【动手学深度学习】第八课 卷积神经网络
上几个小节我们介绍了全连接神经网络,但使用它的代价很大。假如我们采用一个12M像素的相机采集图片,那么RGB图片就有36M像素,我们使用100大小的单隐藏层MLP(已经很小了),这样算下来模型至少有3.6B个参数,=14GB,也就是你光存这些参数就花了14个G的内存,更何况这只是单层、并且我们还没做运算!!
那怎么办呢,于是我们引入了一个新的神经网络。
目录
一、卷积神经网络(CNN)
CNN是一类强大的、为处理图像数据而设计的神经网络,基于卷积神经网络架构的模型在计算机视觉领域中已经占主导地位,当今几乎所有的图像识别、目标检测或语义分割相关的应用都以这种方法为基础。
- 输入层:输入图像等信息
- 卷积层:用来提取图像的底层特征
- 池化层:防止过拟合,将数据维度减小
- 全连接层:汇总卷积层和池化层得到的图像的底层特征和信息
- 输出层:根据全连接层的信息得到概率最大的结果
下面我们依次介绍每一层。
二、输入层
对于输入图像,首先要将其转换为对应的二维矩阵,这个二位矩阵就是由图像每一个像素的像素值大小组成的。如下图所示的手写数字“8”的图像,图像的大小为28x28像素,输入层将包含784个神经元(因为28*28=784),每个神经元对应图像中的一个像素。


图像在计算机中是一堆按顺序排列的数字,数值为 0 到 255 。 0 表示最暗,255 表示最亮。
三、卷积层
1. 为什么需要卷积层
我们在开篇就已经提到,如果使用全连接网络,将整张图的全部特征学习明白,实在是太贵了。那卷积层做了一件什么事情呢,它其实像我们人眼一样,看到一个人不会先去关注整体,而是先去关注局部的特征,先去关心他耳朵的特征、眼睛的特征...最后将所有特征结合起来才能判断出这到底是人还是猴。
下面这里定义了一个输入3通道、输出1通道,3*3卷积核的二维卷积层:
net = nn.Conv2d(3,1,kernel_size=3)
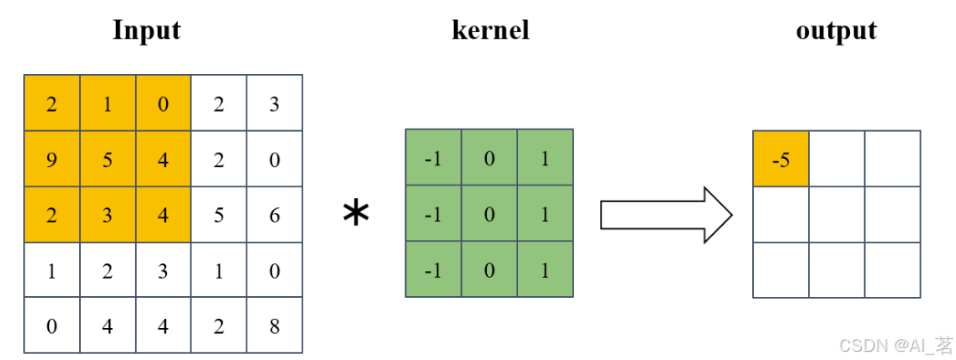
2. 卷积核kernel
给定输入图像,输入图像中一个小区域内的像素加权平均后成为输出图像中的每个对应像素,其中权值由一个函数定义,这个函数称为卷积核。又称滤波器。
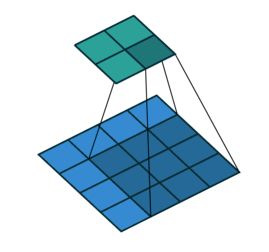
卷积核也是一个二维矩阵,当然这个二维矩阵要比输入图像的二维矩阵要小或相等。卷积核通过在输入图像的二维矩阵上不停的移动,每一次移动都进行一次乘积的求和,作为此位置的值(互相关运算)。
看下面这张图的操作就知道了:
3. 卷积层做了什么?
