PyTorch深度学习模型搭建⼊⻔总结
第一部分:PyTorch入门必备基础知识
PyTorch是Facebook推出的开源深度学习框架,简洁易用、灵活性高,适合新手入门搭建深度学习模型。掌握以下基础知识,是顺利搭建模型的前提,重点围绕“核心概念、环境准备、基础操作”展开,避免复杂理论,聚焦实操所需。
1.1 核心概念(小白必懂,无需深入推导)
-
Tensor(张量):PyTorch的核心数据结构,相当于“多维数组”,是模型输入、输出及参数的载体,类比NumPy的ndarray,但支持GPU加速(深度学习核心优势)。
-
常见类型:标量(0维张量)、向量(1维张量)、矩阵(2维张量)、高维张量(3维及以上,如图片数据为3维:通道数×高度×宽度)。
-
核心属性:shape(张量形状,如(3,32,32)代表3通道、32×32像素图片)、dtype(数据类型,常用torch.float32、torch.int64)、device(运行设备,cpu或cuda)。
-
-
GPU加速:深度学习模型训练耗时久,GPU(显卡)可大幅提升运算速度,PyTorch中只需将张量和模型“移动”到cuda设备即可启用(需电脑有独立显卡且安装对应CUDA)。
-
自动求导(Autograd):PyTorch的核心功能,无需手动计算梯度,通过torch.autograd自动追踪张量的运算过程,计算模型参数的梯度,用于后续参数更新(模型训练的核心步骤)。
-
模型(Module):PyTorch中所有深度学习模型都需继承nn.Module类,通过定义forward(前向传播)方法,实现输入数据的处理和输出,是搭建模型的固定模板。
-
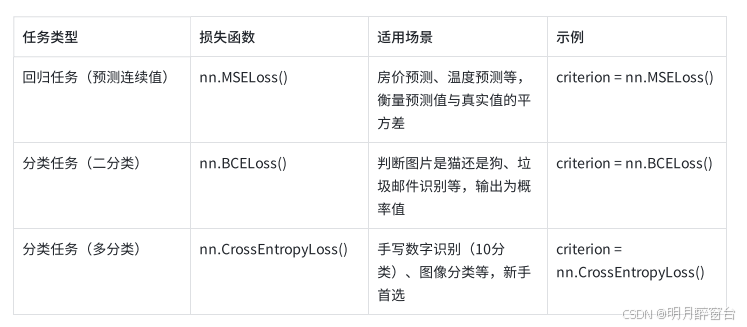
损失函数(Loss Function):衡量模型输出与真实标签的差距,是模型训练的“指南针”,不同任务对应不同损失函数(如分类任务用交叉熵损失,回归任务用均方误差损失)。
-
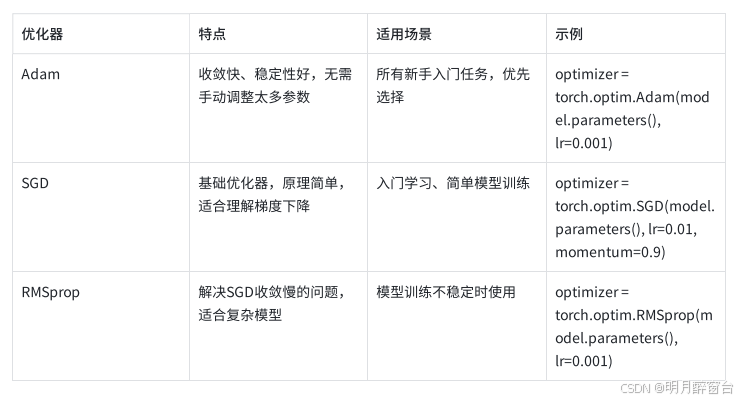
优化器(Optimizer):根据损失函数计算的梯度,更新模型参数,减少损失,常用的有SGD(随机梯度下降)、Adam(新手首选,收敛更快、更稳定)。
1.2 环境搭建(新手一步到位)
搭建PyTorch环境,核心是安装Python、PyTorch及相关依赖库,步骤简洁,避免复杂配置,新手可直接复制命令执行。
-
安装Python:优先选择Python 3.8-3.11(兼容性最好),官网下载(https://www.python.org/),安装时勾选“Add Python to PATH”,安装完成后通过cmd输入“python --version”验证。
-
安装PyTorch(核心步骤):
-
打开PyTorch官网(https://pytorch.org/),选择对应系统(Windows/Mac/Linux)、安装方式(Pip)、CUDA版本(有独立显卡且支持CUDA,选择对应版本;无显卡选择CPU版本)。
-
复制官网生成的命令,在cmd中执行(示例:CPU版本,适用于无独立显卡的电脑):
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
-
验证安装:打开Python终端,输入以下代码,无报错即安装成功:
import torch
print(torch.__version__) # 打印PyTorch版本
print(torch.cuda.is_available()) # 打印True表示支持GPU加速,False表示仅支持CPU
- 安装必备依赖库(用于数据处理、可视化):
pip install numpy pandas matplotlib
1.3 基础操作(实操必备,直接复制可用)
重点掌握Tensor的创建、运算及自动求导,这些是搭建模型、训练模型的基础操作,所有代码可直接在PyCharm或Jupyter Notebook中运行。
1.3.1 Tensor的创建与基本操作
import torch
import numpy as np
#1. 创建Tensor(常用方式)
torch.tensor([1,2,3]) # 从列表创建1维张量
torch.zeros((3,4)) # 创建3行4列的全0张量
torch.ones((2,3,4)) # 创建2个3行4列的全1张量(3维)
torch.randn((3,3)) # 从标准正态分布中创建3行3列张量(常用初始化模型参数)
torch.from_numpy(np.array([1,2,3])) # 从NumPy数组转换为Tensor
#2. 基本属性查看
x = torch.randn((3,4), dtype=torch.float32, device="cpu")
print(x.shape) # 查看形状:torch.Size([3,4])
print(x.dtype) # 查看数据类型:torch.float32
print(x.device) # 查看运行设备:cpu
#3. 张量运算(简单常用)
x = torch.tensor([1,2,3])
y = torch.tensor([4,5,6])
print(x + y) # 加法:tensor([5,7,9])
print(x * y) # 乘法:tensor([4,10,18])
print(x.view(3,1))# 改变形状:从(3,)变为(3,1)
#4. 设备转换(CPU转GPU,GPU转CPU)
