开源数据集下载使用超详解—GEFCom 2014 负荷预测部分—含自研完整打包代码
⚡ GEFCom2014:电力负荷预测界的“顶流”数据集全解析
写这个的原因是,最近打算写一个负荷预测的会议论文,然后找到了这个比较有名的数据集,找到了数据集和对应的论文之后,读取和解析整体的结构和字段就成为了一个比较大的问题,网上找了一堆资料没人说的清楚,最后让gemini,给我半解释带猜,我才总结出来了。然后也是记录一下,我觉得还是比较有意义的。
文章目录
1. 为什么它是绕不开的经典?
如果你正在从事能源电力预测(Energy Forecasting)相关的研究,或者正准备投一篇电力负荷预测的会议论文,那么 GEFCom2014 (Global Energy Forecasting Competition 2014) 这个名字你一定会频繁刷到。它是 2014 年由 Tao Hong 教授等人组织的一场全球性顶级赛事。之所以被称为经典,是因为它标志着能源预测领域的一个重大范式转移:从“点预测(Point Forecasting)”全面转向“概率预测(Probabilistic Forecasting)”。
2. 数据集赛道分类
虽然本文重点讨论 Load(负荷) 预测,但完整的数据集其实涵盖了能源领域的四大核心赛道:
- Load (L): 电力负荷预测 ⚡
- Price §: 电价预测 💰
- Wind (W): 风力发电预测 🌬️
- Solar (S): 光伏发电预测 ☀️
3. 数据集下载地址
我找到的下载地址如下,这个下载链接中包含了GEFCom2014的全部数据集。
🔗 下载链接:Kaggle - GEFCom2014 Dataset
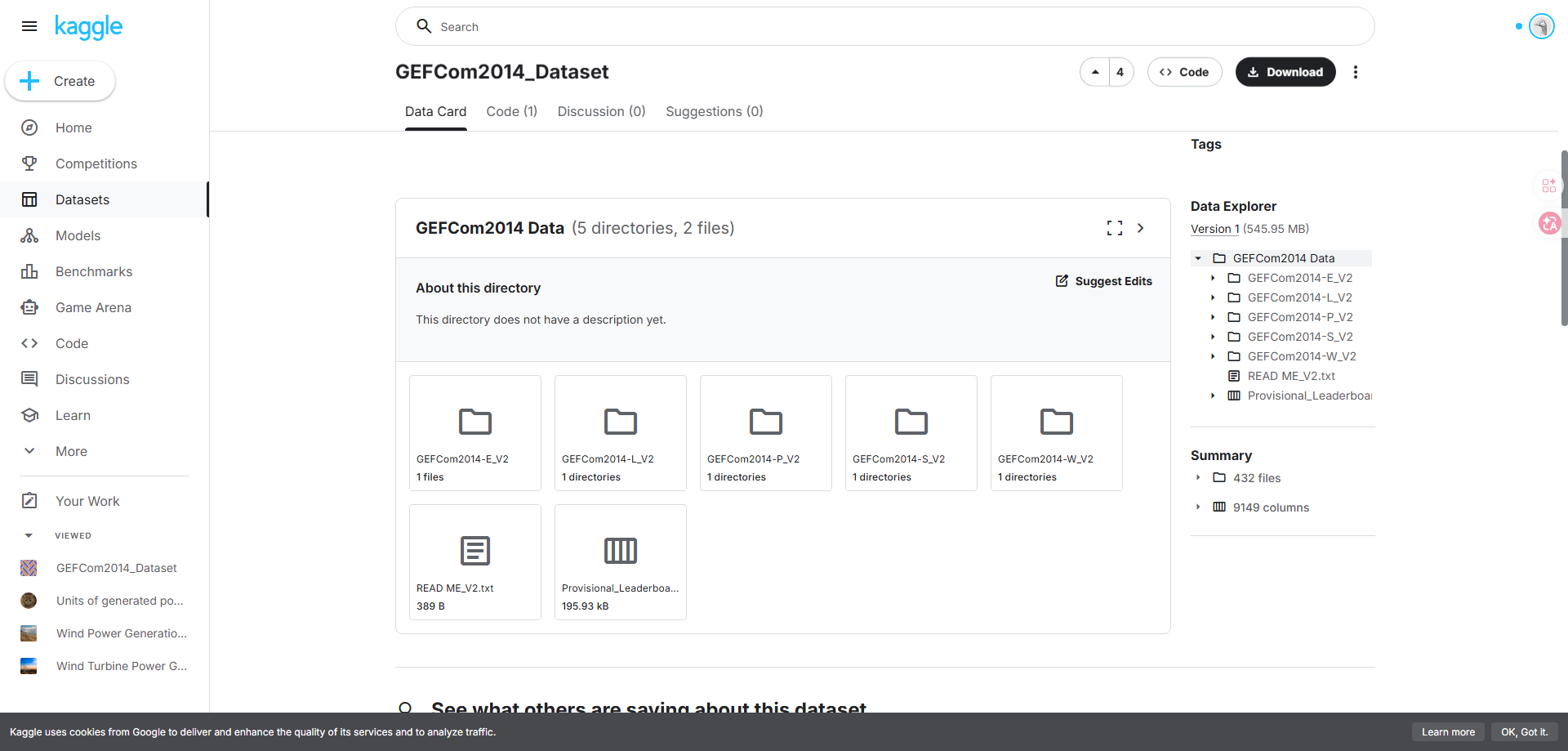
4. 📂 GEFCom2014 数据集目录结构解析
数据集刚下载下来是这样,然后里面有4个文件夹1个excel,和一个txt文件。

| 文件夹/文件名称 | 类型 | 内容描述 | 关联赛道 |
|---|---|---|---|
GEFCom2014-E_V2 |
文件夹 | 负荷预测扩展赛道(Extended)。包含 2015 年 Tao Hong 教授组织的校内竞赛数据,主要针对一年期的概率负荷预测任务。 | Load (E) |
GEFCom2014-L_V2 |
文件夹 | 电力负荷预测赛道。核心赛道数据,包含某美国电力公司的历史小时负荷及 25 个气象站的温度数据。 | Load (L) |
