Reflexion: Language Agents with Verbal Reinforcement Learning论文讲解概括
本文是个人学习时候阅读该篇论文所记录的笔记,可能有总结不到的地方,如有疑问,请评论留言
背景:
问题:基于LLM的智能体很难像传统强化学习那样通过试错快速学习,因为传统方法成本太高,需要大量的数据和微调,计算成本
解决方法
Reflexion框架,不是通过更新权重来强化语言智能体,而是通过语言反馈,用语言强化代替权重强化
机制:
-
语言化反思:智能体将环境反馈转化为自然语言总结。
-
情景记忆:将反思文本存储起来,供后续决策参考。
Reflexion 将来自环境的二元反馈或标量反馈转换为文本摘要形式的语言反馈,然后将其作为额外上下文添加到下一个回合的 LLM 智能体中。这种自我反思的反馈通过为智能体提供一个具体的改进方向来充当“语义”梯度信号,帮助它从先前的错误中学习,从而在任务中表现更好。
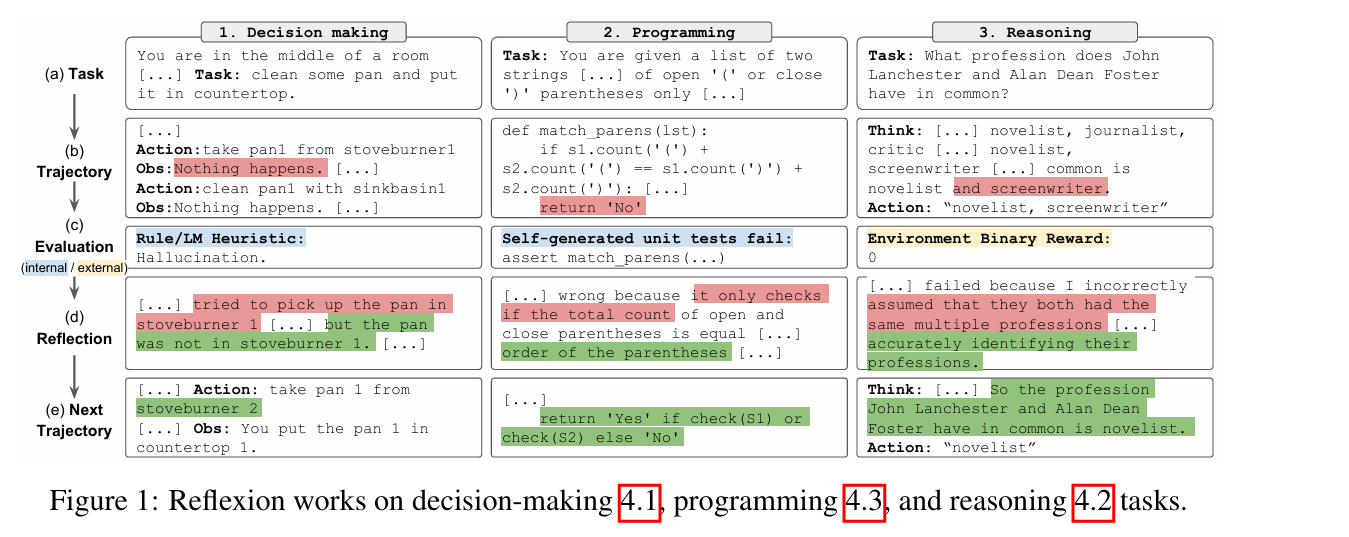
挑战
如何生成有用Reflection是具有挑战性的
-
需要很好地理解模型在哪里犯了错误
-
生成包含可操作改进见解的摘要的能力
三种实现方法:
-
简单的二元环境反馈
-
针对常见失败情况的预定义启发式规则
-
llm自我评估
核心过程就是将评估信号放大,转化为富含语义的自然语言总结
框架
利用了三个不同的模型:一个行动者(Actor),记为 Ma,它生成文本和动作;一个评估者(Evaluator) 模型,记为 Me,它对 Ma 产生的输出进行评分;以及一个自我反思(Self-Reflection) 模型,记为 Msr,它生成语言化的强化线索
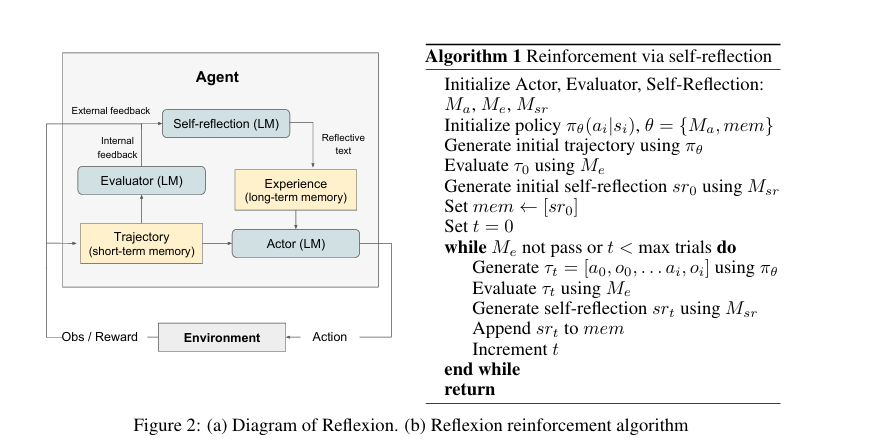
Actor(执行者):
Actor建立在一个大型语言模型之上,该模型被专门提示以根据状态观察生成必要的文本和动作。
我们还添加了一个记忆组件 mem,它为这个智能体提供了额外的上下文
可以灵活集成不同的生成策略,如 ReAct(结合推理与行动)或 思维链。