举个抽象的栗子,假设输入图片是一个人的脑袋,而人的眼睛是我们需要提取的特征,那么我们将人的眼睛作为卷积核,通过在人的脑袋的图片上移动来确定哪里是眼睛,这个过程如下所示:
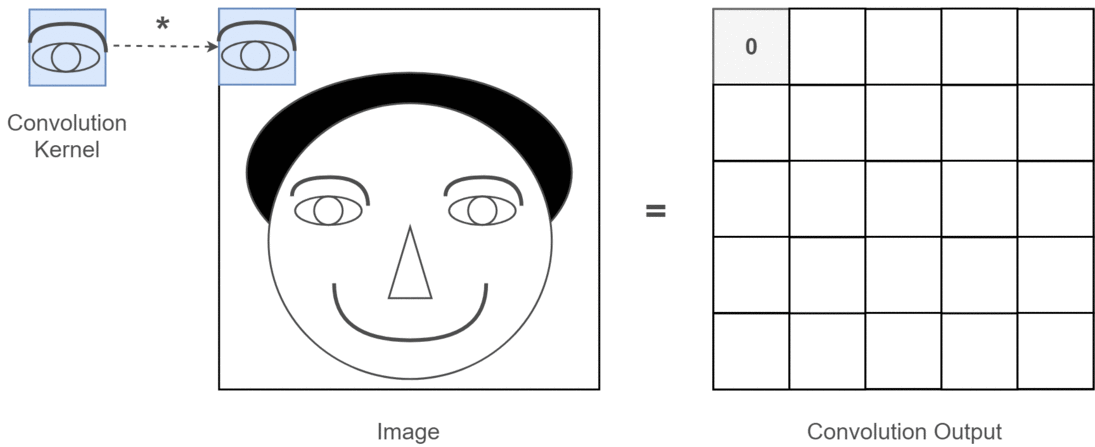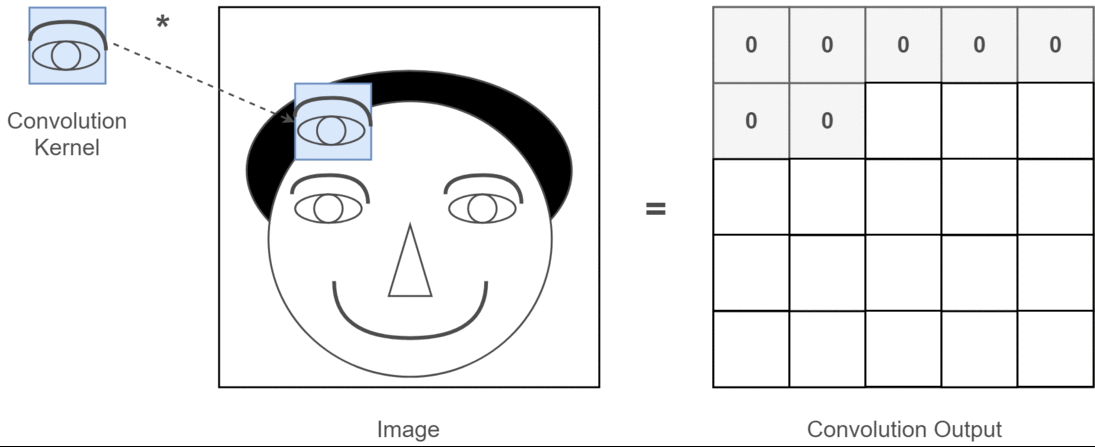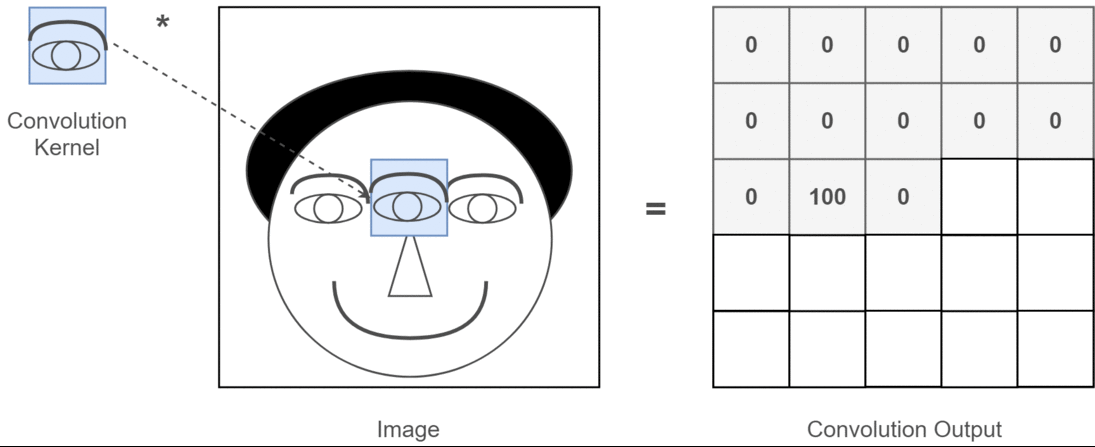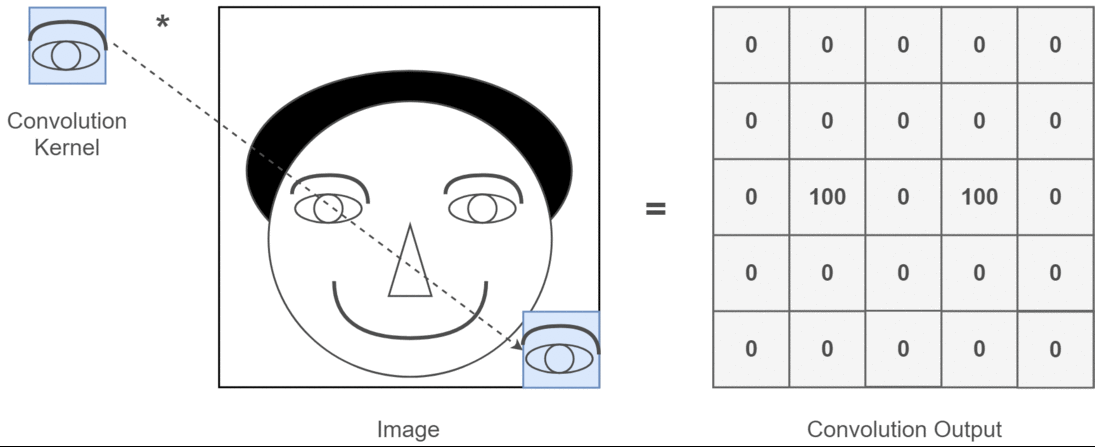
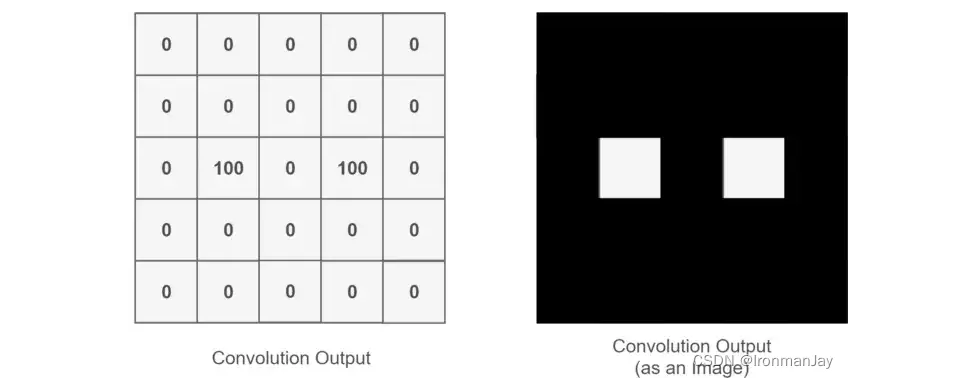
整个过程就是一个降维的过程,通过卷积核的不停移动计算,可以提取图像中最有用的特征。我们通过卷积得到一个新的二维矩阵,即特征图(Feature Map),假如我们将得到的特征图进行上色处理,最后可以提取到关于人的眼睛的特征,如下所示:
再举个具体的栗子,边缘检测卷积核的效果是这样:


用到的卷积核是:
sobel_kernel = torch.tensor([
[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]
]).float()
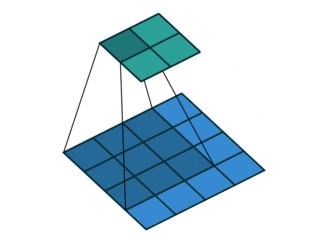
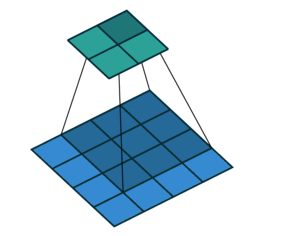
4. 填充padding
(1)我们注意到,卷积核移动的时候,输入图像二维矩阵的中间位置每次都被计算了,而边缘却只计算了一次,这样我们得到的特征图就会丢失边缘特征,最终会导致特征提取不准确。
(2)并且,一个图片经过卷积操作总是会使输出变小的,例3*3的图片经过2*2的卷积核后会变为2*2的特征图,如果我们想使输出大小不改变呢?
