深入理解大模型量化概念
今天分享有关模型量化相关的技术。然后我们先讲解一下它的基本原理,接着再来介绍一个比较经典也算广泛使用的叫GPTQ这样的量化技术。
一、量化的概念
首先什么是量化呢?一个模型,会有非常多的权重,它在训练过程中,我们基本上都是以浮点数的格式去存储的。因为要计算梯度什么的,必须用带小数点的那些数字去。但浮点数的存储在计算机中,它所要占据的位数就比较多,对吧?比如说我们可能常见的FP32或者FP16,它占据的字节数比较多。那我们想要节省显存或者节省显存带宽的话,我们就需要对模型的这个大小进行压缩。
那怎么压缩呢?我们可以用更低的位数去表示这些数字。比如说把它映射成更低的int 8或者其他的更低精度的int 4等。通过这个数值的它的位数的更少的表示来减小模型的体积。
具体来说是这样的,比如有一组权重,可能是来自同一个tensor的一个权重,或者来自于同一个channel的权重。他们这些元素分布在浮点数的这个范围内,那我把它映射到一个比如说int 8表示的范围内,这里我们举的例子是uniform的变化。也就是说每一组权重映射到相同的这个int值的时候,它的这个量化的步长也是这一组映射到某一个整数值的对应的这个范围,它的距离是相等的。这样的好处就是我们的量化和反量化可以通过元素去乘以或者除以一个scale去表示。
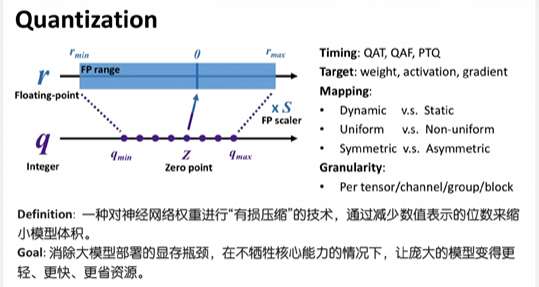
因为这个范围它是均匀的去映射的,那scale要怎么计算呢?其实就是这个范围的最大值和最小值差就代表这个范围的大小。然后去除以我们要量化到的这个精度,它的最大值和最小值的差,就代表这个范围它的缩放。
量化按照不同的维度分类,可以有不同的分类方法。比如说按照量化的时机来讲,有quantization aware training quantization aware functioning以及post training quantization。QAT和QAF是在训练的过程中,我们就对权重进行量化。也就是他训练的时候是知道权重有做量化的,也会对量化后的权重来进行相应的误差的补偿这样的一个训练。
而post training quantization它的使用会更广泛一些,就是不论对于什么权重以及它要量化到具体的某个精度。这个方法post training quantization它都是通用的,也就是它其实性价比会更高。因为像这些training的技术的话,你都要对某个具体的模型,以及它具体要量化到某个某个精度都要进行具体的训练。所以我们后面讲的GPTQ的方法,当然它是肯定是属于PTQ了。它名字也都在PTQ这三个字。
而量化的对象权重肯定是最常见的,那我们这里讲的权重跟模型参数的区别的话是这样,就现在大模型都是transformer,然后它里面的参数除了有我们常见的projection类的,projection是指什么呢?就是一个中间的计算的值去乘以一个权重A * W,W这个权重是固定的,这个activation是根据输入会变化的这样的一类矩阵乘法,我们称为projection。
而在transformer里面大多包括WQ、WK、WV, 也就获取QKV的时候以及attention的输出会有一个WO,还有就是在FFN中现在常用的switchGLU,那可能会包括像gate、up和down这三个,我们通常是对这一些权重进行量化。而还有一些模型参数,比如说projection可能会有bias,A乘完W可能会有这个B。以及Normalization里面,我们norm完一个activation以后,会需要可能乘一个伽马。gamma和b这一些它其实都是形状是向量的这样的一些模型参数,我们一般不会去量化它。而且像对伽马进行量化的话是得不偿失的。在Normalization里面对伽马做量化的话,实际上对模型精度的影响还是蛮大的。所以我们一般只量化这里提到的这一些这七个矩阵。
当然除了权重以外,我们当然也可以量化activation,这在一些端侧的部署上是比较常见的。因为内存会非常紧张,我们可能activation也要做量化。这就是之前讲过的,先用具有代表性的数据跑一遍,认为这些数值就代表真实推理时的输入,那这个时候A和W都做量化的话,它会有一个区别。也就是说权重它本身的范围我们是已知的对吧?因为你模型权重不会根据输入的变化而变化,但是activation根据你输入的token是什么它会变化。所以说它的范围,也就是在我们这里量化的范围它也是会变化的。具体算出来这个scale它也是会变化,所以就会有dynamic跟static的区分。
1.1 dynamic和static
Static的量化是指我在离线的时候,通过一个数据集去profile这个activation它的大小的分布,然后我就确定好这个scale了。Dynamic是指我在具体跑这个模型的时候,我根据当前的activation输入去动态决定这个scale。Static顾名思义,它既然是静态的话,你在运行过程中肯定会有一些activation,可能会超出这个范围,对吧?我们称为outlier。对outlier肯定会有不同的处理的方法。比如说我就把这个outlier直接抛弃掉了,我把它压缩到这个profile出来这个最大值,或者说我可能在计算的时候把它单独拎出来算,这些都是一些不同的量化策略。