根据当前观察(环境状态)和记忆中的反思文本,生成要执行的动作或要输出的文本
Evaluator(评估者):
Evaluator在评估行动者生成的输出质量方面起着至关重要的作用;
它生成的轨迹作为输入,并计算一个奖励分数,该分数反映了其在给定任务上下文中的表现
如何得到奖励分数是难点,方法:刚刚三种方式
1.精确匹配,简单的二元环境匹配
2.预定义启发式规则,针对任务领域的常见错误模式,人工编写一系列判断规则,根据规则触发情况,给出奖励或失败信号
3.LLM 本身的另一个实例作为评估者
Self-Reflection(自我反思):
给定一个稀疏的奖励信号、Evaluator的输出、当前轨迹及其持久记忆 mem,自我反思模型会生成细致且具体的语言反馈,被存储在智能体的记忆 mem中
Memory(记忆):
有长期记忆和短期记忆;轨迹历史充当短期记忆,而自我反思模型的输出则存储在长期记忆中;这些记忆会给Actor做参考;
流程:

实验:
在三大任务上进行评估
-
决策(AlfWorld):文本交互环境中的多步骤任务。
-
推理(HotPotQA):基于维基百科的多跳问答。
-
编程(HumanEval等):代码生成与测试。
1.顺序决策制定:ALFWorld
在 134 个 AlfWorld 环境中运行智能体,涵盖六种不同的任务类型,使用 ReAct 作为动作生成器,两种自我评估技术:使用 LLM 的自然语言分类和手写启发式规则。
Baseline:纯 ReAct。当检测到需要反思时(如陷入循环),它直接重置环境并重试,不进行反思,因此无法从错误中学习。
Reflexion 智能体:当检测到需要反思时,它会启动自我反思流程,分析错误、更新记忆,然后再重置重试。
智能体的记忆截断为最后 3 次自我反思,LLM 使用 GPT-3;
result:
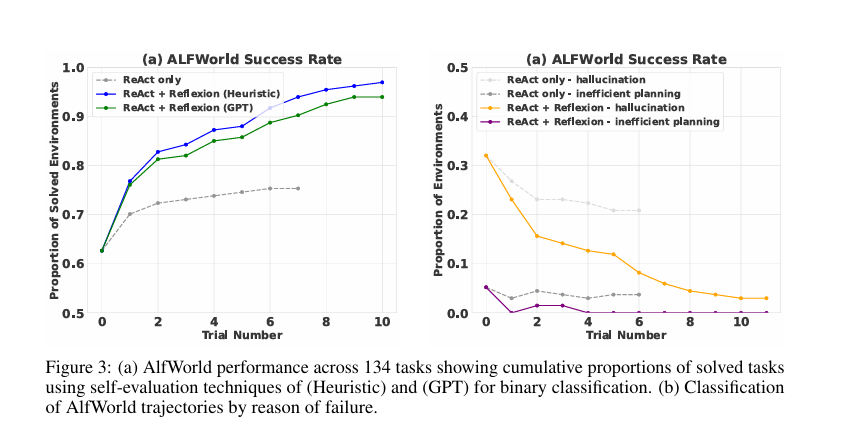
Ya:已解决的环境(任务)比例。
ReAct + Reflexion的曲线在逐渐上升,
Yb:失败轨迹的比例
有幻觉的比例会持续纯在;无效规划的比例也基本不表
