(论文速读)ROCKET-1:掌握开放世界互动与视觉时间上下文提示
论文题目:ROCKET-1: Mastering Open-World Interaction with Visual-Temporal Context Prompting(掌握开放世界互动与视觉时间上下文提示)
会议:CVPR2025
摘要:视觉语言模型(VLMs)在多模态任务中表现出色,但将其适应于开放世界环境中的具体决策提出了挑战。一个关键问题是弥合低层次观察中的离散实体与有效规划所需的抽象概念之间的差距。一种常见的解决方案是构建分层代理,其中vlm充当高级推理器,将任务分解为可执行的子任务,通常使用语言指定。然而,语言无法传达详细的空间信息。我们提出了一种新的vlm和策略模型之间的通信协议——视觉-时间上下文提示。该协议利用来自过去观察的对象分割来指导策略-环境交互。使用这种方法,我们训练了ROCKET-1,这是一种低级策略,基于连接的视觉观察和分割掩码预测动作,由SAM-2的实时目标跟踪支持。我们的方法释放了vlm的潜力,使它们能够处理需要空间推理的复杂任务。在《我的世界》中的实验表明,我们的方法使智能体能够完成以前无法完成的任务,在开放世界的交互性能上绝对提高了76%。
代码可在https://craftjarvis.github.io/ROCKET-1上获得。
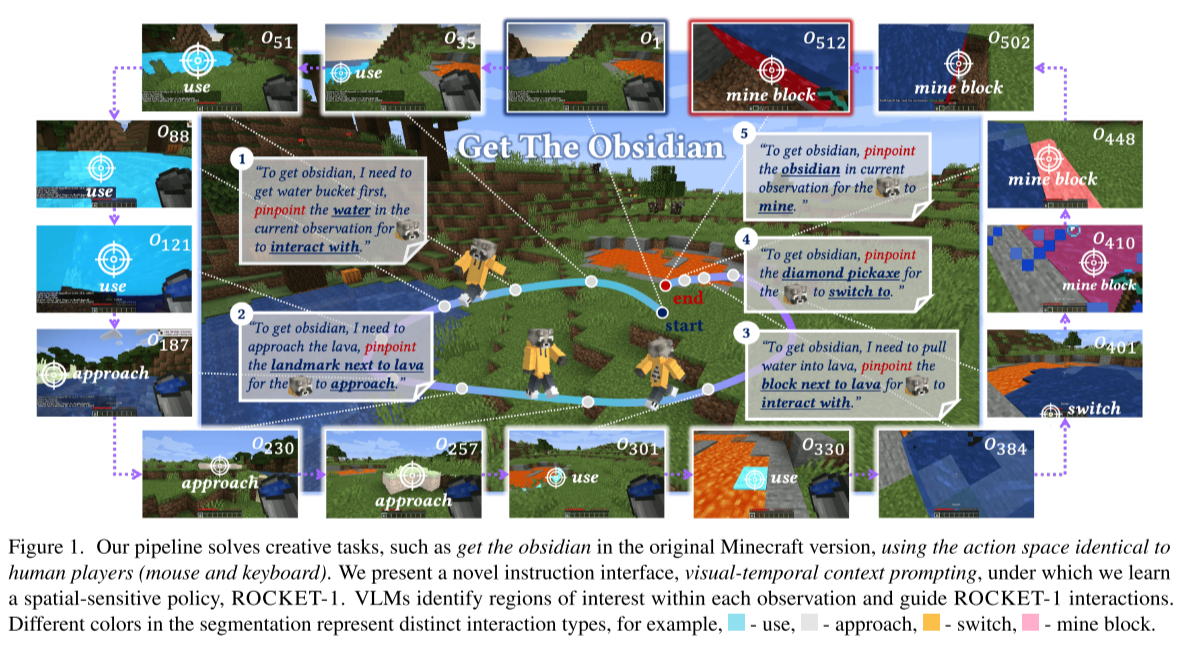
ROCKET-1 - 开启开放世界AI交互的新范式
引言:AI代理的空间感知困境
想象一下这个场景:你让AI助手"去拿右边桌子上的杯子"。对人类来说,这是个简单的任务——我们会看向右边,识别桌子,找到杯子,然后走过去拿。但对AI来说,这个看似简单的任务却充满挑战。
