数据增强赋能AI模型:让模型真正走向落地应用
《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
引言
实验室里表现优异的AI模型,到了真实场景却频频掉链子——遇强光、遮挡就识别失误,在拥挤场景错漏百出,核心原因就是模型鲁棒性不足,无法应对真实世界的复杂视觉变化。
而数据增强是解决这一问题最经济高效的方案:无需额外收集数据,仅对现有训练样本做合理改造,就能让模型学习更全面的特征,大幅提升真实场景适配能力。Ultralytics YOLO26等主流视觉AI模型,更是将数据增强深度融入训练流程,轻松打造高鲁棒性AI系统。
本文精简解析数据增强的核心原理、常用技术和实操方法,教你快速提升AI模型的实战能力。
一、何为AI模型的鲁棒性?
鲁棒性,即模型面对非理想真实场景时,保持稳定准确性能的能力。一个合格的落地模型,绝不能只在干净的实验数据中表现优异,更要从容应对以下4种真实考验:
- 光照变化:强光、弱光、眩光、阴影下仍能稳定检测;
- 部分遮挡:物体被遮挡时,凭局部特征精准识别;
- 拥挤场景:多目标重叠、密集排列时,不错检不漏检;
- 图像劣化:对运动模糊、噪声、低分辨率的图像不敏感。
只有通过以上测试,模型才能从“实验室模型”真正走向落地应用,而数据增强正是打造这类模型的核心手段。
二、数据增强:用现有数据,造海量真实样本
很多开发者误以为提升模型性能只能靠收集更多数据,却忽略了真实数据收集标注成本高、周期长,还可能面临稀缺、隐私等问题。
数据增强的核心逻辑:不改变目标核心特征,对现有训练图像做旋转、调亮度、局部遮挡等合理变换,生成大量带真实场景变化的新样本,提升数据多样性,让模型学习到目标的本质特征(比如猫的轮廓、杯子的形状),而非依赖固定的光照、角度、背景等表面细节,这也是模型鲁棒性提升的关键。
简单来说,就是让同一个目标以不同“姿态”参与训练,让模型明白“不管怎么变,核心特征不变就是同一个目标”。
三、数据增强的核心玩法:动态融入训练流程

高效的数据增强,并非提前生成海量增强样本存储(既占空间又不灵活),而是直接融入模型训练流水线,实现动态随机增强,这也是行业主流做法:
训练时,每次加载原始图像,系统会随机对其应用一种或多种增强操作,模型每次看到的都是该图像的不同变体;甚至可通过随机擦除,模拟物体遮挡的真实场景。
这种方式让模型在有限原始数据上,接触到海量视觉变化,被迫聚焦核心特征,从而在真实场景中遇到从未见过的变化时,依然能准确识别。
四、5大常用数据增强技术
针对视觉AI的落地痛点,行业形成了5类经典增强技术,可单独/组合使用,全方位提升数据多样性,适配真实场景:
-
几何变换:旋转、翻转、缩放、裁剪、平移,模拟不同角度/距离观察目标;

-
光照颜色调整:调亮度、对比度、色调,应对强光、弱光、偏色等光照变化;

-
图像质量劣化:添加模糊、噪声,降低分辨率,适应真实采集的低质量图像;

-
遮挡类增强:随机擦除、掩码,模拟物体被遮挡的常态,提升遮挡容忍度;

-
多图像融合:如马赛克增强,拼接多张图像,模拟拥挤场景,提升密集目标检测能力。
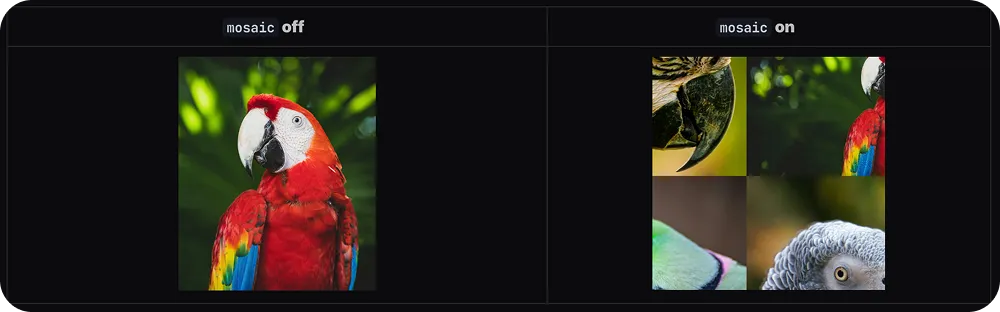
五、实操简化:Ultralytics让数据增强零门槛
手动实现数据增强需要编写大量代码,还需处理标注匹配等问题,而Ultralytics Python包为YOLO系列模型打造了一站式解决方案,让数据增强变得简单:
- 内置优化策略:针对目标检测、分割等任务量身打造经实测的增强方案,直接调用即可;
- 集成Albumentations:无缝对接主流增强库,数百种变换操作一键配置,无需单独开发;
- 动态增强省空间:所有操作训练中实时完成,无需提前存储增强样本,节省海量存储空间。
六、关键细节:标注质量,决定增强效果
数据增强的效果,核心依赖原始数据的标注质量:
训练中,图像的几何变换会自动同步调整边界框、掩码等标注信息,保证增强样本标注准确;但如果原始标注存在错误、偏差,这些问题会在增强中被无限放大,导致模型学习错误特征,反而降低性能。
因此,做数据增强前,一定要用Roboflow等专业工具做好标注校验,保证标注精准,从源头避免错误传递。
七、两大落地场景
数据增强并非纸上谈兵,已深度落地视觉AI核心领域,解决了多个行业痛点:
1. 真实环境目标检测:打通合成数据与真实场景的鸿沟
真实数据稀缺时,开发者常采用合成数据训练,但合成数据“过于干净”,与真实场景差距大。通过对合成数据做光照、遮挡、噪声增强,注入真实多样性,模型即使未见过真实数据,落地表现也能媲美真实数据训练的模型。
2. 医学影像分析:解决数据稀缺与场景多样问题
医学影像受隐私、病例限制,数据量少,且不同设备、患者的影像差异大。对现有影像做噪声、平移、扭曲等增强,生成大量变体样本,让模型学习解剖结构的本质特征,忽略表面影像差异,大幅提升模型在不同医院、设备间的复用性和临床可靠性。
八、总结
- 鲁棒性是AI模型落地的关键,决定了模型在光照、遮挡、拥挤等真实场景的表现;
- 数据增强的核心是提升数据多样性,让模型学习目标本质特征,而非表面细节;
- 动态融入训练流水线是数据增强的高效方式,既省空间又能提升训练效果;
- 5大经典增强技术覆盖真实场景所有视觉变化,是视觉AI的必备手段;
- Ultralytics Python包让数据增强零门槛,内置策略+主流库集成,一键调用;
- 标注质量是前提,原始标注错误会在增强中放大,必须做好前置校验;
- 数据增强解决了合成数据落地、医学数据稀缺等行业痛点,是提升模型实战能力的核心操作。
在AI模型开发中,数据增强早已不是“可选操作”,而是必备步骤。它以极低成本,让模型摆脱实验室“温室环境”,在复杂多变的真实世界中稳定工作,成为打造高鲁棒性视觉AI系统的核心秘诀。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)