if torch.cuda.is_available():
x_cuda = x.to("cuda") # CPU张量转GPU
x_cpu = x_cuda.to("cpu") # GPU张量转CPU
1.3.2 自动求导(Autograd)实操
import torch
#1. 定义需要求导的张量(requires_grad=True表示需要计算梯度)
x = torch.tensor([2.0], requires_grad=True)
y = torch.tensor([3.0], requires_grad=True)
#2. 定义运算过程
z = x**2 + y * 3 # z = 2² + 3×3 = 4 + 9 = 13
#3. 反向传播,计算梯度(对z求x、y的偏导数)
z.backward()
#4. 查看梯度(x的梯度是2x=4,y的梯度是3)
print(x.grad) # 输出:tensor([4.])
print(y.grad) # 输出:tensor([3.])
#注意:每次反向传播后,梯度会累积,下次训练前需清零
x.grad.zero_()
y.grad.zero_()
第二部分:PyTorch模型搭建入门总结(核心实操)
深度学习模型搭建的核心流程:定义模型 → 准备数据 → 定义损失函数与优化器 → 训练模型 → 模型评估。本部分聚焦新手入门级模型搭建,以“简单分类模型、回归模型”为例,全程代码可复制运行,理解搭建逻辑即可,无需深入复杂模型结构。
2.1 模型搭建的固定模板(必记)
所有PyTorch模型都遵循以下模板,只需根据任务修改“网络层结构”和“前向传播逻辑”,新手可直接套用:
import torch.nn as nn
#定义模型,继承nn.Module(固定步骤)
class MyModel(nn.Module):
# 初始化网络层(定义模型的结构)
def __init__(self):
super(MyModel, self).__init__() # 固定写法,继承父类属性
# 在这里定义网络层(如全连接层、卷积层等)
self.layer1 = nn.Linear(10, 5) # 全连接层:输入维度10,输出维度5
self.layer2 = nn.Linear(5, 2) # 全连接层:输入维度5,输出维度2
self.relu = nn.ReLU() # 激活函数(避免模型线性化,提升表达能力)
# 前向传播(定义数据的流动路径,固定方法名forward)
def forward(self, x):
x = self.layer1(x) # 数据经过第一层
x = self.relu(x) # 经过激活函数
x = self.layer2(x) # 经过第二层
return x # 返回模型输出
# 实例化模型
model = MyModel()
print(model) # 查看模型结构
提示:模型的核心是“网络层”和“前向传播”,网络层根据任务选择(分类用全连接层、卷积层;回归用全连接层),激活函数常用ReLU(新手首选)。
2.2 入门级模型案例(2个核心案例,直接运行)
案例1:简单回归模型(预测连续值,如房价预测);案例2:简单分类模型(预测类别,如手写数字识别简化版),覆盖新手最常接触的两种任务。
案例1:简单回归模型(预测y = 2x + 1 + 噪声)
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
#1. 准备数据(模拟回归任务数据)
x = torch.randn(100, 1) # 输入数据:100个样本,每个样本1个特征
y = 2 * x + 1 + torch.randn(100, 1) * 0.1 # 真实标签:y=2x+1,添加少量噪声
#2. 定义回归模型(全连接层,输入维度1,输出维度1)
class RegressionModel(nn.Module):
def __init__(self):
super(RegressionModel, self).__init__()
self.linear = nn.Linear(1, 1) # 全连接层:输入1维,输出1维
def forward(self, x):
return self.linear(x)
# 3. 实例化模型、定义损失函数和优化器
model = RegressionModel()
criterion = nn.MSELoss() # 回归任务:均方误差损失(衡量预测值与真实值的差距)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # Adam优化器,学习率0.01
# 4. 训练模型(核心步骤)
epochs = 100 # 训练轮次:整个数据集训练100遍
loss_list = [] # 保存每轮的损失值,用于后续可视化
for epoch in range(epochs):
# 前向传播:输入x,得到模型预测值
y_pred = model(x)
# 计算损失
loss = criterion(y_pred, y)
# 反向传播+参数更新(固定步骤)
optimizer.zero_grad() # 梯度清零(避免累积)
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
# 保存损失值
loss_list.append(loss.item())
