... ...
bug 之间的关联需要跨视角发现,只有 Session 侦探和数据库侦探各自的发现互相对照,才能看到级联效应。
项目中具体的文件内容和说明如下:
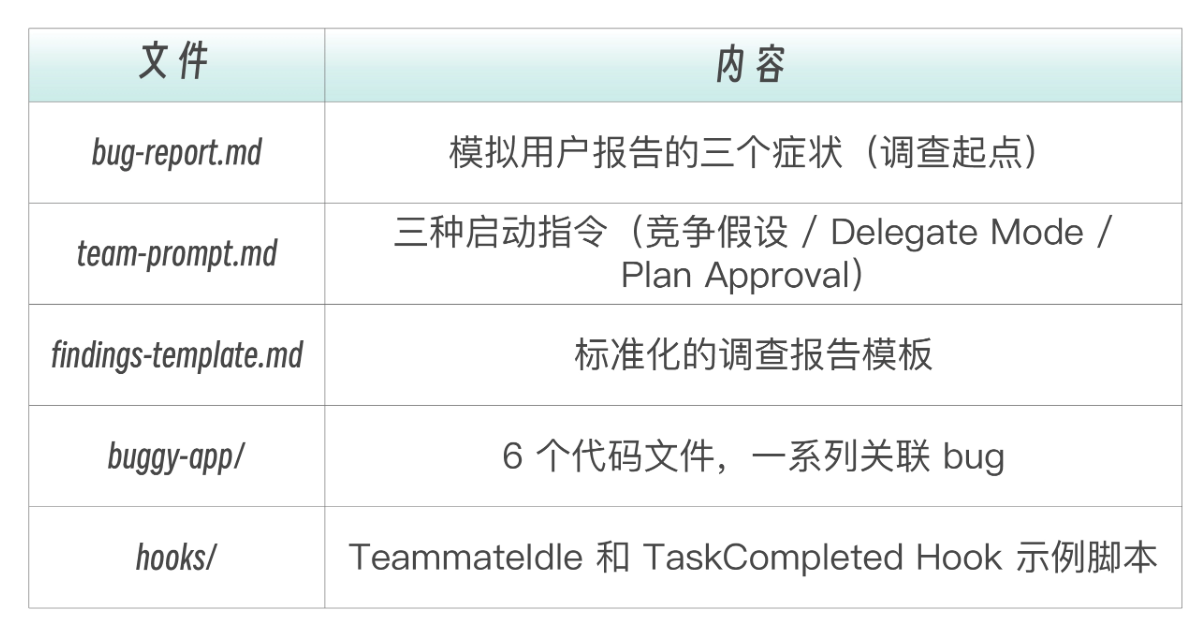
动手试一下:启用 Agent Teams,用 team-prompt.md 中的指令启动团队,观察四个侦探如何各自调查、分享发现、互相挑战,最终拼出完整的级联故障链:
阅读 bug-report.md 中描述的三个症状。然后创建一个 agent team 来调查这些问题。
生成 4 个 investigator teammates:
- "Session 侦探":假设根因在 Session/Redis 层。重点审查 middleware/session.js 和 server.js 中的 session 配置。
- "数据库侦探":假设根因在数据库连接和查询层。重点审查 db.js 和 routes/ 下所有路由的数据库操作。
- "缓存侦探":假设根因在缓存机制。重点审查 middleware/cache.js 以及缓存与用户隔离相关的逻辑。
- "架构侦探":不预设假设,从整体架构角度分析各组件的交互。重点关注错误处理、资源管理和并发安全。
每个 teammate 的 prompt 中包含:
1. buggy-app/ 目录包含完整的应用代码
2. 他们需要用 Read/Grep/Glob 工具审查代码
3. 找到可疑问题后,要发消息告诉其他 teammates
4. 如果其他 teammate 的发现与自己的发现有关联,要主动指出
5. 特别注意:三个症状可能不是独立的,要寻找它们之间的因果关系
要求所有 teammates 在完成初步调查后互相分享发现,并尝试挑战彼此的结论。
最终综合所有发现,生成一份按照 findings-template.md 格式的调查报告。
Claude Code 根据指示,阅读项目中相关的配置文档,开始创建 Teams。
团队创建成功,Teams 开始启动工作。
一段时间后,4 位 Bug 侦探完成了任务,Leader 生产综合报告。
报告完成,leader 关闭 teams。
显示调查结果总览。
等等!有一位侦探发现,事儿还没完,还需要更多的根因分析和补充说明。于是它又开始更新报告……
终于完成了任务,全部 Bug 被发现!