GEFCom2014-P_V2 |
文件夹 | 电价预测赛道。包含区域边际电价(LMP)、区域负荷预测值及系统级负荷预测值。 | Price § |
GEFCom2014-S_V2 |
文件夹 | 光伏发电预测赛道。包含澳洲 3 个光伏电站的功率及来自 ECMWF 的 12 个气象预报变量。 | Solar (S) |
GEFCom2014-W_V2 |
文件夹 | 风电预测赛道。包含澳洲 10 个风电场在 10m 和 100m 高度的风速分量(u, v)预报及功率数据。 | Wind (W) |
Provisional_Leaderboard_V2.xlsx |
Excel | 官方评分记录与排行榜单。包含各赛道 15 个任务的提交日志(Log)、详细评分(Score)以及最终符合评审要求的选手名单(Eligible)。 | 全赛道 |
READ ME_V2.txt |
文本 | 数据集官方说明。由 Tao Hong 教授编写,详细说明了数据集的版本更迭、各赛道数据的单位、版权声明及数据使用许可。 | 全赛道 |
5. 📂 GEFCom2014_L_V2 (负荷预测赛道)目录结构解析
我们这次看的负荷预测的数据在GEFCom2014_L_V2 文件夹里,然后点进去之后还有一个孤零零的Load文件夹,再点进去出现文件目录结构如下:
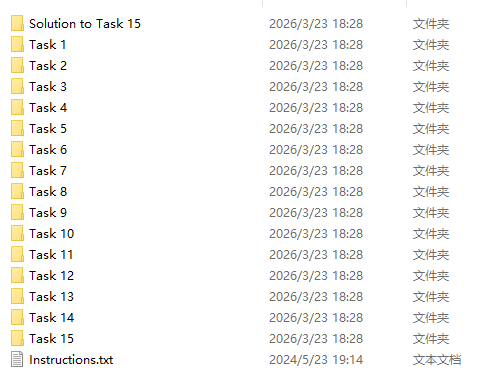
在 Load 文件夹下,共有 15 个 Task 文件夹(对应 15 个滚动预测任务)。每个 Task 文件夹内通常包含两个核心 CSV 文件,其组织逻辑如下:
| 文件夹名称 | 内部核心文件 | 包含内容与数据特征 |
|---|---|---|
| Task 1 (最特殊) | L1-train.csv |
初始超长训练集。跨度为 2001-01-01 至 2010-09-30。⚠️ 关键点: 前 4 年(2001-2004)仅有天气数据(w1-w25),负载(LOAD)列为空;有效负荷数据从 2005-01-01 才开始 。 |
L1-benchmark.csv |
基准模型预测值。包含 10 月份 744 个小时的 99 列分位数预测占位符 。 | |
| Task 2 ~ 14 | Lx-train.csv |
