计算机毕业设计:基于Python的智慧交通大数据分析预测系统 Flask Vue 可视化 ARIMA LSTM 大数据(建议收藏)✅
·
1、项目介绍
技术栈
Python 语言、Flask 框架、Vue 前端框架、MySQL 数据库、Echarts 可视化库、requests 爬虫技术、ARIMA 时间序列模型、LSTM 深度学习模型
功能模块
- 首页仪表盘模块
- 交通数据分析模块
- 地铁数据分析模块
- 地铁数据预测模块
- 交通数据预测模块
- 模型对比分析模块
- 用户认证模块
项目介绍
本项目是基于 Python 与 Flask 开发的交通大数据分析与预测系统,聚焦中国主要城市交通健康与地铁客流数据。系统通过 requests 爬虫技术定向抓取 MetroDB 网站数据,经清洗后存入 MySQL 数据库。首页仪表盘集成城市总数、总客流量等核心指标,结合柱状图、饼图、折线图实现全局数据总览。交通与地铁数据分析模块支持按时间范围与指标维度进行精细化筛选查询。预测模块融合 ARIMA 与 LSTM 算法,针对地铁客流量与城市拥堵指数生成未来一周趋势预测并以折线图呈现。模型对比分析模块展示不同预测模型的实际值与预测值对比效果。前端采用 Vue 与 Echarts 构建响应式交互界面,实现数据可视化与图表联动,为交通管理与公众出行提供数据支撑。
2、项目界面
一、首页仪表盘,交通数据
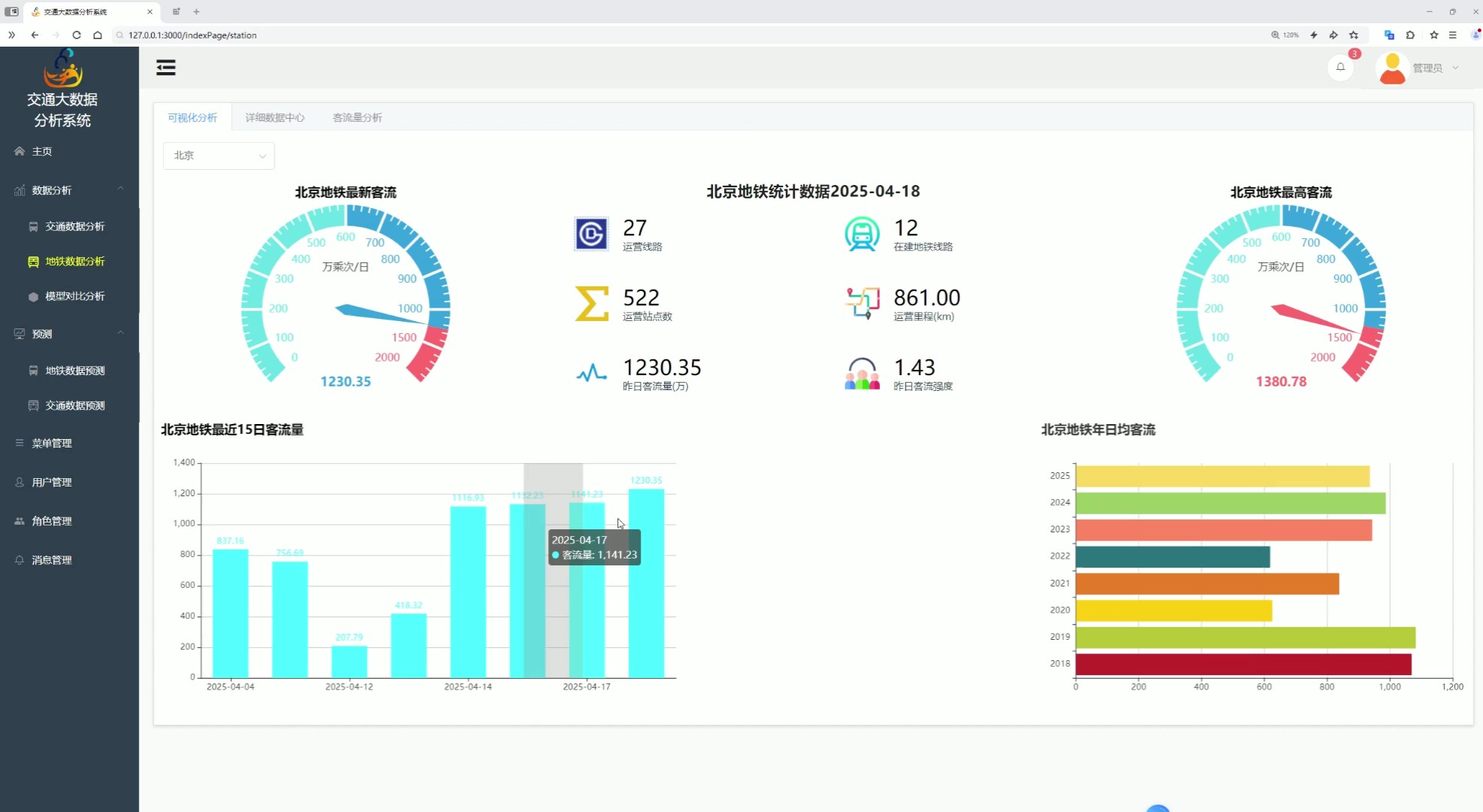
