用Reformer模型实现长期时间序列预测:基于Pytorch框架的探索
Reformer模型,可用于长期时间序列预测。 Pytorch框架 Reformer的重点部分在于: 1、Locality sensitive hash attention(局部敏感哈希注意力):空间换时间 2、Reversible layers(可逆层):时间换空间 3、Chunking FFN layer 操作简单,数据集更换简单
在时间序列预测领域,处理长序列数据一直是个挑战。传统方法在面对长期时间序列时,计算资源和时间成本会急剧上升。今天咱们聊聊Reformer模型,它在处理这类问题上有独特的优势,特别适合长期时间序列预测,而且是基于大家熟悉的Pytorch框架哦。
Reformer重点剖析
Locality sensitive hash attention(局部敏感哈希注意力):空间换时间
这玩意儿是Reformer的一个关键创新。传统的注意力机制计算量会随着序列长度平方增长,处理长序列就力不从心了。而局部敏感哈希注意力采用了一种巧妙的方式,牺牲一些空间来换取计算时间的大幅减少。
简单来说,它把输入序列划分成多个小的“桶”(buckets),通过哈希函数把相似的元素映射到同一个桶中。在计算注意力时,只在每个桶内进行,而不是对整个序列。这样一来,计算量就从序列长度的平方级降到了近似线性级。
Reformer模型,可用于长期时间序列预测。 Pytorch框架 Reformer的重点部分在于: 1、Locality sensitive hash attention(局部敏感哈希注意力):空间换时间 2、Reversible layers(可逆层):时间换空间 3、Chunking FFN layer 操作简单,数据集更换简单
下面这段代码大概展示下局部敏感哈希注意力的一个简单概念实现(实际应用会复杂很多哦):
import torch
import hashlib
def simple_lsh_attention(query, key, value, num_buckets):
batch_size, seq_len, dim = query.size()
bucket_size = seq_len // num_buckets
hash_buckets = [[] for _ in range(num_buckets)]
for i in range(seq_len):
hash_value = int(hashlib.sha256(key[:, i, :].numpy().tobytes()).hexdigest(), 16) % num_buckets
hash_buckets[hash_value].append(i)
output = torch.zeros_like(query)
for bucket in hash_buckets:
if bucket:
q_bucket = query[:, bucket, :]
k_bucket = key[:, bucket, :]
v_bucket = value[:, bucket, :]
attention_scores = torch.matmul(q_bucket, k_bucket.transpose(-2, -1))
attention_scores = torch.softmax(attention_scores, dim=-1)
output[:, bucket, :] = torch.matmul(attention_scores, v_bucket)
return output
在这段代码里,我们通过一个简单的哈希函数(这里用了SHA256,实际应用会选更高效的哈希函数)把key中的元素映射到不同的桶里,然后只在每个桶内计算注意力得分和最终输出,大大减少了计算量。
Reversible layers(可逆层):时间换空间
可逆层也是Reformer的一大亮点。传统神经网络在反向传播时,需要存储中间层的激活值,序列越长,占用的内存就越大。可逆层通过特殊设计,让我们在反向传播时可以重新计算中间层激活值,而不是存储它们,这就把空间复杂度降下来了,不过代价是反向传播时间会增加一些,这就是所谓的时间换空间。
Chunking FFN layer
Chunking FFN layer是对前馈神经网络层(FFN)的一种优化。它把输入序列分成多个块(chunks),分别进行FFN计算,最后再合并结果。这样可以减少内存占用,尤其在处理长序列时效果显著。
操作与数据集更换的便利性
Reformer模型操作起来相当简单。在Pytorch里搭建模型结构,只需要按照各个模块的逻辑依次组合就行。而且数据集更换也不麻烦,不管是新的时间序列数据集,还是不同格式的数据,只要按照Pytorch的标准数据加载流程稍作调整,就能适配到Reformer模型上。
比如加载一个简单的时间序列数据集:
from torch.utils.data import Dataset, DataLoader
class TimeSeriesDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
data = torch.randn(1000, 10) # 这里简单模拟1000个长度为10的时间序列数据
dataset = TimeSeriesDataset(data)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
以上代码展示了如何用Pytorch加载一个简单的时间序列数据集,将其包装成Dataset类并通过DataLoader进行批量加载,要是更换数据集,只需要修改data部分的数据来源和格式调整即可。
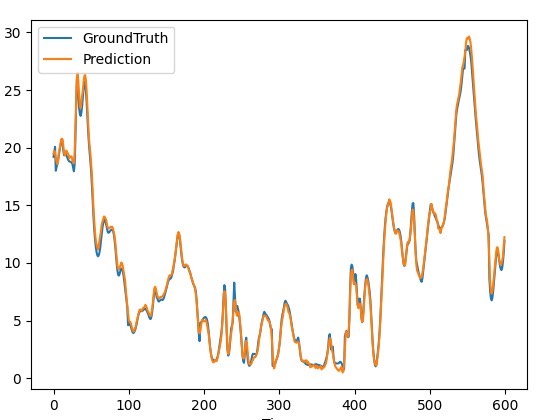
总之,Reformer模型凭借它独特的设计,在长期时间序列预测上有很大的潜力,再加上Pytorch框架的便利性,让我们在实际应用中能够更加轻松地进行模型搭建和优化。无论是研究还是实际业务场景,都值得一试。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)