通过这个可以判断Reflexion消除了幻觉和无效规划的影响
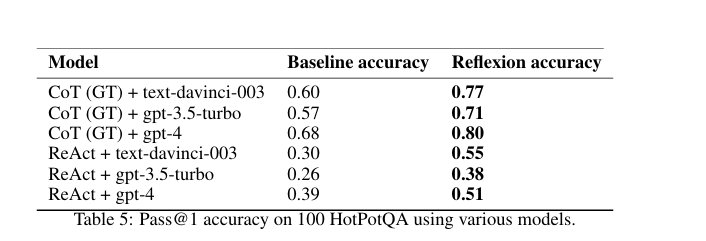
2 推理:HotpotQA
HotPotQA 是一个基于维基百科的数据集,包含113k个问答对;
使用环境进行精确匹配答案评分,为智能体提供二元成功信号。每次试验后,采用自我反思循环来放大二元信号,记忆为最后三次反思
测试纯推理能力的提升,我们实现了 Reflexion + 思维链,用于逐步的 Q→A(Cot) 和 Q,Cgt→A(Cotgt)实现,其中 Q是问题,Cgt是数据集中提供的真实上下文,A是最终答案
测试需要推理和动作选择的整体问答能力,我们实现了一个 Reflexion + ReAct 智能体,它可以使用维基百科 API 检索相关上下文,并使用逐步的显式思维推断答案。
CoT 实现,使用 6-shot 提示;对于 ReAct,使用 2-shot 提示;对于自我反思,我们使用 2-shot 提示
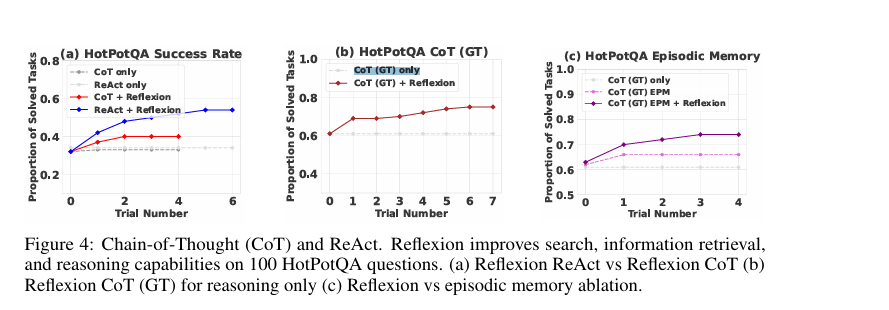
实验a:
1.验证封闭式推理和开放式检索推理的影响
2.验证 Reflexion 对它们的影响
实验b:验证反思机制提升纯推理的能力
实验c:判断提升是来自“简单地看到上次做了什么”,还是来自“深刻地总结上次为什么错”;
-
CoT (GT) only:基线。 -
CoT (GT) + EPM:增加情节记忆(Episodic Memory),即让智能体能看到上次尝试的完整轨迹。 -
CoT (GT) + EPM + Reflexion:在拥有情节记忆的基础上,再加入语言化自我反思步骤。
附录:
“涌现能力”
对于弱模型,Reflexion 框架无效。
一个非常小或弱的模型,即使你教它“反思”的格式,它也无法生成高质量、可操作的反思文本。它的“反思”可能只是重复错误或者给出模糊的建议(标准差减小)。

当模型足够强时候,Reflexion 都带来了显著提升;

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)