# 每10轮打印一次损失(查看训练进度)
if (epoch + 1) % 10 == 0:
print(f"Epoch: {epoch+1}, Loss: {loss.item():.4f}")
# 5. 可视化训练过程(损失值变化)
plt.plot(range(epochs), loss_list)
plt.title("Training Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
# 6. 模型预测(用训练好的模型预测新数据)
x_test = torch.tensor([[3.0]]) # 新输入:x=3
y_pred = model(x_test)
print(f"当x=3时,预测y值为:{y_pred.item():.4f}") # 理想值为7,预测值接近7即训练成功
案例2:简单分类模型(手写数字识别简化版,10分类)
import torch
import torch.nn as nn
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 1. 准备数据(使用MNIST手写数字数据集,简化版)
# 数据预处理:将图片转为Tensor,并归一化(新手直接套用)
transform = transforms.Compose([
transforms.ToTensor(), # 转为Tensor,形状为(1,28,28),值范围[0,1]
transforms.Normalize((0.1307,), (0.3081,)) # 归一化,提升训练效果
])
# 下载训练集和测试集(自动下载,首次运行较慢)
train_dataset = datasets.MNIST(
root="data", train=True, download=True, transform=transform
)
test_dataset = datasets.MNIST(
root="data", train=False, download=True, transform=transform
)
# 数据加载器(批量加载数据,训练时用)
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=32, shuffle=False)
# 2. 定义分类模型(输入为28×28=784维,输出为10维(10个类别))
class ClassificationModel(nn.Module):
def __init__(self):
super(ClassificationModel, self).__init__()
self.linear1 = nn.Linear(784, 128) # 全连接层1:输入784维,输出128维
self.linear2 = nn.Linear(128, 64) # 全连接层2:输入128维,输出64维
self.linear3 = nn.Linear(64, 10) # 全连接层3:输入64维,输出10维(10分类)
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
# 图片形状为(32,1,28,28),先转为(32,784)(批量大小×特征数)
x = x.view(-1, 28*28) # -1表示自动计算批量大小
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
x = self.relu(x)
x = self.linear3(x)
return x
# 3. 实例化模型、损失函数和优化器
model = ClassificationModel()
criterion = nn.CrossEntropyLoss() # 分类任务:交叉熵损失(新手首选)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 4. 训练模型
epochs = 5 # 新手可先训练5轮,熟悉流程(后续可增加轮次提升精度)
for epoch in range(epochs):
model.train() # 模型进入训练模式(固定写法)
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
# 前向传播
output = model(data)
# 计算损失
loss = criterion(output, target)
# 反向传播+参数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 累积损失
total_loss += loss.item()
# 每轮打印训练损失
print(f"Epoch: {epoch+1}, Training Loss: {total_loss/len(train_loader):.4f}")
# 5. 模型评估(测试模型准确率)
model.eval() # 模型进入评估模式(固定写法,禁用Dropout等)
correct = 0
total = 0
with torch.no_grad(): # 评估时禁用自动求导,节省内存
for data, target in test_loader:
output = model(data)
_, predicted = torch.max(output.data, 1) # 取预测概率最大的类别
total += target.size(0)
