Research Summary of a Cosmetics Consumer Sentiment Analysis Model Based on Deep Text Mining
This study was presented at the 4th International Symposium on Computer Applications and Information Technology (ISCAIT) in 2025. Taking cosmetic reviews on the JD.com platform as the research object, it proposed a consumer sentiment analysis method based on deep text mining to address the imbalance between positive and negative sentiment categories in the reviews. First, the study conducted text preprocessing with Jieba segmentation and TF-IDF feature extraction combined with the N-gram model, and adopted class-weight adjustment to solve the problem of category imbalance. It compared the effects of four stopword strategies (generic stopwords, Chinese sentiment-specific stopwords, customized stopwords and no stopwords). In addition, the study tested the Class 0 (negative sentiment) F1-scores of traditional machine learning models (Logistic Regression) and deep learning models (LSTM and CNN), and performed hyperparameter tuning on the core models through Bayesian optimization. The experimental results showed that the no-stopword strategy was more suitable for deep learning models; after Bayesian optimization, the LSTM model achieved the optimal performance with a Class 0 F1-score of 0.8598, the CNN model reached 0.8521, and the Logistic Regression model only increased slightly to 0.8139. The study ultimately verified that the combination of TF-IDF text representation, deep learning and Bayesian optimization can significantly improve the effect of negative sentiment prediction, providing a reference for large-scale cross-domain sentiment analysis.
(一)Research Background and Core Objectives
With the development of the internet and e-commerce, online consumer reviews have become an important channel for enterprises to obtain market dynamics. In the cosmetics industry, consumer sentiment directly impacts brand reputation and sales, yet existing cosmetics reviews suffer from a severe imbalance between positive and negative sentiment categories.
Core Research Objectives:
- Address the class imbalance between positive and negative samples in cosmetics reviews, and improve the F1-score for Class 0 (negative sentiment).
- Investigate the impact of different stopword strategies on model performance.
- Compare the sentiment analysis performance of traditional machine learning and deep learning models, and further optimize the models by combining Bayesian optimization.
Core Research Contributions:
- Systematically analyzed the impact of stopword strategies on sentiment analysis models.
- Applied traditional machine learning and deep learning combined with Bayesian optimization to negative sentiment prediction in cosmetics reviews, providing a methodological reference for sentiment analysis on imbalanced datasets.
(二)Data Source and Processing
Data Source: User reviews of four cosmetics brands (Juduo, Marie Dalgar, Perfect Diary, and Mao Geping) from the JD.com platform were selected. The initial dataset contains 51,245 entries, which are binary-labeled data, including 47,564 positive reviews (Class 1) and 3,681 negative reviews (Class 0), exhibiting a significant class imbalance problem.
Data Correction: It was found that some model misclassifications were caused by incorrect user labeling. False positive and false negative samples in both the training and test sets were corrected through manual review. The updated dataset consists of 47,494 positive reviews and 3,751 negative reviews, slightly increasing the proportion of negative reviews and providing a more reliable foundation for model training.
(三)Text Preprocessing
1.Text preprocessing is a critical step in this study, encompassing three core components: tokenization, stopword strategy comparison, and feature extraction. All processing is performed on the updated dataset:
2.Tokenization: The Jieba segmentation tool is used to accurately segment Chinese cosmetics reviews, laying the foundation for subsequent feature extraction.
3.Stopword Strategy Experiments: Four stopword strategies were designed and compared based on the Class 0 F1-score. The key finding was that the generic stopword strategy performed the worst (with a Class 0 F1-score of only 0.64), while the customized stopword list (constructed based on word frequency statistics and N-gram analysis, with the top 10 new words including "effect", "price", "lipstick", etc.) performed similarly to the no-stopword strategy in the Random Forest model. The core design logic of the customized stopword list is to remove nouns that frequently appear in both positive and negative reviews and have no sentiment polarity, while retaining key sentiment words such as verbs and adjectives, and avoiding incorrect splitting of negative sentiment phrases.
4.Feature Extraction: TF-IDF combined with N-gram models is used for feature extraction. The vectorized text is input into traditional machine learning models to calculate feature importance. Meanwhile, the frequency of each word in positive and negative reviews is counted, and the impact of words on sentiment prediction is evaluated by combining TF-IDF values. Words with strong sentiment tendencies show significant differences in frequency between positive and negative reviews, contributing more to the prediction.
