Qwen2 详解
1 Qwen2 概述
1.1 Qwen2 整体介绍
Qwen2 的推理流程如下:
- tokenizer 将 text 转化为词表里面的索引 input_ids
- 索引 input_ids 通过 embedding 得到 hidden_states
- hidden_states 经过多个由注意力机制构建的模型解码层 layers
- 然后通过 RMSNorm 对特征进行归一化
- 最后经线性层 linear 输出 output
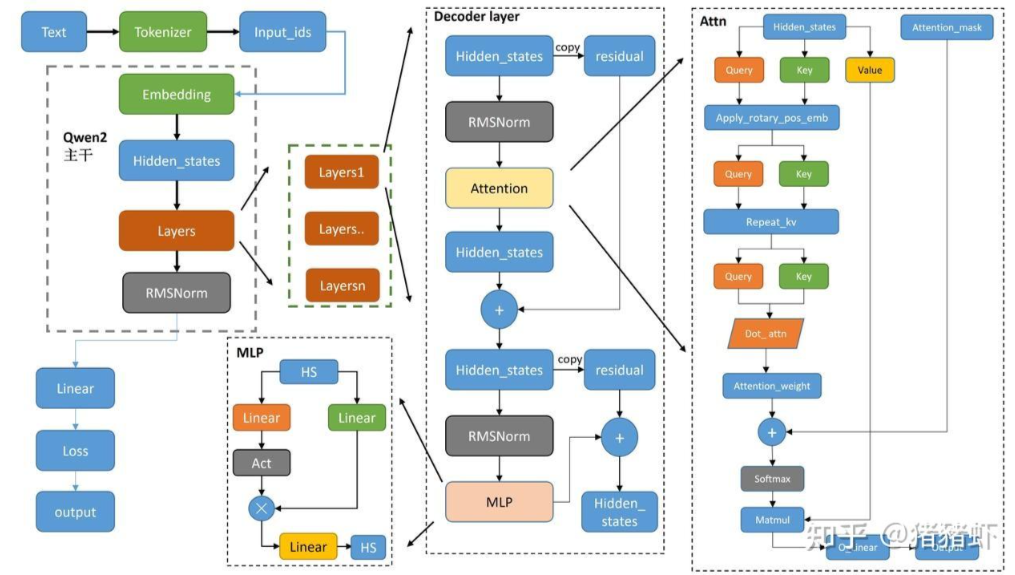
1.2 Qwen2 推理 Tiny Demo
- 定义 Qwen2Config
- 实例化 Qwen2Model
- 构造虚拟输入 input_ids
- 推理 res = qwen2model(input_ids)
2 Qwen2 模型 Qwen2Model
2.1 初始化
初始化中主要定义了
- 嵌入层 self.embed_tokens = nn.Embedding(…)
- 解码器层 self.layers = nn.ModuleList([Qwen2DecoerLayer …])
- 归一化层 self.norm = Qwen2RMSNorm
class Qwen2Model(Qwen2PreTrainedModel):
def __init__(self, config: Qwen2Config):
super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
self.layers = nn.ModuleList(
[Qwen2DecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)
self.norm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()2.2 前向传播
前向传播中主要进行了
- 嵌入 inputs_embeds = self.embed_tokens(input_ids)
- 将特征送入解码层 layer_output = decoder_layer(hidden_states, …)
- 将解码器的第一个输出作为 hidden_states = layer_outputs[0]
- 将输出进行标准化 hidden_states = self.norm(hidden_states)
inputs_embeds = self.embed_tokens(input_ids)
# embed positions
hidden_states = inputs_embeds
for idx, decoder_layer in enumerate(self.layers):
# 将所有的hidden_states保存成tuple
if output_hidden_states:
all_hidden_states += (hidden_states,)
# 将hs送入每一层decoder_layer
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
# 取出上一层decoder_输出的hs,再传入下一个layer
# 只要第一个,第二个是cache的一个类,然后进入下一个layer
hidden_states = layer_outputs[0]
# 将最后layers输出后的hidden_states进行标准化
hidden_states = self.norm(hidden_states)
# 加上最后一层的hidden_states
if output_hidden_states:
all_hidden_states += (hidden_states,)3 Qwen2 解码器 Qwen2DecoderLayer
3.1 初始化
- 注意力层 self.self_attn = QWEN2_ATTENTION_CLASSES[…]
- MLP 层 self.mlp = Qwen2MLP()
- 输入归一化层 self.input_layernorm = Qwen2RMSNorm()
- 注意后归一化层 self.postatten_layernorm = Qwen2RMSNorm()
QWEN2_ATTENTION_CLASSES = {