该页面是交通大数据分析系统的客流量分析功能页,顶部设有可视化分析、详细数据中心等功能入口,侧边有系统管理相关功能选项,页面可展示地铁线路、站点、里程等基础运营数据,还能呈现客流量相关统计数据、客流强度及多维度客流趋势图表,同时实现地铁客流量的预测分析,整体用于交通地铁客流相关的大数据统计、可视化分析与趋势预测。
二、首页仪表盘
该页面是交通大数据分析系统的主页仪表盘,设有交通数据分析、地铁数据分析、模型对比分析、预测等功能入口,还有菜单、用户、角色、消息等系统管理功能,可展示多城市地铁基础运营数据、城市健康状态占比、不同时间客流量及城市客流排名趋势,也能实现地铁和交通数据的预测分析,整体用于交通大数据的整体概览与多维度分析。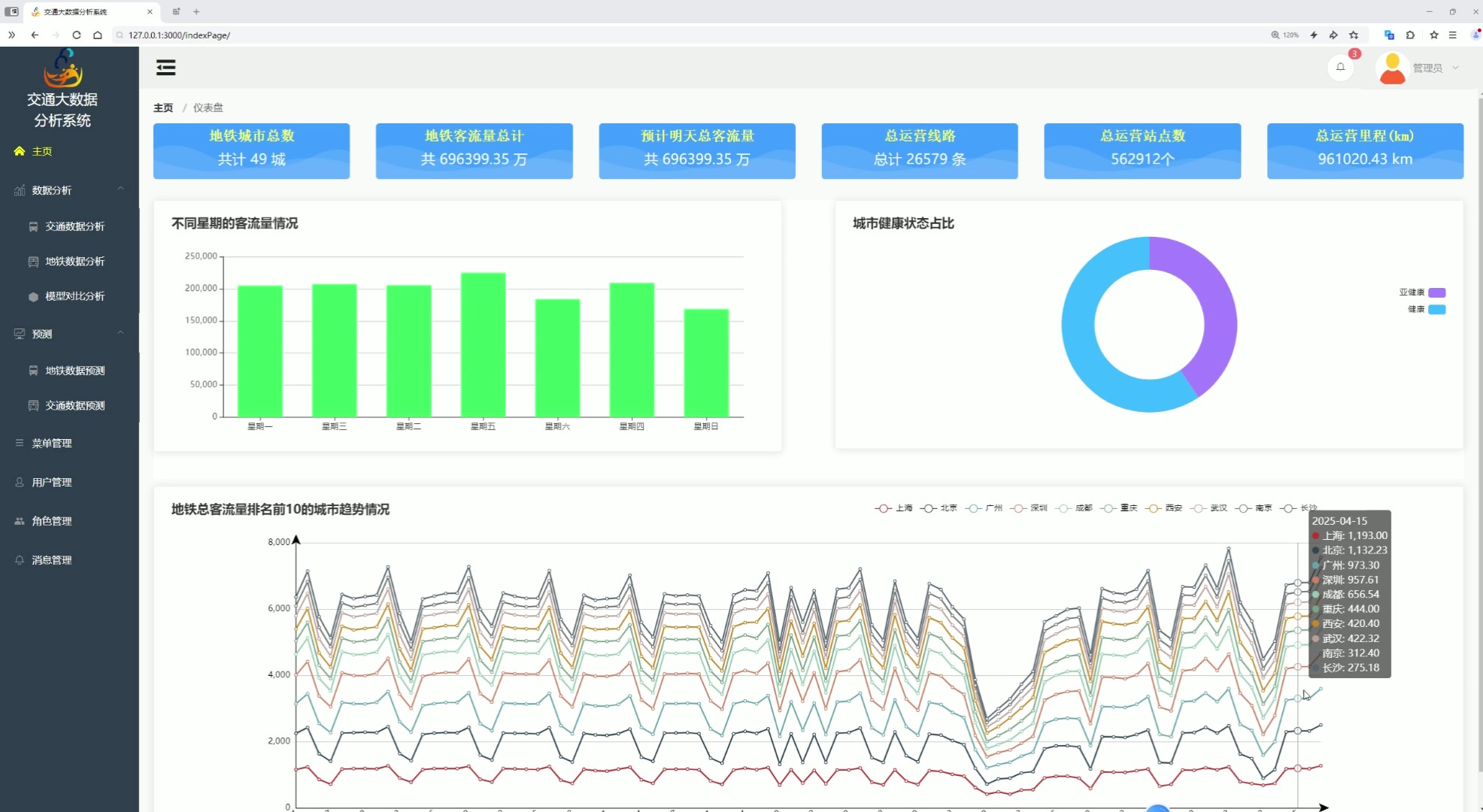
三、中国主要城市交通健康榜
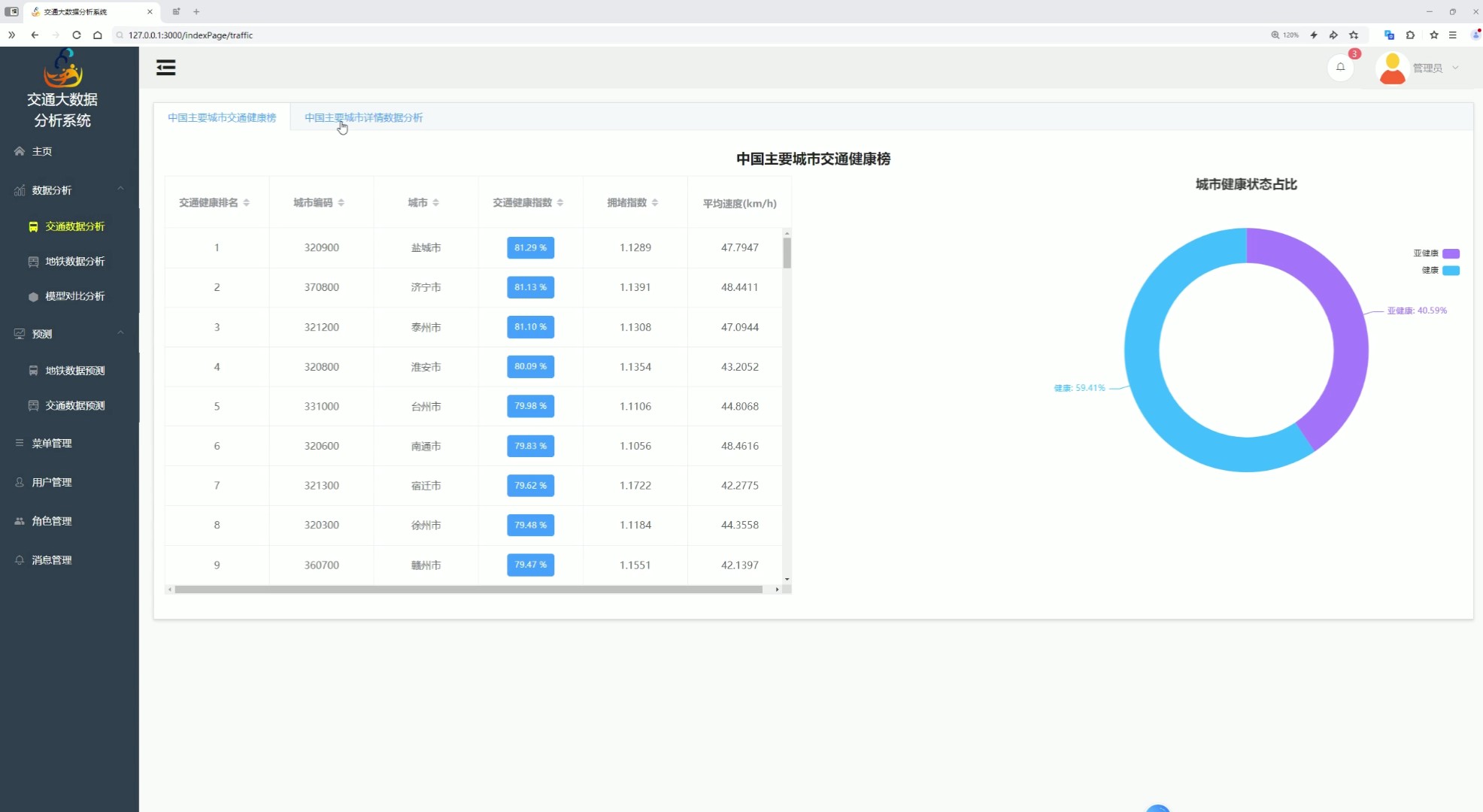
该页面是交通大数据分析系统的交通数据分析功能页,设有地铁数据分析、模型对比分析、预测等功能入口和菜单、用户等系统管理功能,可展示中国主要城市交通健康榜的多维度数据排名表格,呈现城市健康状态占比情况,也能开展城市详情数据分析,整体用于城市交通健康相关的数据分析与排名展示。
四、交通数据分析
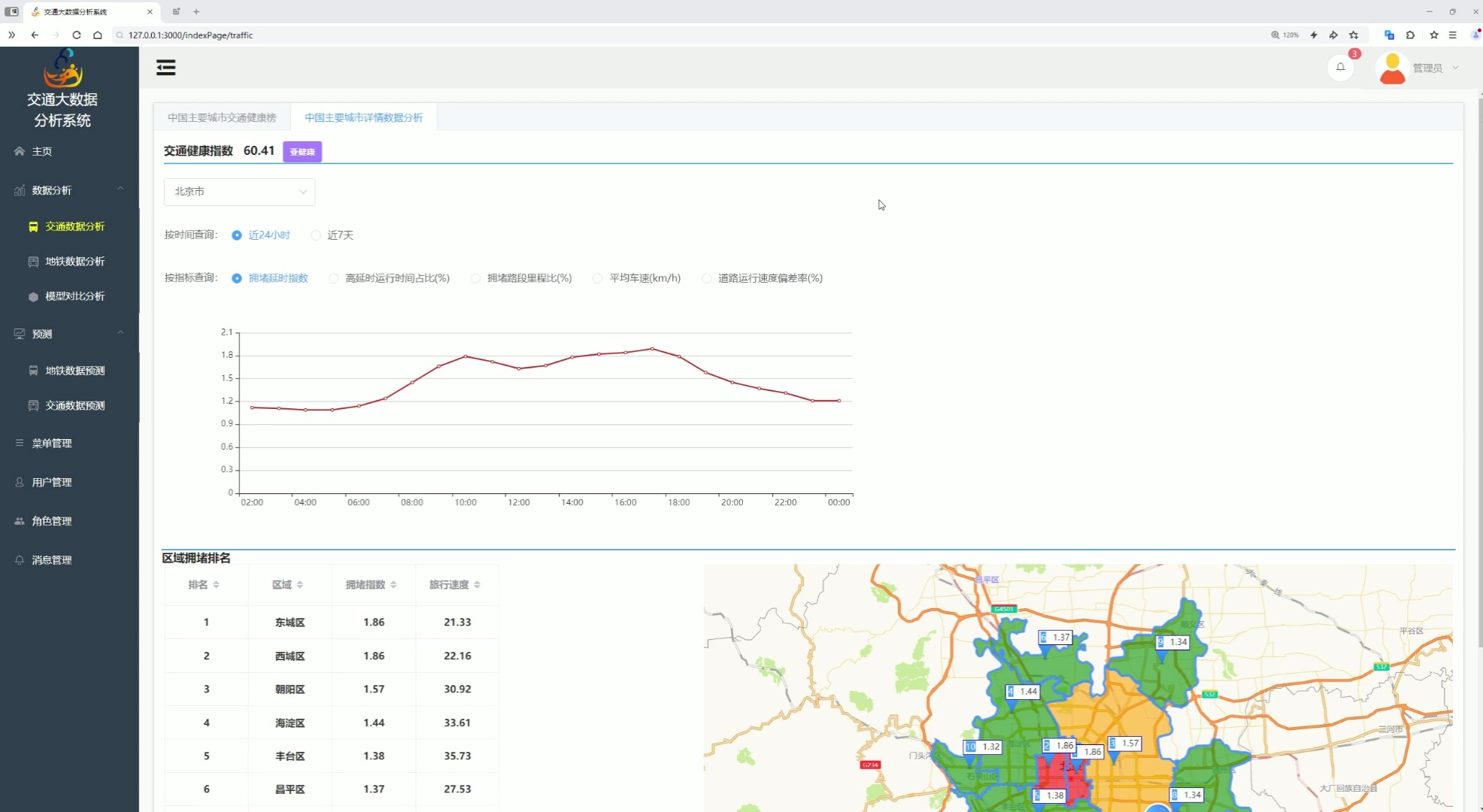
