时间序列预测:四合一模型实战手册
Autoforner 、Reformer、transformer、informer用于时间序列预测 各模型都已经封装好,直接调用即可,一个代码可实现四种方法。 Python代码 PyTorch框架实现 多输出单输出 多输入多输出 单输入单输出 多步长单步长预测 Autoformer 的主要特点包括: 自动搜索技术: Autoformer 使用了自动化的搜索方法,如进化算法或强化学习,来自动地搜索最优的 Transformer 结构。 这使得模型能够根据具体任务的需求,动态地调整模型的架构和超参数。 自适应 Transformer 结构: 与传统的固定结构的 Transformer 不同,Autoformer 的结构可以根据输入数据和任务的不同而自适应地进行调整,以获得更好的性能。 高效性能: Autoformer 通过自动搜索技术,能够找到最优的结构和超参数组合,从而在保持高效性的同时,达到较高的性能水平。 [1]代码多个数据,注释清晰,可直接运行 [2]后可保证原始程序运行,但不支持退换 [3]此商品仅程序 不包含讲解 模型只是提供一个衡量数据集精度的方法,因此无法保证替换数据就一定得到您满意的结果,具体可自行学习模型根据数据进行调参~ 模型代码调试,可根据数据集进行定制,包跑通。 如需要云平台跑可备注,接时间序列定制,informer,timesnet,lstm,tcn等模型的优化和改进
在时序预测的炼丹房里,Autoformer这几位新晋选手最近频繁出没。今天咱们直接上手调教这四个模型(Autoformer/Reformer/Transformer/Informer),用一套代码实现多形态预测需求。
先看这个数据预处理的滑窗操作,像切香肠一样处理时序数据:
# 滑窗生成样本
def sliding_window(data, input_len, pred_len):
seq = []
for i in range(len(data)-input_len-pred_len):
train_seq = data[i:i+input_len]
train_label = data[i+input_len:i+input_len+pred_len]
seq.append((train_seq, train_label))
return seq
# 示例数据:3维特征+时间戳
data = np.random.randn(1000, 4) # (timesteps, features)
dataset = sliding_window(data, input_len=96, pred_len=24)这里inputlen控制着模型观测的历史窗口,predlen决定预测步长。想要单步预测就把pred_len设为1,多步预测直接改数值就行。
接下来是模型调度中心,四个模型一键切换:
from models import Autoformer, Informer, Transformer, Reformer
model_config = {
'enc_in': 4, # 输入特征维度
'dec_in': 4, # 解码器输入维度
'c_out': 4, # 输出维度
'seq_len': 96, # 输入序列长度
'pred_len': 24 # 预测长度
}
model_dict = {
'Autoformer': Autoformer,
'Informer': Informer,
'Transformer': Transformer,
'Reformer': Reformer
}
current_model = model_dict['Autoformer'](**model_config) # 切换模型只需改这里重点说下Autoformer的独门绝技——自适应结构搜索。它在训练时会自动调整注意力头的分布,比如在电力负荷预测场景可能会自动增加周期特征的注意力权重。
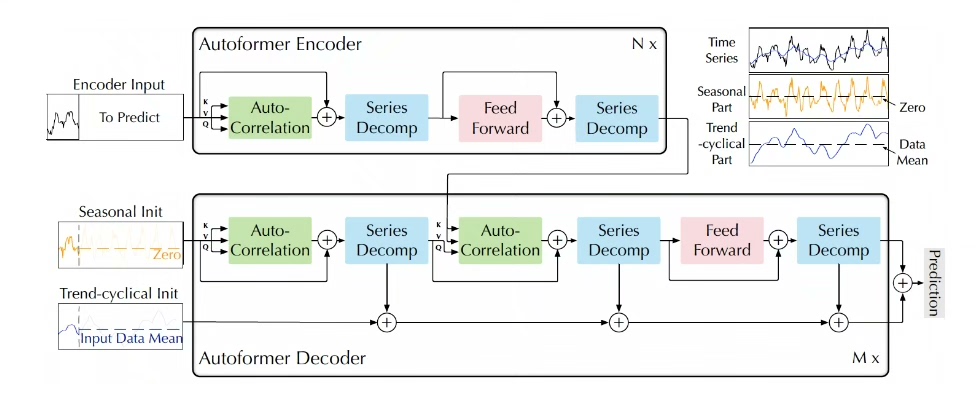