除了weight和activation以外,还有gradient。就我们在训练的时候,比如data parallellism,我们可能会让不同卡去跑同一个batch的不同mini batch,就把一个batch拆成不同的mini batch,在不同的卡上去跑。这些卡中就要就需要相互交换这个gradient的信息。那这个通讯量的话可以通过对gradient的量化去减少这个通讯量。
1.2 uniform和non-uniform
Mapping type的话,我们刚刚介绍了dynamic跟static的分类。还有一个是uniform还是non-uniform类,它是什么样分类的?也就是我们前面介绍是uniform分类,也就是映射到相同的整数值,它所对应的这个浮点数表示范围它都是一样宽的,是均匀的。但有些时候我权重的分布可能是不均匀的,那我们可以通过聚类的办法,比如说聚类出我的这个量化后的整数,它有这么几位,那我也对应的浮点数的范围也把这些权重也聚成几类。那我可能比如说一大块需要这一个整数,这一块它比较密集,就影响到这个整数,这个是non-uniform的,量化和反量化这个关系不是均匀的。
所以说我们不能简单的通过计算这个scale来得到,我们必须维护一个code book。比如说对于int 2的话,int 2共有2的2次方,四种整数,那我们就要维护一个相当于一个四个元素的数组,这个代表的是0,映射到一个浮点数,1映射到一个浮点数,2映射到一个浮点,3映射到哪个浮点数。这个code book你可以想象到它的反量化实际上是一个查表的操作,就是我们某一个运元素,比如说它量化成了2,那我查这个code book得到,那反量化结果应该是这个浮点数,那它就会有一些限制,就是一般non-uniform的都会用在低精度的量化里面。
有两个原因,第一个是如果是高精度的话,比如说你要量化成int值,它是有b bit,那你的code book的大小就是二的b次方,这么大个表有可能对会给你这个模型的存储在额外开销,因为你是要跟模型的权重一起存的,你才能做反量化。如果b太大了,它是得不偿失的。第二个是既然是查表的话,你在做反量化的时候可能会需要用到一些设备的查表的指令去做反量化。而那些查表指令往往都会有元素个数或者宽度的限制,所以这个b也不能取得太大。总的来说就是uniform的话,你也可以想象到它在位数比较多的时候,实际上效果也是比较好的。因为你如果你的b比较大的话,就每一个量化步长也会比较窄。而non-uniform的话在低精度的量化上面表现会更好。
1.3 symmetric和asymmetric
还有一个区别是symmetric和asymmetric。也就是说假如我这个权重它本身是关于0对称的话,那我元素的量化转换的话可以通过直接乘以S来实现对吧?但假如如果不对称的话,顶点有一点偏移的话,那我们最好是再保存一个Z叫zero point。Zero point的意思就是说我原来浮点数的范围里这个0它所映射的这个位置。那我反量化可能要做的就是把这个Z给它减回去,也就是W = S (Wq - Z)。
1.4 granularity
最后一个分类维度的话叫granularity,也就是量化的力度。它决定了多少个权重的元素去共享同量化的meta data。Meta data就包括比如说scale、zero point或者code book,有多少个元素去共享这一套meta data。
我们刚刚提到我们会量化的权重,它一般是个矩阵,那不同的力度的话,像per tense,也就是说这整个矩阵它都共享同一套meta data。Per Channel的话就是我们每一行的权重元素去共享一套meta data,per group的话一般是按照channel的里面再去分group,比如说这一个channel,我把它划分成128个元素一个group。而per block的话则不一定是沿着channel进行的,它可能是这个矩阵按照某一个tile的大小,比如说32乘32这样的一个tile大小去划分一个他要内部去共享一个meta date。
不同的策略的话,当然力度越细,肯定是对模型的精度保持是越好的,就因为你会引入更多的meta data,从信息的角度来说,你肯定是引入了更多的信息,压缩比没这么高,但是你保留了更多的信息,效果也越好。但是具体的量化策略要其实有时候要根据硬件去确定。就比如说有些硬件它在计算这个矩阵乘法的时候,它就是按照tile要进行的,那你这个时候可能选择跟硬件大小相同的,它也要去做量化,可能是最好的。但有些加速器它可能不是按照tile要去做乘法的,它可能就是两个矩阵在做乘法的时候就是按照两个向量去做内积,那这个时候你可能就要选择per channel的策略。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)