《AI+HW 2035:塑造下一个十年》论文核心重点解读
导读:
2026年3月,由伊利诺伊大学厄巴纳-香槟分校(UIUC)、加州大学洛杉矶分校(UCLA)、斯坦福大学以及英伟达(Nvidia)、谷歌(Google)等27家顶尖学术机构与行业巨头联合发布的《AI+HW 2035:塑造下一个十年》(AI+HW 2035: Shaping the Next Decade)愿景白皮书,正式确立了一个跨越算法、架构、系统与可持续性的十年路线图 。该报告的核心命题在于,AI的未来不再仅仅取决于智能的规模化(Scaling Intelligence),更取决于效率的规模化(Scaling Efficiency),即在不增加无节制算力消耗的前提下,实现每焦耳能量所能承载智能水平的指数级飞跃 ,报告指出未来十年内实现 AI 计算将能效 1000 倍的跨越式提升。
本文就这份报告核心重点进行提炼和解读,可以概括为以下五个维度:
1. 核心目标:1000倍能效提升
论文指出,当前的 AI 发展模式(单纯堆砌算力)在环境和经济上都不可持续。成功的标准将从单纯的“算力(FLOPs)”转向“每焦耳智能(Intelligence per Joule)”。
“每焦耳智能”(Intelligence per Joule)是这篇论文提出的核心评价指标,旨在彻底取代传统的“每秒浮点运算次数”(FLOPS)。简单来说,它不再关注你的芯片跑得有多快,而关注你的芯片在消耗每一单位能量时,能产生多少实际的智能产出。
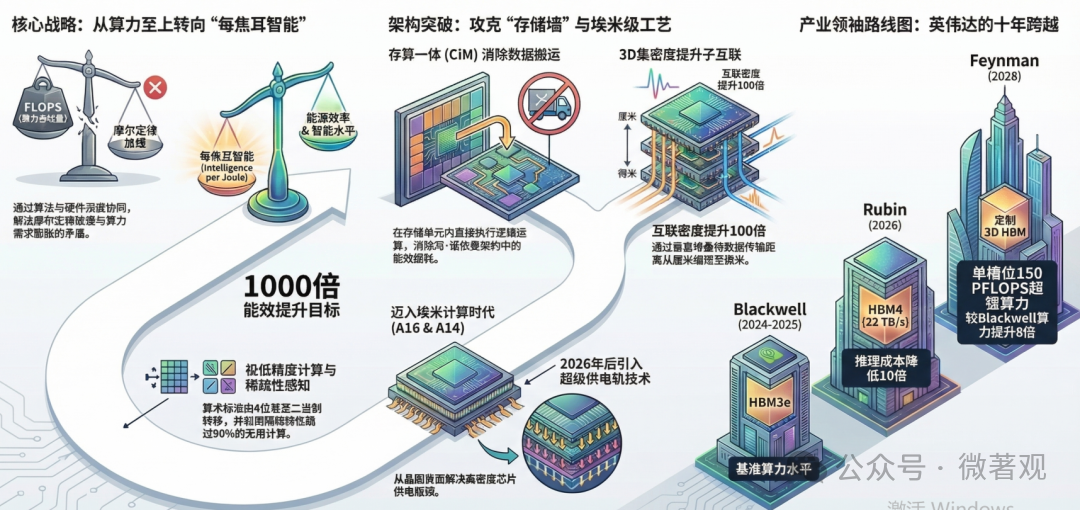
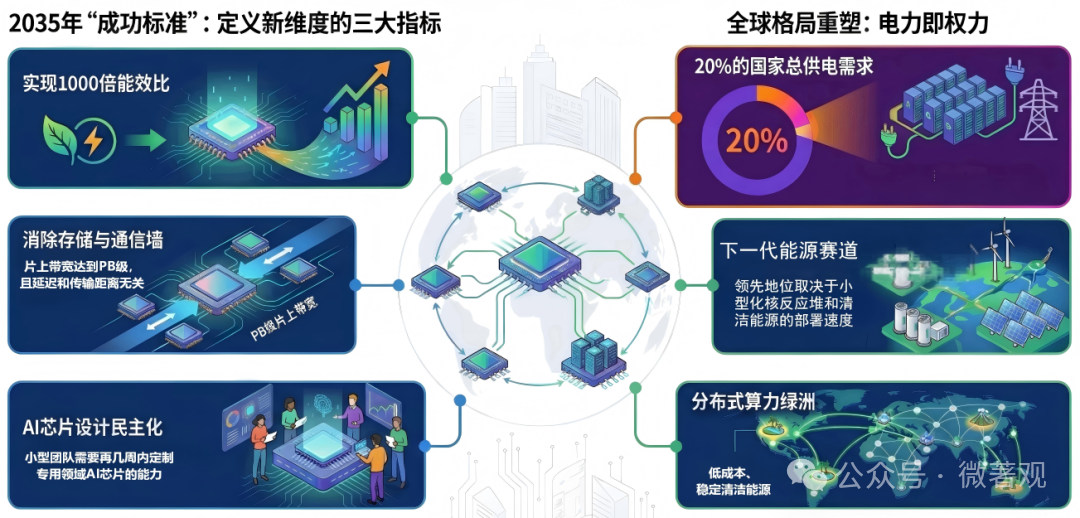
近期目标(2-5年):实现 100 倍能效提升。远期目标(6-10年):通过算法、软件和硬件的深度耦合,实现1000 倍的综合能效增益。