该页面是交通大数据分析系统的中国主要城市详情数据分析功能页,设有地铁数据分析、模型对比分析、预测等功能入口和各类系统管理功能,支持按时间和指标对指定城市交通数据进行查询,展示城市交通健康指数及相关交通指标的时段变化趋势,还呈现城市区域拥堵排名数据,整体用于单一城市交通数据的精细化查询与多维度分析展示。
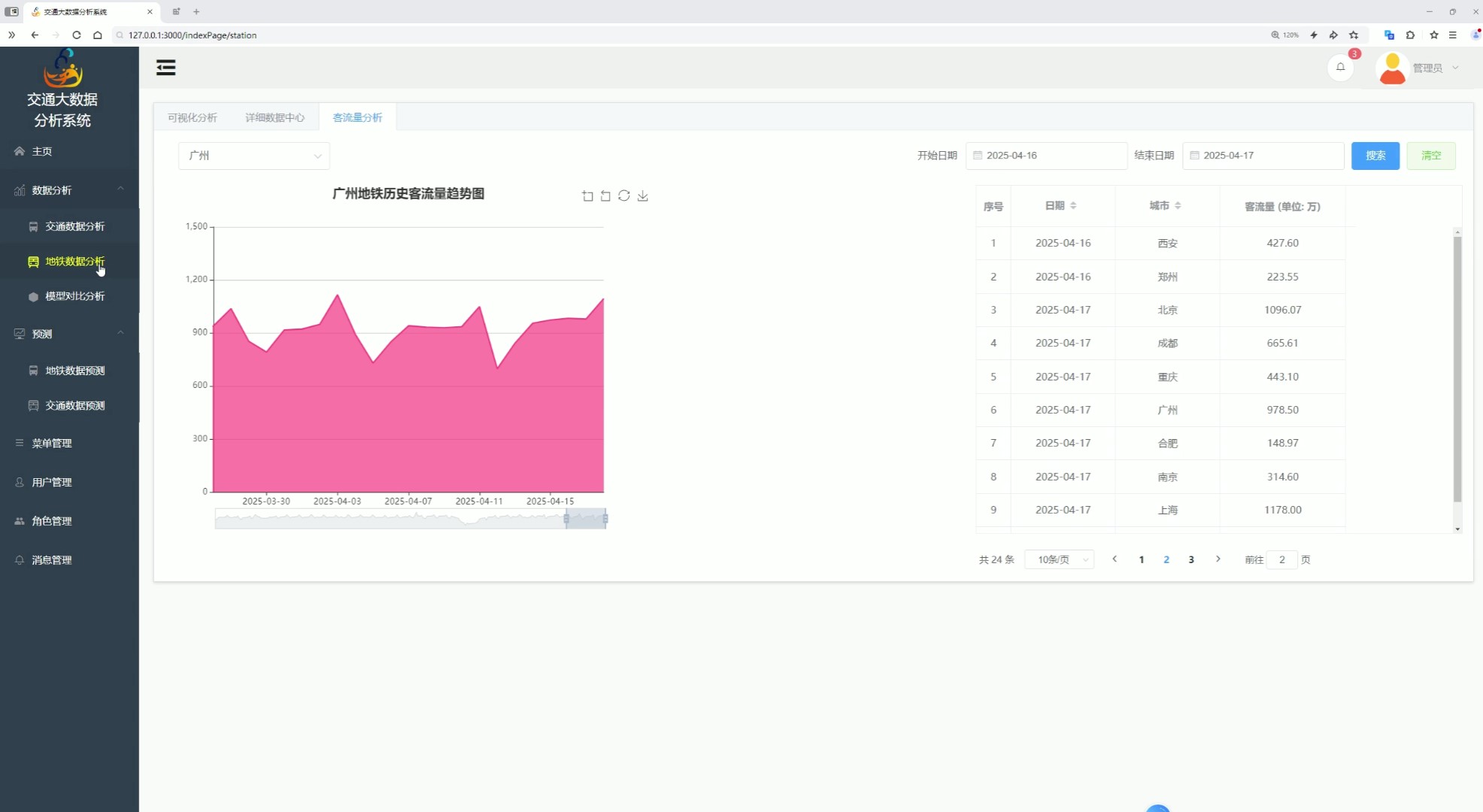
五、地铁数据分析
该页面是交通大数据分析系统的地铁数据分析下的客流量分析功能页,设有可视化分析、详细数据中心入口和交通数据分析等功能及各类系统管理功能,支持按日期筛选查询地铁客流数据,展示指定城市地铁历史客流量趋势图,还以分页表格形式呈现多城市地铁客流量数据,整体用于地铁客流量的筛选查询、趋势可视化及多城市数据统计展示。
六、模型对比
该页面是交通大数据分析系统的模型对比分析功能页,设有交通数据分析、地铁数据分析、预测等功能入口和各类系统管理功能,可展示不同预测模型的多项评估指标数据,呈现指定城市下各模型的实际值与预测值对比情况,整体用于交通数据预测相关模型的性能指标对比和实际预测效果的可视化分析。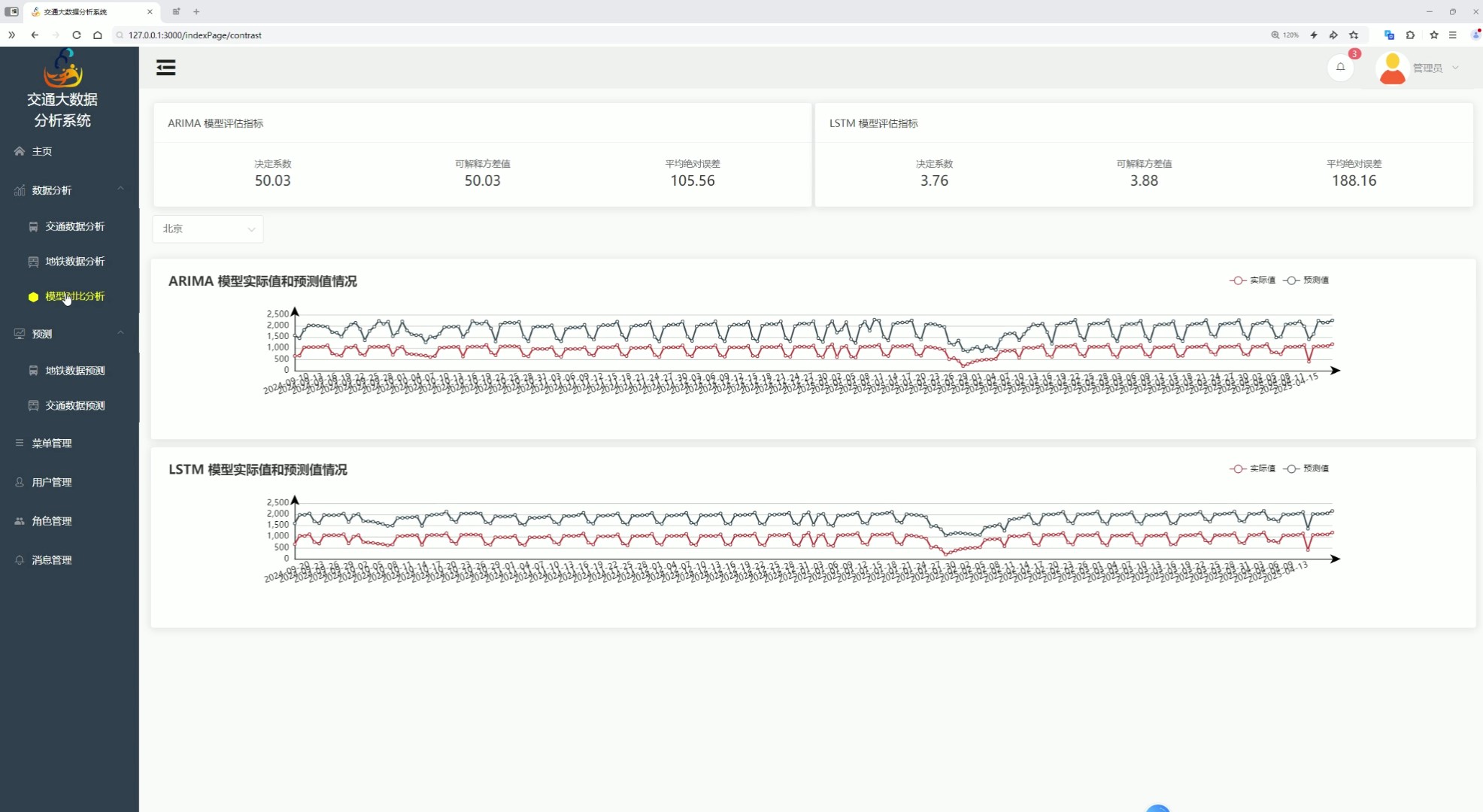
七、地铁数据预测
该页面是交通大数据分析系统的地铁数据预测功能页,设有交通数据分析、地铁数据分析、模型对比分析等功能入口和各类系统管理功能,支持选定城市并刷新查看数据,可展示指定城市未来一周地铁客流量的预测数据并以趋势图呈现客流预测变化,整体用于地铁客流量的专项预测及预测数据的可视化展示分析。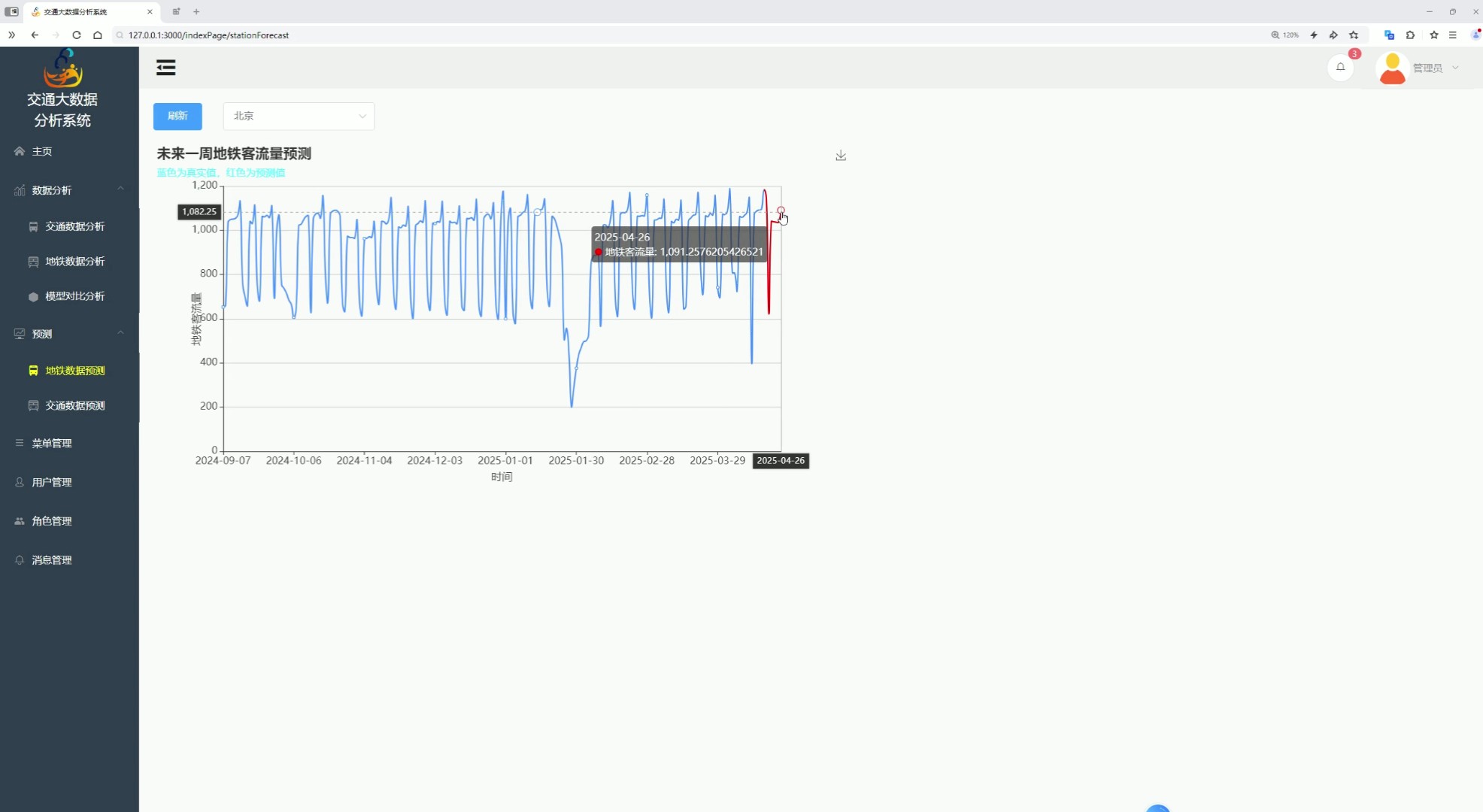
