基于TCN-BiGRU-Attention的Matlab多变量回归预测模型——创新点与实用性的...
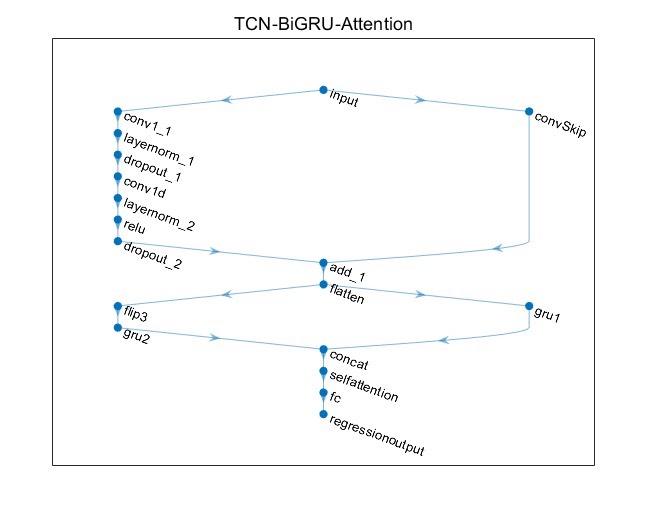
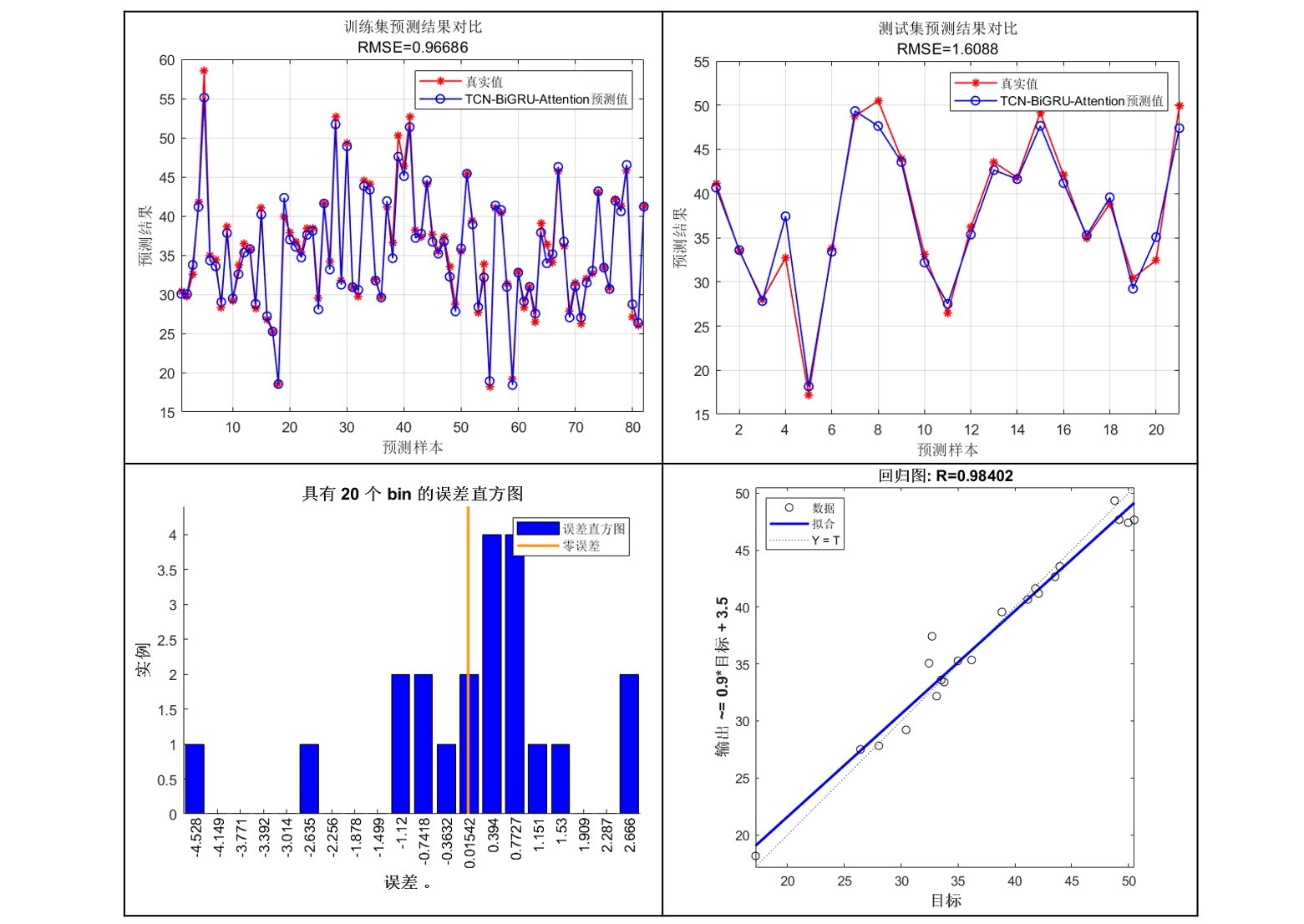
TCN-BiGRU-Attention基于时间卷积网络-双向门控循环单元结合注意力机制的多变量回归预测 Matlab语言 程序已调试好,无需更改代码直接替换Excel运行 你先用,你就是创新 多变量单输出,回归预测也可以提前加好友换成分类或时间序列单列预测,回归效果如图1所示~ 模型网络结构如图2所示,非常新颖适合作为创新点先用先发 也可以增加各类优化算法,如冠豪猪CPO、蜣螂DBO等等,需要请提前加好友 (Matlab版本需要在2023及以上,没有的我可以提供安装包) 注: 1.附赠测试数据,数据格式如图4所示~ 2.注释清晰,适合新手小白运行main文件一键出图~ 3.商品仅包含Matlab代码,后可保证原始程序运行 4.模型只是提供一个衡量数据集精度的方法,因此无法保证替换数据就一定得到您满意的结果~
最近在折腾时间序列预测的时候发现了个挺有意思的玩意儿——TCN-BiGRU-Attention混合模型。这名字听着有点唬人,其实就是把时间卷积网络和双向GRU用注意力机制串起来了。试了下手头的传感器数据,效果居然比LSTM单干强不少,特别是对多变量数据里隐藏的特征抓得挺准。
先看模型怎么组装的吧。TCN那部分主要负责捕捉局部时间特征,这货的膨胀卷积结构对长序列特别友好。代码里核心结构长这样:
numFilters = 64;
filterSize = 3;
numBlocks = 4;
layers = [
sequenceInputLayer(inputSize)
convolution1dLayer(filterSize,numFilters,'DilationFactor',1)
reluLayer
convolution1dLayer(filterSize,numFilters,'DilationFactor',2)
reluLayer
convolution1dLayer(filterSize,numFilters,'DilationFactor',4)
reluLayer];这里的DilationFactor每次翻倍,相当于给网络装了个"时间望远镜",能同时关注不同时间尺度的特征。注意输入层直接用了sequenceInputLayer,处理多元数据时比传统全连接省事多了。
接着BiGRU部分负责捕捉前后时序依赖。双向结构有个妙用:正向GRU捕捉"过去影响现在",反向GRU捕捉"未来潜在趋势"。代码实现里有个小技巧:
gruHiddenUnits = 128;
layers = [
gruLayer(gruHiddenUnits,'OutputMode','sequence','Name','gru1')
gruLayer(gruHiddenUnits,'OutputMode','last','Name','gru2','Reverse',true)
concatenationLayer(1,2,'Name','concat')];这里用sequence模式保留时间维度信息,再让反向GRU从尾部开始处理。最后用concat层把正反向特征拼起来,比直接相加保留了更多信息量。
注意力机制才是画龙点睛之笔。传统方法里特征加权都是静态的,注意力层让模型动态调整重点。这个实现挺有意思:
function Z = attentionLayer(X, weights)