月度增量数据。每个文件包含上一个月的真实负荷和天气。例如 L2-train 包含的是 2010 年 10 月的实测值 。 |
Lx-benchmark.csv |
对应月份模板。规定了该阶段需要预测的月份和 99 列分位数的提交格式 。 | |
| Task 15 | L15-train.csv |
最后一份增量数据。补齐了 Task 14 预测月份的实测值。 |
L15-benchmark.csv |
收官预测目标。针对评估周期最后一期的预测模板。 |
6. 📊 核心数据文件解析:四类 CSV 的字段与物理意义
在深入了解这个数据集最精妙的“滚动预测”机制之前,我们需要先“解剖”一下数据集里的底层文件。整个 GEFCom2014-L_V2/Load 目录下,满打满算其实只有 四类 CSV 文件。
按照出现的位置,我们可以将它们分为两组:
- 基础组(Task 1 ~ Task 15 均有):
Lx-train.csv和Lx-benchmark.csv - 收官组(仅在 Solution 文件夹出现):
solution15_L.csv和solution15_L_temperature.csv
💡 核心预测目标: 在所有文件中,名为
LOAD的字段就是我们需要预测的终极目标(代表电力系统实际的负荷/功率)。这场比赛的本质,就是利用历史的 LOAD 数据和气象特征,去预测未来一个月 LOAD 值的 99 个概率分布区间。
下面是这四类文件的核心字段与物理意义的详细拆解:
- ①
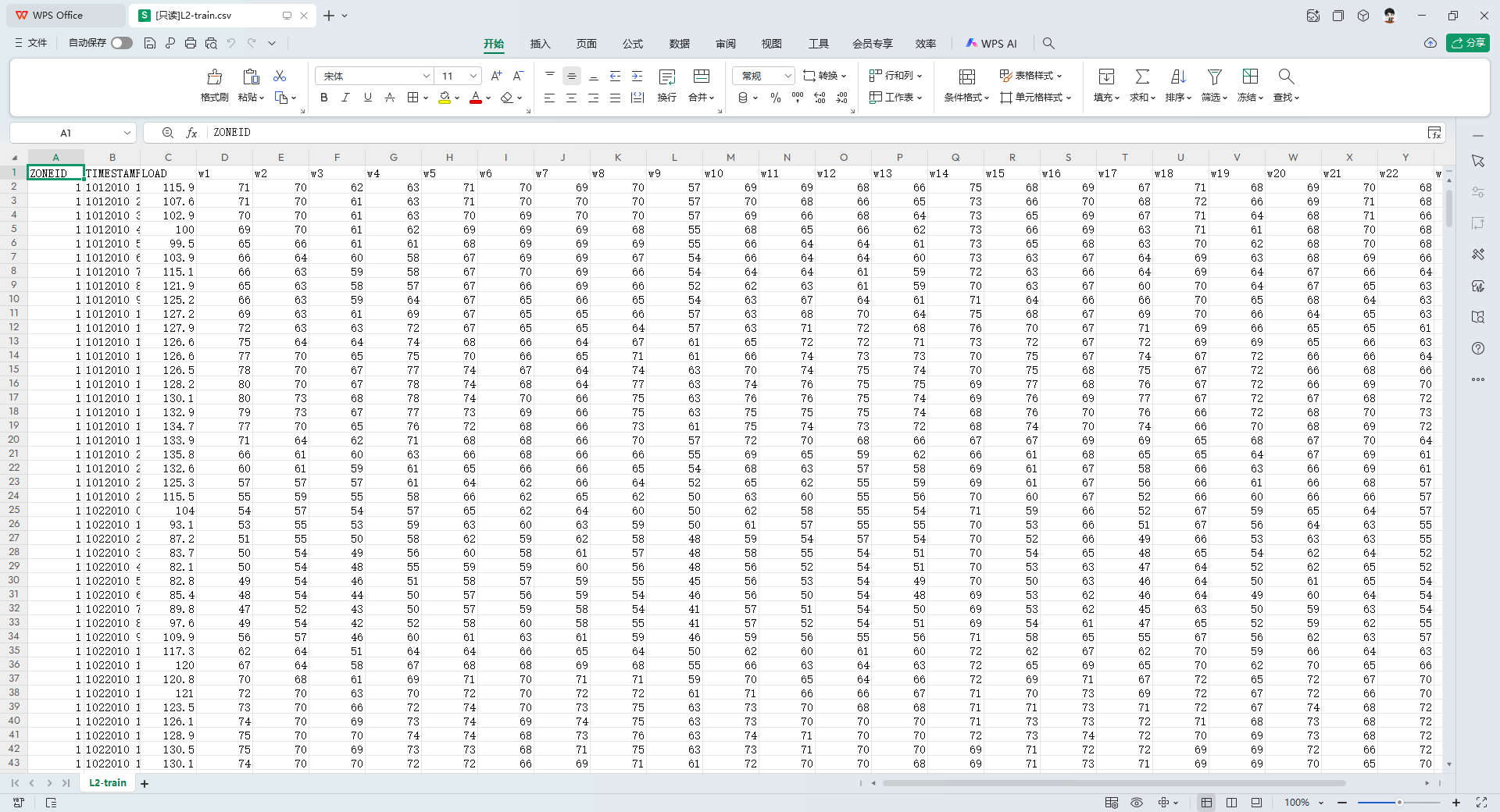
Lx-train.csv:历史训练集数据
这是你训练模型的核心“口粮”,Task 1 到 Task 15 的文件夹中都存在。 ZONEID:区域编号。在这个负荷赛道中全量固定为1,代表该匿名电力公司所在的唯一供电区域。TIMESTAMP:时间戳。格式通常为M/D/YYYY H:00,代表具体的按小时计的时间点。LOAD:【核心预测目标】 该时段实际的电力负荷值(官方未公开具体单位,推测通常为兆瓦 MW)。w1 ~ w25:天气特征(Weather/Temperature)。代表分布在目标区域附近的 25 个匿名气象站记录的真实温度数据(华氏度 °F)。注意:赛题官方并没有告诉你这 25 个气象站的具体经纬度或权重。
- ②
Lx-benchmark.csv:提交模板与基准