来自北京大学、UCLA和BIGAI的研究团队在CVPR 2025上发表的ROCKET-1论文,为解决这个问题提供了突破性方案。他们的核心洞察令人兴奋:与其用语言描述空间信息,不如直接"指给AI看"。
问题的本质:语言不擅长描述"哪里"
当前的AI代理系统通常采用分层架构:高层规划器(通常是大语言模型)负责思考"做什么",低层执行器负责"怎么做"。两者之间的沟通主要依赖自然语言。
但这里有个致命弱点:语言在传达精确空间信息方面非常低效。
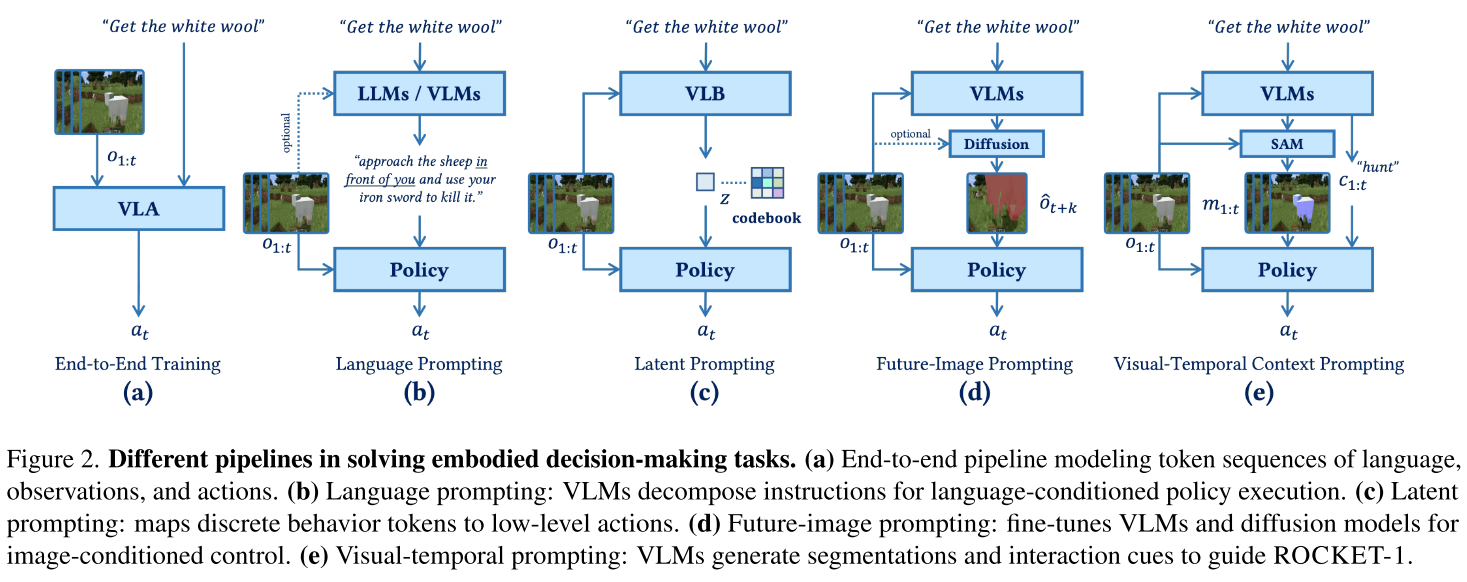
考虑Minecraft中的场景:屏幕上有两只羊,一只在左边栅栏,一只在右边栅栏。如果任务是"猎杀右边栅栏里的羊",用语言描述需要这样说:"走向屏幕右侧的木质栅栏围成的区域,那里有一只羊,靠近它并攻击"。这样的描述不仅冗长,还容易产生歧义。
现有的替代方案也各有问题:
- 未来图像生成:让AI想象完成任务后的画面,但这需要准确的世界模型,容易产生幻觉
- 潜在编码:用抽象向量表示任务,但缺乏可解释性
- 端到端训练:直接让VLM输出动作,但需要海量标注数据
创新:向人类学习的Visual-Temporal Context Prompting
ROCKET-1的核心创新来自对人类行为的观察。
人类拿杯子时不会:
- ❌ 预先想象自己拿着杯子的样子
- ❌ 在脑海里用语言描述杯子的精确位置
人类会:
- ✅ 看着目标杯子
- ✅ 在靠近时持续关注它
- ✅ 如果它被遮挡,依靠记忆回忆位置