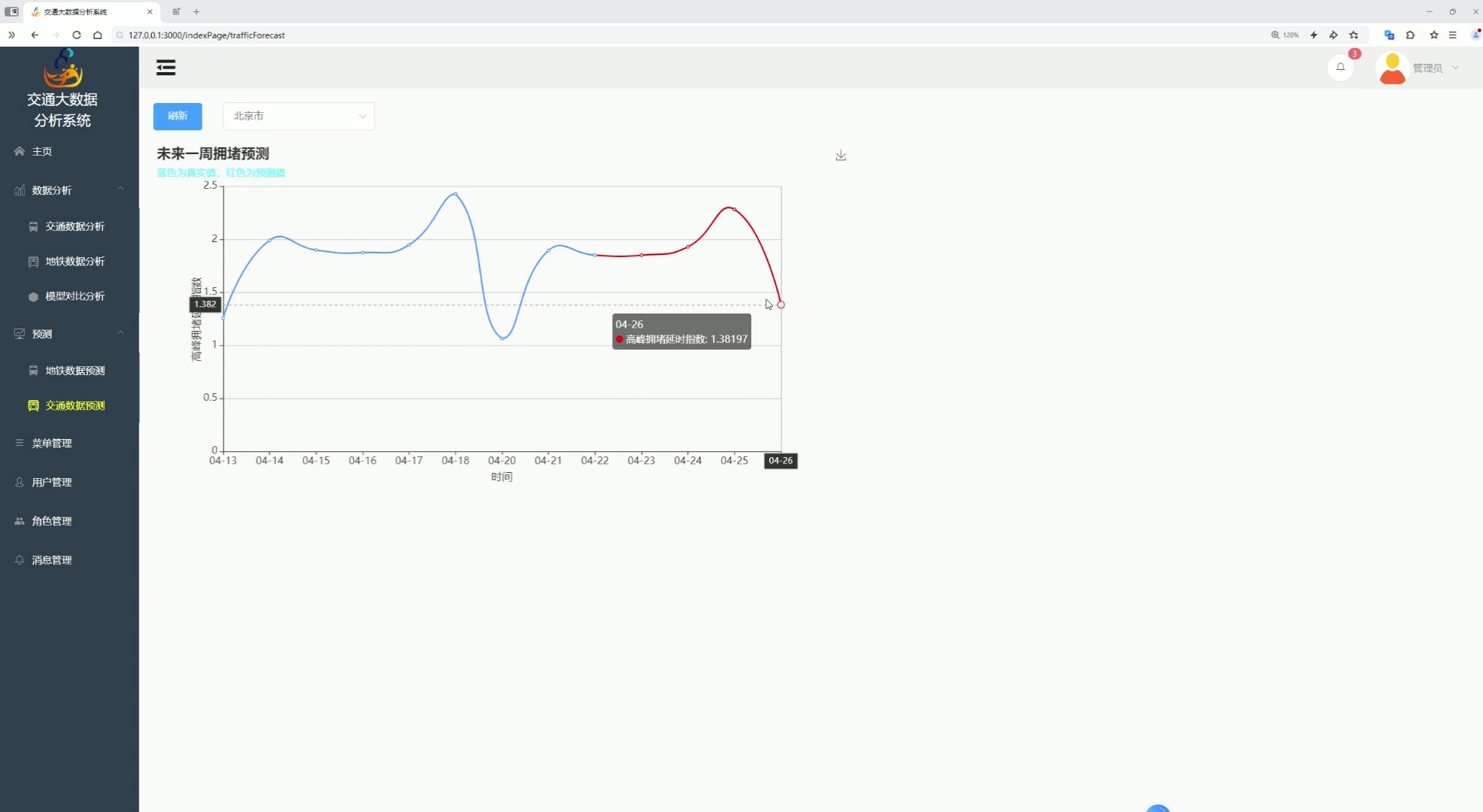
八、交通数据预测
该页面是交通大数据分析系统的交通数据预测功能页,设有交通数据分析、地铁数据分析、模型对比分析等功能入口和各类系统管理功能,支持选定城市并刷新数据,可展示指定城市未来一周的拥堵预测趋势图,呈现高峰拥堵延时指数等关键拥堵指标数据,整体用于城市交通拥堵的专项预测及预测数据的可视化展示分析。
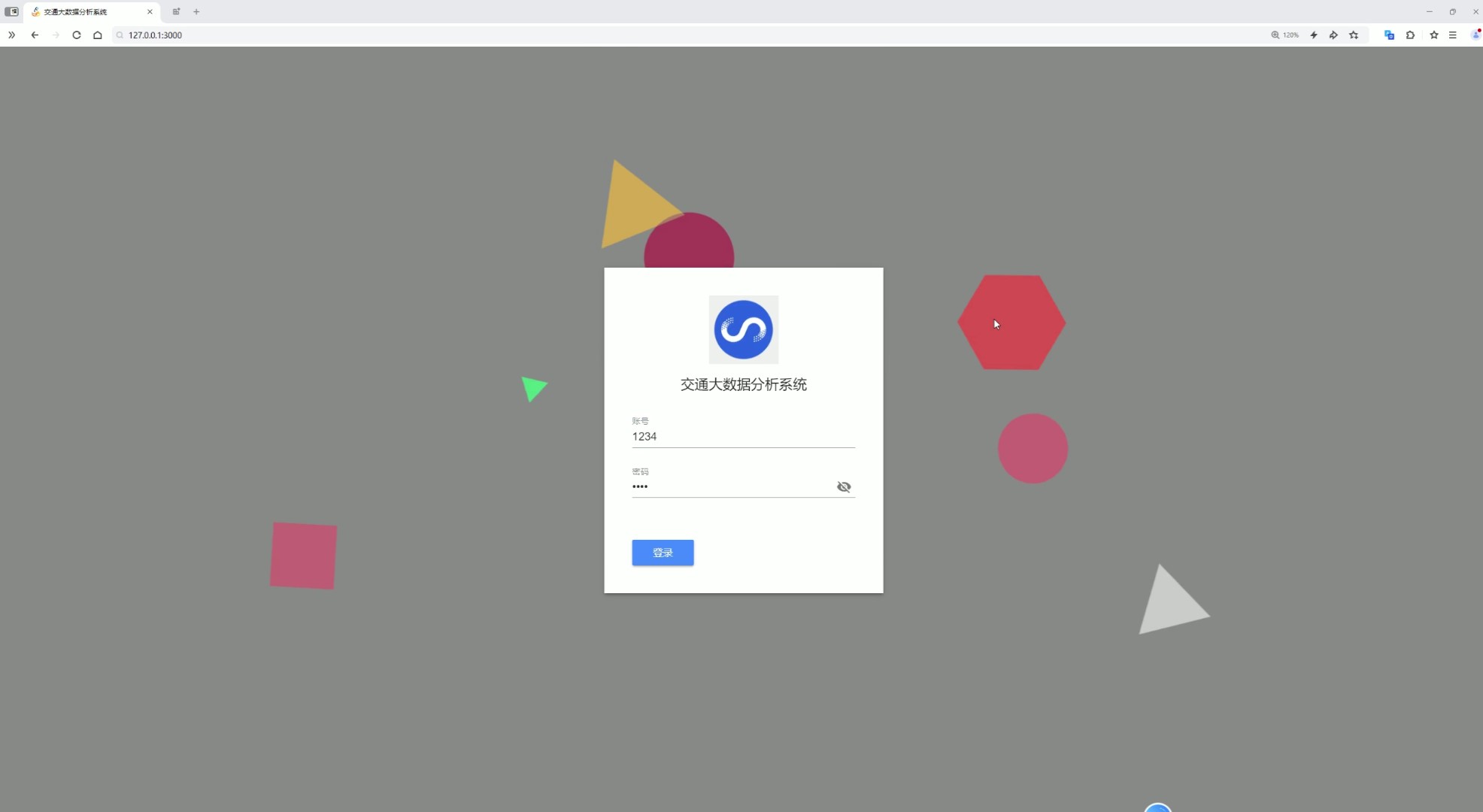
九、登录页面
该页面是交通大数据分析系统的登录页,作为系统的访问入口,核心实现用户身份验证的功能,提供账号和密码的输入区域以及登录操作按钮,用户完成信息填写并执行登录操作后,可通过验证进入系统内部,访问各类交通大数据的分析、统计、预测等功能模块,整体承担系统的访问权限管控功能。
3、项目说明
一、技术栈简要说明
系统后端采用 Python 语言与 Flask 框架构建,前端使用 Vue 框架实现响应式交互,数据库选用 MySQL 进行数据存储。数据采集环节基于 requests 爬虫技术定向抓取 MetroDB 网站的中国主要城市交通健康与地铁运营数据。可视化部分通过 Echarts 图表库实现柱状图、饼图、折线图等多类型图表渲染。预测模块融合 ARIMA 时间序列模型与 LSTM 深度学习模型,对客流量与拥堵指数进行短期趋势预测。
