【向量及向量数据库-1】向量表征
文章目录
1. 向量表征概述
在人工智能、大模型RAG检索、语义搜索等场景爆火的当下,向量表征(Embedding)早已成为AI底层核心技术。无论是文本匹配、图文检索,还是个性化推荐、知识推理,都离不开向量的支撑。本篇博客将从零拆解向量表征的核心知识,覆盖基础理论、生成原理、相似度计算、技术演进全流程,帮你快速建立完整的知识体系。
1.1 目标
-
吃透核心概念:精准理解向量表征的本质含义,明确其在AI、NLP、大模型生态中的核心定位,厘清普通数学向量与文本/多模态向量的定义、特征及应用边界,搭建扎实的基础认知体系。
-
精通相似度度量:熟练掌握主流向量相似度计算方法,深挖余弦相似度、欧氏距离等算法的计算逻辑、适用场景和优劣对比,具备实战场景下的算法选型能力。
1.2 向量表征
1.2.1 向量表征的核心定义
向量表征是AI世界的“通用翻译官”,是人工智能领域(尤其是自然语言处理NLP)的基石技术,核心作用是将文本、图像、音频、用户行为、实体关系等非结构化、异构化信息,转化为高维稠密Embedding向量,让机器通过数学运算、空间几何计算理解并处理现实世界的复杂问题。
从AI数据处理逻辑来看:人类可感知的自然语言、音视频、图像等信息,属于机器无法直接识别的“非结构化数据”;而向量表征搭建了人类认知与机器理解之间的桥梁,相当于为各类AI模型提供了标准化的数据交互语言。
打个通俗比方:就像Java、C++等高级语言需要编译为底层汇编指令,才能被计算机硬件执行一样,人类的各类异构信息,必须通过向量表征转化为机器可解读的数学数值,才能成为模型训练、推理、检索的统一数据入口。
1.2.2 向量表征的本质
向量表征的核心本质是数据的数学化重构,通过数学手段将抽象的非结构化信息,转化为机器可运算、可量化的数值载体,核心思想围绕两大维度展开,辅以严谨的数学逻辑支撑:
-
降维抽象:构建标准化向量空间映射
将文本、图片、音视频等复杂异构对象,映射至固定维度的稠密向量空间,通过算法提炼数据的关键语义、特征信息,实现高维数据的降维抽象。无论输入是单字、短句、长文本还是图像,模型都会输出固定维度的向量,保障向量空间格式规整、支持各类数学运算,这是向量兼容复用的基础。 -
相似度度量:量化语义关联度
依托向量空间内的距离、夹角等数值指标,精准量化数据间的语义相关性。简单来说:语义相近的对象,向量在空间中距离更近、夹角更小;语义无关的对象,向量距离更远、夹角更大。
举个例子:“猫”和“狗”同属宠物类目,二者向量高度接近;“猫”与“汽车”类目差异极大,向量空间距离则会拉远,这也是语义检索、个性化推荐的核心逻辑。 -
底层数学意义
以数学运算为底层支撑,完成异构信息的语义抽象、特征编码与相似性量化,彻底打通人类可感知信息与AI机器理解之间的壁垒,让机器学习、检索推理、内容匹配等任务具备可计算、可复现、可优化的数学基础。
1.2.3 向量表征的典型应用
向量表征凭借强大的语义量化、跨模态映射能力,成为打通多领域AI任务的核心枢纽,落地场景覆盖NLP、计算机视觉、推荐系统、大模型RAG等方向,具体应用如下:
① 自然语言处理(NLP)领域
-
词向量与歧义消解:将单词映射为低维稠密向量,精准解决一词多义难题。比如“苹果”在水果语境、科技公司语境下,会生成差异化向量,避免模型语义混淆。
-
句子/文本级向量表征:基于Transformer架构的大模型(如BERT),实现整句、段落级语义编码,兼顾上下文信息实现深度理解,常用于文本相似度计算、语义匹配、问答系统。