这是官方提供的预测格式模板文件,规定了你在该 Task 阶段需要预测的时间范围和格式。 ZONEID&TIMESTAMP:对齐你需要预测的未来一个月的具体小时时间戳。0.01 ~ 0.99(共计 99 列):要求填入的 概率预测分位数(Quantiles)。与传统的点预测只给出一个确定的功率值不同,这里要求你给出从 1% 到 99% 的 99 个可能的值,用以描绘未来电力负荷的概率分布情况。官方 Benchmark 已经在这里填入了他们跑出的基准参考值。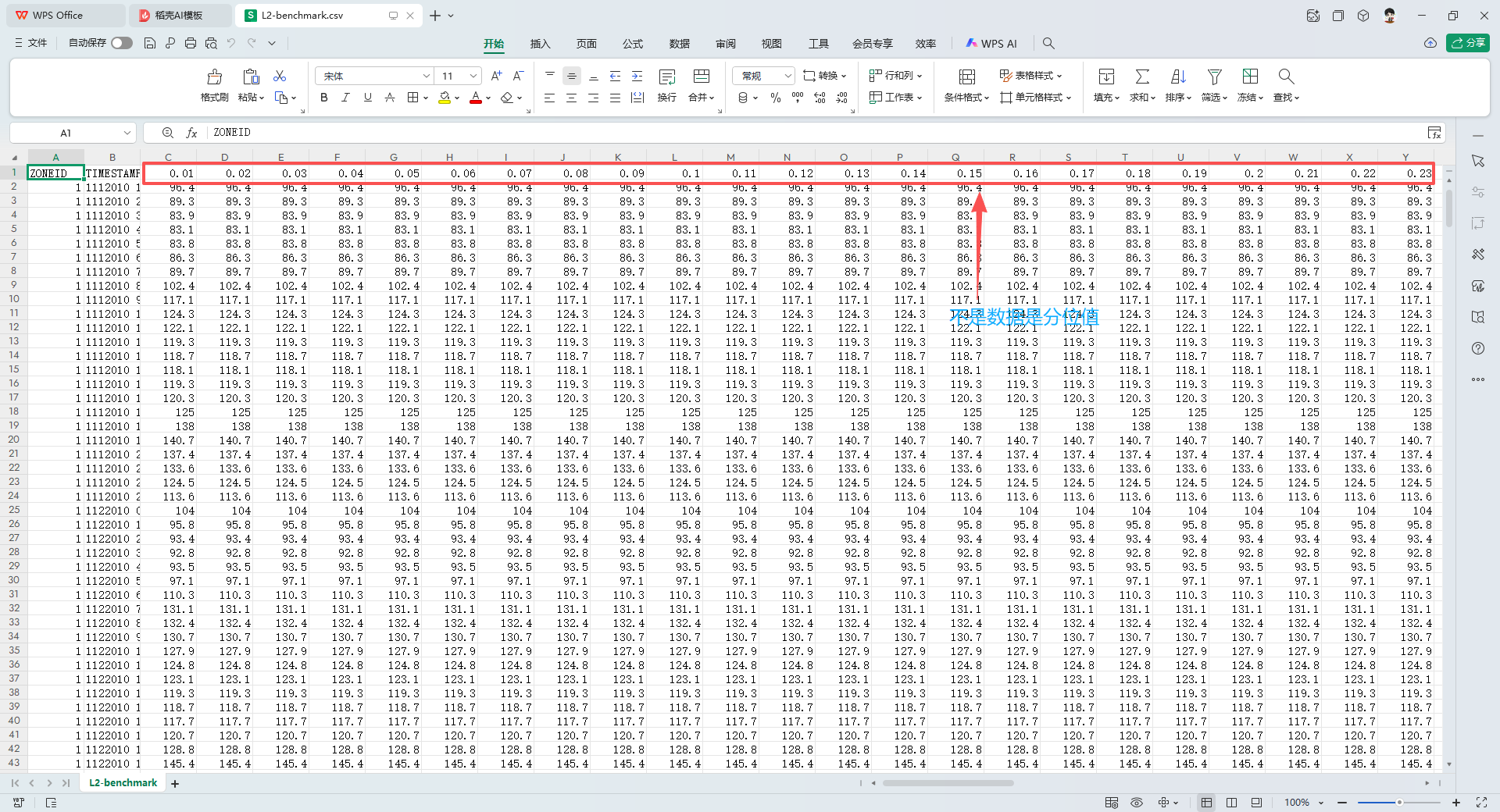
- ③
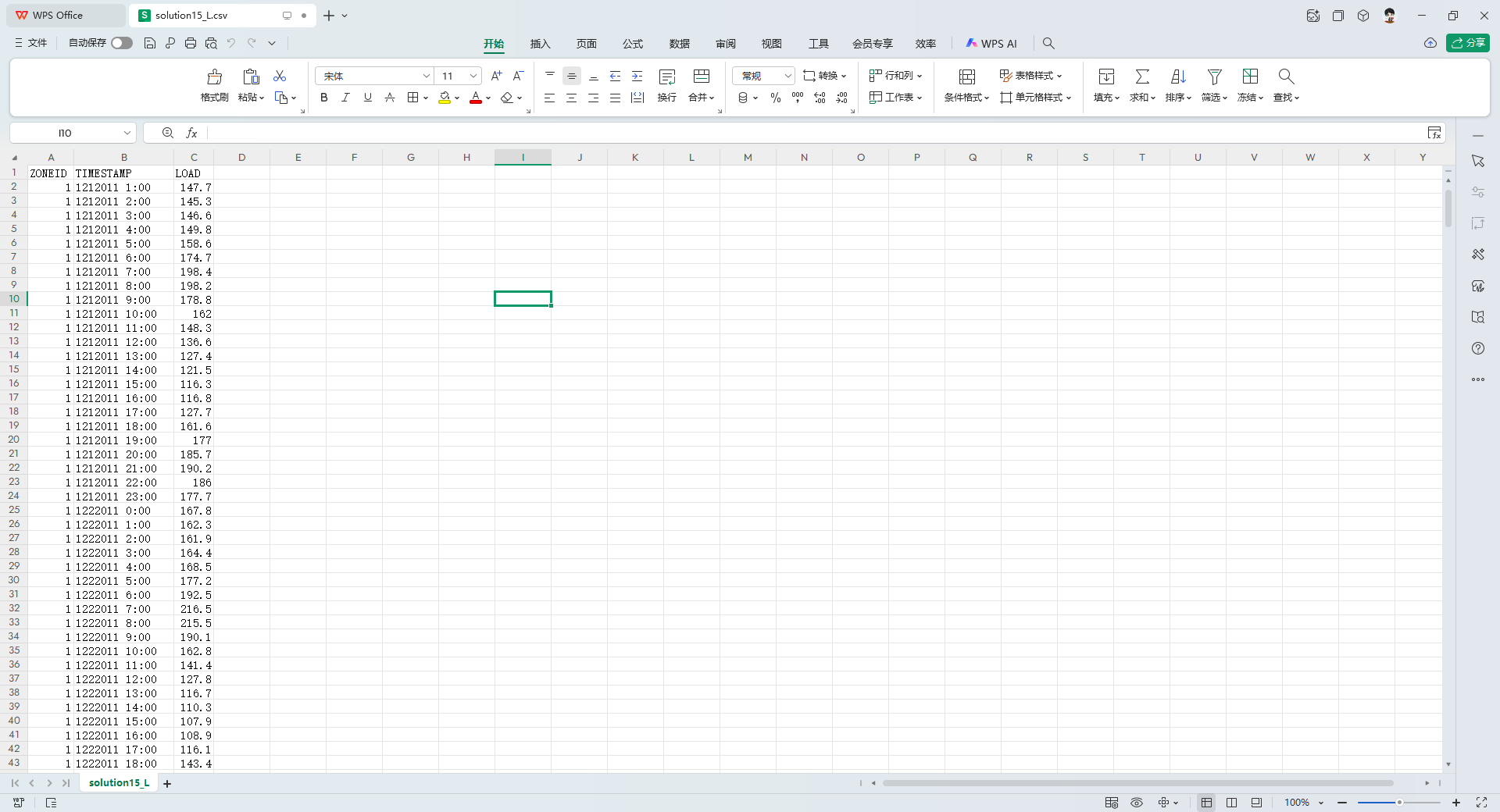
solution15_L.csv:收官时刻的负荷真值
此文件仅存在于Solution to Task 15文件夹中。它是整个系列赛最后一个任务(Task 15)的最终答案核对表。 - 字段:仅包含
ZONEID、TIMESTAMP和LOAD。 - 物理意义:直接给出了 Task 15 评估期(即最后一个预测月)每个小时的实际电力负荷真值,官方当年就是用它来计算选手的最终 Pinball Loss 评分的。
- ④
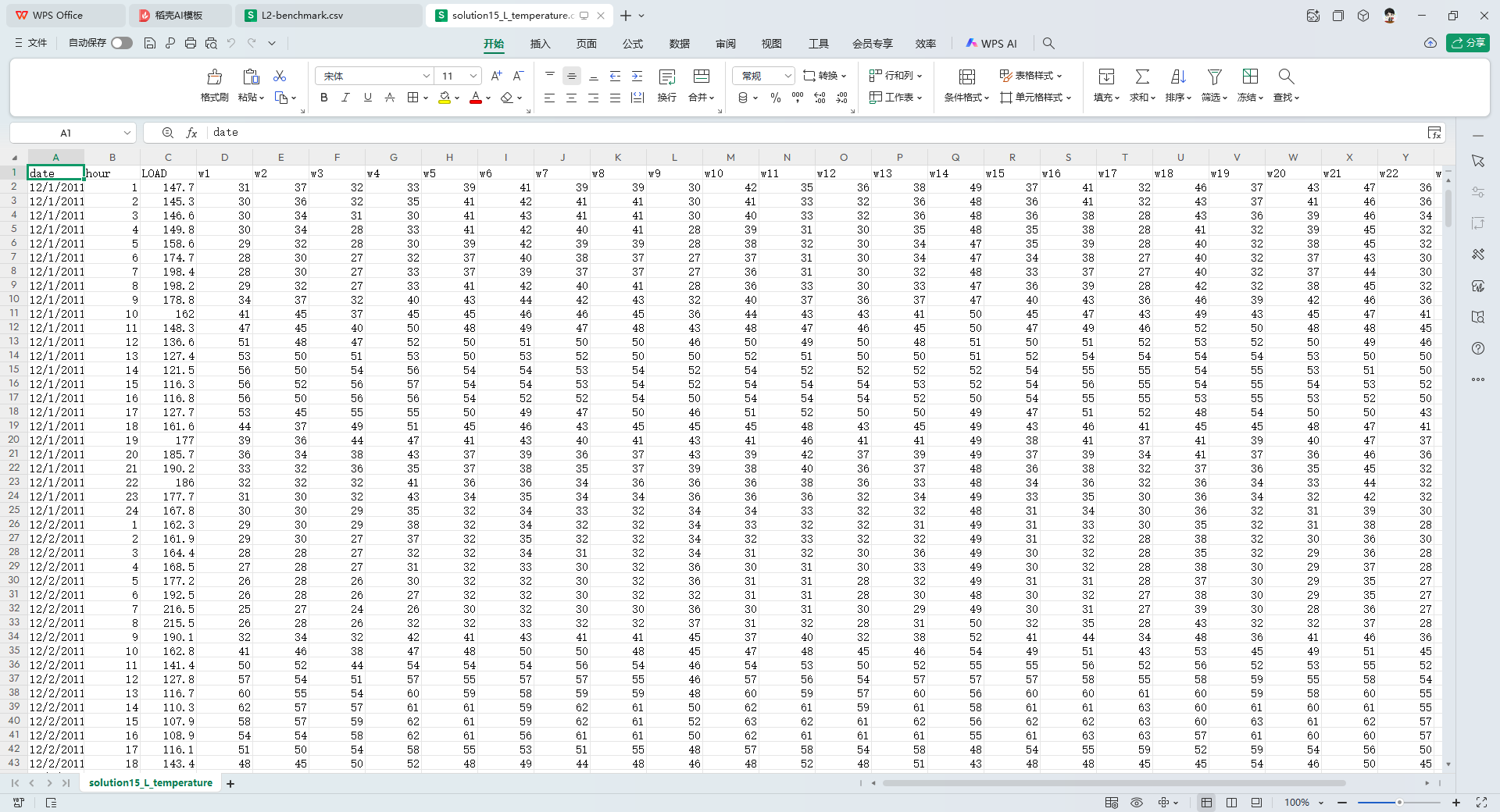
solution15_L_temperature.csv:收官时刻的完整真值档案
同样仅存在于Solution to Task 15文件夹中,它是整个比赛落幕后官方释出的最全数据档案。 date&hour:将原本的 TIMESTAMP 拆分成了具体的日期和小时。LOAD:评估期的实际电力负荷。w1 ~ w25:评估期 25 个气象站的实际记录温度。这部分数据可以在比赛结束后,供参赛者或研究人员进行离线复盘和论文数据实验。
搞清楚了这四类数据文件的结构,以及我们的“终极预测目标(LOAD)”后,我们再来看这个数据集最令人头疼、但也最贴近工业界真实场景的设计——滚动预测逻辑。
7. 🔄 滚动预测逻辑:训练集、测试集与标签的“套娃”关系
GEFCom2014-L 并不是一个静态的“一次性”数据集,它通过 15 个连续的 Task 模拟了现实工业界中的 滚动预测(Rolling Forecasting) 场景。这也是该数据集最精妙、最贴近真实业务逻辑的设计之处。
在这个机制下,训练集、测试目标和真实标签之间形成了一种有趣的“位移”关系。我们可以用下表清晰地理清这个逻辑:
| 阶段 (Task) | 你的“已知”训练数据 (Training Set) | 你要预测的“目标” (Testing Target) | 对应的真实负荷标签在哪里? (Ground Truth) |
|---|---|---|---|
| Task 1 | L1-train.csv (2005年 - 2010年9月) |
预测 2010年10月 的负荷 | 藏在 L2-train.csv 的开头部分 |
| Task 2 | L1 + L2 (累加了10月的真实数据) |
预测 2010年11月 的负荷 | 藏在 L3-train.csv 的开头部分 |
| Task 3 | L1 + L2 + L3 |
预测 2010年12月 的负荷 | 藏在 L4-train.csv 的开头部分 |
| … | … | … | … |
| Task 15 | L1 + … + L15 |
预测 2011年12月 的负荷 | Solution to Task 15 文件中 |
💡 关键理解点(避坑指南)
-
增量式拼接(Incremental Learning)
- 当你处理 Task N N N 时,你的输入数据不是单独的一个文件,而是需要从
L1-train一直垂直拼接(Concatenate)到LN-train。 - 随着任务推进,你的训练集会像滚雪球一样越来越大,包含的历史信息越来越丰富。
- 当你处理 Task N N N 时,你的输入数据不是单独的一个文件,而是需要从
-
标签的“位移”现象
- 这是一个非常巧妙的设计:
L2-train.csv里的负荷数据,其实就是你在 Task 1 里绞尽脑汁想要预测的“标准答案”;同理,L3-train.csv是 Task 2 的答案。 - 现实意义:这模拟了真实世界中,到了11月初,调度中心终于拿到了10月份完整的真实负荷报表,并立即将其用于更新模型以预测11月的情况。
- 这是一个非常巧妙的设计:
-
Task 1 的“冷启动”
L1-train是最庞大的原始积累,提供了长达5年以上的历史负荷基线。- 从 Task 2 开始,后续的
Lx-train文件通常只包含上个月的新增数据(约744行),专门用来给你“喂”最新的市场变化信息。
8. 🎯 概率预测怎么算分?揭秘 Pinball Loss 与物理意义
在理清了数据是如何“滚动”给出的之后,我们会面临一个直击灵魂的问题:
真实的标签(Ground Truth)明明只有一个确定的功率值,但我却要预测 99 个分位数,这卷子到底怎么批改?