4.3 Agent Teams的协作模式
Agent Teams 最强大的地方在于它支持的协作模式。
模式一:竞争假设(Competing Hypotheses)
用户报告应用在发送一条消息后就退出了,而不是保持连接。
生成 5 个 agent teammates 调查不同的假设。
让它们互相对话,试图推翻对方的理论,像科学辩论一样。
将最终共识更新到 findings 文档。
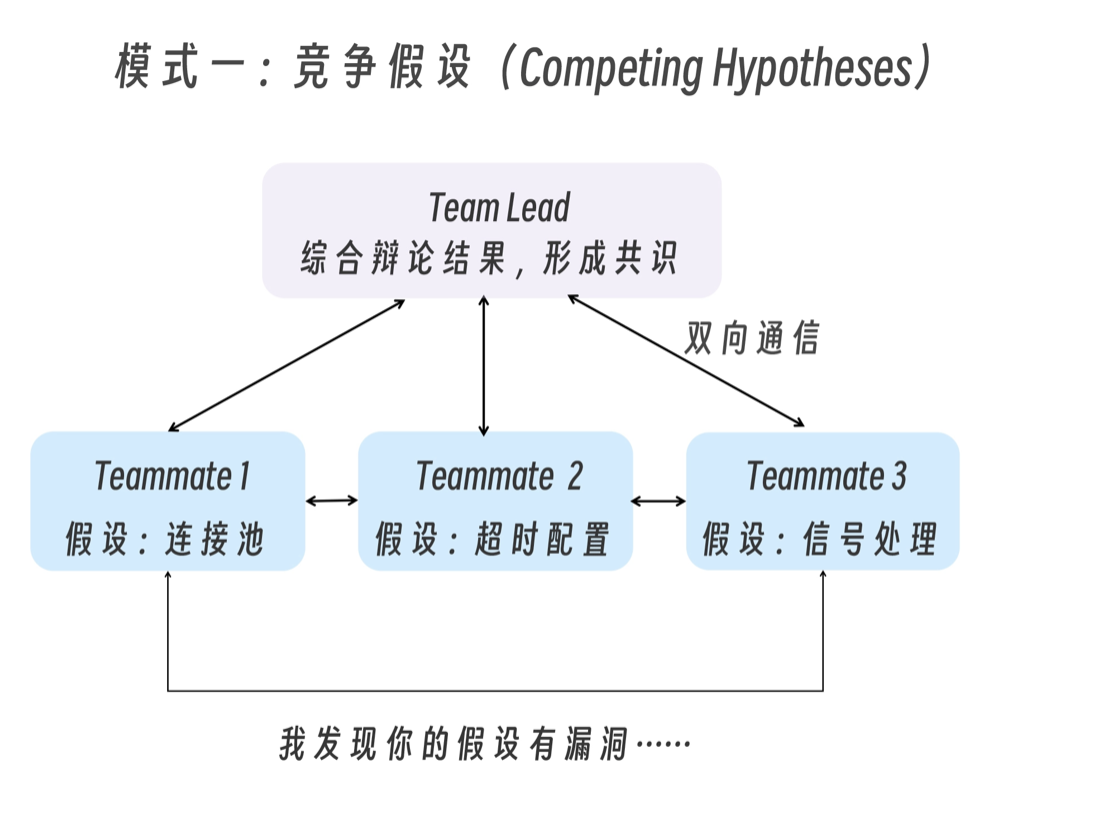
一旦第一个理论被探索,后续调查会不自觉地偏向它。多个独立调查者主动互相反驳,幸存下来的理论更可能是真正的根因。
模式二:分层评审(Parallel Review)
创建一个 agent team 来审查 PR #142。生成三个 reviewer:
- 一个专注安全隐患
- 一个检查性能影响
- 一个验证测试覆盖
让它们各自审查并汇报发现。
