城市内涝模拟:用AI识别城市积水的深度学习解决方案
暴雨过后,城市道路常因排水不畅形成积水,轻则影响通行,重则危及安全。传统依赖人工巡查或群众上报的方式,存在滞后性与覆盖盲区。 城市内涝模拟数据采集过程中借助深度学习技术,构建一个能从监控视频中自动识别积水区域的AI系统,已成为提升城市韧性的重要路径。
01内涝模型定制开发之 为什么必须构建专用模型?
通用目标检测模型(如YOLOv8在COCO上预训练 的数据集 )无法识别“积水”,原因有二:
- 语义缺失:COCO等数据集不含“Water”或“Flood” 等积水 类别;
- 形态多变:积水可呈深黑、镜面反光、浑浊泥色,甚至仅是薄层水膜,缺乏固定轮廓与纹理。
因此,必须构建 专用数据 + 专用模型 ,让AI学会“什么是积水”。
02内涝模型定制开发之 数据准备:基于Flood-IMG数据集的清洗与组织
系统采用公开数据集 Flood-IMG (来源:Roboflow 影像数据平台 ),包含1976张真实场景图像,其中“Water”类别标注1842个实例。数据涵盖白天/夜间、晴天/雨天、城市街道/乡村小路等多种场景。
数据预处理流程:

图1:数据集样本展示
- 格式统一:将原始标注转换为YOLO格式(归一化中心坐标 + 宽高);
- 划分策略:按7:2:1比例自动切分训练集(1383张)、验证集(395张)、测试集(198张);
- 类别映射:确保标签对应类别名 Water ,并在训练脚本中显式指定。
03
内涝模型定制开发之 模型训练:基于YOLO架构的高效微调
选用 Ultralytics YOLO 系列作为基础框架,因其支持检测与实例分割双任务,且训练/推理接口高度封装。 既能准确找出图中有哪些物体(检测),又能精细勾勒出每个物体的轮廓(实例分割),而且用起来非常方便,几行代码就能完成训练和预测。
▶ 训练配置详解
骨干网络优先加载 最新 模型版本 yolo26n,若该权重不可用,则回退至 yolov8 n 。输入图像统一调整为 640×640 分辨率,在保持原始宽高比的前提下,通过边缘填充将其转换为正方形。为提升 城市内涝模拟 模型的泛化能力,训练过程中采用多种数据增强策略:包括 Mosaic 增强(将四张图像拼接为一张进行训练)、HSV 色彩空间扰动(色相 H 偏移 ±0.015,饱和度 S 偏移 ±0.7,明度 V 偏移 ±0.4)、随机水平翻转(概率设为 0.5),以及自适应锚框计算(autoanchor)以更好 地匹配数据集中的目标尺度分布。
优化方面,设置批大小( batch size)为 32 , 初始学习率设为 0.01,并采用余弦退火(cosine decay)调度策略——即让学习率从初始值按照余弦函数曲线平滑下降至接近零,使 城市内涝模拟 模型在训练后期能够更稳定地收敛。同时配置动量为 0.937,权重衰减系数为 0.0005。训练控制上,最大训练轮次(epochs)设为 100,早停耐心值(patience)设为 50,即当验证集上的 m AP50 指标连续 50 轮未见提升时,自动终止训练以防止过拟合。此外,全程启 用 AMP(自动混合精度训练),在不损失精度的前提下显著加速训练过程并降低显存占用。
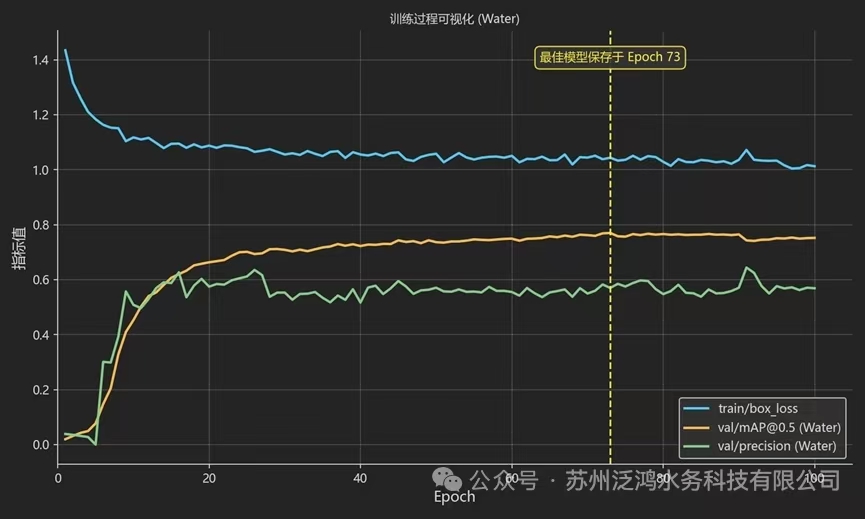
图2:训练过程
▶ 训练结果
最终 城市内涝模拟 模型在验证集上表现如下:
- mAP50 ( 在IoU阈值=0.5时的平均精度均值 ) : 0.763
- mAP50 - 95 ( 在IoU阈值=0. 5-0.95 范围内 的平均精度均值 ) : 0 . 627
- Recall: 0.8 1
城市内涝模拟 模型权重自动保存为 pt文件 ,可用于后续推理。
04
内涝模型定制开发之 视频流推理:从单帧检测到连续监控
训练完成的 城市内涝模拟 模型被集成进高性能推理引擎,支持对本地视频或RTSP流进行实时处理。
▶ 推理流程详解
推理流程如下:首先进行视频解码,使用 OpenCV 逐帧读取输入视频,默认每隔 3 帧处理一帧以平衡效率与实时性。随后对选中的每一帧执行图像预处理,包括将图像按原始宽高比缩放至 640×640,并在边缘填充灰色像素以构成正方形;接着将像素值归一化到 [0, 1] 范围,并转换为 PyTorch 张量(Tensor)格式,以便送入模型。
预处理后的图像被送入 GPU 进行 城市内涝模拟 模型前向推理,模型输出包含原始预测信息,如边界框坐标(xywh)、置信度(conf)、类别标签(cls)以及实例分割掩码(masks)。接下来进入后处理阶段:首先严格过滤掉所有非 “Water” 类别的预测结果(仅保留标签名完全匹配的项),然后应用非极大值抑制(NMS)以去除重叠冗余的检测框,默认 IoU 阈值设为 0.45,最后仅保留置信度大于 0.5 的有效检测结果。
最终进行可视化与输出:在原始分辨率的图像上绘制绿色边界框,并添加文本标注,格式为 “Water: {conf:.2f}”(保留两位小数);若启用了实例分割功能,则额外叠加半透明的蓝色掩码以突出水体区域。处理完成的帧可被编码为带标注的视频文件保存,或通过 Web 服务以实时流形式输出,供前端展示或进一步分析使用。

