无人船目标跟踪控制:NMPC 与 PPO 强化学习的对决
基于NMPC与PPO强化学习无人船/无人艇的目标跟踪控制 python源文件 gym环境 文献+程序 两种控制方法对比 非线性模型预测控制
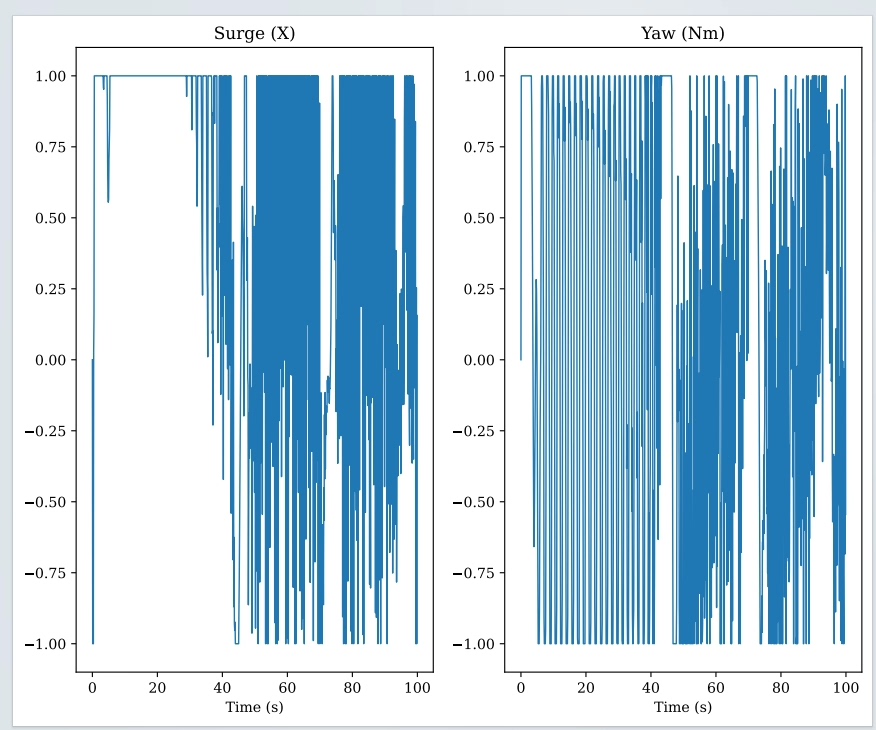
在无人船/无人艇的目标跟踪控制领域,非线性模型预测控制(NMPC)与近端策略优化(PPO)强化学习这两种方法备受关注。今天咱们就深入探讨一下这两种控制方法,并结合 Python 源文件和 Gym 环境,通过代码来感受它们的魅力。
一、NMPC:非线性模型预测控制
NMPC 是一种基于模型的控制策略,它通过预测系统未来的行为来优化当前的控制输入。在无人船目标跟踪中,它需要建立无人船的非线性动力学模型。
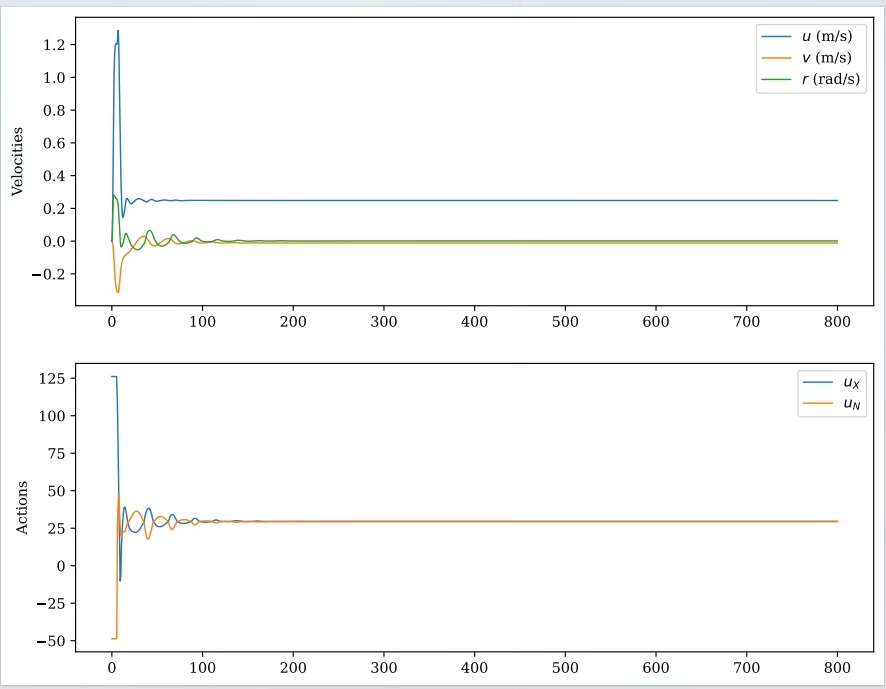
假设有一个简单的无人船运动学模型(这里只是示例简化模型):
import numpy as np
# 无人船简单运动学模型
def unmanned_boat_kinematic_model(state, control_input, dt):
x, y, theta = state
v, omega = control_input
new_x = x + v * np.cos(theta) * dt
new_y = y + v * np.sin(theta) * dt
new_theta = theta + omega * dt
return np.array([new_x, new_y, new_theta])
上述代码定义了一个简单的无人船运动学模型函数 unmannedboatkinematicmodel,它接收当前状态 state(包括位置 x、y 和航向角 theta)、控制输入 controlinput(线速度 v 和角速度 omega)以及时间步长 dt,返回下一时刻的状态。
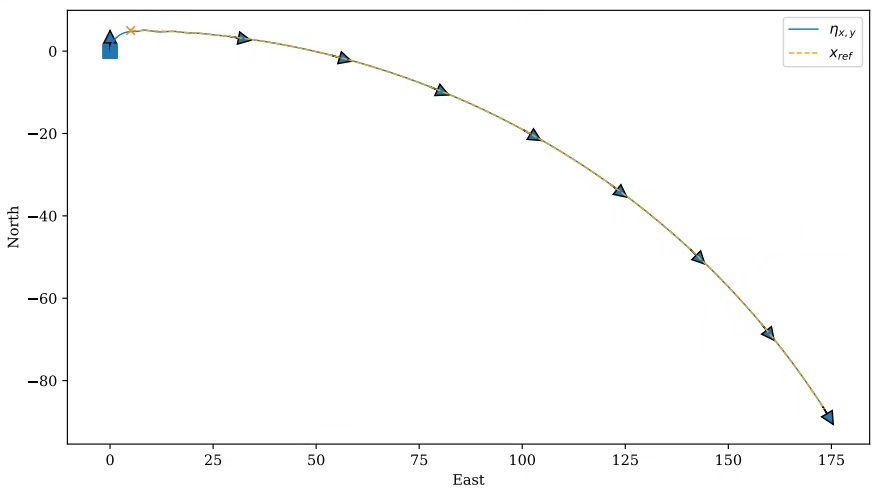