query = fullyConnectedLayer(size(X,2),'Name','query');
key = fullyConnectedLayer(size(X,2),'Name','key');
value = fullyConnectedLayer(size(X,2),'Name','value');
Q = query(X);
K = key(X);
V = value(X);
attentionWeights = softmax((Q*K')/sqrt(size(K,2)));
Z = attentionWeights * V;
end其实可以看作自注意力的简化版,用全连接生成QKV三个矩阵。softmax前的缩放因子1/sqrt(d_k)防止点积过大导致梯度消失,这个细节在实践里还挺重要。
TCN-BiGRU-Attention基于时间卷积网络-双向门控循环单元结合注意力机制的多变量回归预测 Matlab语言 程序已调试好,无需更改代码直接替换Excel运行 你先用,你就是创新 多变量单输出,回归预测也可以提前加好友换成分类或时间序列单列预测,回归效果如图1所示~ 模型网络结构如图2所示,非常新颖适合作为创新点先用先发 也可以增加各类优化算法,如冠豪猪CPO、蜣螂DBO等等,需要请提前加好友 (Matlab版本需要在2023及以上,没有的我可以提供安装包) 注: 1.附赠测试数据,数据格式如图4所示~ 2.注释清晰,适合新手小白运行main文件一键出图~ 3.商品仅包含Matlab代码,后可保证原始程序运行 4.模型只是提供一个衡量数据集精度的方法,因此无法保证替换数据就一定得到您满意的结果~
实测时发现几个调参要点:
- TCN层数别超过5层,否则GPU显存飙得比比特币还快
- BiGRU的hidden units设到输入特征数的2倍左右效果最佳
- 注意力头数超过3反而降低精度,单头足够应对大多数场景
数据预处理记得做滑窗处理,代码里自带的滚动预测函数很实用:
function [XTrain, YTrain] = createRollingData(data, windowSize)
numSamples = size(data,1) - windowSize;
XTrain = zeros(numSamples, windowSize, size(data,2));
YTrain = zeros(numSamples, 1);
for i = 1:numSamples
XTrain(i,:,:) = data(i:i+windowSize-1, :);
YTrain(i) = data(i+windowSize, end);
end
end窗口大小的经验值是数据周期的1/4到1/2。比如你的数据每24小时一个周期,窗口设6-12比较合适。
最后说下部署时的坑:Matlab2023a开始支持cuda加速,但要注意把cuDNN升级到8.9以上版本。之前遇到个玄学bug——训练正常但预测时显存泄漏,后来发现是TensorFlow底层库冲突,重装CUDA工具包才解决。
模型虽然打包成一键运行了,但真要换自己的数据得注意两点:1.时间列别带时区信息 2.缺失值用线性插值比直接删效果好。试过某电力数据缺了30%的点,用三次样条插反而让RMSE涨了15%,可能因为过度拟合噪声了。
总的来说这套组合拳在多元时序预测上算是新晋网红,发paper当baseline够用,工业级应用还需要加特征工程和模型蒸馏。最近在尝试融合CPO优化器,等跑出稳定结果再来分享。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)