2. 三大架构转型的技术关键
论文指出,算力提升已触及传统电互联与平面布局的物理极限。为了彻底打破“存储墙”与“功耗墙”,硬件设计需要从“二维到三维”、“从电到光”以及“从计算中心到存储中心”三大方面发生根本性改变。
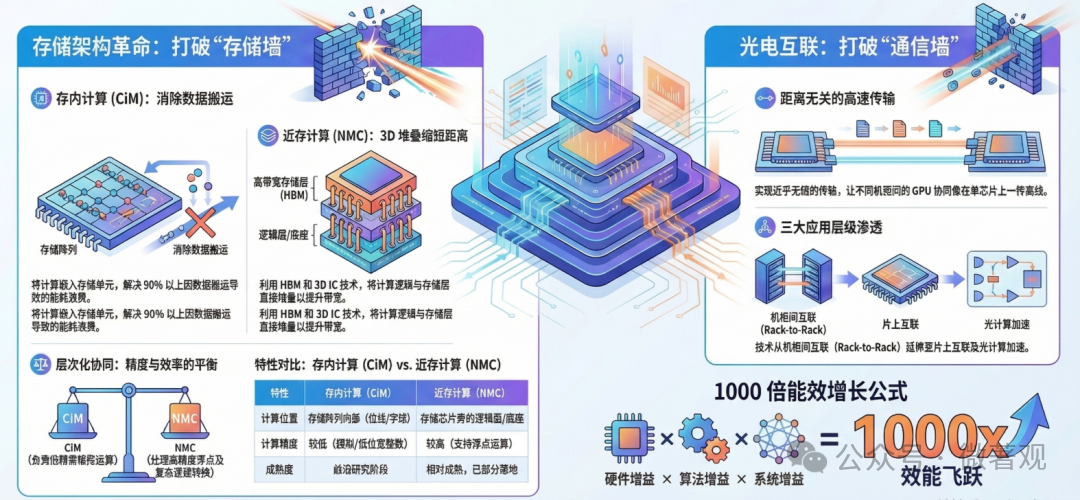
1.从以计算为中心转向以存储为中心:大力发展近存计算(Near-memory Computing)和存内计算(In-memory Computing, CiM),减少数据搬运能效损耗。
-
近存计算(NMC) 将计算逻辑移动到紧挨着存储单元的地方。通常通过 3D 堆叠技术(如 HBM、3D IC),将计算逻辑层(Logic Die)通过硅通孔(TSV)直接堆叠在存储层(Memory Die)之上;
-
存内计算(CiM)是直接在存储单元里“算“,即将计算功能直接嵌入到存储单元(如 SRAM、RRAM 或 MRAM)中。数据“原地”进行矩阵乘法等运算,彻底消除数据搬运带来的功耗和延迟。
在 论文中论文建议未来的 AI 芯片不要“二选一”,而是采用混合架构:
-
CiM 阵列: 负责处理那些对精度要求不高、但计算量巨大的卷积层和矩阵乘法。
-
NMC 模块:负责处理复杂逻辑、非线性激活函数和高精度要求的残差连接。
2. 3D 集成与异构封装:垂直堆叠计算和存储单元(3D Monolithic Integration),利用 Chiplet(小芯片)架构提升系统的灵活性和良率。论文指出,未来的系统不再由单一制程的巨型芯片(Monolithic SoC)组成,而是通过 3D 封装将不同功能的Chiplets(小芯片)组合在一起:
-