NMPC 的核心就是在每个控制周期内,求解一个有限时域的优化问题,以确定最优的控制输入序列。这个优化问题通常包含预测模型、目标函数(比如最小化跟踪误差)以及约束条件(如速度限制、转向角度限制等)。
二、PPO:近端策略优化强化学习
PPO 是一种无模型的强化学习算法,它不需要精确的系统模型,而是通过智能体与环境的交互来学习最优策略。在无人船目标跟踪场景中,Gym 环境就成为了智能体与外界交互的桥梁。
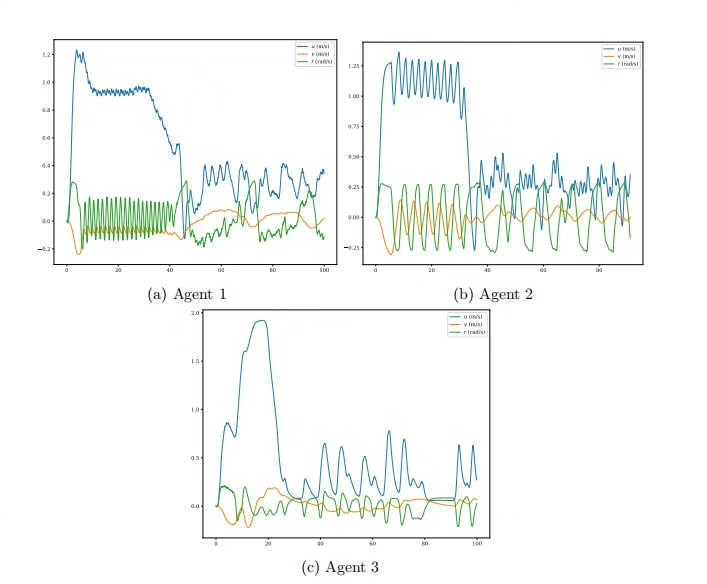
基于NMPC与PPO强化学习无人船/无人艇的目标跟踪控制 python源文件 gym环境 文献+程序 两种控制方法对比 非线性模型预测控制
首先,我们要定义 Gym 环境,以下是一个简化的无人船目标跟踪 Gym 环境框架示例:
import gym
from gym import spaces
class UnmannedBoatTrackingEnv(gym.Env):
def __init__(self):
self.action_space = spaces.Box(low=np.array([-1, -1]), high=np.array([1, 1]))
self.observation_space = spaces.Box(low=np.array([0, 0, 0]), high=np.array([100, 100, np.pi]))
def step(self, action):
# 这里简单模拟环境状态更新,实际需要更复杂逻辑
self.state = self.state + action
reward = -np.linalg.norm(self.state - self.target)
done = np.linalg.norm(self.state - self.target) < 0.5
return self.state, reward, done, {}
def reset(self):
self.state = np.random.uniform(low=[0, 0, 0], high=[100, 100, np.pi])