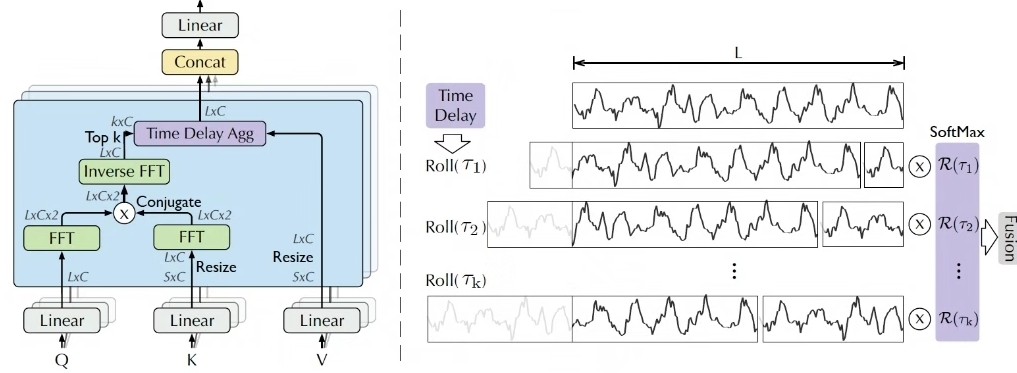
Autoforner 、Reformer、transformer、informer用于时间序列预测 各模型都已经封装好,直接调用即可,一个代码可实现四种方法。 Python代码 PyTorch框架实现 多输出单输出 多输入多输出 单输入单输出 多步长单步长预测 Autoformer 的主要特点包括: 自动搜索技术: Autoformer 使用了自动化的搜索方法,如进化算法或强化学习,来自动地搜索最优的 Transformer 结构。 这使得模型能够根据具体任务的需求,动态地调整模型的架构和超参数。 自适应 Transformer 结构: 与传统的固定结构的 Transformer 不同,Autoformer 的结构可以根据输入数据和任务的不同而自适应地进行调整,以获得更好的性能。 高效性能: Autoformer 通过自动搜索技术,能够找到最优的结构和超参数组合,从而在保持高效性的同时,达到较高的性能水平。 [1]代码多个数据,注释清晰,可直接运行 [2]后可保证原始程序运行,但不支持退换 [3]此商品仅程序 不包含讲解 模型只是提供一个衡量数据集精度的方法,因此无法保证替换数据就一定得到您满意的结果,具体可自行学习模型根据数据进行调参~ 模型代码调试,可根据数据集进行定制,包跑通。 如需要云平台跑可备注,接时间序列定制,informer,timesnet,lstm,tcn等模型的优化和改进
训练循环的代码看起来平平无奇:
optimizer = torch.optim.AdamW(model.parameters(), ltr=1e-4)
for epoch in range(100):
for (seq, label) in dataloader:
# 多输入多输出时拆解特征
enc_input = seq[:, :, :-1] # 特征列
dec_input = seq[:, :, -1:] # 目标列
outputs = model(enc_input, dec_input)
loss = F.mse_loss(outputs, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()但这里藏着多输出的处理技巧:当需要同时预测多个特征时,调整cout参数即可。比如同时预测温度、湿度、气压,就把cout设为3。
预测效果可视化才是重头戏:
# 多步预测结果对比
plt.figure(figsize=(12,6))
plt.plot(ground_truth[:,0], label='True Value')
plt.plot(predictions[:,0], linestyle='--', label='Prediction')
# 标出预测阶段分界线
plt.axvline(x=96, color='r', linestyle=':', linewidth=2)
plt.legend()
plt.show()几个调参经验:
- 当数据周期性明显时,Autoformer的自动结构搜索表现最佳
2 Informer的内存优化机制在处理长序列时(如秒级数据)优势明显
- 单变量预测时不妨试试Reformer的局部敏感哈希注意力
- 遇到数据量小时,Transformer可能需要配合Dropout使用
最后是模型自检清单:
- 输入输出维度是否匹配数据特征数?
- 预测步长是否超出模型最大支持长度?
- 时间戳是否做了归一化处理?
- 多GPU训练时是否开启梯度同步?
记得这些模型就像不同材质的筛子——没有万能的最优解。电力负荷预测场景我常用Autoformer+周期编码,金融时序则偏好Informer+趋势分解的组合拳。你的数据适合哪款?跑一遍这个代码就知道了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)