基于GJO-TCN-BiGRU-Attention金豹算法优化的多变量时间序列预测
Matlab完整源码和数据 1.基于GJO-TCN-BiGRU-Attention金豹算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测,要求Matlab2023版以上; 2.输入多个特征,输出单个变量,考虑历史特征的影响,多变量时间序列预测; 3.data为数据集,main.m为主运行即可,所有文件放在一个文件夹; 4.命令窗口输出R2、MSE、MAE、MAPE和RMSE多指标评价; 5.优化学习率,神经元个数,注意力机制的键值, 正则化参数。
最近在研究多变量时间序列预测问题,发现了一种很有意思的方法,基于GJO-TCN-BiGRU-Attention金豹算法优化时间卷积双向门控循环单元融合注意力机制来进行预测。今天就来和大家分享一下这个过程。
一、算法概述
这个算法结合了多种强大的模型和优化策略。其中,时间卷积网络(TCN)擅长处理时间序列中的局部依赖关系,双向门控循环单元(BiGRU)能够捕捉序列中的长期依赖,而注意力机制则可以聚焦于重要的时间步,增强模型对关键信息的捕捉能力。金豹算法则用于优化模型的超参数,如学习率、神经元个数、注意力机制的键值以及正则化参数等,以提升模型的性能。
二、Matlab实现
(一)数据集准备
首先,我们需要准备好数据集data。假设我们的数据集中有多个特征列作为输入,最后一列为输出的单个变量。例如,我们的数据可以存储在一个CSV文件中,使用以下代码读取:
data = readtable('your_data.csv');
input_vars = data(:, 1:end-1); % 输入的多个特征
output_var = data(:, end); % 输出的单个变量(二)模型构建
接下来构建基于GJO-TCN-BiGRU-Attention的模型。这里我们使用Matlab的深度学习工具箱来实现。
- 时间卷积网络(TCN)
layers = [
sequenceInputLayer(size(input_vars, 2))
temporalConvolutionLayer(32, 7)
batchNormalizationLayer
reluLayer
temporalPoolingLayer(3)
temporalConvolutionLayer(64, 7)
batchNormalizationLayer
reluLayer
temporalPoolingLayer(3)
fullyConnectedLayer(1)
regressionLayer
];这段代码定义了一个简单的TCN结构。首先是输入层,接受多变量时间序列数据。然后是两层时间卷积,接着是批归一化和ReLU激活函数,再进行池化操作,最后通过全连接层和回归层输出预测结果。
- 双向门控循环单元(BiGRU)
layers = [
sequenceInputLayer(size(input_vars, 2))
bilstmLayer(32)
fullyConnectedLayer(1)
regressionLayer
];这里构建了一个简单的BiGRU模型,输入层之后直接接入BiGRU层,然后是全连接层和回归层。
- 融合注意力机制
layers = [
sequenceInputLayer(size(input_vars, 2))
attentionLayer
fullyConnectedLayer(1)
regressionLayer
];添加注意力层到模型中,通过注意力机制聚焦重要时间步信息。
(三)金豹算法优化
使用金豹算法来优化模型的超参数。这里需要定义一些适应度函数来评估模型性能。
function fitness = myFitnessFunction(params)
learningRate = params(1);
numNeurons = params(2);
attentionKey = params(3);
regParam = params(4);
% 根据超参数调整模型结构
layers = [
sequenceInputLayer(size(input_vars, 2))
bilstmLayer(numNeurons)
attentionLayer('AttentionDimension', attentionKey)
fullyConnectedLayer(1)
regressionLayer
];
options = trainingOptions('adam',...
'MaxEpochs', 100,...
'InitialLearnRate', learningRate,...
