基于深度强化学习的光伏系统MPPT控制技术探索
基于深度强化学习的光伏系统 MPPT 控制技术 太阳能电池引入新材料以提高能量转换效率外,最大功率点跟踪(MPPT) 算法,以确保光伏系统在最大功率点时有效运行。 本模型搭建了DQN和深度确定性策略梯度(DDPG)的MPPT 控制器,提高光伏能量转换系统的高效和稳健性。 在 MATLAB/Simulink 搭建两种基于DRL的光伏系统高效鲁棒 MPPT 控制器,包括 DQN 和 DDPG。 本模型有详细说明文档(SCI 3区,paper)
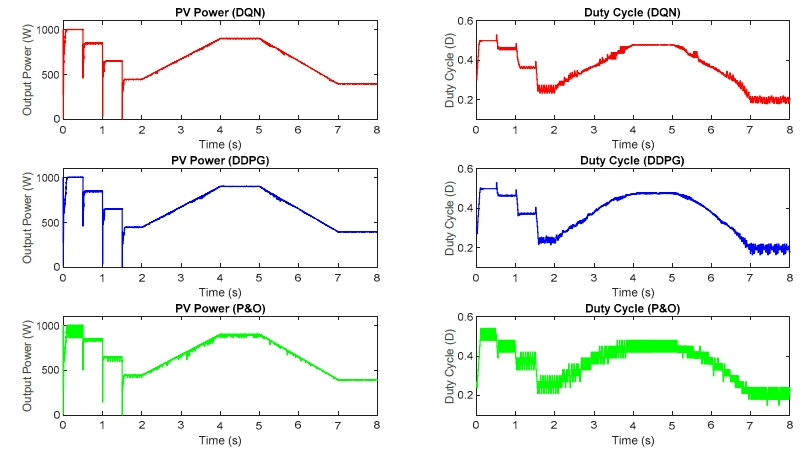
在光伏系统的研究领域,提高能量转换效率一直是重中之重。除了在太阳能电池中引入新材料,最大功率点跟踪(MPPT)算法也至关重要,它能确保光伏系统始终在最大功率点处高效运行。今天,就和大家分享下基于深度强化学习实现光伏系统MPPT控制技术的一些研究成果。
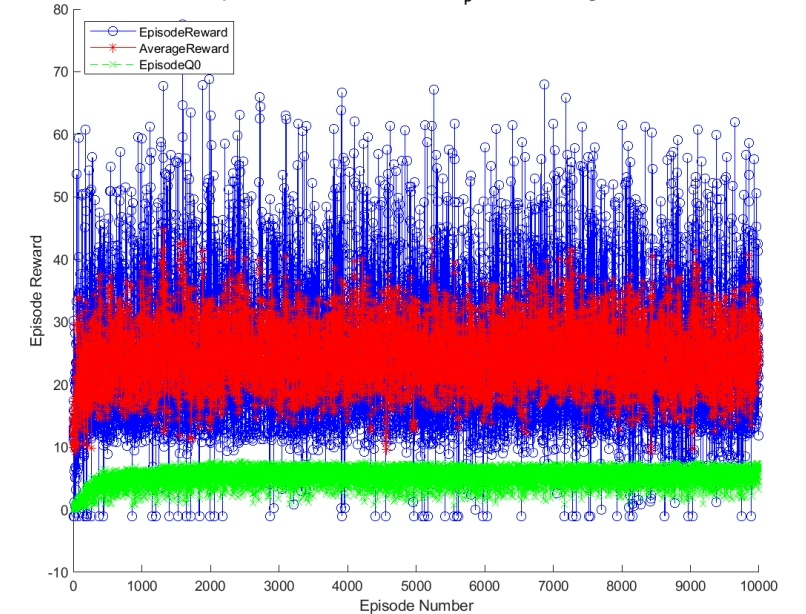
我们搭建了基于深度Q网络(DQN)和深度确定性策略梯度(DDPG)的MPPT控制器,以此来提升光伏能量转换系统的高效性与稳健性。并且,我们是在MATLAB/Simulink环境下搭建了这两种基于深度强化学习(DRL)的光伏系统高效鲁棒MPPT控制器,也就是DQN和DDPG。
DQN算法原理与代码示例
DQN基于Q学习算法,结合了深度学习来处理高维度状态空间。简单来说,它通过一个神经网络来近似Q值函数,这个网络被称为Q网络。在训练过程中,智能体与环境进行交互,收集经验并存储在经验回放池中。从经验回放池中随机采样小批量数据来训练Q网络,使得Q网络能够更好地学习到最优策略。
基于深度强化学习的光伏系统 MPPT 控制技术 太阳能电池引入新材料以提高能量转换效率外,最大功率点跟踪(MPPT) 算法,以确保光伏系统在最大功率点时有效运行。 本模型搭建了DQN和深度确定性策略梯度(DDPG)的MPPT 控制器,提高光伏能量转换系统的高效和稳健性。 在 MATLAB/Simulink 搭建两种基于DRL的光伏系统高效鲁棒 MPPT 控制器,包括 DQN 和 DDPG。 本模型有详细说明文档(SCI 3区,paper)
以下是一个简化的DQN代码示例(Python,使用PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# 定义Q网络
class QNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# 经验回放池
class ReplayBuffer:
def __init__(self, capacity):
self.capacity = capacity
self.buffer = []
self.position = 0
def push(self, state, action, reward, next_state, done):
if len(self.buffer) < self.capacity:
self.buffer.append(None)
self.buffer[self.position] = (state, action, reward, next_state, done)
self.position = (self.position + 1) % self.capacity
def sample(self, batch_size):
batch = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = map(np.stack, zip(*batch))
return state, action, reward, next_state, done
def __len__(self):
return len(self.buffer)
# 参数设置
state_dim = 10 # 状态维度
action_dim = 5 # 动作维度
learning_rate = 0.001
gamma = 0.99
batch_size = 32
buffer_size = 10000
# 初始化Q网络和目标Q网络
q_network = QNetwork(state_dim, action_dim)
target_q_network = QNetwork(state_dim, action_dim)
target_q_network.load_state_dict(q_network.state_dict())
# 定义优化器和损失函数
optimizer = optim.Adam(q_network.parameters(), lr=learning_rate)
criterion = nn.MSELoss()
# 经验回放池初始化
replay_buffer = ReplayBuffer(buffer_size)
# 训练循环
for episode in range(1000):
state = np.random.rand(state_dim)
done = False
while not done:
state_tensor = torch.FloatTensor(state).unsqueeze(0)
q_values = q_network(state_tensor)
action = torch.argmax(q_values).item()
# 执行动作,获取下一个状态、奖励和是否结束
next_state = np.random.rand(state_dim)
reward = np.random.rand()
done = np.random.choice([True, False], p=[0.1, 0.9])
replay_buffer.push(state, action, reward, next_state, done)
state = next_state
