Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free门控注意力论文阅读
本文章是针对阅读Qwen提出的门控注意力论文的一个阅读总结,如有不当,可以评论留言
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
背景:
1.门控机制在深度学习中有很长的历史
2.但现有研究很少单独分析门控的作用,往往与其他结构(如稀疏注意力、专家路由)混在一起。
工作:
所以这篇工作就提出了一个很简单的改动:一个简单的修改——在缩放点积注意力后应用头特定的 Sigmoid 门控。
优点:
-
性能提升(比如PPL 降低)
-
训练更稳定(减少 Loss 尖峰,下降更加稳定)
-
能承受更大学习率
-
扩展性更好(模型越大效果越明显)
工作概述:
-
研究对象:标准softmax注意力机制中的门控。
-
研究方法:在注意力机制的不同位置(查询、键、值投影后,SDPA输出后,最终输出后)系统性地引入并比较各种门控变体(元素级/头级、特定头/共享头、加性/乘性)。
-
核心发现:
-
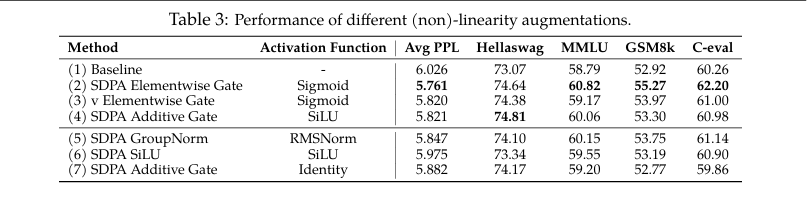
最佳位置:在SDPA输出处应用头部特定门控效果最佳,能显著降低困惑度并提升MMLU等基准测试分数。
-
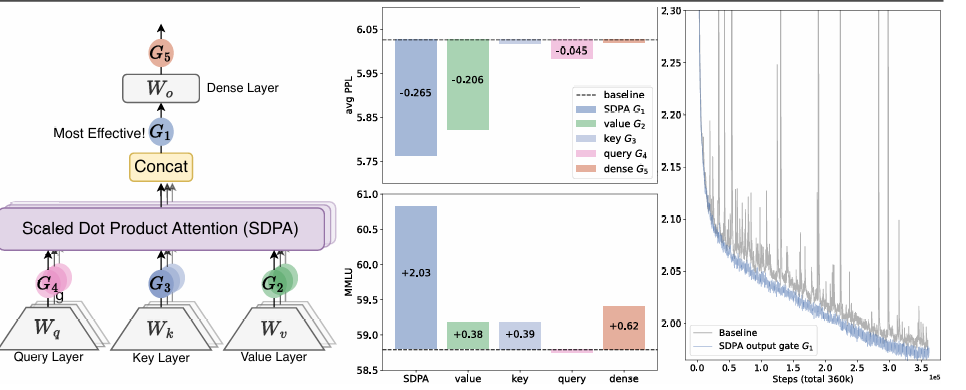
-
稳定性提升:该门控还能极大提高训练稳定性(几乎消除损失尖峰),允许使用更大的学习率,改善模型缩放性质。
-
-
为什么可以很好提升?