计算 + 存储:将逻辑芯片(如 GPU)与HBM(高带宽内存)堆叠,这是目前最成功的近存计算形态。
-
模拟 + 数字:在同一封装内集成高性能数字逻辑与敏感的模拟/射频组件(如光电互联模块)。
-
不同制程混搭:核心计算单元使用最先进的 2nm 工艺,而 I/O 或电源管理单元使用更成熟、更廉价的工艺,优化总成本。
3. 光电互联:利用硅光技术解决芯片间及机柜间的高速互联瓶颈,实现近乎无损的全球通信。论文描绘了光技术从宏观到微观的渗透过程:
机柜间/芯片间(Rack-to-Rack / Chip-to-Chip):利用硅光子(Silicon Photonics)技术取代传统光模块,大幅提升数据中心集群的互联带宽,支撑万亿参数模型的分布式训练。
片上互联(On-chip Interconnects):在同一个封装内通过光波导连接不同的 Chiplet,解决电信号在高频下的发热和信号衰减问题。
光计算加速(Photonic Computing):论文还探讨了利用光子进行特定的线性代数运算(如矩阵乘法),利用光子的并行性实现极低延迟的计算。
3. 算法层面的范式转移
论文指出,算法已进入性能与能效平衡的转折点。未来的核心竞争力不再是无限堆砌参数,而是如何通过算法与硬件的深度解耦与协同,在有限的能量预算内交付更精准、更具物理真实性的智能
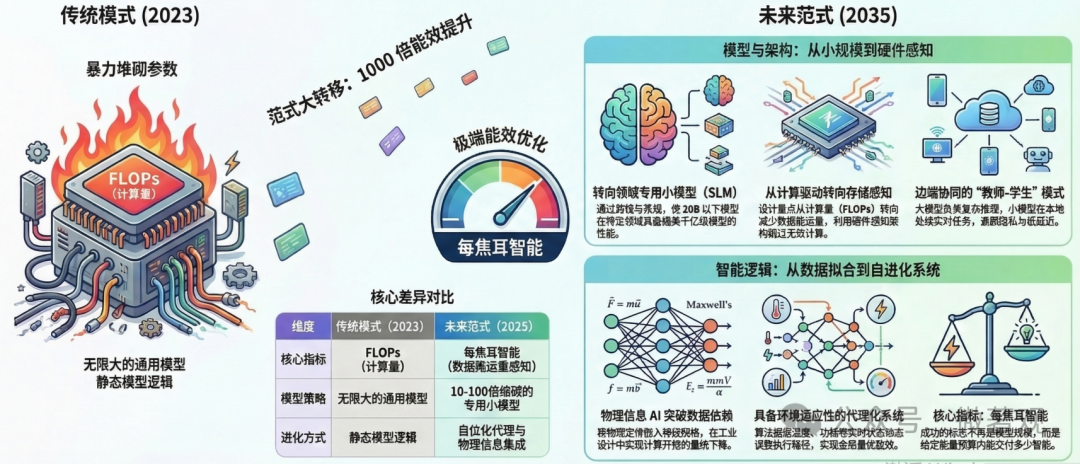
-
小模型(SLM)的崛起:研发参数量小于 20B、性能可媲美前沿大模型的领域专用模型,使其能在边缘侧和机器人终端运行。
-
硬件感知训练:在算法设计阶段就考虑硬件的稀疏性、低精度(量化)和非线性特性。
-
物理信息 AI(Physics-informed AI):将物理定律嵌入神经网络,减少对海量数据的依赖,提升模型在科学发现和工程设计中的可靠性。