if len(replay_buffer) >= batch_size:
state_batch, action_batch, reward_batch, next_state_batch, done_batch = replay_buffer.sample(batch_size)
state_batch = torch.FloatTensor(state_batch)
action_batch = torch.LongTensor(action_batch).unsqueeze(1)
reward_batch = torch.FloatTensor(reward_batch).unsqueeze(1)
next_state_batch = torch.FloatTensor(next_state_batch)
done_batch = torch.FloatTensor(done_batch).unsqueeze(1)
q_values = q_network(state_batch).gather(1, action_batch)
next_q_values = target_q_network(next_state_batch).max(1)[0].detach().unsqueeze(1)
target_q_values = reward_batch + (1 - done_batch) * gamma * next_q_values
loss = criterion(q_values, target_q_values)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 定期更新目标Q网络
if episode % 10 == 0:
target_q_network.load_state_dict(q_network.state_dict())在这段代码中,我们首先定义了Q网络结构,它包含三层全连接层。然后创建了经验回放池ReplayBuffer,用于存储和采样经验。在训练循环中,智能体根据当前状态选择动作,与环境交互并将经验存入回放池。当回放池中有足够数据时,采样小批量数据进行训练,通过计算Q值与目标Q值的均方误差损失来更新Q网络。
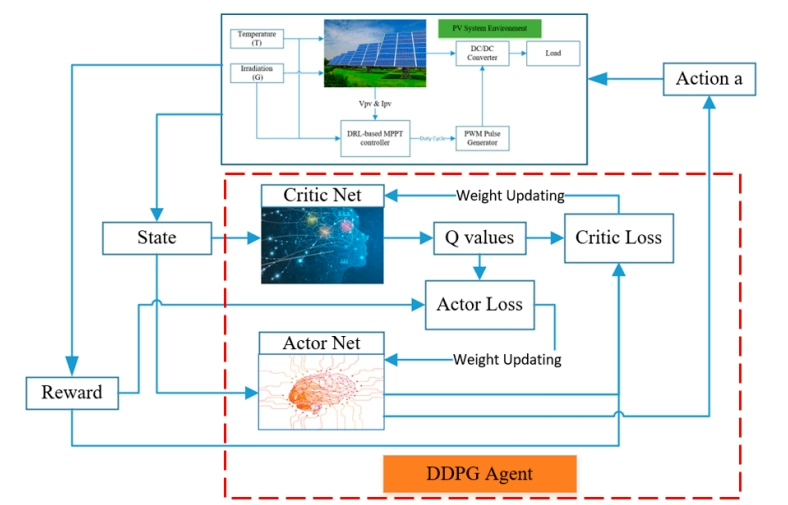
DDPG算法原理与代码示例
DDPG是用于连续动作空间的深度强化学习算法,它结合了深度Q网络(DQN)和确定性策略梯度(DPG)的思想。DDPG使用两个神经网络,一个用于生成动作(策略网络),另一个用于评估动作(价值网络)。同时,它也有对应的目标网络来稳定训练过程。
下面是一个简化的DDPG代码示例(Python,使用PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
# 定义策略网络
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, action_bound):
super(Actor, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
self.action_bound = action_bound
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
action = torch.tanh(self.fc3(x))
return action * self.action_bound
# 定义价值网络
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
self.fc1 = nn.Linear(state_dim + action_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, 1)
def forward(self, state, action):
x = torch.cat([state, action], dim=1)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# 定义OU噪声,用于探索
class OUNoise:
def __init__(self, action_dimension, scale=0.1, mu=0, theta=0.15, sigma=0.2):
self.action_dimension = action_dimension
self.scale = scale
self.mu = mu
self.theta = theta
self.sigma = sigma
self.state = np.ones(self.action_dimension) * self.mu
def reset(self):
self.state = np.ones(self.action_dimension) * self.mu
def noise(self):
x = self.state
dx = self.theta * (self.mu - x) + self.sigma * np.random.randn(len(x))
self.state = x + dx
return self.state * self.scale
# 参数设置
state_dim = 10
action_dim = 1
action_bound = 1
learning_rate_actor = 0.0001
learning_rate_critic = 0.001
gamma = 0.99
tau = 0.001
buffer_size = 100000
batch_size = 64
# 初始化策略网络、价值网络及其目标网络
actor = Actor(state_dim, action_dim, action_bound)
critic = Critic(state_dim, action_dim)