self.target = np.random.uniform(low=[0, 0, 0], high=[100, 100, np.pi])
return self.state
上述代码创建了一个 UnmannedBoatTrackingEnv 类,继承自 gym.Env。在 init 方法中定义了动作空间和观测空间。step 方法模拟了环境在执行动作后的状态更新、奖励计算以及是否结束的判断。reset 方法用于重置环境状态和目标位置。
PPO 算法在这个环境中训练智能体,通过不断调整策略网络的参数,使得智能体能够学会如何采取最优动作,以达到跟踪目标的目的。
三、两种控制方法对比
- 模型依赖:NMPC 依赖精确的系统模型,对无人船动力学模型的准确性要求较高。如果模型不准确,控制效果会大打折扣。而 PPO 强化学习不需要精确模型,通过与环境交互学习,适应性更强,但训练过程可能需要更多的时间和样本。
- 计算复杂度:NMPC 每个控制周期都要求解一个优化问题,计算量较大,对硬件要求较高。PPO 虽然训练时计算量也不小,但训练完成后,在线执行时计算相对简单,只需根据策略网络输出选择动作。
- 控制性能:在模型准确的情况下,NMPC 能够利用模型信息进行精确的预测和控制,跟踪性能较好。PPO 强化学习通过大量训练,可以学习到复杂的策略,在一些复杂场景下可能表现出色,但训练过程可能陷入局部最优。
在实际应用中,需要根据具体的场景需求、硬件条件以及对模型的了解程度来选择合适的控制方法。
无论是 NMPC 还是 PPO,都在无人船/无人艇目标跟踪控制领域有着重要的应用价值,希望通过今天的介绍和代码示例,能让大家对这两种方法有更深入的理解。如果你对相关文献感兴趣,可以进一步查阅关于无人船控制、NMPC 和 PPO 强化学习的专业资料,里面会有更详细的理论推导和实验验证。
以上就是本次博文的全部内容啦,欢迎大家在评论区交流讨论。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)