Prompt 写了 2000 字还是翻车?Strands Agents 的 Steering Hook 让 AI Agent 准确率从 82% 跳到 100%
你以为的 AI Agent 开发:写好 Prompt,坐等结果。
实际的 AI Agent 开发:加了 500 字规则,Agent 还是跳步骤;加到 1000 字,它开始忘记发邮件;加到 2000 字,token 费用让你怀疑人生。
一、引子:我也曾是 Prompt 加长党
我记得第一次认真搭 AI Agent 的时候,充满信心地写下了一段 System Prompt:
你是一个图书馆管理助手。在续借书籍之前,必须先检查书的状态。续借完成后,必须发送确认邮件给用户……
跑了十次,七次正常,三次翻车——有时跳过了状态检查,有时忘了发邮件。
于是我加更多规则。规则越加越长,Agent 的表现时好时坏,像一个靠心情上班的实习生。
这不是我一个人的故事。这是 2026 年大多数 AI Agent 开发者的日常。
二、Prompting 跑步机:越跑越累,原地踏步
我把这个现象叫做 “Prompting 跑步机”——你在不断地跑,消耗大量精力,但实际上没有前进。
为什么 Prompt 工程有天花板?
大语言模型的本质是概率采样。无论你的 Prompt 写得多精确,它都是在"建议"模型去做某件事,而不是"命令"。
这里有几个根本性问题:
1. 注意力衰减:Prompt 越长,模型对后半段规则的遵守率越低。你加了 20 条规则,模型到第 18 条可能已经"走神"了。
2. 规则冲突:随着规则增多,它们之间开始相互矛盾。模型会按照自己的"理解"来取舍,而不是按你的意图。
3. 上下文污染:在多轮对话中,用户的输入会逐渐"覆盖"你的 Prompt 效果。用户说"快点,不用确认了",Agent 可能真的就跳过确认步骤了。
4. 无法测试:你怎么单元测试一段自然语言 Prompt?几乎不可能写出确定性的测试用例。
结论:Prompt 工程能把你带到 80%,但那最后的 20% 是它够不到的地方。
根本原因在于:你用自然语言写的规则,在模型眼里和用户说的话是同等地位的"文本"。可靠的 Agent 行为,需要代码级别的保障,而不仅仅是语言级别的祈祷。
下面这组实验数据,会让你对这句话有具体感受。
三、四种方案横向对比:数据说话
AWS 在开源 Strands Agents SDK 时,做了一个非常扎实的评估实验:设计了一个图书馆续借场景,用 600 次自动化测试对比了五种行为控制方案。
实验场景包含多种混合请求(查询 + 续借、单纯续借、无效操作等),每次测试都验证 Agent 是否完整执行了正确的步骤序列。
结果如下:
| 方案 | 通过率 | 平均输入Token | 平均输出Token | 特点 |
|---|---|---|---|---|
| 无指令(基线) | 15.7% | 1,870 | 401 | 什么都不说,AI 自由发挥 |
| 简单 Prompt 指令 | 82.5% | 2,329 | 430 | 最常见方案,有明显上限 |
| SOP 文档 | 99.8% | 9,879 | 459 | 准确率高但 token 成本爆炸 |
| Steering Hooks | 100.0% | 3,346 | 598 | 最优平衡点 |
| Graph 工作流 | 80.8% | 3,116 | 1,125 | 固定流程好用,混合场景崩溃 |
几个值得关注的数字:
-
SOP 文档能达到 99.8%,但平均输入 Token 高达 9,879——是 Steering Hooks(3,346)的近 3 倍。在高并发场景下,这个差距会直接体现在账单上。
-
Graph 工作流看起来不错(3,116 Token),但通过率只有 80.8%,比简单 Prompt 还低一点点。原因在于它太"死板"——遇到混合请求就不知道怎么办了。
-
Steering Hooks 以适中的 Token 消耗,实现了 100% 的通过率。这个数字不是统计意义上的"约等于100%",是字面意义上的 600/600。
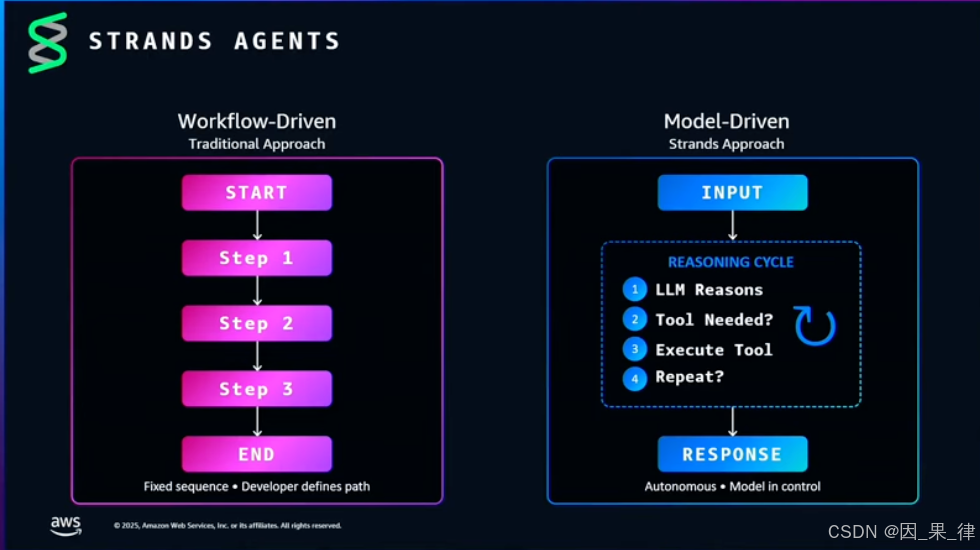
四、Steering 机制深度解析:它到底是什么魔法?