二、功能模块详细介绍
· 首页仪表盘模块
作为系统主入口,集成地铁城市总数、总客流量、线路数、站点数、运营里程等核心运营数据,通过不同星期客流量柱状图、城市健康与亚健康状态饼图、前10城市客流趋势折线图等形式,实现全局数据可视化总览,提供多维度功能入口导航。
· 交通数据分析模块
包含中国主要城市交通健康榜与城市详情分析两个子模块。健康榜以表格形式展示城市排名、拥堵指数等关键指标,并呈现城市健康状态占比。城市详情分析支持按近24小时或近7天时间范围及多类交通指标进行筛选查询,展示城市交通健康指数时段变化趋势与区域拥堵排名,实现精细化数据挖掘。
· 地铁数据分析模块
支持按日期筛选查询地铁客流数据,展示指定城市地铁历史客流量趋势图,同时以分页表格形式呈现多城市地铁客流量数据,满足地铁客流数据的筛选查询、趋势可视化与多城市统计展示需求。
· 地铁数据预测模块
支持用户选择目标城市,基于 ARIMA 与 LSTM 算法对未来一周地铁客流量进行预测,以折线图形式直观呈现客流预测变化趋势,为运力调配提供前瞻性参考。
· 交通数据预测模块
针对城市拥堵指数,支持用户选择城市并刷新数据,通过 ARIMA 与 LSTM 算法输出未来一周拥堵预测趋势图,展示高峰拥堵延时指数等关键指标的变化规律,辅助拥堵疏导决策。
· 模型对比分析模块