受此启发,研究团队提出Visual-Temporal Context Prompting(视觉-时间上下文提示):
传统方法:
高层规划器 → "走向右边栅栏里的羊" → 低层执行器
ROCKET-1方法:
高层规划器 → [羊的分割掩码 + "接近"命令] → ROCKET-1
这种方法有三大优势:
- 精确的空间指示:分割掩码直接标出目标对象
- 时间连续性:保留历史观察中的分割信息
- 自然的表达方式:更接近人类"指向"的直觉
技术实现:ROCKET-1的精巧设计
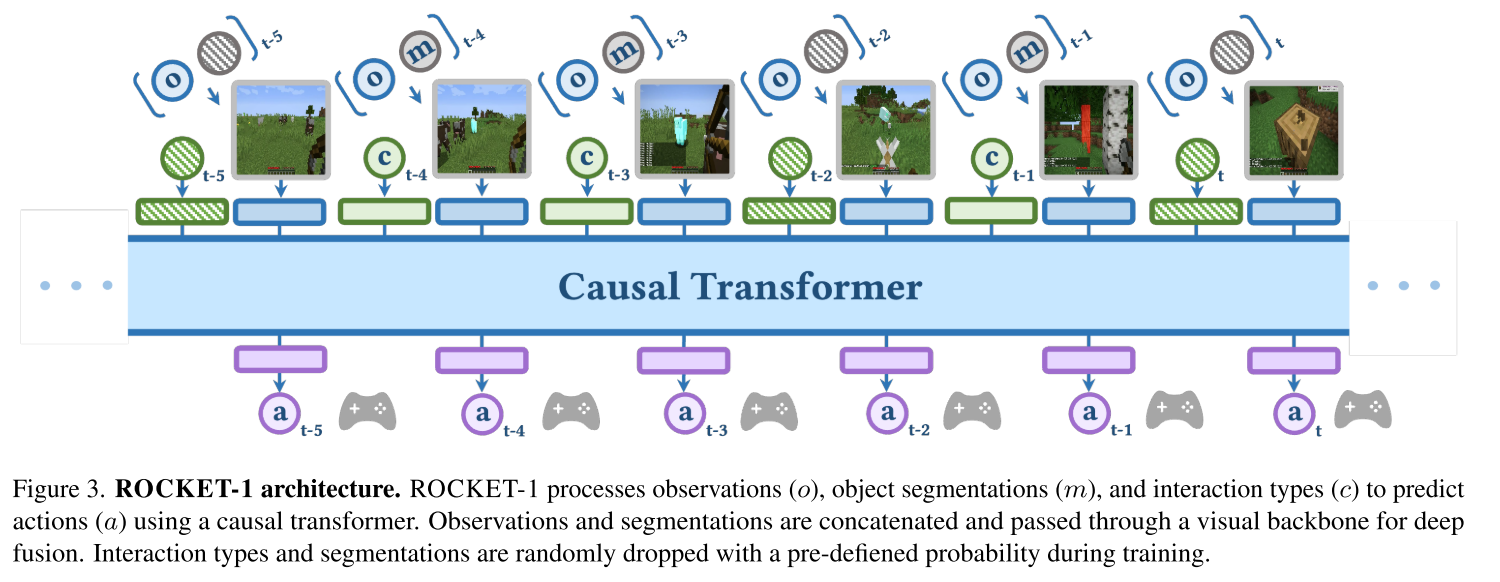
1. 架构设计
ROCKET-1的输入包括三部分:
- 观察序列 (o₁:t):游戏画面
- 分割掩码序列 (m₁:t):高亮显示的交互对象
- 交互类型 (c₁:t):use、approach、mine等
创新的融合策略:
观察(3通道) + 分割掩码(1通道) → 4通道图像
↓
视觉骨干网络(EfficientNet-B0)
↓
注意力池化
↓
TransformerXL(建模时间依赖)
↓
动作预测
2. 训练的智慧:随机Dropout
一个反直觉但关键的设计:训练时随机丢弃75%的分割掩码。
为什么?因为要让ROCKET-1学会"记忆"。当前帧的掩码被丢弃时,模型必须从历史观察中推断目标位置,这迫使它发展出强大的时间推理能力。
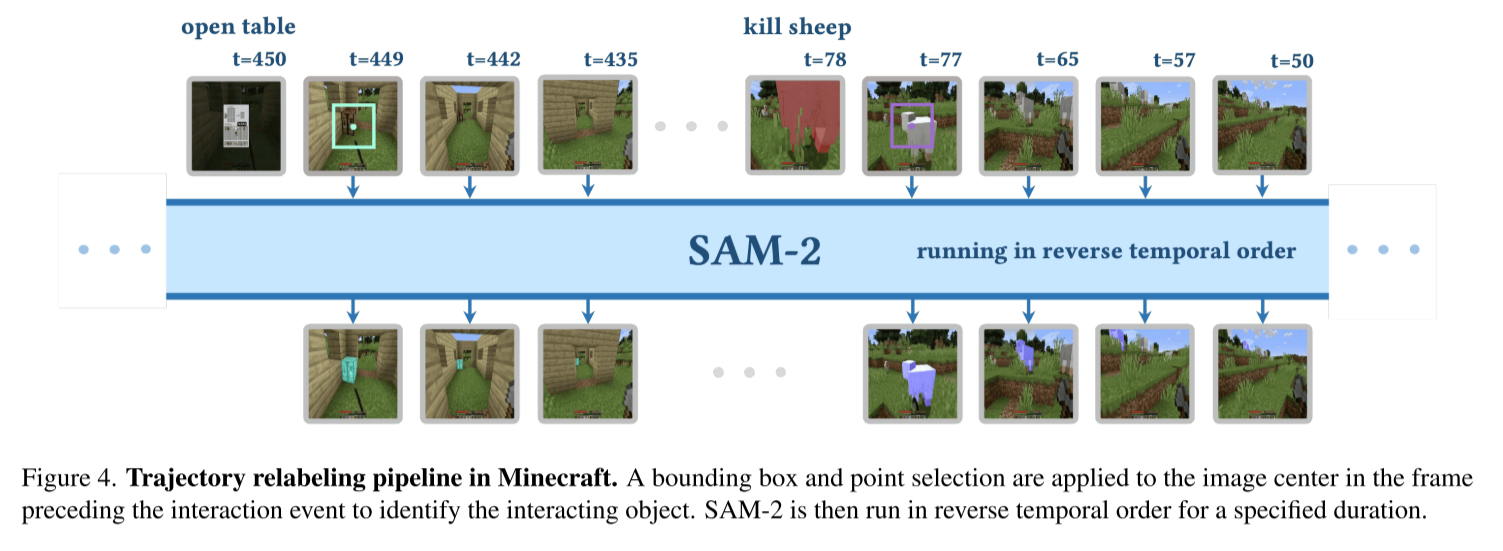
3. 数据标注:Backward Trajectory Relabeling
如何为百万帧游戏数据自动生成分割标注?团队设计了巧妙的反向标注流程:
- 识别交互事件:检测"杀死实体"、"挖掘方块"等事件