"eager": Qwen2Attention, # 一般情况下是这个
"flash_attention_2": Qwen2FlashAttention2,
"sdpa": Qwen2SdpaAttention,
}
class Qwen2DecoderLayer(nn.Module):
def __init__(self, config: Qwen2Config):
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = QWEN2_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx)
self.mlp = Qwen2MLP(config)
self.input_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)3.2 前向传播
- 归一化 hidden_states = self.input_layernorm(hidden_states)
- 注意力计算 hidden_states, … = self.self.attn(hidden_states, …)
- 残差相加 hidden_states = residual + hidden_states
- 注意力后归一化 hidden_states = self.post_attention_layernorm(hidden_states)
- MLP hidden_states = self.mlp(hidden_states)
- 残差相加 hidden_states = residual + hidden_states
- 输出 output = (hidden_states, )
residual = hidden_states
# 标准化后送入attn
hidden_states = self.input_layernorm(hidden_states) # RMSNorm标准化
# Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
**kwargs,
)
# 残差与新的hidden_states相加
hidden_states = residual + hidden_states
# Fully Connected
residual = hidden_states
# 同样的RMSNorm标准化
hidden_states = self.post_attention_layernorm(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
outputs = (hidden_states,)
return outputs4 Qwen2 注意力层 Qwen2Attention
4.1 前向推理
- 从 hidden_states 映射得到 query, key, value
- 对 query, key 使用旋转位置编码 apply_rotatary_pos_emb
- 使用 group attention (GQA) 降低对显存需求
- 对注意力的输出进行输出映射 attn_output= self.o_project(attn_output)
# 获取形状信息,hidden_states输入的为(bs,T,hd)
bsz, q_len, _ = hidden_states.size()
# 对hidden_states进行Linear生成query、key、value
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
# reshape多头处理--分块--(bs,T,heads,hd_d)
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
# 将旋转位置嵌入应用于查询和键张量。使用了旋转位置嵌入的余弦和正弦部分,将它们与查询和键张量相乘,并将结果相加,从而实现旋转位置嵌入的效果
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
# 先将key_states和value_states重复了num_key_value_groups次
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