'L2Regularization', regParam);
model = trainNetwork(input_vars, output_var, layers, options);
predictions = predict(model, input_vars);
% 计算评价指标
r2 = corrcoef(predictions, output_var);
mse = mean((predictions - output_var).^2);
mae = mean(abs(predictions - output_var));
mape = mean(abs((predictions - output_var)./output_var));
rmse = sqrt(mse);
fitness = -r2(1, 2); % 这里取负的R2是因为金豹算法默认求最大值,而我们希望最小化损失
end这段代码定义了适应度函数myFitnessFunction。它接受一组超参数,根据这些超参数调整模型结构并训练模型,然后计算预测结果与真实值之间的多个评价指标(R2、MSE、MAE、MAPE和RMSE),最后返回一个适应度值(这里取负的R2)。
(四)主运行文件`main.m`
% 初始化金豹算法参数
numVars = 4; % 超参数个数(学习率、神经元个数、注意力键值、正则化参数)
lb = [0.0001, 16, 8, 0.001]; % 超参数下限
ub = [0.1, 128, 64, 0.1]; % 超参数上限
options = gaoptimset('PopulationSize', 50, 'MaxGenerations', 100);
[bestParams, bestFitness] = ga(@myFitnessFunction, numVars, [], [], [], [], lb, ub, [], options);
% 根据最优超参数构建并训练最终模型
learningRate = bestParams(1);
numNeurons = bestParams(2);
attentionKey = bestParams(3);