- 反向跟踪:
- 在交互发生的帧t,用固定位置(画面中心)的边界框提示SAM-2
- SAM-2向前跟踪,自动为t-1, t-2, ..., t-k帧生成分割
- 处理导航:如果玩家移动超过阈值,标记为"接近"动作
这个方法完全自动化,无需人工标注,成功处理了OpenAI的1.6B帧Minecraft数据。
4. 分层系统集成
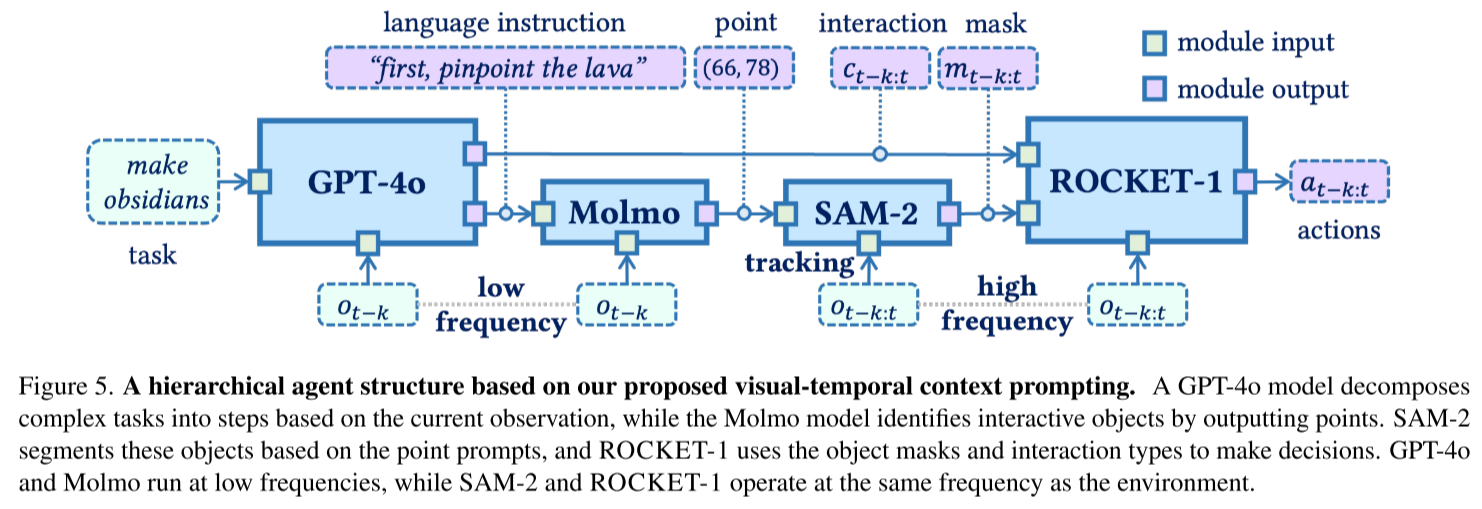
完整的ROCKET-1系统是一个精密编排的四件套:
任务:"在Minecraft中获取黑曜石"
GPT-4o(低频):
"首先,我需要找到水源装满桶。然后定位岩浆池,倒水形成黑曜石。
最后切换到钻石镐开采。"
↓
Molmo 72B(低频):
识别"水源"在观察中的位置 → 输出(x, y)坐标
↓
SAM-2(高频):
根据坐标生成分割掩码 → 实时跟踪对象(即使被遮挡)
↓
ROCKET-1(高频):
根据分割和交互类型 → 输出鼠标/键盘动作
这种分工充分发挥了各模型的优势:
- GPT-4o:强大的推理和知识
- Molmo:精确的视觉定位
- SAM-2:鲁棒的对象跟踪
- ROCKET-1:高效的低层控制
实验结果:突破性的性能提升
Minecraft Interaction Benchmark

研究团队构建了包含12个任务的基准测试,强调空间定位能力。任务设计非常巧妙,例如:
- "猎杀右边栅栏里的羊"(如果杀了左边的就算失败)
- "在钻石块上放置橡木门"(门必须与钻石块相邻)
结果令人震撼:
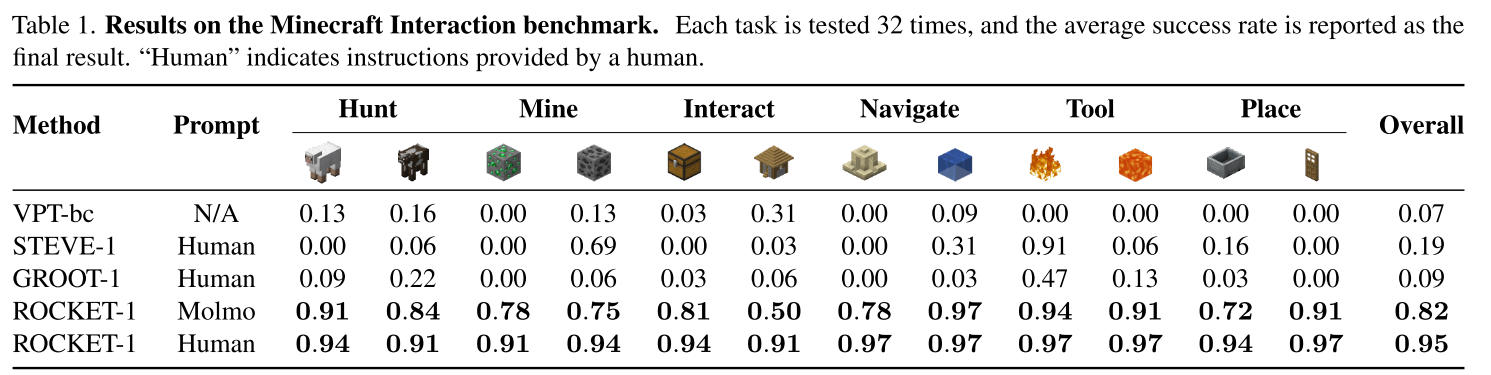