于是,我们可以在原始的输入图像的二维矩阵周围再拓展一圈或者几圈。这个操作叫做填充(padding)。
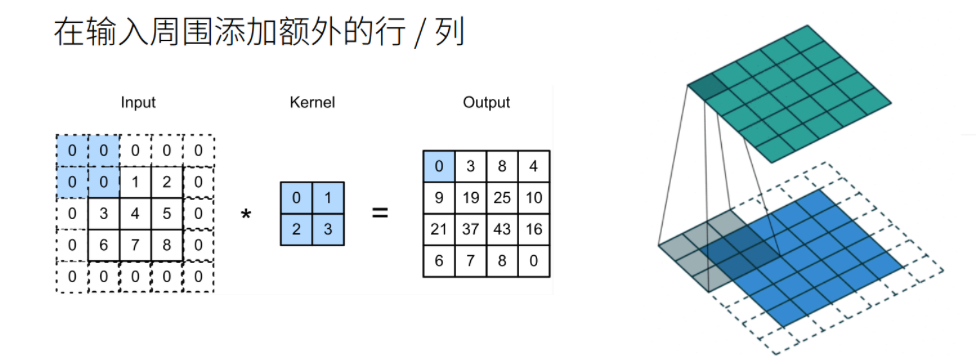
分别填充一圈和两圈的效果如下:
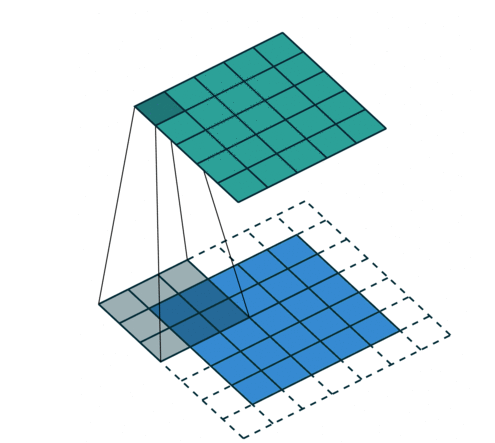
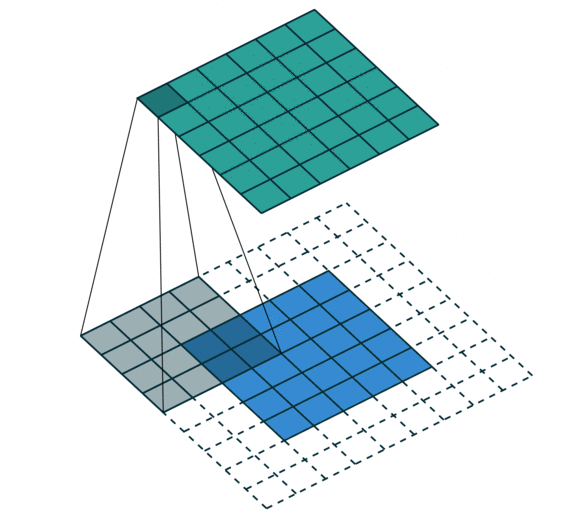
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
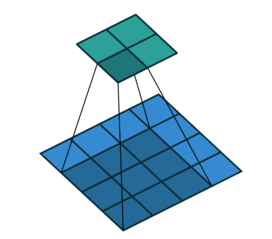
#每边都填充了1行/1列5. 步长stride
在前面的例子中,我们默认每次滑动一个元素。 但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
#每次滑动2格6. 卷积层的多输入多输出
对于多输入多输出的卷积层来说,输出通道数就是卷积层卷积核的个数,输入通道就是一个卷积核里面所包含的通道数。
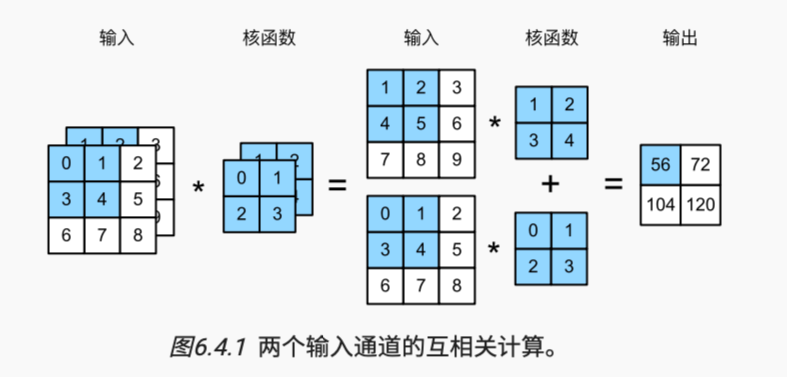
(1)多输入通道
需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算。下图以2通道数的输入为例:
(2)多输出通道
很好理解,多输入需要增加卷积核的通道数,那么多输出就来增加卷积核的个数。上图一样的例子,如果想要输出的通道数是2,那把刚刚那个通道数为2的卷积核再加一个☝️就好了呗。