- 传统的点预测 vs. 概率预测
- 点预测(Point Forecasting):
- 目标:输出一个具体的值(例如:“预测明天中午负荷是 100 MW”)。
- 评价:使用 MSE(均方误差)或 MAE(平均绝对误差),误差越小越好。
- 概率预测(Probabilistic Forecasting,本赛题要求):
- 目标:输出从 1% 到 99% 的 99 个分位数(Quantiles)。
- 评价:为了评估这 99 个值构成的概率分布是否准确,竞赛采用了 Pinball Loss(弹球损失函数,也称分位数损失函数)。
- 99 个分位数的物理意义:描绘“风险防线”
为什么非要算 99 个值?因为在现实的电力系统中,仅仅“猜得准中心点”是远远不够的,甚至可能引发大祸。
假设你预测 90% 分位数( τ = 0.90 \tau=0.90 τ=0.90) 的值为 120 MW。
- 物理含义:“作为预测模型,我有 90% 的把握,明天的真实负荷绝对不会超过 120 MW。”
- 作用:这相当于给电网调度员画了一条 “风险防线”。
- ✅ 防线守住:如果实际负荷只有 110 MW,说明预测安全,调度员可以放心。
- ❌ 防线击穿:如果实际负荷飙升到 130 MW,说明小概率的高负荷事件发生了,现实中这可能意味着拉闸限电或设备过载。
- Pinball Loss 是如何“惩罚”模型的?
Pinball Loss 的核心魔法在于 “不对称惩罚”。它根据你预测的分位数 τ \tau τ 不同,对“高估”和“低估”施加不同的惩罚力度。
以评估 90% 分位数( τ = 0.90 \tau=0.90 τ=0.90) 为例:
| 预测情况 | 场景描述 | 惩罚权重 | 后果分析 |
|---|---|---|---|
| 预测偏高 | 模型预测 130 MW,实际只有 120 MW。 (模型比较保守,包住了真实值) |
1 − τ = 0.1 1 - \tau = \mathbf{0.1} 1−τ=0.1 | 轻罚:虽然浪费了一点备用容量,但保证了安全,损失很小。 |
| 预测偏低 | 模型预测 115 MW,实际却有 120 MW。 (防线被击穿,发生漏报) |
τ = 0.9 \tau = \mathbf{0.9} τ=0.9 | 重罚:引发了停电风险!损失函数会给模型一记重拳,惩罚力度是前者的9倍。 |
数学公式表达:
L τ ( y , y ^ ) = { ( 1 − τ ) ⋅ ( y ^ − y ) if y < y ^ ( 高估 ) τ ⋅ ( y − y ^ ) if y ≥ y ^ ( 低估 ) L_\tau(y, \hat{y}) = \begin{cases} (1-\tau) \cdot (\hat{y} - y) & \text{if } y < \hat{y} \quad (\text{高估}) \\ \tau \cdot (y - \hat{y}) & \text{if } y \ge \hat{y} \quad (\text{低估}) \end{cases} Lτ(y,y^)={(1−τ)⋅(y^−y)τ⋅(y−y^)if y<y^(高估)if y≥y^(低估)
(其中 y y y 是真实值, y ^ \hat{y} y^ 是预测的分位数值)
- 最终得分意味着什么?
官方的最终评分,会将你预测的 q = 0.01 q=0.01 q=0.01 到 q = 0.99 q=0.99 q=0.99 这 99 个分位数 的 Pinball Loss 分别算出来,然后求 平均值。
如果一个模型的平均 Pinball Loss 非常低,这证明了:
- 中心准:它的中位数(50%分位数)预测很准。
- 区间准:它对系统 不确定性的估计(Uncertainty Quantification) 非常精准。
- 它没有盲目自信(导致高分位数防线频繁被击穿,遭受重罚)。
- 它也没有过度保守(为了安全给出一个极宽的区间,导致低分位数也被重罚)。