展示不同预测模型的多项评估指标数据,以图表形式呈现指定城市下各模型的实际值与预测值对比情况,便于用户直观对比 ARIMA 与 LSTM 等模型的预测性能与效果差异。
· 用户认证模块
提供系统登录页面,实现用户身份验证功能,包含账号与密码输入区域及登录操作按钮,通过验证后用户可进入系统访问各类交通数据分析、统计、预测功能模块,承担系统访问权限管控职能。
三、项目总结
本系统是基于 Python 与 Flask 开发的智慧交通大数据分析与预测平台,聚焦中国主要城市交通健康与地铁客流数据,构建了从数据采集到分析预测的全流程解决方案。系统通过 requests 爬虫实现 MetroDB 网站数据的定时抓取与清洗存储,依托 Echarts 实现柱状图、饼图、折线图等多类型图表渲染。五大核心模块协同发力:首页仪表盘提供全局数据总览,交通与地铁数据分析模块支撑精细化数据挖掘,预测模块融合 ARIMA 与 LSTM 算法实现未来一周客流量与拥堵指数趋势预判,模型对比模块展示不同算法预测效果。前端采用 Vue 与 Echarts 构建响应式交互界面,支持图表缩放、悬浮提示与数据联动,有效降低数据解读门槛,为交通管理决策与公众出行规划提供科学支撑。
4、核心代码
# -*- coding: UTF-8 -*-
"""
@summary:
@DATE: 11/15 17:53
"""
import asyncio
import csv
import aiohttp
import re
import json
# from tool.logger import logger
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm
from typing import List, Any, Union
class DataFetcher:
def __init__(self, base_url: str, headers: dict, cookies: dict):
self.base_url = base_url
self.headers = headers
self.cookies = cookies
async def get_response(self, session, url):
"""异步获取响应"""
max_retries = 5 # 最大重试次数
retries = 0
while retries < max_retries:
try:
async with session.get(url, headers=self.headers, cookies=self.cookies) as response:
return await response.text()
except aiohttp.ClientConnectorError as e:
retries += 1
print(f"连接错误,正在重试 {retries}/{max_retries}...")