# 使用dot attn实现q*kT/hd_d^0.5
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
# 然后 attn_weights 加上 attention_mask,实现读取顺序
attn_weights = attn_weights + attention_mask
# softmax + dropout + values_states相乘
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)
attn_output = torch.matmul(attn_weights, value_states)
# 转置,修改形状等reshape操作
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
# 最后在进行一次o_proj
attn_output = self.o_proj(attn_output)
# 返回结果
return attn_output, attn_weights, past_key_value4.2 旋转位置编码 Rotary Position Embedding
旋转位置编码作用在 key 和 value 上,高效地形式实现了相对位置的编码。
旋转位置编码是论文 Roformer: Enhanced Transformer with Rotray Position Embedding 提出的。
论文中提出为了能利用上 token 之间的相对位置信息,假定 query 向量 和 key 向量 之间的内积操作可以被一个函数 表示,该函数 的输入是词嵌入向量 , 和它们之间的相对位置 :
接下来的目标就是找到一个等价的位置编码方式,从而使得上述关系成立。
假定现在词嵌入向量的维度是两维 ,这样就可以利用上2维度平面上的向量的几何性质,然后论文中提出了一个满足上述关系的 和 的形式如下:
这里面 Re 表示复数的实部。
进一步地, 可以表示成下面的式子:
看到这里会发现,这不就是 query 向量乘以了一个旋转矩阵吗?这就是为什么叫做旋转位置编码的原因。
同理, 可以表示成下面的式子:
最终 可以表示如下:
关于上面公式(8)~(11)的具体推导,可以参考文章:一文看懂 LLaMA 中的旋转式位置编码(Rotary Position Embedding)。
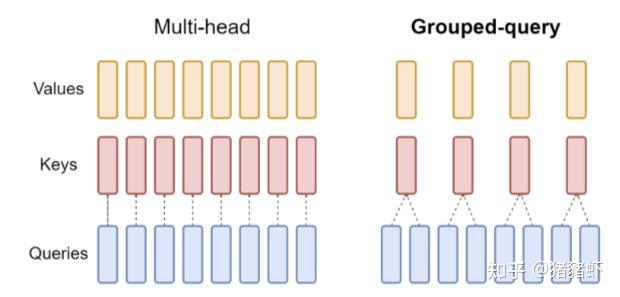
4.3 Grouped Query Attention GQA
通过将查询头 query 分组,每组共享一个 key 和 value。从而降低存储 key 和 value 的数量,节省显存。
5 Qwen2 线性层 Qwen2MLP
这里分了两个支路,一个支路做线性+激活,另外一个支路只做线性,然后进行相乘,再通过一个线性层得到输出。
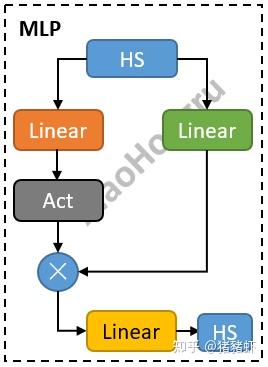
class Qwen2MLP(nn.Module):
def __init__(self, config):
super().__init__()
# 这俩不必多说
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
# 三个全连接层
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_proj6 Qwen2RMSNorm
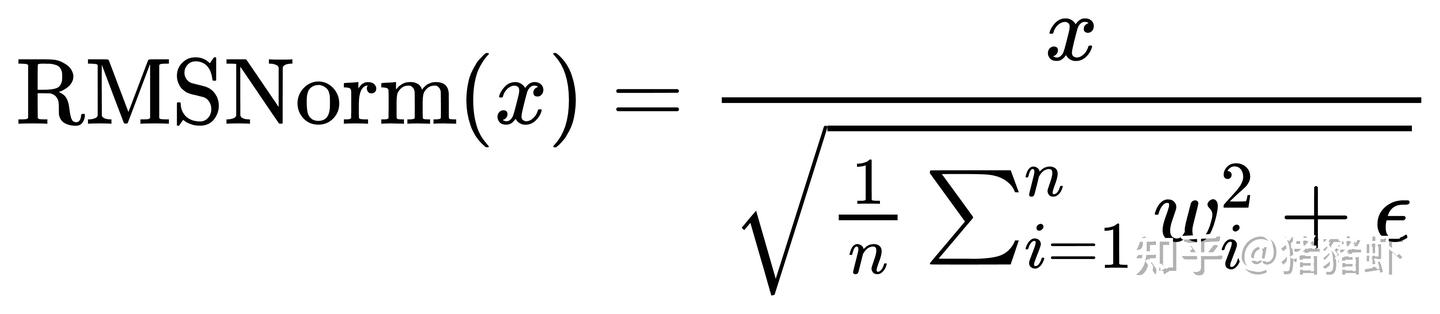
其中 x 是 hidden_state,w 是 hidden_state 的特征纬度。
class Qwen2RMSNorm(nn.Module): # 标准化层
def __init__(self, hidden_size, eps=1e-6):
"""
Qwen2RMSNorm is equivalent to T5LayerNorm
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)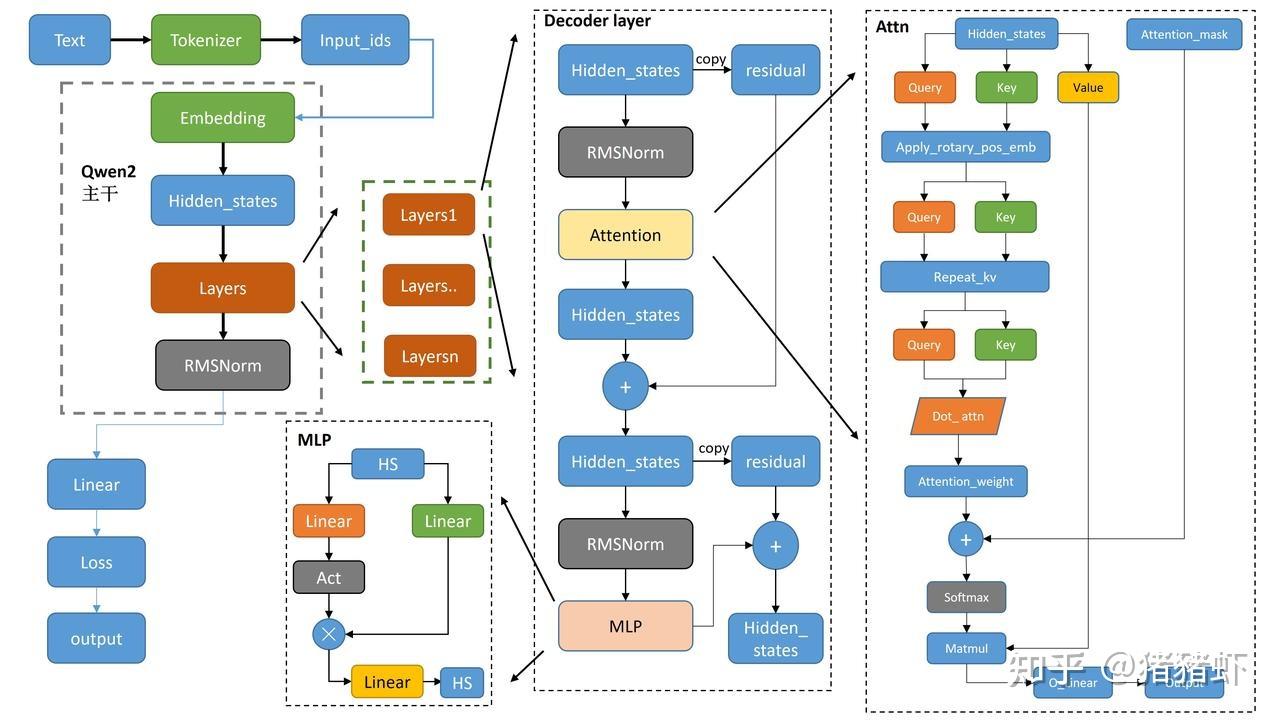
7 参考资料

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)