regParam = bestParams(4);
layers = [
sequenceInputLayer(size(input_vars, 2))
bilstmLayer(numNeurons)
attentionLayer('AttentionDimension', attentionKey)
fullyConnectedLayer(1)
regressionLayer
];
options = trainingOptions('adam',...
'MaxEpochs', 200,...
'InitialLearnRate', learningRate,...
'L2Regularization', regParam);
finalModel = trainNetwork(input_vars, output_var, layers, options);
% 预测并输出评价指标
finalPredictions = predict(finalModel, input_vars);
r2 = corrcoef(finalPredictions, output_var);
mse = mean((finalPredictions - output_var).^2);
mae = mean(abs(finalPredictions - output_var));
mape = mean(abs((finalPredictions - output_var)./output_var));
rmse = sqrt(mse);
fprintf('R2: %.4f\n', r2(1, 2));
fprintf('MSE: %.4f\n', mse);
fprintf('MAE: %.4f\n', mae);
fprintf('MAPE: %.4f%%\n', mape * 100);
fprintf('RMSE: %.4f\n', rmse);在main.m文件中,首先初始化金豹算法的参数,包括超参数的个数、下限和上限。然后使用遗传算法(GA)调用适应度函数来寻找最优超参数。最后根据最优超参数构建并训练最终模型,进行预测并输出多指标评价结果。