| 方法 | 平均成功率 |
|---|---|
| VPT-bc | 7% |
| STEVE-1 | 19% |
| GROOT-1 | 9% |
| ROCKET-1 | 82% |
76%的绝对提升意味着什么?这是从"基本不能完成"到"大部分时候都能成功"的质变。
更令人兴奋的是零样本泛化能力。在"将橡木门放在钻石块上"任务中(训练集中从未出现),ROCKET-1达到91%成功率,而所有基线方法完全失败。
长视野任务:攻克前人未解之题
在复杂的长视野任务中,ROCKET-1展现了压倒性优势。最具说服力的是两个"不可能任务":

获取黑曜石(需要:找水→装桶→找岩浆→倒水→切换钻石镐→开采)
- 所有基线方法:0%
- ROCKET-1:50%
制作粉色羊毛(需要:找羊→剪羊毛→找花→制作染料→染色)
- 所有基线方法:0%
- ROCKET-1:70%
这些任务需要多步规划、空间推理和精确交互的完美结合,ROCKET-1首次让AI代理在这些任务上取得成功。
消融研究的洞察
两个关键发现:
-
融合位置matters:在视觉骨干(而非Transformer)中融合条件信息提升了13个百分点(Hunt任务:0.91 vs 0.72)。原因是这允许视觉网络跨不同交互类型共享知识。
-
SAM-2的价值:即使高层推理器每30帧才提供一次提示(相比每3帧),使用SAM-2仍能维持高性能。这大幅降低了计算成本。
技术启示与未来展望
ROCKET-1的成功给我们带来几点重要启示:
1. 多模态不等于端到端
不需要把所有模态塞进一个大模型。巧妙的模块化设计+合适的通信协议,可以让专用模型发挥各自优势。
2. 从人类直觉中寻找答案