-
知识图谱嵌入:将知识图谱中的实体、关联关系转化为向量,实现结构化知识的数学化表达,支撑链路预测、可信度校验、逻辑推理等高阶任务。
② 计算机视觉与跨模态领域
-
图像特征向量提取:依托CNN、ViT等神经网络提取图像核心特征并编码为向量,实现图像分类、目标检测、人脸识别、图像比对等任务。
-
多模态统一表征:以CLIP为代表的跨模态模型,将文本、图像映射至同一向量空间,打破模态壁垒,支持图文互搜、文本生成图像、跨模态检索等创新场景,是多模态AI的核心底层技术。
③ 个性化推荐系统领域
作为推荐算法的核心支撑,通过向量表征实现用户与物品的精准匹配:将用户点击、收藏、购买等行为序列编码为用户向量,把商品属性、内容特征编码为物品向量,依托相似度计算预测兴趣匹配度,实现电商、短视频、资讯平台的“千人千面”推荐,同时解决内容冷启动、复杂用户建模等痛点。
④ 大模型RAG场景
这是当前向量表征最热门的落地方向,将知识库文档转化为向量存储,用户提问时生成提问向量,通过相似度检索匹配相关知识库内容,再喂给大模型生成答案,解决大模型幻觉、知识滞后、隐私数据调用等核心问题。
1.2.4 向量表征的技术实现
向量表征技术伴随机器学习范式迭代持续升级,从早期浅层静态表征,发展到当前深度动态表征,形成两大成熟技术体系,二者在建模思路、向量特性、适用场景上存在本质差异:
一、无监督学习范式(传统静态词向量技术)
该范式是向量表征的奠基性技术,完全依托海量无标注语料进行自监督训练,无需人工标注数据,依靠文本内部统计特征与上下文关联挖掘语义,是早期NLP向量生成的主流方案。
-
核心原理:分为上下文预测和矩阵分解两大路线。上下文预测(Skip-gram、CBOW)捕捉词汇与周边语境的共现关系;矩阵分解基于全局词共现矩阵,兼顾局部语境与全局统计信息,提取词汇语义特征。
-
主流代表模型:Word2Vec(谷歌轻量级模型,支持CBOW/Skip-gram)、GloVe(斯坦福研发,融合全局+局部优势)。
-
技术特性:生成静态向量,单个词汇对应唯一向量,无法适配多义词语境差异;优点是模型简单、训练成本低、推理速度快,适用于轻量化语义任务、基础词汇相似度计算。
二、预训练微调范式(深度动态向量技术)
这是当前工业界主流的向量表征技术,基于Transformer架构搭建深度预训练模型,先通过大规模无标注数据学习通用语义,再结合场景微调,实现上下文感知的动态向量生成,彻底解决静态向量的语义局限。
-
核心原理:依托Transformer注意力机制,深度捕捉文本上下文依赖关系,模型会根据词汇所处语境动态调整向量表示,精准区分一词多义;预训练保证泛化性,微调提升场景适配度。
-
主流代表模型:BERT(文本向量标杆)、RoBERTa、ALBERT、Sentence-BERT(句子级向量优化款)等。
-
技术特性:生成动态向量,语义表达精准、泛化能力极强,支持句子/段落/文档级高阶语义表征;适用于语义检索、RAG、文本匹配、情感分析等复杂AI任务。
这部分内容与传统NLP词向量知识一脉相承,此前接触过NLP基础的小伙伴可结合过往笔记联动学习,理解更透彻~
2. 向量基础
2.1 文本向量(Embeddings)
文本向量是向量表征最核心的应用形态,简单来说:文本向量就是将自然语言文本,转化为固定维度的浮点型数值数组,是文本语义的数字化、可计算表达。
举个直观例子:
-
“这个东西多少钱?”
-
“这个东西什么价格?”