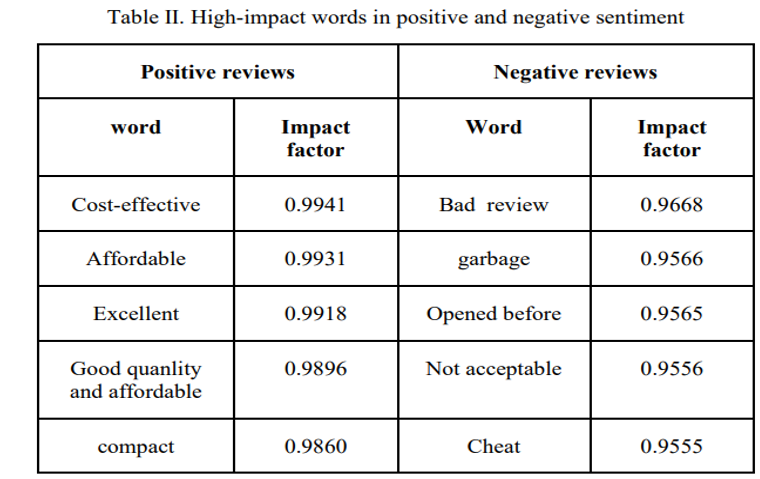
5.Core data on feature importance: The impact coefficients of high-impact words in positive and negative reviews were derived from the Random Forest model, and the core data are shown in the table below:
(四) Model Selection and Initial Experimental Results
- Two types of models, traditional machine learning and deep learning, were selected in the study. Experiments were conducted under two strategies (customized stopwords and no stopwords), with the Class 0 F1-score as the core evaluation index. The key conclusion is that models show significant differences in their dependence on stopword strategies:
- Traditional Machine Learning: Seven models including LR, Random Forest, SVM, GBDT, Naive Bayes, LightGBM and CatBoost were selected for experiments based on the TF-IDF+N-gram feature engineering. SVM, LR and GBDT are more suitable for the no-stopword strategy, while the performance of Random Forest, LightGBM, CatBoost and Naive Bayes slightly improved or remained the same under the customized stopword strategy.
- Deep Learning: LSTM and CNN models were selected, which outperform traditional machine learning in capturing sequential text features of texts. The models achieved better performance under the no-stopword strategy, with initial Class 0 F1-scores of 0.8331 for LSTM and 0.8271 for CNN respectively, and the results slightly decreased under the customized stopword strategy. The reason is that without stopword removal, the deep learning network can automatically learn key sentiment words without relying on external filtering.
- Comparison of Initial Models: The initial Class 0 F1-scores of deep learning models are significantly higher than those of traditional machine learning models (e.g., the initial score of LR is only 0.8135), demonstrating a stronger ability to predict negative sentiment.
(五) Bayesian Optimization and Model Performance Improvement
To maximize the Class 0 F1-score, the study conducted Bayesian hyperparameter optimization on three core models (LR, LSTM and CNN), and determined the optimal hyperparameters for each model (e.g., LSTM with a batch size of 24 and a learning rate of 3.13×10⁻³; CNN with 196 filters and a kernel size of 5, etc.). The Class 0 F1-score data of the core models after optimization are shown in the table below:
|
Model |
Class 0 F1-score before Optimization |
Class 0 F1-score after Optimization |
Improvement Margin |
|
LSTM |
0.8331 |
0.8598 |
0.0267 |
|
CNN |
0.8271 |
0.8521 |
0.0250 |
|
Logistic Regression |
0.8135 |
0.8139 |
0.0004 |
Core Conclusion: Bayesian optimization can effectively improve the generalization ability of models, and its optimization effect on deep learning models is far superior to that on traditional machine learning models. After optimization, the LSTM model became the optimal model in this study.
(六) Research Conclusions and Future Outlook
Core Conclusions
- Stopword strategies have a significant impact on model performance. The no-stopword strategy or customized stopword strategy is more suitable for sentiment analysis of cosmetics reviews, and the choice of strategy should be tailored to the characteristics of the model.