correct += (predicted == target).sum().item()
# 打印测试准确率
print(f"Test Accuracy: {100 * correct / total:.2f}%") # 训练5轮后,准确率约95%左右
2.3 模型搭建核心注意事项(新手避坑)
-
模型必须继承nn.Module,且__init__方法中必须调用super(MyModel, self).init(),否则会报错。
-
前向传播方法名必须是forward(固定写法),不能修改,数据的流动路径需在forward中明确。
-
网络层的输入输出维度必须匹配:如前一层输出维度为128,后一层输入维度必须为128,否则会出现维度不匹配错误。
-
训练时必须执行“梯度清零→反向传播→参数更新”三步,缺一不可,否则模型无法收敛(参数不更新)。
-
评估模型时,需调用model.eval(),并使用with torch.no_grad()禁用自动求导,避免不必要的内存消耗。
-
学习率(lr)的选择:新手建议用0.001-0.01,学习率太高会导致训练不稳定,太低会导致训练速度太慢。
第三部分:常用网络层与工具总结(新手查询必备)
整理PyTorch搭建模型时最常用的网络层、损失函数、优化器,按功能分类,方便新手查询使用,直接复制到代码中即可调用。
3.1 常用网络层(按功能分类)

3.2 常用损失函数(按任务分类)
3.3 常用优化器(新手首选)
第四部分:模型保存与加载(实操必备)
训练好的模型需要保存,后续可直接加载使用,避免重复训练,新手掌握两种常用保存方式即可。
import torch
from model import MyModel # 假设模型定义在model.py中,若在同一文件可省略
# 1. 保存模型(两种方式)
# 方式1:保存整个模型(包含模型结构+参数,简单直观,推荐新手)
model = MyModel()
torch.save(model, "my_model.pth")
# 方式2:只保存模型参数(推荐,占用内存小,灵活)
torch.save(model.state_dict(), "my_model_params.pth")
# 2. 加载模型(对应两种保存方式)
# 方式1:加载整个模型
loaded_model = torch.load("my_model.pth")
loaded_model.eval() # 加载后需进入评估模式
# 方式2:加载模型参数(需先实例化模型,再加载参数)
loaded_model = MyModel()
loaded_model.load_state_dict(torch.load("my_model_params.pth"))
loaded_model.eval() # 评估模式
# 3. 加载后使用模型预测
x_test = torch.randn(1, 10) # 输入数据,维度需匹配模型输入
y_pred = loaded_model(x_test)
print(y_pred)
第五部分:新手常见问题汇总(避坑指南)
-
问题1:运行代码时提示“ModuleNotFoundError: No module named ‘torch’”?
解决方案:未安装PyTorch,重新打开cmd,复制PyTorch官网的安装命令执行,确保安装成功。 -
问题2:提示“CUDA out of memory”(CUDA内存不足)?
解决方案:降低批量大小(batch_size,如从32改为16),或使用CPU训练(将模型和数据移动到cpu)。 -
问题3:训练时损失值不下降,模型不收敛?
解决方案:检查学习率(调小或调大)、网络层结构(是否维度匹配)、损失函数是否对应任务(分类用交叉熵,回归用均方误差)。 -
问题4:维度不匹配错误(如“Expected input batch_size (32) to match target batch_size (16)”)?
解决方案:检查数据加载器的batch_size与模型输入维度是否一致,或网络层的输入输出维度是否匹配。 -
问题5:加载模型时提示“AttributeError: ‘dict’ object has no attribute ‘eval’”?
解决方案:混淆了两种保存方式,若用方式2保存(只保存参数),需先实例化模型,再加载参数,不能直接load后调用eval()。
第六部分:PDF导出提示(适配汇总需求)
本总结可直接复制到Word、WPS等文档中,整理格式后导出为PDF,方便离线查阅、打印,步骤如下:
-
复制全文内容,粘贴到Word/WPS文档中;
-
调整格式:统一字体(如宋体)、字号(标题四号,正文小四号),调整行距(1.5倍行距),确保标题层级清晰;
-
处理代码块:将代码块设置为“等宽字体”(如Consolas),调整字体大小(小五号),确保代码清晰可读;
-
点击“文件”→“另存为”,选择“PDF”格式,点击“保存”,即可完成导出。
总结
本总结聚焦PyTorch深度学习模型搭建的入门知识,从基础知识、环境搭建、模型搭建模板、实操案例,到常用工具、避坑指南,全程贴合新手需求,所有代码可直接复制运行。新手学习时,建议先掌握“核心概念+固定模板”,再通过两个入门案例实操,熟悉训练流程,逐步理解网络层、损失函数、优化器的作用,无需急于深入复杂模型,夯实基础即可逐步提升。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)