-
“给我报个价”
这三句话表述不同,但语义完全一致,经过同一向量模型转换后,会生成维度完全相同的浮点向量(常见维度:768维、1024维、512维),向量中的每一个数值,都对应文本的一个细微语义特征。
文本向量的核心规律:语义相近的文本向量在空间中高度聚合,语义无关的向量相互远离。如果同义句生成的向量距离较远,说明向量模型的语义理解能力不足,或未适配专业领域。
实战避坑小贴士:在金融、医疗、法律等垂直领域的RAG系统中,严禁直接套用通用向量模型!必须用领域专属语料测试效果,若专业词汇匹配偏差大,需更换领域专用模型或用行业数据微调,这是保障语义检索精度的关键。
2.2 文本向量的生成原理
文本向量由专用Embedding模型生成,主流训练逻辑基于对比学习,训练过程核心分为两步,目标是让模型学会“精准区分语义异同”:
-
构建训练样本对:批量准备正样本对(语义相同/相近的句子)和负样本对(语义无关的句子),让模型有明确的学习目标。
-
训练双塔语义模型:将样本对输入双塔架构模型,通过优化算法拉近正样本对的向量距离,拉远负样本对的向量距离,反复迭代后模型即可输出高质量语义向量。
训练完成后,模型输出的向量数值通常会归一化至[-1, 1]区间,可直接用于后续相似度计算与检索。
目前工业界最常用的文本向量架构为Sentence-BERT,专门针对句子级语义表征优化,后续会单独出专题拆解其原理与实战部署。
开源代码:https://github.com/huggingface/sentence-transformers
论文地址:https://arxiv.org/pdf/1908.10084v1
2.3 向量相似度计算
向量生成并存储后,需要通过算法计算语义相似度,这是语义检索、匹配的核心环节。主流方法为余弦相似度和欧氏距离,二者适用场景差异极大:
① 余弦相似度(首选算法)
计算两个向量的夹角余弦值,只关注向量的方向差异,不关注向量长度,完美适配文本语义匹配场景,是知识库、RAG、语义检索的行业首选算法。
核心规律:夹角越小,余弦值越接近1,代表文本语义越相似;向量完全重合时,余弦值为1,代表语义完全一致。
② 欧氏距离
计算向量空间中两点的直线距离,距离越小代表相似度越高。但该算法受向量长度、数值尺度影响较大,在文本语义任务中容易出现偏差,因此仅适用于特定场景,极少用于NLP语义检索。
核心结论:做文本语义匹配、RAG检索,优先选余弦相似度;欧氏距离更适用于注重空间绝对距离的场景(如坐标、数值聚类)。
3. 向量相似度计算示例
3.1 示例1
为了更直观理解向量空间分布、余弦相似度与语义关联的关系,这里提供一套基于Ollama+Qwen3-Embedding的可视化代码。通过PCA将高维向量降维至2D平面,绘制查询向量与文档向量的空间位置,直观呈现“语义相近则向量靠近”的核心规律。
- 依托远程Ollama服务调用Embedding模型生成文本向量
- 计算向量余弦相似度、欧氏距离
- PCA降维实现高维向量2D可视化,标注原文文本
- 区分查询向量与文档向量样式,清晰展示空间分布
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.decomposition import PCA
import ollama
import matplotlib.font_manager as fm
# ===================== 1. 精确加载中文字体 =====================
font_path = "/usr/share/fonts/truetype/wqy/wqy-microhei.ttc"
font_prop = fm.FontProperties(fname=font_path)
plt.rcParams['axes.unicode_minus'] = False
# ===================== 2. 远程 Ollama 配置 =====================
client = ollama.Client(host="http://192.168.1.11:11434")
# ===================== 3. 向量生成 & 相似度函数 =====================
def get_embeddings(text: str, model: str = "qwen3-embedding:4b") -> list:
try:
res = client.embeddings(model=model, prompt=text)
return res["embedding"]
except Exception as e:
print("❌ 无法连接远程 Ollama,请检查:")
print(" 192.168.1.11 是否运行:OLLAMA_HOST=0.0.0.0 ollama serve")
raise e
def cosine_similarity_score(v1, v2):
return cosine_similarity([v1], [v2])[0][0]
def euclidean_distance(v1, v2):
return np.linalg.norm(np.array(v1) - np.array(v2))
# ===================== 4. 主程序 & 可视化 =====================
if __name__ == '__main__':
query = "国际争端"
docs = [
"日本与我国在东海海域存在权益争议",
"联合国召开会议调解国际冲突",
"今天的天气非常晴朗适合外出",
"人工智能技术在医疗领域快速发展",
"国内新能源汽车销量持续增长"
]
# 生成向量
q_vec = get_embeddings(query)
d_vecs = [get_embeddings(doc) for doc in docs]
# PCA降维到2D
all_vecs = [q_vec] + d_vecs
# Label 直接显示原文
labels = [query] + docs
data_2d = PCA(n_components=2).fit_transform(all_vecs)
# 绘图
plt.figure(figsize=(14, 8), dpi=150)
plt.style.use('seaborn-v0_8-whitegrid')
# 绘制原点到各点的向量箭头
for i, (x, y) in enumerate(data_2d):
if i == 0:
# 查询向量:红色箭头
plt.arrow(0, 0, x, y, color="#e74c3c", alpha=0.7, width=0.008, head_width=0.03, label="查询向量" if i == 0 else "")
plt.scatter(x, y, color="#e74c3c", s=200, edgecolors="black", zorder=5)
else:
# 文档向量:蓝色箭头
plt.arrow(0, 0, x, y, color="#3498db", alpha=0.6, width=0.006, head_width=0.025)
plt.scatter(x, y, color="#3498db", s=160, edgecolors="white", zorder=5)
# 标注原文 Label(使用中文字体)
for i, txt in enumerate(labels):
plt.annotate(txt, (data_2d[i, 0], data_2d[i, 1]),
fontproperties=font_prop, fontsize=9, fontweight='medium',
xytext=(5, 5), textcoords='offset points')
# 标题与图例
plt.title("文本向量空间分布可视化(Qwen3-Embedding 4B|远程Ollama)",
fontproperties=font_prop, fontsize=14, fontweight='bold')
# 手动创建图例(避免重复箭头)
from matplotlib.lines import Line2D
custom_lines = [
Line2D([0], [0], color="#e74c3c", marker='o', linestyle='None', markersize=10, label='查询向量'),
Line2D([0], [0], color="#3498db", marker='o', linestyle='None', markersize=10, label='文档向量')
]