简而言之,优秀的模型能够完美地描绘出未来电力波动的真实概率分布形状,为电网的安全经济运行提供最可靠的决策依据。
9.数据一体化打包输出代码⭐
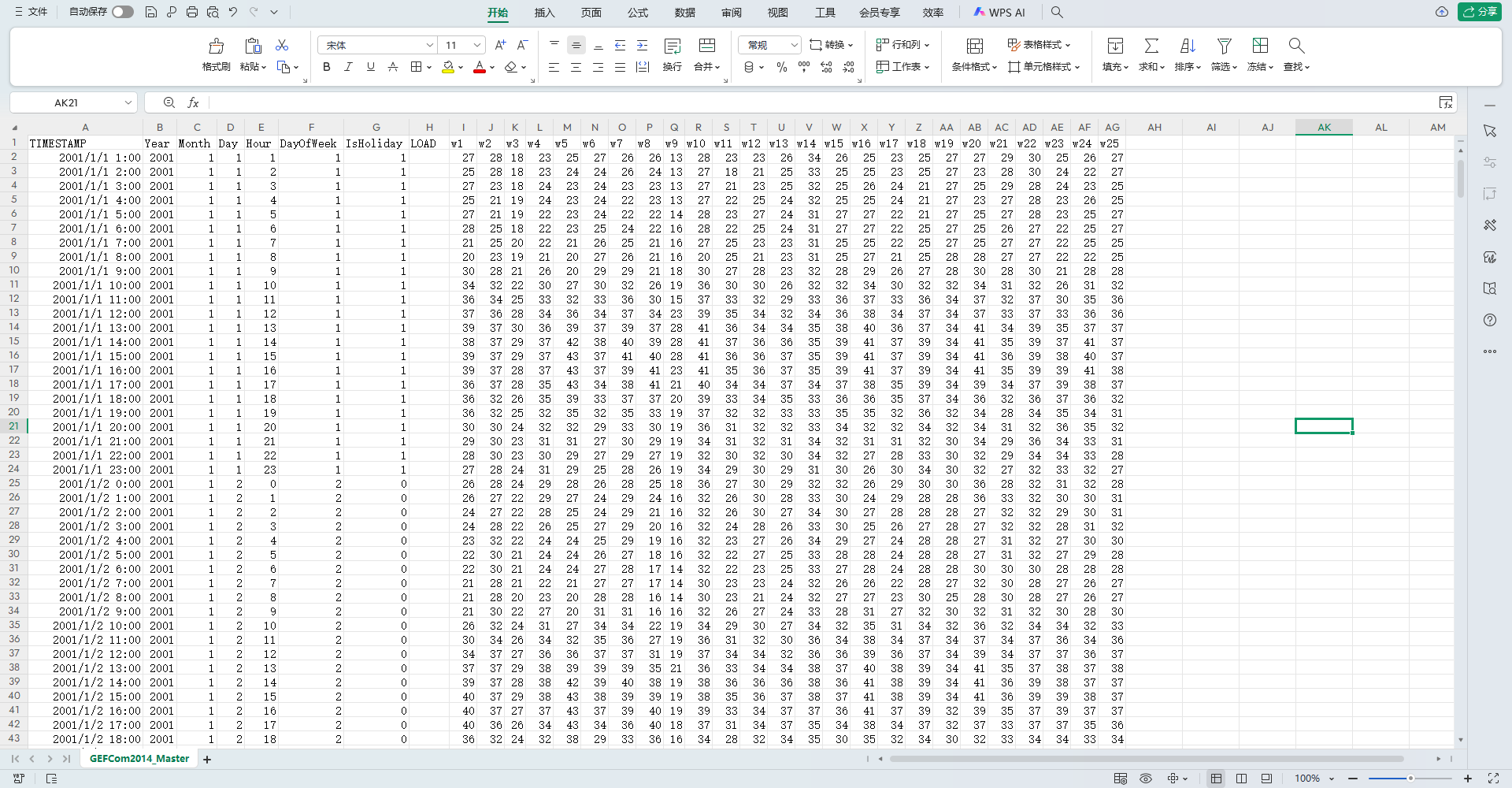
做了一晚上最关键的部分来了,我觉得他这个文件给的数据结构最终形式还是比较混乱的,然后就规整了下,将不同Task的数据都连到一起得到一个完整的文件,然后再把年月日,周几,日期这类东西都加上,甚至还加了一列是否为美国节假日的变量,最后你会得到一个无敌之表如下。
代码逻辑比较复杂,对大多数人来说没必要,运行用就行了,打包代码如下:
import pandas as pd # 导入数据处理神库 Pandas
import os # 导入操作系统接口库,用于处理文件路径
import holidays # 导入节假日库,用于自动判断美国法定节假日 这个 pip install holidays 安装一下自己
def build_and_save_master_matrix(base_path, output_csv):
all_chunks = [] # 初始化一个空列表,用于装载所有的碎片数据块
# === 1. 读取 15 个基础训练集 ===
for i in range(1, 16): # 循环遍历 1 到 15 个 Task 文件夹
file_path = os.path.join(base_path, f"Task {i}", f"L{i}-train.csv") # 拼接出每个 L{i}-train.csv 的完整路径
if os.path.exists(file_path): # 如果该文件存在(防止报错)
df = pd.read_csv(file_path) # 读取该 CSV 文件为 DataFrame
df = df.drop(columns=['TIMESTAMP', 'ZONEID'], errors='ignore') # 暴力丢弃残次品时间戳列和全是 1 的无用 ZONEID 列
all_chunks.append(df) # 将处理后的数据块塞入列表中
# === 2. 读取带温度的 Solution 真值表 ===
sol_path = os.path.join(base_path, "Solution to Task 15", "solution15_L_temperature.csv") # 拼接最终真值文件的路径
if os.path.exists(sol_path): # 如果真值文件存在
sol_df = pd.read_csv(sol_path) # 读取真值文件
valuable_cols = ['LOAD'] + [f'w{j}' for j in range(1, 26)] # 只提取我们需要的目标值 LOAD 和 25 个温度特征 w1~w25
all_chunks.append(sol_df[valuable_cols]) # 将提取后的真值块也塞入列表中
# === 3. 垂直拼接所有数据 ===
full_df = pd.concat(all_chunks, ignore_index=True) # 将列表里的所有数据块首尾相连,无缝拼成一个长表
# === 4. 重建绝对连续的时间轴 ===
full_df['TIMESTAMP'] = pd.date_range(start="2001-01-01 01:00:00", periods=len(full_df),
freq="h") # 从 2001年1月1日凌晨1点开始,按小时(h)向下生成等长的时间戳
# === 5. 提取时间衍生特征 ===
full_df['Year'] = full_df['TIMESTAMP'].dt.year # 提取年份 (如 2001)
full_df['Month'] = full_df['TIMESTAMP'].dt.month # 提取月份 (1-12)