-
非线性:注意力机制中的值投影和输出投影实质是低秩线性变换。在SDPA输出或值投影后加入门控,引入了非线性,从而增强了模型的表达能力。
-
稀疏性:最有效的门控(SDPA输出门控)会产生高度稀疏的、输入依赖的门控分数。这种稀疏性是关键。
-
消除注意力沉没:上述查询依赖的稀疏门控能够有效消除“注意力沉没”现象。这使得模型展现出优异的长上下文外推能力。
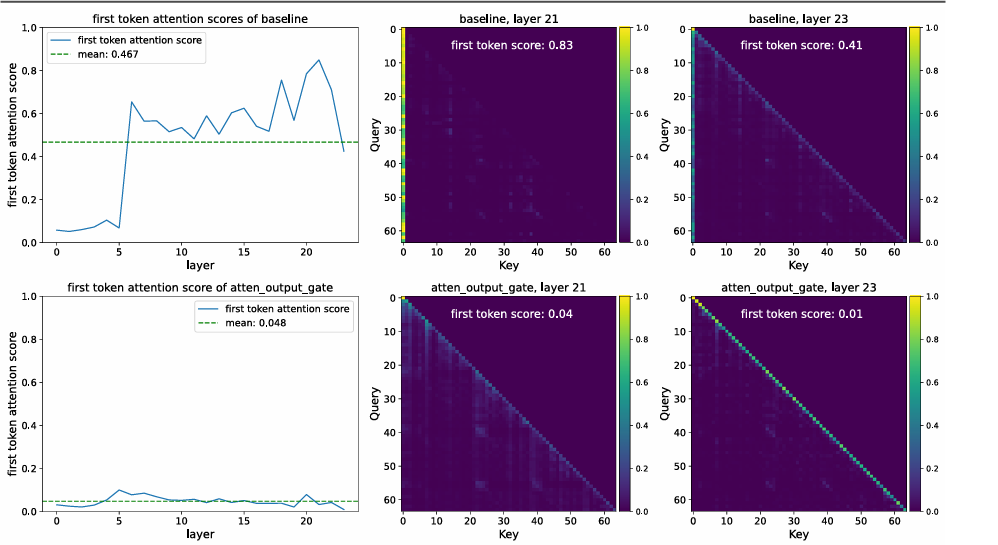
左:每一层分配给序列第一个token的注意力比例
右:展示了基线模型在第21层和第23层的注意力权重分布
门控:
门控机制的形式化定义为:
![]()
Y是SDPA的输出,X(n,d)是当前 token 的经过注意力层 pre-norm 后的隐藏状态(用于生成门控分数),Wθ(d,d)是门控的可学习参数,σ是激活函数(如 sigmoid),Y′ 是门控后的输出。
作用:这一设计使门控分数依赖于当前查询 token(query-dependent),从而实现动态信息过滤,通过选择性保留或擦除Y的特征来控制来自Y的信息流。
在Gated Attention中引入了门控函数,这种门控函数将原本的“低秩线性”变为“低秩+非线性”,大幅提升函数表达能力。
实验:
模型架构与训练设置 在混合专家模型和稠密模型上均进行了实验。 MoE模型使用了128个专家,采用top-8 softmax门控、细粒度专家、全局批次的负载均衡损失和z-loss。在注意力部分采用了GQA。
训练数据集:在一个包含多语言、数学和通用知识的3.5万亿高质量token的数据子集上训练模型。上下文序列长度设置为4096。
由于门控引入的参数和计算量很小,其带来的实际时间延迟低于2%。
为了公平比较,补充了参数扩展方法,包括增加q头数量(第2行)、增加v头数量(第3行),以及增加专家总数和激活专家数(第4行)。这些方法引入的参数数量与门控机制相当或更多。