plt.legend(handles=custom_lines, prop=font_prop, fontsize=10)
# 绘制坐标轴原点
plt.axhline(0, color='black', linewidth=0.8, linestyle='--', alpha=0.5)
plt.axvline(0, color='black', linewidth=0.8, linestyle='--', alpha=0.5)
plt.grid(True, alpha=0.3)
plt.tight_layout()
# 保存图
plt.savefig("/mnt/data/ai_dev/knowledge_consolidation/embedding和向量数据库/code/images/embedding_vector_arrows.png", dpi=150, bbox_inches="tight")
plt.close()
print("✅ 带向量箭头+原文Label的图片已保存:embedding_vector_arrows.png")
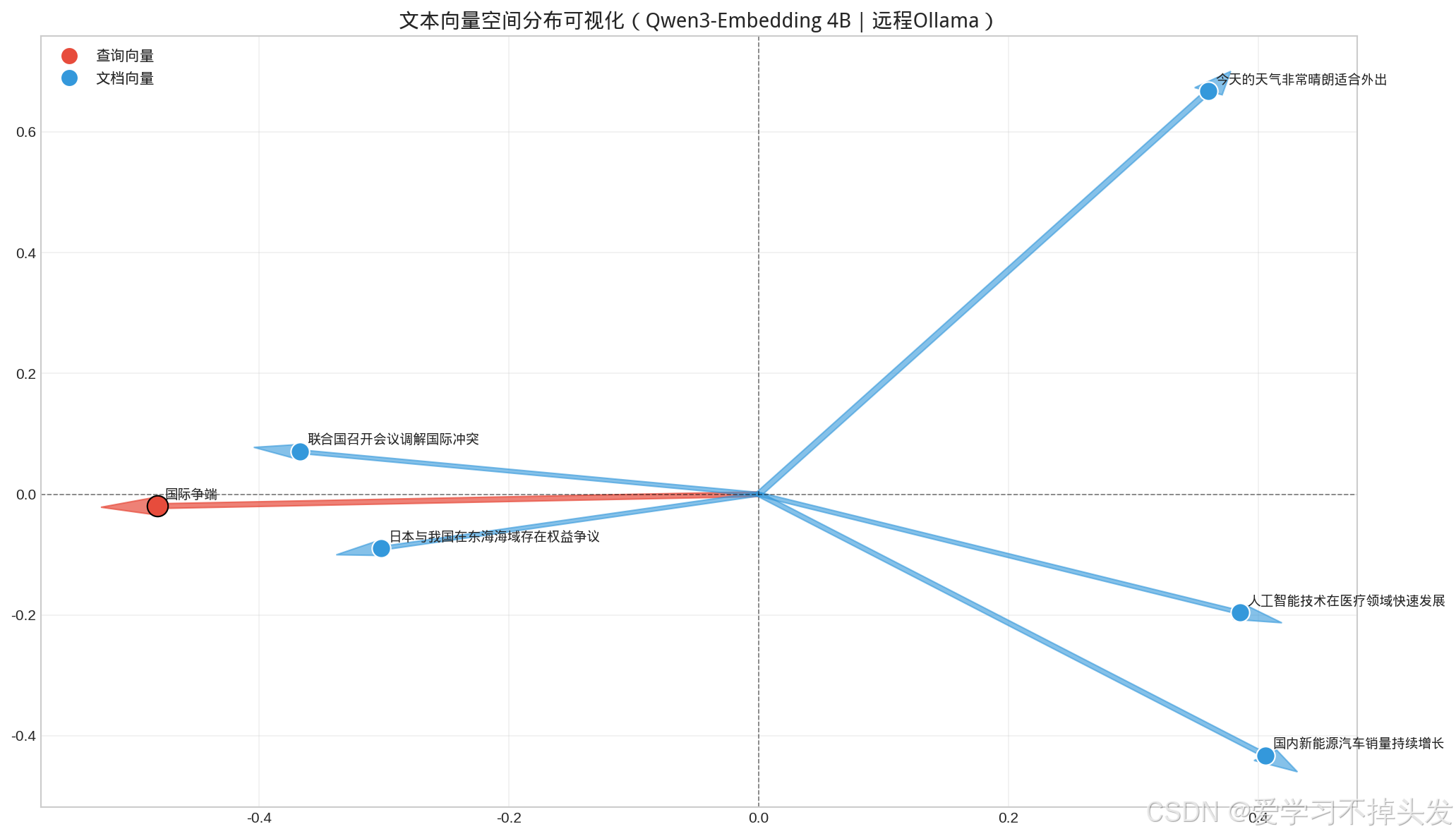
可视化结论:查询词“国际争端”的向量,会与语义相关的“东海权益争议”“联合国调解冲突”向量距离更近、夹角更小;与天气、AI、新能源汽车等无关文本向量距离更远,完美印证余弦相似度的语义匹配逻辑。
3.2 示例2
import requests
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
import seaborn as sns
# 设置字体
# 方法1:直接指定字体路径(最可靠)
font_path = "/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc"
font_prop = FontProperties(fname=font_path)
# 方法2:使用字体名称(如果系统已识别)
# font_prop = FontProperties(family="Noto Sans CJK JP")
# 全局设置:所有文本都用这个中文字体
plt.rcParams["font.family"] = font_prop.get_name()
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
# ===================== 1. 配置Ollama 服务 =====================
OLLAMA_BASE_URL = "http://xxxxxxxx:11434" # 服务地址
EMBEDDING_MODEL = "qwen3-embedding:4b" # embedding 模型
# ===================== 2. 定义测试文本(演示用) =====================
# 构造3组语义相关/无关的文本,直观展示相似度差异
text_samples = [
"人工智能正在改变世界",
"AI技术推动社会发展",
"今天的天气非常晴朗",
"我喜欢吃水果和蔬菜",
"机器学习属于人工智能分支"
]
text_labels = [
"AI改变世界",
"AI推动发展",
"天气晴朗",
"喜欢吃果蔬",
"机器学习=AI"
]
# ===================== 3. 调用 Ollama 获取文本向量 =====================
def get_embedding(text: str) -> list:
"""调用本地 Ollama 生成文本 embedding 向量"""
url = f"{OLLAMA_BASE_URL}/api/embeddings"
payload = {
"model": EMBEDDING_MODEL,
"prompt": text
}
try:
response = requests.post(url, json=payload, timeout=10)
response.raise_for_status() # 抛出请求异常
return response.json()["embedding"]
except Exception as e:
print(f"生成向量失败: {e}")
return []
# 批量生成所有文本的向量
print("正在生成文本向量...")