四、池化层
池化层,也称汇聚层(pooling),用于降低特征图的空间尺寸, 其本质就是对输入的片区域做平均或取最大处理。超参数与卷积核类似常用的有stride,padding,kernel_size。
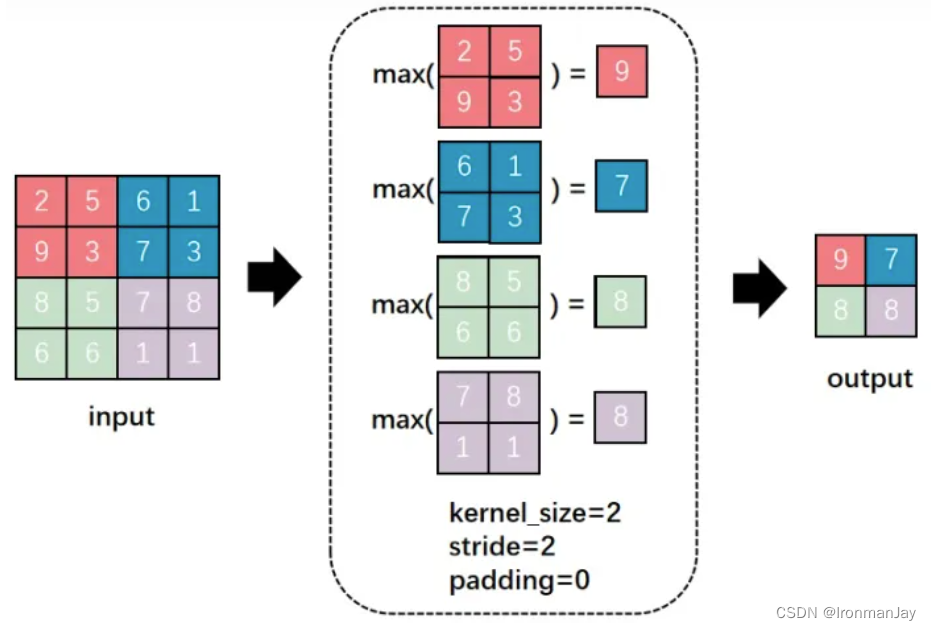
1. 最大池化
与互相关运算符一样,汇聚窗口从输入张量的左上角开始,从左往右、从上往下的在输入张量内滑动。在汇聚窗口到达的每个位置,它计算该窗口中输入子张量的最大值。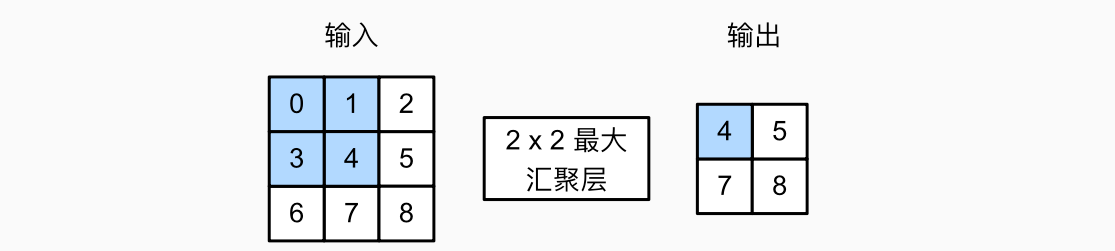
2. 平均池化
同理,对核区域的元素求平均。
五、全连接层
前面章节已经介绍过了。它的主要作用是学习到前面层(如卷积层、池化层等)输出的特征,进行全局整合,并将这些特征进一步映射到输出层。
下一节我们再来看具体的卷积神经网络有哪些。
注:该篇借鉴了李沐老师的深度学习教材和下面这篇文章https://ironmanjay.blog.csdn.net/article/details/128689946?fromshare=blogdetail&sharetype=blogdetail&sharerId=128689946&sharerefer=PC&sharesource=PPofficer&sharefrom=from_link

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)