评估 在流行的基准测试上测试了少样本学习的结果,包括用于英语的Hellaswag、用于通用知识的MMLU、用于数学推理的GSM8k、用于代码生成的HumanEval,以及用于中文能力的C-eval和CMMLU。
Result:
-
最佳门控位置:在SDPA的输出之后 或 在V映射之后 添加门控效果最好。这能显著降低困惑度,并在所有基准测试上提升性能,效果甚至优于简单地增加模型参数(如增加注意力头数或专家数量)且增加的参数量更少。
-
头特定门控的重要性:必须为每个注意力头单独计算门控分数。如果所有头共享同一个门控分数,性能提升会大打折扣。这表明门控机制需要精细到每个头,才能有效发挥其作用。
-
乘法门控优于加法门控:使用乘法形式(sigmoid)比加法形式(SiLU)效果更好。
-
激活函数选择:使用Sigmoid激活函数比使用SiLU效果更好。
-
结论:在SDPA输出或值层添加逐头的乘法门控,是一个高效(仅增加极少量参数和计算开销)且有效的模型改进方法。
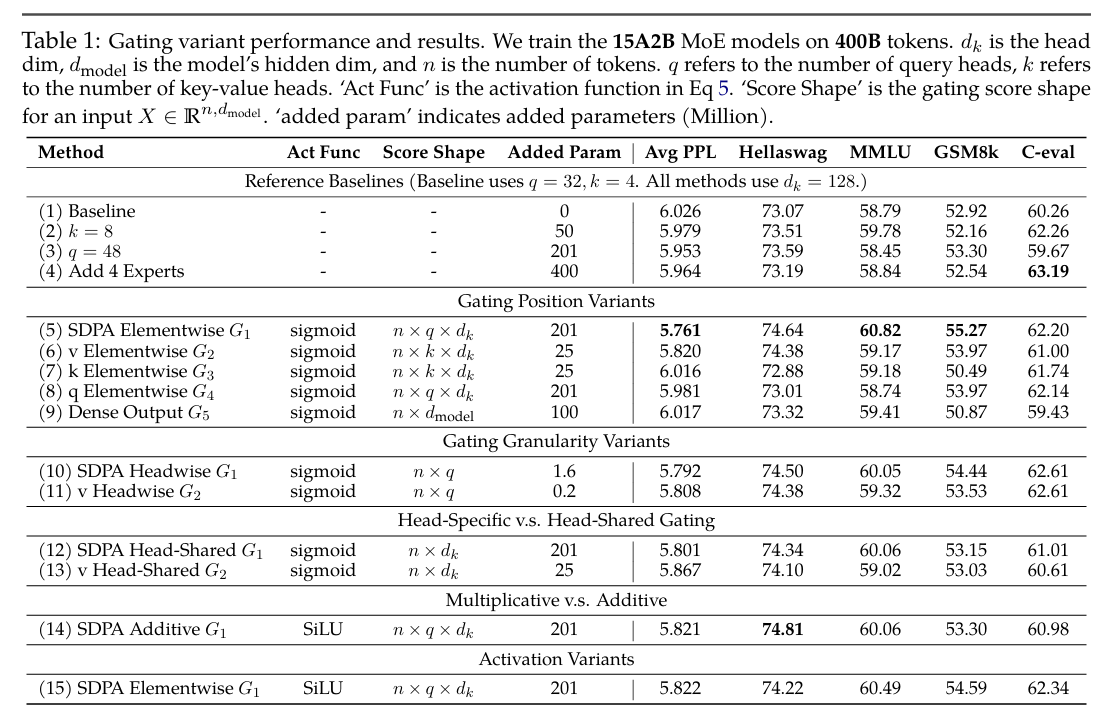
同时,他们也在稠密模型上进行了实验,来验证“SDPA输出门控”在稠密模型上同样有效
为了控制参数变量,当使用门控时,我们会减少FFN的宽度以保持参数量不变。
结果:
验证有效性:实验首先证实了在MoE模型上表现最好的“SDPA输出门控”在稠密模型上同样有效
提升训练稳定性:门控机制被证明能够显著提高训练过程的稳定性。它允许模型在原本会导致基线模型训练失败(发散)的更大学习率下进行稳定训练。这使得研究人员可以采用更激进的训练策略来追求更好的模型性能
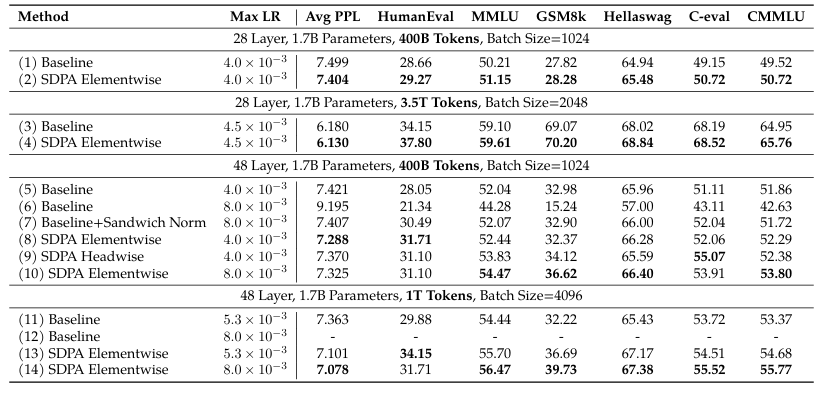
为什么门控机制是有效的?