- Deep learning models (LSTM, CNN) are significantly superior to traditional machine learning models in capturing the emotional features of cosmetics review texts.
- The method combining TF-IDF text representation with deep learning and Bayesian optimization can effectively solve the problem of class imbalance in reviews and significantly improve the F1-score of negative sentiment prediction.
- Words with high emotional polarity (such as "cost-effective", "bad review") contribute the most to sentiment prediction of cosmetics reviews, while high-frequency nouns without emotional polarity are suitable to be removed as stopwords.
Future Research Directions
- Explore the application of pre-trained language models in cosmetics review sentiment analysis.
- Further optimize the stopword construction strategy based on more diverse datasets.
- Verify the effectiveness of the method in this study on larger-scale, cross-domain review datasets.
Question
Question 1:
What is the core pain point of this study on sentiment analysis of cosmetics reviews, and what methods are adopted to address this pain point?
Answer: The core pain point is that cosmetics reviews on JD.com suffer from a severe class imbalance between positive and negative sentiments, with the number of negative review samples far lower than that of positive ones, leading to poor model performance in predicting negative sentiment (Class 0). The solutions include:
-
Conducting manual review and correction of the original labeled data to improve label accuracy and slightly increase the proportion of negative reviews.
-
Adopting a class-weight adjustment strategy to specifically address the class imbalance problem.
-
Performing feature extraction using TF-IDF combined with N-gram to retain words with high emotional polarity and enhance the discriminative power of features for negative sentiment.
-
Applying Bayesian optimization to tune the hyperparameters of deep learning models, with a focus on improving the Class 0 F1-score for negative sentiment prediction.
-
Comparing and selecting suitable stopword strategies to reduce the interference of meaningless features on the model.
Question 2:
What are the reasons for the significant differences in the experimental effects of different stopword strategies in this study? What is the construction logic of the customized stopword list?
(1) Core reasons for the differences in effects:
-
The generic stopword list fails to consider the industry characteristics of cosmetics reviews and the requirements of sentiment analysis, removing some useful features and leading to a significant drop in the model’s Class 0 F1-score.
-
The Chinese sentiment-specific stopword list is not optimized for the lexical features of cosmetics reviews, resulting in moderate adaptability.
-
The customized stopword list is constructed based on word frequency statistics and N-gram analysis of cosmetics reviews, accurately removing high-frequency nouns without emotional polarity, retaining key sentiment words, and avoiding incorrect splitting of negative sentiment phrases.
-
The no-stopword strategy allows the model to autonomously learn emotional features from the text, which is more compatible with the autonomous feature extraction capability of deep learning.
(2) Construction logic of the customized stopword list:
Statistical analysis is performed on words that frequently appear in both positive and negative reviews. Nouns without emotional polarity (such as "effect", "price", "lipstick") are removed, while words with emotional expression (such as verbs and adjectives) are retained. Meanwhile, the splitting of negative sentiment phrases into individual words is avoided to prevent the accidental removal of key sentiment words, ultimately providing a cleaner and more efficient feature input for the model.
Question 3:
Why is there a huge difference in the optimization effect of Bayesian optimization on different models in this study? What is the performance of each core model after optimization?
(1) Core reasons for the differences in optimization effects:
Bayesian optimization improves the generalization ability of models by intelligently searching for optimal hyperparameters (such as learning rate, batch size, network structure, etc.). Deep learning models (LSTM, CNN) have a more complex hyperparameter space, and the initial parameter settings have a greater impact on model performance, leading to a more significant tuning effect of Bayesian optimization. In contrast, Logistic Regression, as a traditional linear model, has a simple hyperparameter space, and its initial performance is close to the model’s upper limit, resulting in only a slight performance improvement after optimization.
(2) Performance of core models after optimization:
After Bayesian optimization, the LSTM model achieves the best performance with a Class 0 F1-score of 0.8598; the CNN model reaches 0.8521, slightly lower than LSTM; the Logistic Regression model only improves from 0.8135 to 0.8139 with a minimal increase. The optimization effect on deep learning models is far superior to that on traditional machine learning models, making them the optimal choice for solving negative sentiment prediction in cosmetics reviews.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)