await asyncio.sleep(2) # 等待2秒后重试
except Exception as e:
print(f"发生错误: {e}")
break
return None
def is_null_number_string(self, string: str) -> Union[int, str]:
"""判断字符串是否为空数字字符串"""
return 0 if string.strip() == "" else string
def process_city_data(self, city, response_text, year_list):
"""处理每个城市的数据"""
new_data = re.findall(r'data: \[(.*?)\]', response_text)
years = new_data[1].split(', ')[:-1]
flows = new_data[2].split(', ')[:-1]
flow_list = [0] * len(year_list)
for i, year in enumerate(years):
year = int(year)
if year in year_list:
index = year_list.index(year)
flow_list[index] = flows[i]
new_data = re.findall(r'rollNum\(".*", 0, (.*?)\);', response_text)
data = {
'city': city[1],
'time': new_data[0],
'operating_line': new_data[1],
'under_construction_line': new_data[2],
'operating_mileage': self.is_null_number_string(new_data[3].replace(', 2', '')),
'max_passenger_flow': self.is_null_number_string(new_data[4].replace(', 2', '')),
'yesterday_passenger_flow': self.is_null_number_string(new_data[6].replace(', 2', '')),
'yesterday_passenger_intensity': self.is_null_number_string(new_data[7].replace(', 2', '')),
'operating_station_count': self.is_null_number_string(new_data[8]),
'year_flow': json.dumps(dict(zip(year_list, flow_list)), ensure_ascii=False),
}
return data
async def fetch_city_data(self, session, city, year_list):
"""异步获取每个城市的数据"""
url = f"{self.base_url}/index/{city[0]}"
while True:
try:
response_text = await self.get_response(session, url)
return self.process_city_data(city, response_text, year_list)
except aiohttp.ClientError:
continue
async def get_data(self, city_url: str, year_list: List[int], max_workers=10):
"""获取并处理数据"""
async with aiohttp.ClientSession() as session:
# 获取城市列表
response_text = await self.get_response(session, city_url)
city_list = re.findall('<a href="(.*?)">(.*?)</a>', response_text)[1:-1]
total_cities = len(city_list)
results = []
errors = []
# 使用线程池来加速写入等操作
with ThreadPoolExecutor(max_workers=max_workers) as executor:
with tqdm(total=total_cities, desc="处理城市数据") as pbar:
loop = asyncio.get_event_loop()
tasks = []
# 创建任务
for city in city_list:
tasks.append(self.fetch_city_data(session, city, year_list))
# 处理完成的任务
for future in asyncio.as_completed(tasks):
try:
city_data = await future
results.append(city_data)
pbar.update(1)
except Exception as e:
pbar.update(1)
errors.append(str(e))
return results, errors
def generate_date_lists(self, start_date, end_date):
"""根据日期生成年份列表"""
start = datetime.strptime(start_date, '%Y-%m-%d')
end = datetime.strptime(end_date, '%Y-%m-%d')
return [year for year in range(start.year, end.year + 1)]
async def get_metro_db_data():
# 初始化DataFetcher实例
city_url = "https://www.metrodb.org/index/guangzhou.html"
# 创建DataFetcher实例
fetcher = DataFetcher(base_url="https://www.metrodb.org", headers=headers, cookies=cookies)
# 获取年份列表
year_list = fetcher.generate_date_lists('2018-01-01', datetime.now().strftime('%Y-%m-%d'))
# 获取数据并返回
result, errors = await fetcher.get_data(city_url, year_list, max_workers=10)
if errors:
print(f"处理过程中发生错误:{errors}")
return result
def get_response(url, headers, method: str = "GET", cookies: dict = None):
response = None
if method == "GET":
try:
response = requests.get(url, headers=headers, cookies=cookies, timeout=10)
except:
max_retries = 5 # 最大重试次数
retries = 1
while retries < max_retries:
print(f"连接错误,正在重试 {retries}/{max_retries}...")
try:
response = requests.get(url, headers=headers, cookies=cookies, timeout=10)
return response
except:
retries += 1
else:
response = requests.post(url, headers=headers, cookies=cookies, timeout=10)
return response
def to_date(date_str):
return datetime.strptime(date_str, "%Y-%m-%dT%H:%M:%S")
def to_timestamp(timestamp):
# 将时间戳转换为datetime对象
dt_object = datetime.fromtimestamp(timestamp)
# 将datetime对象格式化为字符串
return dt_object.strftime("%Y-%m-%d %H:%M:%S")
def get_metro_watch_data():
def get_real_time_traffic_detail_data(code, data_type: str):
"""
@summary: 获取实时交通详情数据
"""
url = "https://report.amap.com/ajax/cityHourly.do"
params = {
"cityCode": code,
"dataType": data_type
}
response = requests.get(url, headers=headers, params=params, cookies=cookies)
json_data = response.json()
data_list = []
print(type(data_type))
if data_type != '5':
for item in json_data:
data_list.append([to_timestamp(item[0] / 1000), item[1]])
return data_list
else:
return json_data
def get_real_time_traffic_detail_data2(code, data_type: str):
"""
@summary: 获取实时交通详情数据
"""
url = "https://report.amap.com/ajax/cityDaily.do"
params = {
"cityCode": code,
"dataType": data_type
}
response = requests.get(url, headers=headers, params=params, cookies=cookies)
json_data = response.json()
data_list = []
if data_type != '5':
for item in json_data:
data_list.append([to_timestamp(item[0] / 1000), item[1]])
return data_list
else:
return json_data
async def get_traffic_data():
url =
response = get_response(url, headers, cookies=cookies)
json_data = response.json()
city_traffic = []
for item in tqdm(json_data):
code = item['adcode']
rank = item['rankchange1']
time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
cityName = item['cityName']
healthValue = item['healthValue']
idx = item['idx']
realSpeed = item['realSpeed']
city_traffic.append({
'rank': rank,
'city': cityName,
'city_code': code,
'timestamp': time,
'traffic_health_index': healthValue,
'congestion_delay_index': idx,
'average_speed': realSpeed
})
return city_traffic
if __name__ == "__main__":
print(to_timestamp(1733533200))
get_metro_watch_data()
ls = get_real_time_traffic_detail_data('321200', '1') # 获取实时交通详情数据
print(ls)
pass

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 27
27 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)