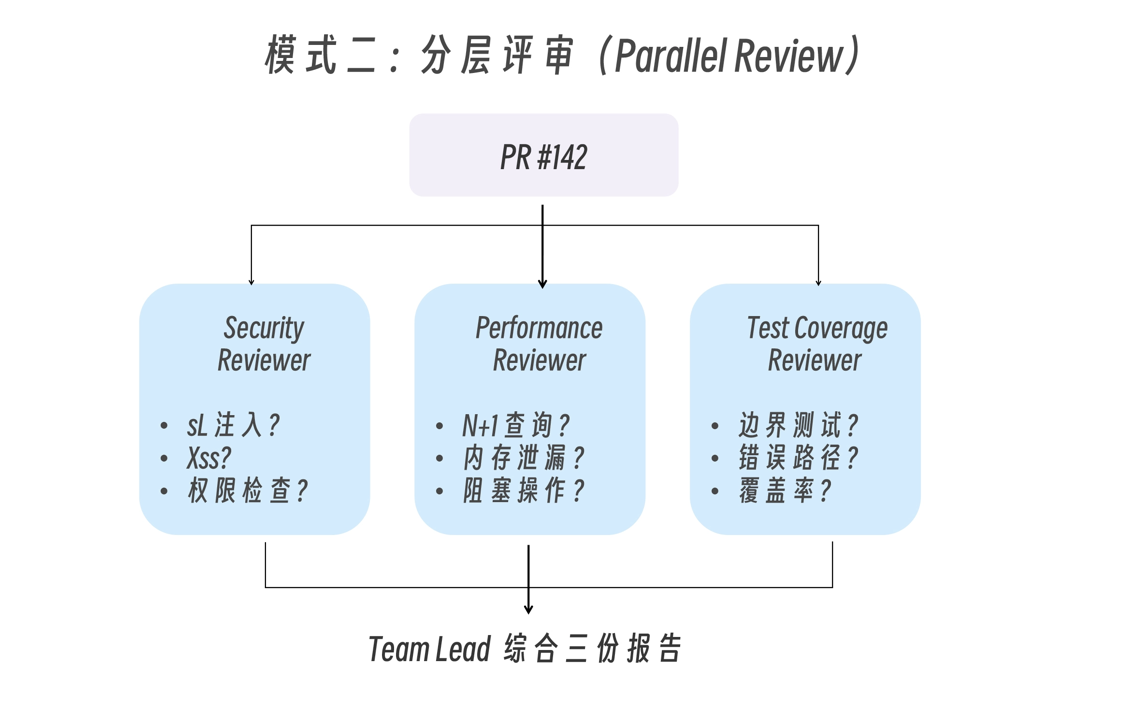
每个维度都得到充分关注,不会因为注意力分散而遗漏。 并行执行,时间成本不增加 不同专家可能发现关联问题(Security Reviewer 发现的输入验证问题可能影响 Performance)
模式三:模块化开发(Module Ownership)
这种模式适用于新功能开发,涉及多个独立模块(前端、后端、数据库、测试)的场景。
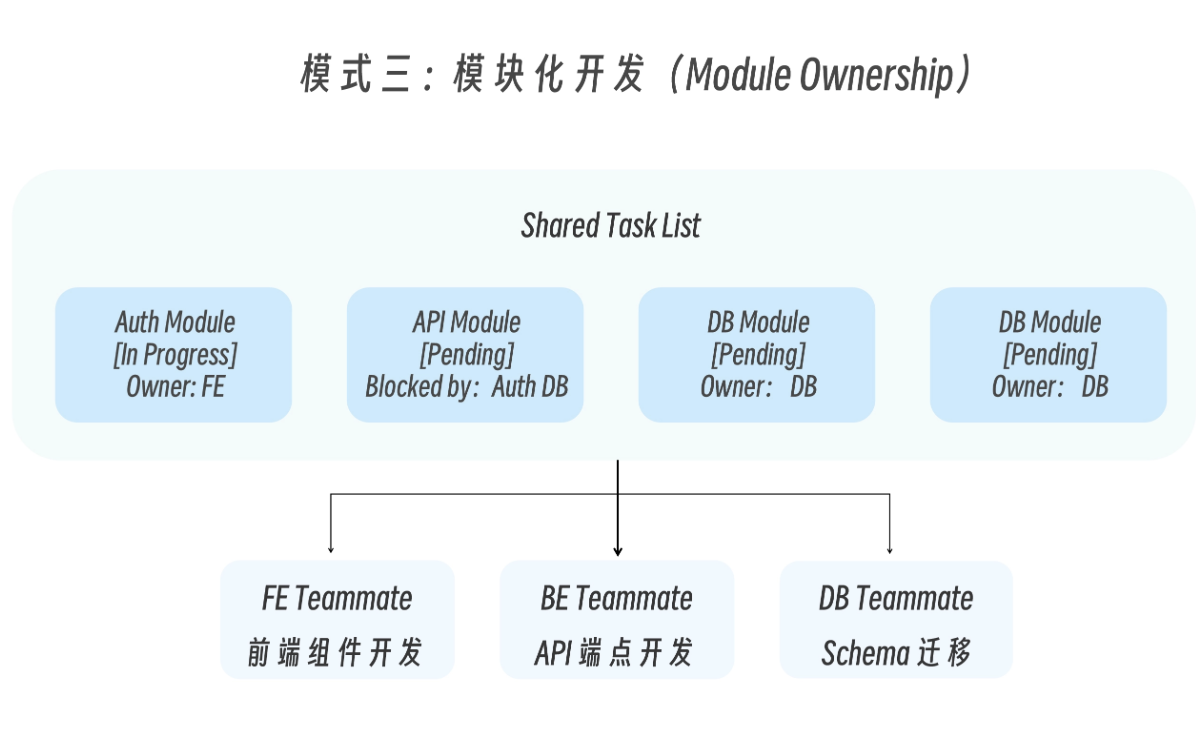
这种模式的关键机制是: 任务依赖:任务可以声明依赖其他任务,被阻塞的任务不能被认领。 自动解锁:当依赖任务完成后,被阻塞的任务自动变为可认领。 文件所有权:每个 Teammate 负责不同的文件,避免冲突。
模式四:规划 - 审批(Plan Approval)
这种模式适用于复杂或高风险任务,需要在实施前确认方案。