full_df['Day'] = full_df['TIMESTAMP'].dt.day # 提取日期 (1-31)
full_df['Hour'] = full_df['TIMESTAMP'].dt.hour # 提取小时 (0-23)
full_df['DayOfWeek'] = full_df['TIMESTAMP'].dt.dayofweek + 1 # 提取星期几 (1=周一, 7=周日)
# === 6. 提取美国法定节假日 ===
us_holidays = holidays.US(years=full_df['Year'].unique().tolist()) # 获取数据集中涵盖的所有年份的美国节假日字典
full_df['IsHoliday'] = full_df['TIMESTAMP'].dt.date.apply(
lambda x: 1 if x in us_holidays else 0) # 如果当前日期在节假日字典中则记为 1,否则记为 0
# === 7. 整理最终列排版并导出 ===
time_cols = ['TIMESTAMP', 'Year', 'Month', 'Day', 'Hour', 'DayOfWeek', 'IsHoliday'] # 定义时间与节假日特征的列顺序
weather_cols = [f'w{j}' for j in range(1, 26)] # 定义 25 个气象站点的列顺序
final_cols = time_cols + ['LOAD'] + weather_cols # 将所有列拼接成最终的完美排版:时间 -> 目标负荷 -> 天气
final_matrix = full_df[final_cols] # 按照最终排版重组矩阵
# === 8. 保存为 CSV 文件 ===
final_matrix.to_csv(output_csv, index=False) # 将大矩阵保存为 CSV 文件,index=False 代表不保存前面的行号
print(f"✅ 处理完毕!数据已完美保存至: {output_csv} (总行数: {len(final_matrix)})") # 打印成功提示及总行数
return final_matrix # 返回该矩阵供程序继续使用
# ================= 测试与运行 =================
if __name__ == "__main__":
base_dir = "./GEFCom2014-L_V2/Load" # 设定数据集所在的根目录
output_file = "GEFCom2014_Master.csv" # 设定想要保存的最终 CSV 文件名
df_master = build_and_save_master_matrix(base_dir, output_file) # 调用函数,执行拼接并保存
pd.set_option('display.max_columns', None) # 解除 Pandas 打印时隐藏列数的封印
pd.set_option('display.width', 1000) # 加宽控制台的打印宽度,防止换行错乱显示难看
print("\n【独立日节假日检查 (预期 IsHoliday 为 1)】:") # 打印提示语
print(df_master[(df_master['Year'] == 2011) & (df_master['Month'] == 7) & (df_master['Day'] == 4)].head(
3)) # 打印 2011 年 7 月 4 日(美国独立日)的前 3 个小时数据
记得改成自己的路径
代码运行结果如下: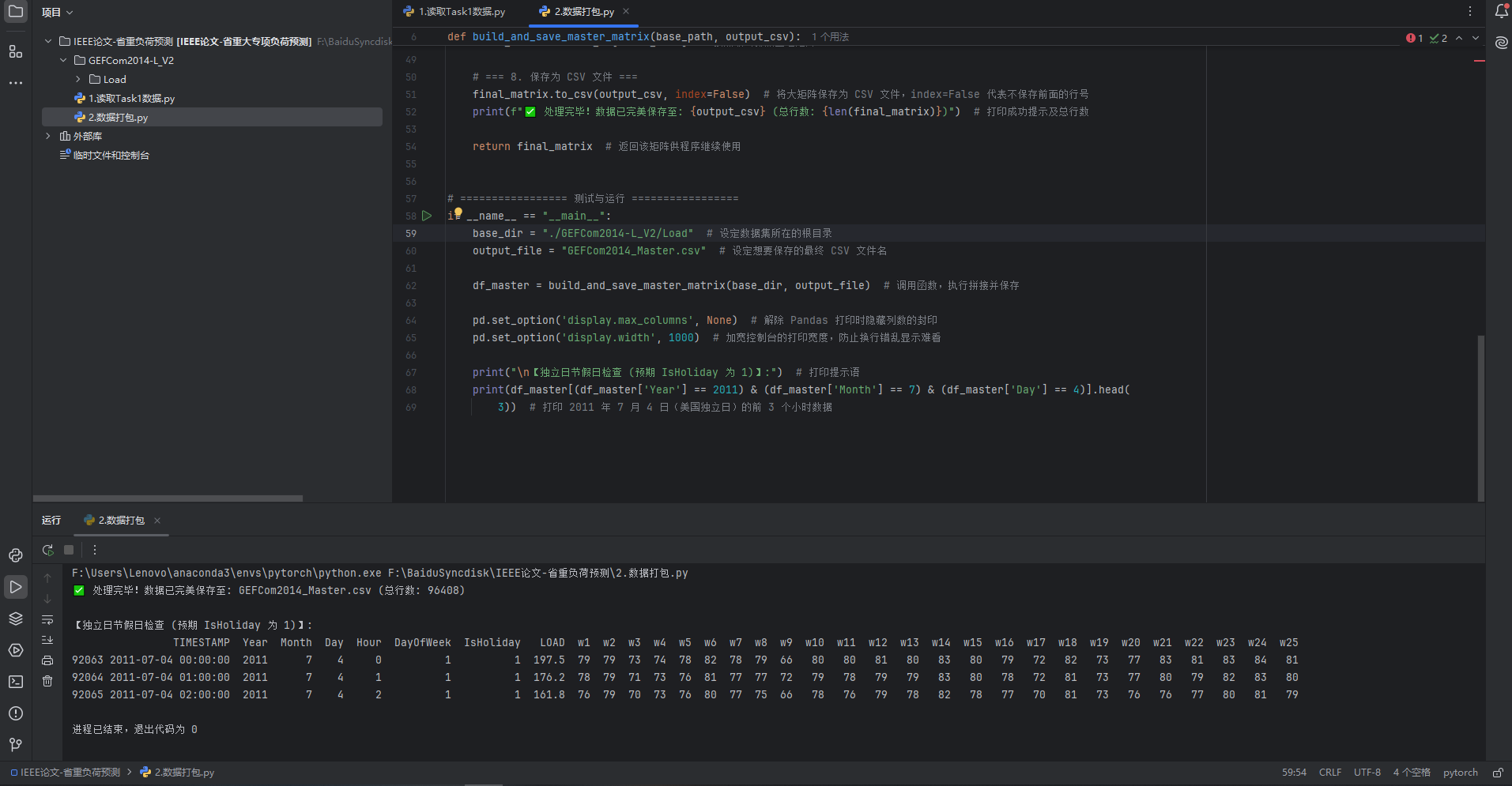
10.总结
写完了成就感还是挺明显的,希望能帮助到更多的人。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)