非线性、稀疏性、消除AttentionSink
非线性增强了低秩映射的表达能力
在传统的标准多头注意力块中,每个注意力头的就算都是低秩线性变换;这种线性变换的表达能力是有限的;
但是在Gated Attention中引入了门控函数,这种门控函数将原本的“低秩线性”变为“低秩+非线性”,大幅提升函数表达能力。

实验结果
-
非线性的价值:所有在W_V和W_O之间引入非线性的方法(第2-5行),其困惑度都显著低于基线,验证了“非线性增强低秩映射表达能力”的核心论点。
-
乘法门控优于加法门控
-
归一化也是一种有效的非线性:第5行的RMSNorm虽然不叫“门控”,但它同样在G1位置引入了非线性变换,效果也不错,且几乎不增加参数。
输入相关的稀疏性:动态过滤无关上下文
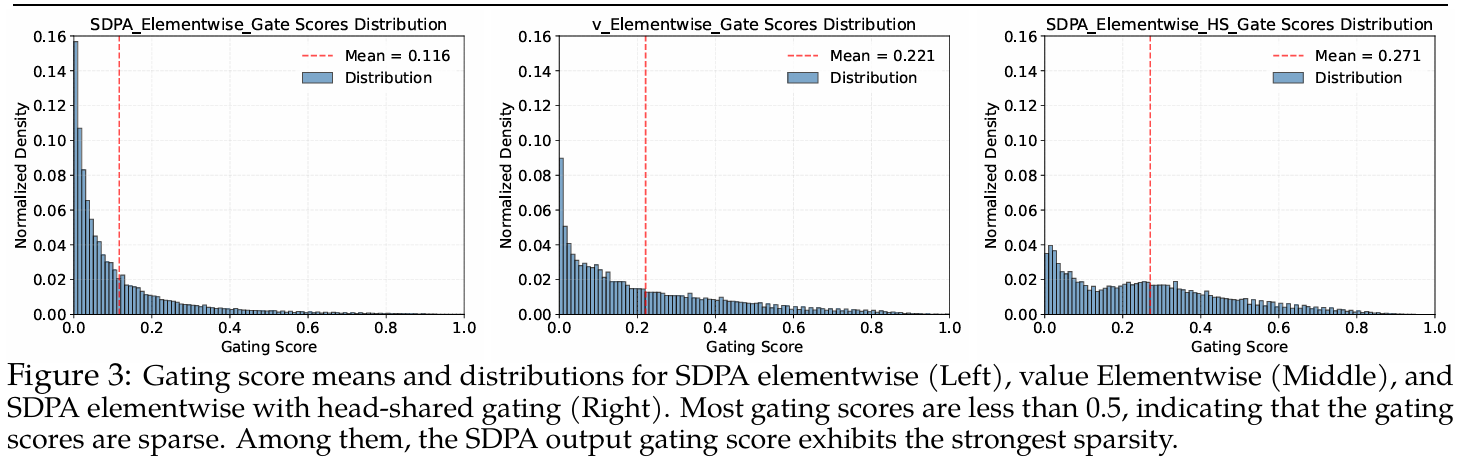
实验显示,SDPA逐元素门控 输出门控的平均门控值仅为 0.116,且分布高度集中在 0 附近,表明其具有强稀疏性。更重要的是,该门控基于当前查询 token 的隐藏状态计算,因此是查询依赖的(query-dependent)——模型能动态判断“哪些历史上下文对当前 token 无关”,并主动抑制其贡献(图Left),而SDPA头共享门控效果最差(图right)
相比之下,Value 层门控(G2)基于历史 token 的状态计算,无法感知当前查询意图,其门控值更高(0.221),稀疏性更弱,性能也相应较差。(图Middle)这进一步证明:有效的门控必须是稀疏且由当前 token 驱动的。
消除注意力沉没
门控注意力将首 token 的注意力占比降至 4.8%,同时将最大激活值从 1053 降至 94。值得注意的是,Value 层门控虽能抑制巨量激活,却无法消除注意力池,说明巨量激活并不是注意力池的充分要条件。只有通过查询相关的稀疏门控,才能同时根除这两个现象。
实验结果看本文图二

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)