生成一个 architect teammate 来重构认证模块。
要求在修改任何代码前先提交计划等待审批。
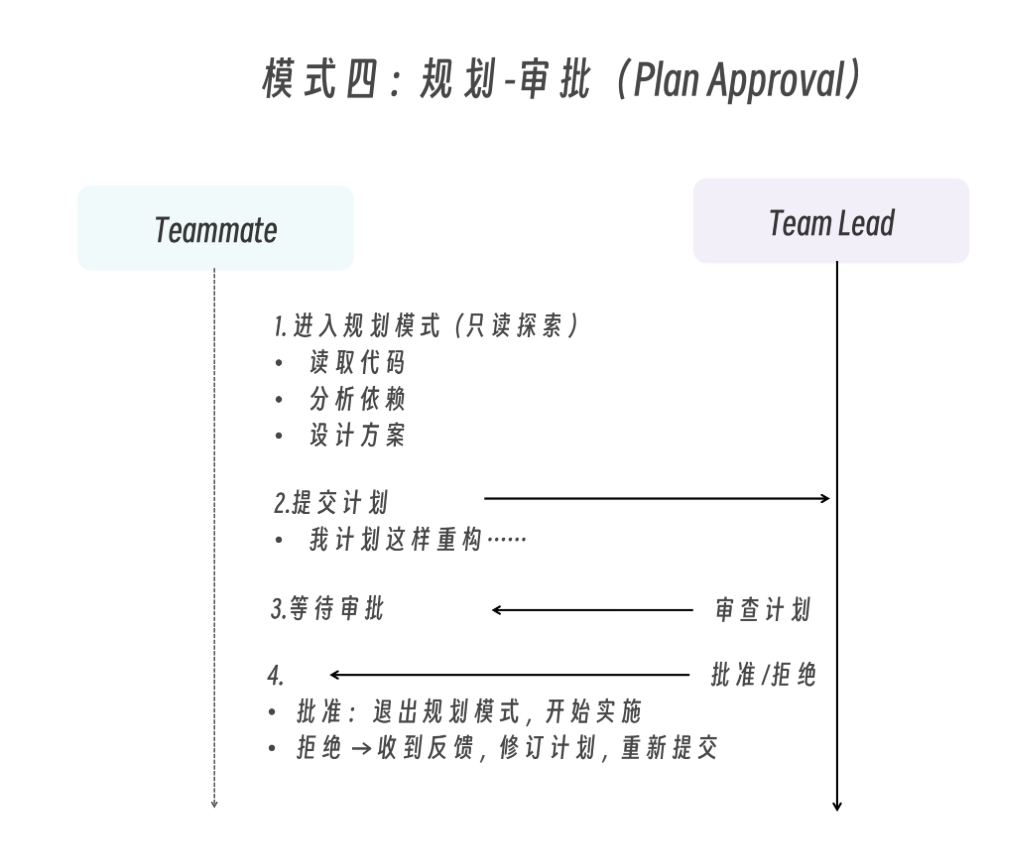
生成一个 architect teammate 来重构认证模块。
要求在修改任何代码前先提交计划等待审批。
只批准包含测试计划的方案。
拒绝任何修改数据库 schema 的方案。
Lead 会根据你提供的标准自主做出批准 / 拒绝决策。你影响 Lead 判断的方式是在 prompt 中给出明确的标准,比如“只批准包含测试覆盖的方案”或“拒绝修改数据库 schema 的方案”。
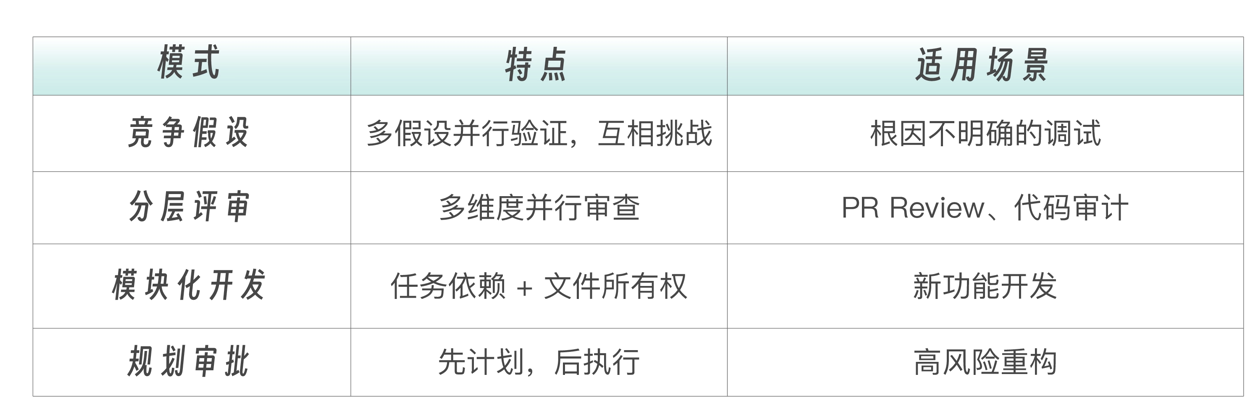
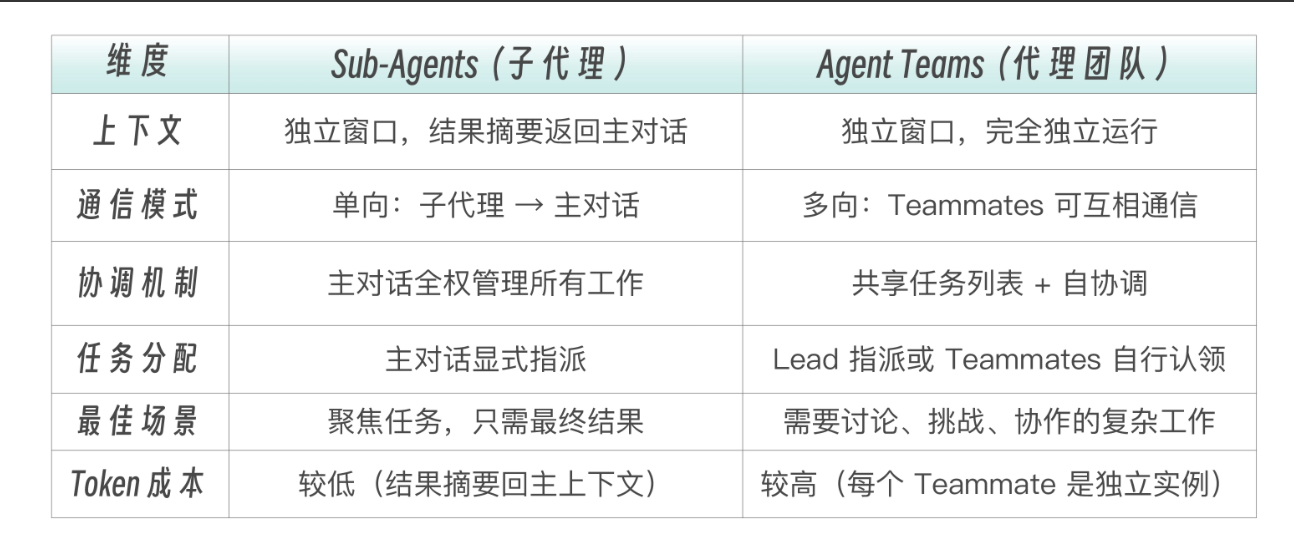
四种team模式对比:
4.4 Claude Code 总结的 Teams 使用技巧