target_actor = Actor(state_dim, action_dim, action_bound)
target_critic = Critic(state_dim, action_dim)
target_actor.load_state_dict(actor.state_dict())
target_critic.load_state_dict(critic.state_dict())
# 定义优化器
optimizer_actor = optim.Adam(actor.parameters(), lr=learning_rate_actor)
optimizer_critic = optim.Adam(critic.parameters(), lr=learning_rate_critic)
# 经验回放池初始化
replay_buffer = []
# 训练循环
for episode in range(1000):
state = np.random.rand(state_dim)
ou_noise = OUNoise(action_dim)
done = False
while not done:
state_tensor = torch.FloatTensor(state).unsqueeze(0)
action = actor(state_tensor)
action = action.detach().numpy() + ou_noise.noise()
action = np.clip(action, -action_bound, action_bound)
# 执行动作,获取下一个状态、奖励和是否结束
next_state = np.random.rand(state_dim)
reward = np.random.rand()
done = np.random.choice([True, False], p=[0.1, 0.9])
replay_buffer.append((state, action, reward, next_state, done))
if len(replay_buffer) > buffer_size:
replay_buffer.pop(0)
state = next_state
if len(replay_buffer) >= batch_size:
batch = random.sample(replay_buffer, batch_size)
state_batch = torch.FloatTensor(np.array([e[0] for e in batch]))
action_batch = torch.FloatTensor(np.array([e[1] for e in batch]))
reward_batch = torch.FloatTensor(np.array([e[2] for e in batch])).unsqueeze(1)
next_state_batch = torch.FloatTensor(np.array([e[3] for e in batch]))
done_batch = torch.FloatTensor(np.array([e[4] for e in batch])).unsqueeze(1)
# 计算目标Q值
target_action = target_actor(next_state_batch)
target_q_value = target_critic(next_state_batch, target_action)
target_q_value = reward_batch + (1 - done_batch) * gamma * target_q_value
# 更新价值网络
current_q_value = critic(state_batch, action_batch)
critic_loss = nn.MSELoss()(current_q_value, target_q_value.detach())
optimizer_critic.zero_grad()
critic_loss.backward()
optimizer_critic.step()
# 更新策略网络
actor_loss = -critic(state_batch, actor(state_batch)).mean()
optimizer_actor.zero_grad()
actor_loss.backward()
optimizer_actor.step()
# 软更新目标网络
for target_param, param in zip(target_actor.parameters(), actor.parameters()):
target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)
for target_param, param in zip(target_critic.parameters(), critic.parameters()):
target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)
在这段代码中,我们定义了策略网络Actor和价值网络Critic。策略网络用于生成动作,价值网络用于评估动作的价值。通过OU噪声来增加探索性,经验回放池存储经验并用于训练。在训练过程中,交替更新策略网络和价值网络,并软更新目标网络以稳定训练。
通过在MATLAB/Simulink中搭建基于DQN和DDPG的MPPT控制器,我们能够有效提升光伏系统的能量转换效率与稳定性。并且本模型有详细说明文档,发表在SCI 3区的paper中,如果大家感兴趣可以进一步查阅。希望这些分享能给从事光伏系统研究的小伙伴们一些启发,一起在这个领域探索更多的可能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)