embeddings = []
valid_labels = []
for text, label in zip(text_samples, text_labels):
vec = get_embedding(text)
if vec:
embeddings.append(vec)
valid_labels.append(label)
embeddings_np = np.array(embeddings)
print(f"成功生成 {len(embeddings)} 个向量,向量维度: {embeddings_np.shape[1]}")
# ===================== 4. 计算余弦相似度 =====================
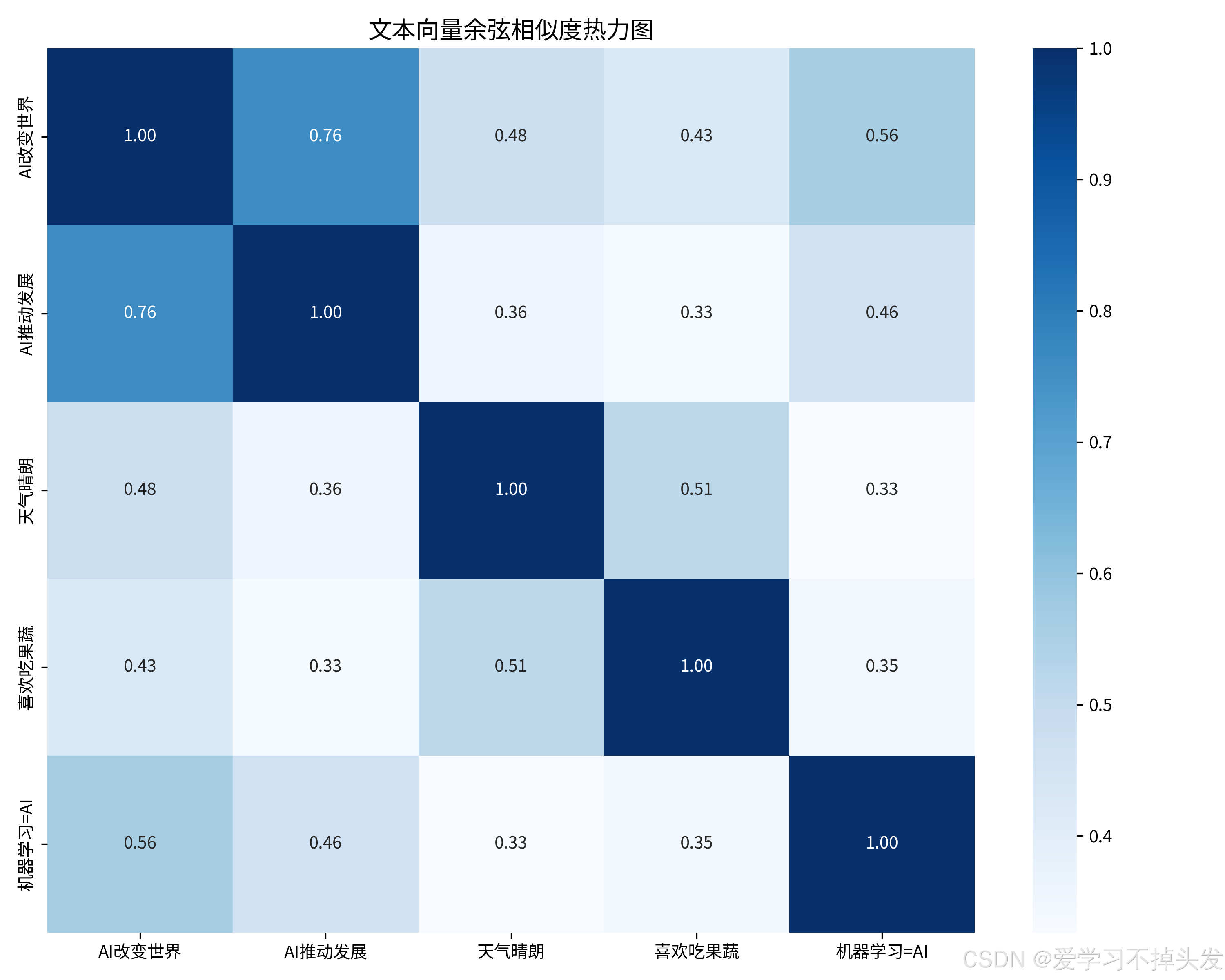
print("\n========== 文本相似度计算结果 ==========")
similarity_matrix = cosine_similarity(embeddings_np)
# 打印相似度结果
for i in range(len(valid_labels)):
for j in range(len(valid_labels)):
if i < j:
print(f"{valid_labels[i]} ↔ {valid_labels[j]}: {similarity_matrix[i][j]:.4f}")
# ===================== 5. 生成相似度热力图可视化 =====================
plt.rcParams["font.sans-serif"] = ["SimHei", "DejaVu Sans"] # 支持中文显示
plt.figure(figsize=(10, 8))
# 绘制热力图
sns.heatmap(
similarity_matrix,
annot=True, # 显示数值
cmap="Blues", # 配色
fmt=".2f", # 数值格式
xticklabels=valid_labels,
yticklabels=valid_labels
)
plt.title("文本向量余弦相似度热力图", fontsize=14)
plt.tight_layout()
plt.savefig("/mnt/data/ai_dev/knowledge_consolidation/embedding和向量数据库/code/images/text_embedding_similarity.png", dpi=300)
plt.show()
print("\n可视化图片已保存为: text_embedding_similarity.png")

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)