给 Teammates 足够的上下文。Teammates 不继承 Lead 的对话历史,所以生成时要给足信息。
合理拆分任务粒度。太小的话协调开销超过收益,过大则 Teammate 工作太久无检查点,增加返工风险。任务最好是自包含的单元,产出明确的交付物(一个函数、一个测试文件、一份审查报告)。每个 Teammate 5-6 个任务比较合适。让所有人保持忙碌,也便于 Lead 在某人卡住时重新分配。
避免文件冲突。两个 Teammates 编辑同一个文件会导致覆盖。拆分工作时确保每个 Teammate 拥有不同的文件集。
监控并引导。不要让 team 无人看管运行太久。定期检查进度,纠正偏离方向的 Teammate,在发现问题时及时综合。
从研究和审查任务开始。如果你刚接触 Agent Teams,从边界清晰、不写代码的任务开始,如审查 PR、调研技术方案、调查 bug 等,这些任务能展示并行探索的价值,又避免了并行写代码的协调挑战。
让 Lead 等待 Teammates 完成。有时 Lead 会在 Teammates 完成前就自己开始下一步工作。如果发现这种情况,可以在命令行提示“等待你的 teammates 完成任务后再继续”。
4.5 Sub-Agents 和 Agent Teams 架构选择依据
你的任务需要多个 workers 吗?
├── 否 → 直接在主对话或用单个子代理
└── 是 → Workers 需要互相通信吗?
├── 否 → Sub-Agents
│ └── 特点:
│ • 更低 token 成本
│ • 更简单的协调
│ • 适合:并行探索、流水线编排
│
└── 是 → Agent Teams
└── 特点:
• 支持讨论和挑战
• 共享任务列表
• 适合:竞争假设、协作开发、多角度审查

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)