NVIDIA Tesla P100的AI推理速度测试
25年你可能错过了1000元的MI50 32G,那么现在26年380元的P100 16G你一定不要再错过了。
P100最早在23年底900多元买过一次,后来涨价就出了。那会儿主要是玩SD的文生图,由于没有视频输出,很多人拿回去玩不来。如今又一次降价了,380买不到吃亏,橙色居然还不错。
The Tesla P100 PCIe 16 GB was an enthusiast-class professional graphics card by NVIDIA, launched on June 20th, 2016. Built on the 16 nm process, and based on the GP100 graphics processor, in its GP100-893-A1 variant, the card supports DirectX 12. The GP100 graphics processor is a large chip with a die area of 610 mm² and 15,300 million transistors. It features 3584 shading units, 224 texture mapping units, and 96 ROPs. NVIDIA has paired 16 GB HBM2 memory with the Tesla P100 PCIe 16 GB, which are connected using a 4096-bit memory interface. The GPU is operating at a frequency of 1190 MHz, which can be boosted up to 1329 MHz, memory is running at 715 MHz.
Being a dual-slot card, the NVIDIA Tesla P100 PCIe 16 GB draws power from 1x 8-pin power connector, with power draw rated at 250 W maximum. This device has no display connectivity, as it is not designed to have monitors connected to it. Tesla P100 PCIe 16 GB is connected to the rest of the system using a PCI-Express 3.0 x16 interface. The card measures 267 mm in length, and features a dual-slot cooling solution. Its price at launch was 5699 US Dollars.
Theoretical Performance
Pixel Rate 127.6 GPixel/s
Texture Rate 297.7 GTexel/s
FP16 (half) 19.05 TFLOPS (2:1)
FP32 (float) 9.526 TFLOPS
FP64 (double) 4.763 TFLOPS (1:2)
主要的参考指标是 FP16 (half) 19.05 TFLOPS (2:1) 还不错。
现在本地部署AI更多的是玩LLM,加上Qwen3.5超强的开源小模型,16G也能玩得很好。
今天选的是unsloth/Qwen3.5-9B-GGUF:Qwen3.5-9B-UD-Q4_K_XL.gguf
首先需要编译最新版的llama.cpp, 当前版本b8475
如果你是Ubuntu24.04, 执行以下命令安装驱动和开发套件
sudo apt install nvidia-cuda-toolkit nvidia-cuda-dev nvidia-driver-580-server安装完成后运行 nvidia-smi,如下打印成功即可
Mon Mar 23 09:09:44 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:04:00.0 Off | 0 |
| N/A 40C P0 34W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+解压llama.cpp源码,进入源码目录后执行
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release编译完成后可进入build/bin 目录,看到有编译出的文件,先测试下速度
ggml_cuda_init: found 1 CUDA devices (Total VRAM: 16269 MiB):
Device 0: Tesla P100-PCIE-16GB, compute capability 6.0, VMM: yes, VRAM: 16269 MiB
| model | size | params | backend | ngl | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | --------------: | -------------------: |
| qwen35 9B Q4_K - Medium | 5.55 GiB | 8.95 B | CUDA | 99 | pp512 | 596.59 ± 2.77 |
| qwen35 9B Q4_K - Medium | 5.55 GiB | 8.95 B | CUDA | 99 | tg128 | 33.24 ± 0.01 |
build: unknown (0)运行服务, 注意:由于算力有限,关闭了思考模式。并启用128k的上下文,可以做一些中小型的开发任务了。
llama-server -m Qwen3.5-9B-UD-Q4_K_XL.gguf -a Qwen3.5-9B --ctx-size 128000 --temp 0.6 --top-p 0.95 --top-k 20 --min-p 0.00 --chat-template-kwargs '{"enable_thinking":false}' --host 0.0.0.0 --port 1234 --jinja实际使用OpenCode进行AI coding任务,在上下文达到43k时,读取速度55.61t /s , 生成速度22.61 t/s , 还行可以接受。
slot launch_slot_: id 2 | task 4332 | processing task, is_child = 0
slot update_slots: id 2 | task 4332 | new prompt, n_ctx_slot = 128000, n_keep = 0, task.n_tokens = 43588
slot update_slots: id 2 | task 4332 | n_tokens = 43566, memory_seq_rm [43566, end)
slot update_slots: id 2 | task 4332 | prompt processing progress, n_tokens = 43584, batch.n_tokens = 18, progress = 0.999908
slot update_slots: id 2 | task 4332 | created context checkpoint 25 of 32 (pos_min = 43565, pos_max = 43565, n_tokens = 43566, size = 50.251 MiB)
slot update_slots: id 2 | task 4332 | n_tokens = 43584, memory_seq_rm [43584, end)
slot init_sampler: id 2 | task 4332 | init sampler, took 5.78 ms, tokens: text = 43588, total = 43588
slot update_slots: id 2 | task 4332 | prompt processing done, n_tokens = 43588, batch.n_tokens = 4
srv log_server_r: done request: POST /v1/chat/completions 192.168.0.5 200
slot print_timing: id 2 | task 4332 |
prompt eval time = 395.59 ms / 22 tokens ( 17.98 ms per token, 55.61 tokens per second)
eval time = 2875.47 ms / 65 tokens ( 44.24 ms per token, 22.61 tokens per second)
total time = 3271.06 ms / 87 tokens
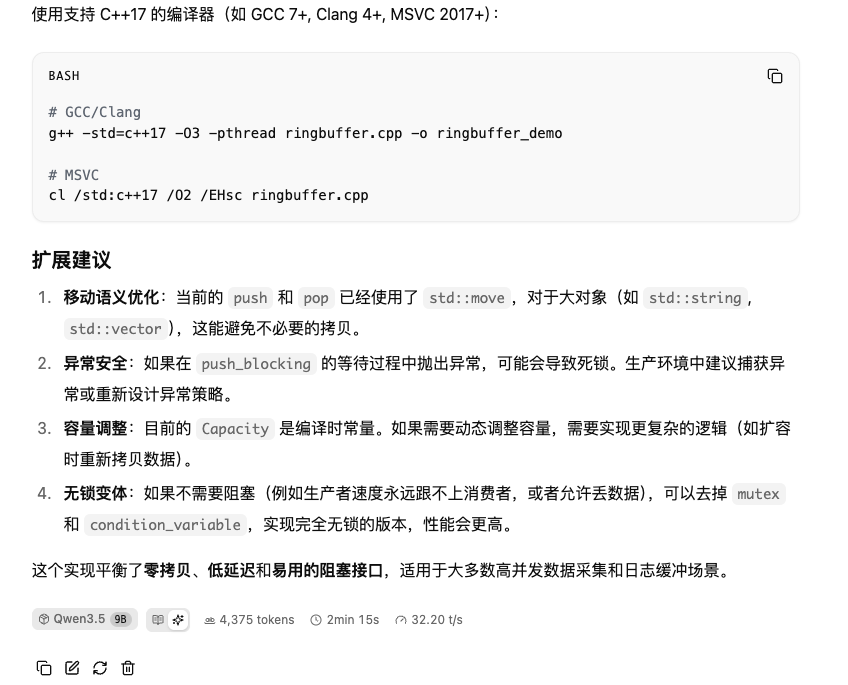
slot release: id 2 | task 4332 | stop processing: n_tokens = 43652, truncated = 0使用WebUI 对话式AI生成,要求写一个c++17标准的ringbuffer,高性能,线程安全,共生成4375个token,速度32t/s。生成内容中有代码,有注释和细节解析。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)