"用分割指示目标"这个想法很简单,但很有效。它来自对人类行为的观察:我们用手指、眼神来指示,而不是详细描述。
3. 时间建模的重要性
通过历史观察理解任务、处理遮挡,这些能力对开放世界交互至关重要。随机Dropout训练策略巧妙地强化了这一点。
4. 自动化数据标注的创新空间
Backward Trajectory Relabeling展示了如何利用强大的预训练模型(SAM-2)和领域知识(物体常居中)来自动化标注。
局限与未来方向
论文也诚实地指出当前的局限:
- 环境特定性:目前主要在Minecraft中验证,泛化到真实机器人还需研究
- 交互类型有限:预定义了6种交互类型,可能无法覆盖所有场景
- 计算成本:虽然比端到端VLM高效,但同时运行4个模型仍有开销
未来可能的方向:
- 扩展到真实世界机器人操作
- 开发更通用的交互类型表示
- 探索轻量级的部署方案
- 研究多对象并行交互
结语:迈向真正的开放世界AI
ROCKET-1不仅仅是性能的提升,更是范式的转变。它告诉我们:
- AI不必完全模仿人类的思维方式
- 但可以借鉴人类的交互方式
- 模块化设计+合适的"语言"=强大的能力
当AI代理能够在Minecraft这样的开放世界中准确地"看"和"指"时,我们离真正的通用AI又近了一步。这个"指向"的能力——通过visual-temporal context prompting实现——可能是打开具身AI潜力的一把钥匙。
正如论文所展示的,有时候最好的沟通方式不是说得更多,而是指得更准。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)