4. 生产力变革:AI 设计硬件
论文强调了“AI-in-the-loop”的设计流程,即利用 AI 来加速硬件开发:
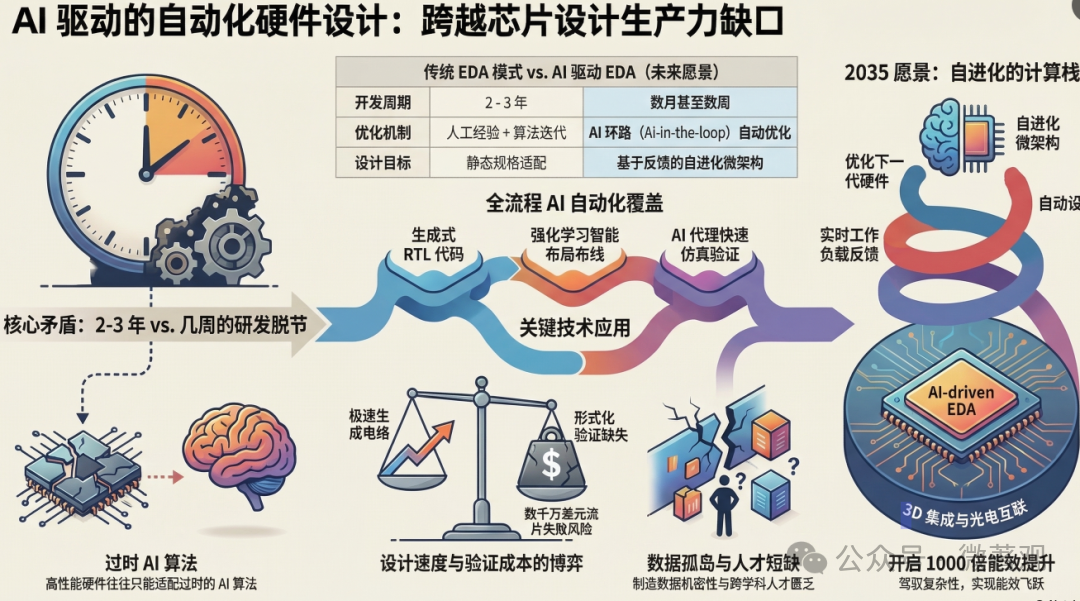
-
生成式 RTL 设计:利用类似于GPT-4或专用大模型自动生成 Verilog/VHDL 代码,并进行初步的逻辑验证。
-
智能布局布线(Place and Route):利用深度强化学习(RL)在巨大的解空间中寻找最优的芯片布局,以减少信号延迟和功耗。
-
快速仿真与验证:使用 AI 代理(Agents)自动生成测试向量,预测电路的物理特性(如热分布、IR 压降),从而取代耗时的传统物理仿真。
5. 社会影响与行动倡议
论文将算力视作国家竞争力的终极货币,强调算力竞争已跨越芯片技术,演变为能源供给与地缘政治的综合博弈。未来的胜者必须在实现千倍能效的同时,构建起自主的 AI 设计生态与自给自足的能源体系。
-
电力危机预警:论文预测美国可能在 5 年内面临电力短缺,建议政府投资小型模块化核反应堆(SMR)等新型能源以支撑算力中心。
-
去中心化与民主化:通过提升效率,降低算力门槛,防止 AI 算力被少数巨头垄断。
-
产学研协作:呼吁政府建立类似于 NAIRR 的国家级 AI+HW 计划,打破学术界(侧重长期探索)与工业界(侧重短期落地)的藩篱。
论文最后给出了一个带有警示意味的结论:
“我们不能用今天的电网去跑明天的算法。” > 2035 年的胜者,将是那些能同时掌握超低功耗芯片架构、自主 AI 设计工具以及自给自足清洁能源的实体。
论文原文参考:https://arxiv.org/pdf/2603.05225

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)