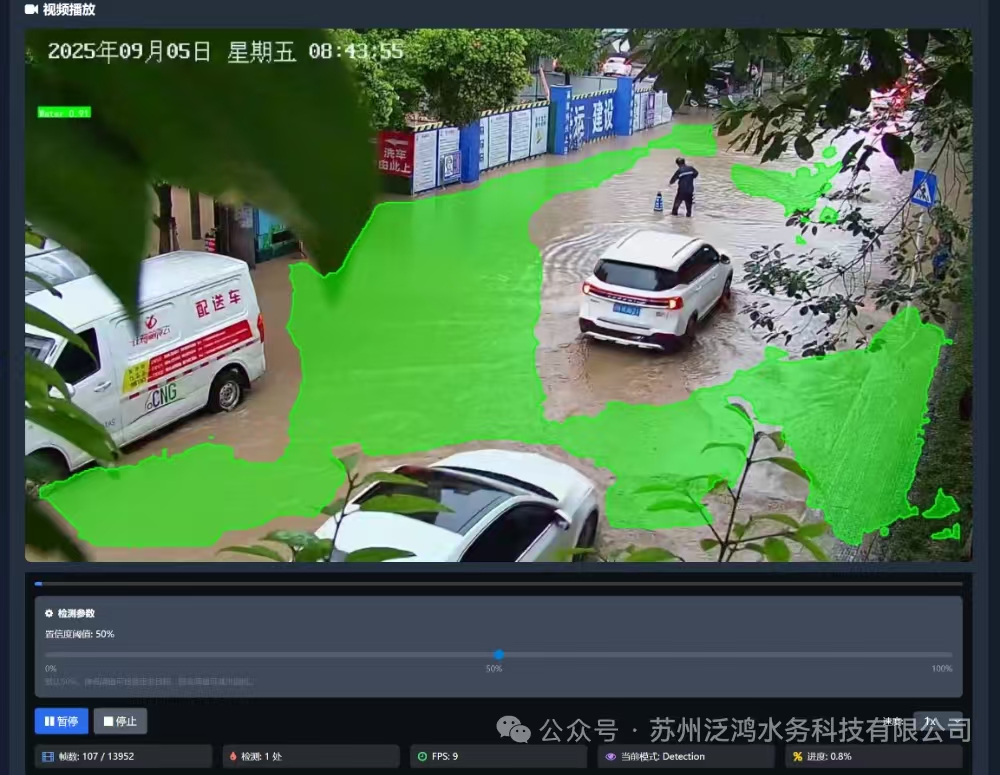

图3: 积水识别效果
▶ 系统支持动态调节参数
- conf-thres 0.6 :提高置信度阈值,减少误报
- skip-frames 5 :跳帧处理,提升吞吐量
- show-mask :开启分割掩码可视化
05内涝模型定制开发之 局限与未来方向
尽管系统在多数场景表现良好,仍存在挑战:
- 内涝模型定制开发 过程中 极浅 的积水 因缺乏视觉对比度难以识别;
- 强烈阳光下玻璃幕墙或车窗反光易被误判;
- 完全被遮挡的积水(如大型车辆下方)无法检测。
未来可通过以下方式优化:
- 引入合成数据增强(如用Blender生成可控积水场景);
- 融合多帧时序信息(利用积水的动态特性);
接入多视角摄像头,通过几何一致性校验提升鲁棒性。
06结语
内涝模型定制开发 积水识别不是炫技,而是城市安全基础设施的重要组成部分。当AI能够从成千上万路摄像头中自动捕捉到那一片危险的反光水面时,它便不再仅仅是一套算法,而成为默默守护公共安全的“眼睛”。通过端到端的深度学习实践,证明了:只要数据精准、训练充分、部署得当,AI完全有能力应对这类“非标准却高价值”的现实挑战,真正将技术转化为民生保障的力量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)