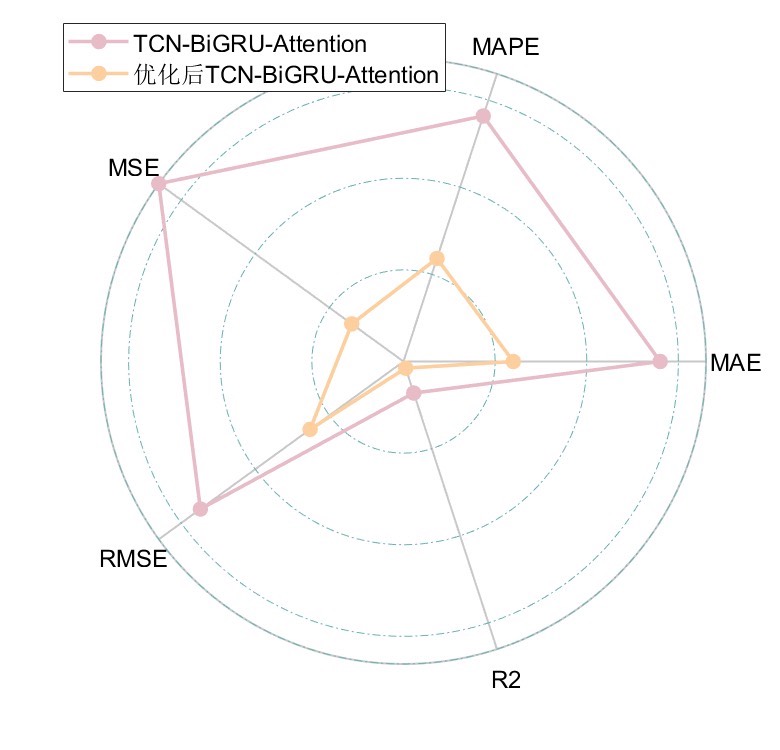
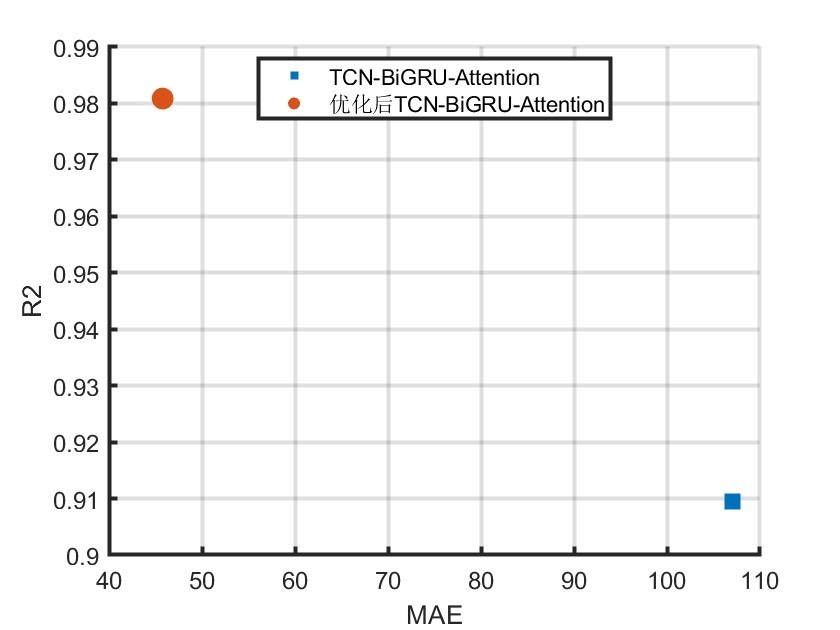
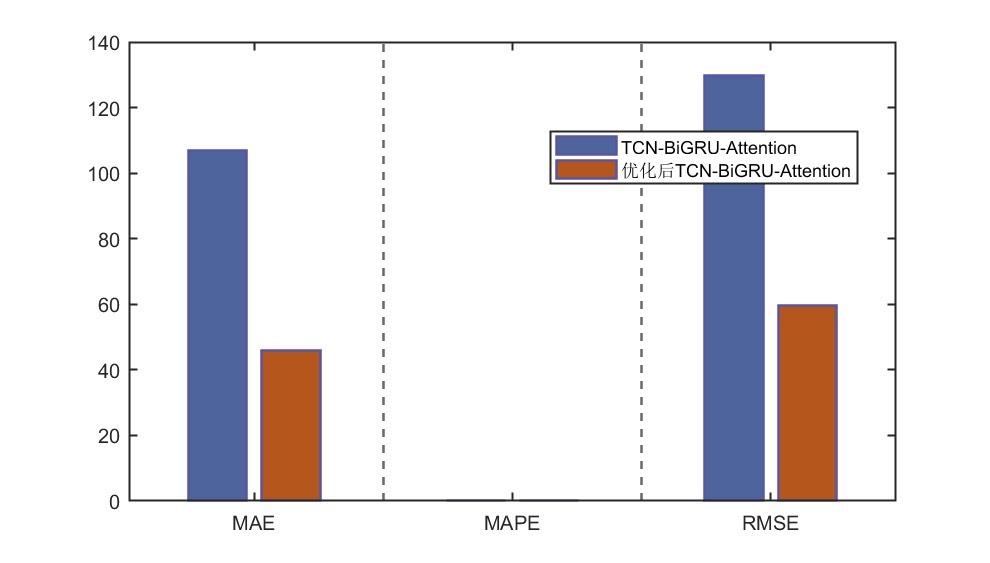
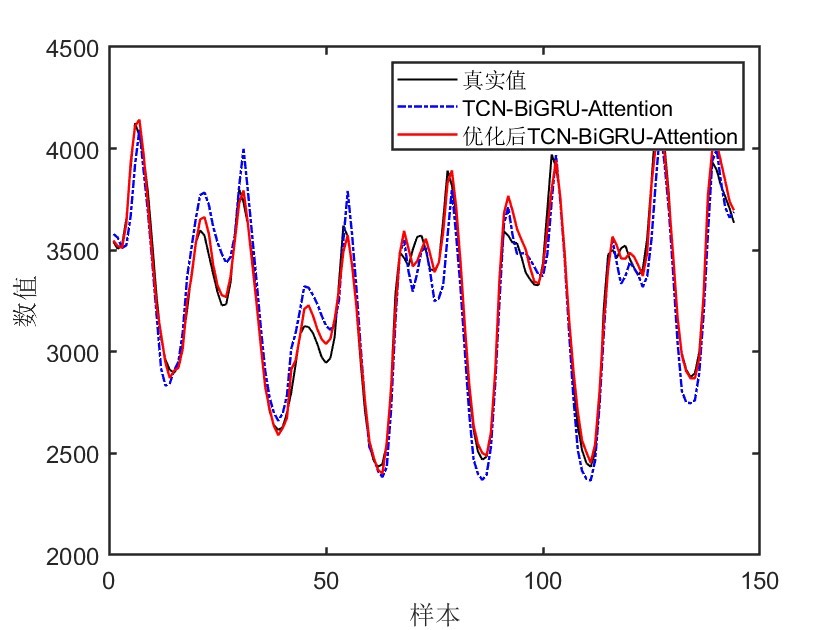
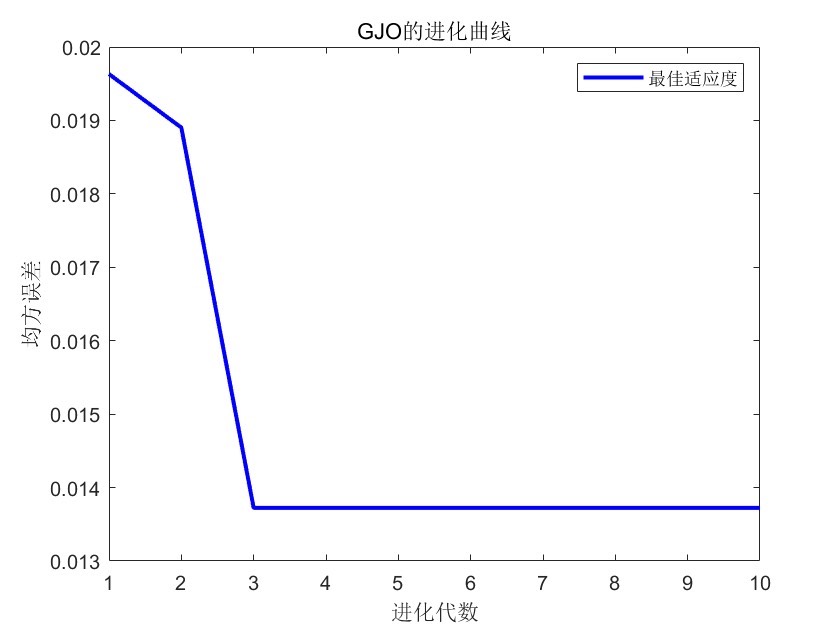
三、结果分析
运行main.m文件后,命令窗口会输出R2、MSE、MAE、MAPE和RMSE等多指标评价。这些指标可以帮助我们全面评估模型的预测性能。例如,如果R2接近1,说明模型拟合效果较好;MSE、MAE和RMSE值越小,说明预测值与真实值的误差越小;MAPE则反映了相对误差的平均水平。通过分析这些指标,我们可以了解模型在不同方面的表现,进而判断是否满足实际应用的需求。
Matlab完整源码和数据 1.基于GJO-TCN-BiGRU-Attention金豹算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测,要求Matlab2023版以上; 2.输入多个特征,输出单个变量,考虑历史特征的影响,多变量时间序列预测; 3.data为数据集,main.m为主运行即可,所有文件放在一个文件夹; 4.命令窗口输出R2、MSE、MAE、MAPE和RMSE多指标评价; 5.优化学习率,神经元个数,注意力机制的键值, 正则化参数。
总之,基于GJO-TCN-BiGRU-Attention金豹算法优化的多变量时间序列预测方法在Matlab中实现起来并不复杂,而且通过优化超参数能够有效提升模型性能。希望这篇分享对大家研究时间序列预测问题有所帮助!
以上就是整个基于GJO-TCN-BiGRU-Attention金豹算法优化的多变量时间序列预测的Matlab实现过程,从数据集准备到模型构建、优化以及结果分析,都进行了详细的介绍。大家如果有兴趣可以尝试运行一下代码,看看在自己的数据上能取得怎样的效果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)