Steering Hooks 的核心思想其实非常朴素:不在事前把所有规则塞进 Prompt,而是在运行时"即时介入"。
就像一个有经验的老师傅带徒弟——不是在出发前把所有情况都预讲一遍,而是在关键节点上实时提醒:“等等,你得先检查书的状态。”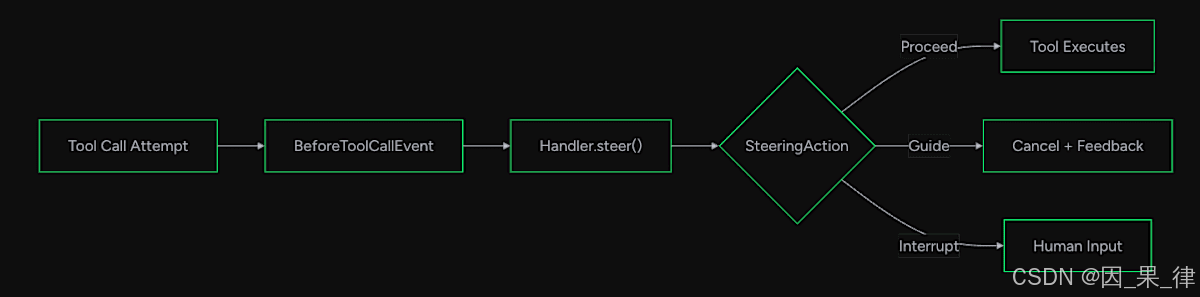
4.1 两个拦截点
Strands Agents SDK 提供了两个核心钩子:
-
steer_before_tool:在 Agent 调用工具之前触发。此时你可以检查"即将发生什么",如果条件不满足,可以拦截并给出指导(Guide),或者放行(Proceed)。 -
steer_after_model:在 模型生成响应之后触发。此时可以检查模型的输出是否符合预期,比如语气是否合适、内容是否完整。
这两个钩子覆盖了 Agent 推理循环中最关键的两个时机。
4.2 初始化:把 Handler 装进 Plugins
# 创建 Agent 时,将多个 handler 作为 plugins 传入
# 每个 handler 负责一个关注点,像插件一样可拔插
agent = Agent(
tools=tools,
system_prompt=system_prompt, # system_prompt 保持简洁
plugins=[
renewal_workflow_handler, # 控制续借流程顺序
confirmation_workflow_handler, # 控制确认邮件流程
confirmation_tone_handler, # 控制确认消息的语气
model_tone_handler, # 控制模型整体回复风格
],
)
注意:每个 handler 只负责一件事。这是单一职责原则在 Agent 设计中的具体体现。你可以自由组合、单独测试每一个 handler。
4.3 核心 Handler:工作流验证(原文完整版)
下面是原文中 steer_before_tool 的完整实现,用于确保续借流程的步骤顺序正确、数据来源可信:
async def steer_before_tool(
self, *, agent, tool_use, **kwargs
):
# Only validate renewal attempts
if tool_use.get("name") != "renew_book":
return Proceed(reason="Not a renewal tool call")
# Get the history of tool calls from the ledger
ctx = self.steering_context.data.get()
ledger = ctx.get("ledger", {})
tool_calls = ledger.get("tool_calls", [])
# Was book status verified first?
status_checked = any(
c["tool_name"] == "get_book_status"
and c["status"] == "success"
for c in tool_calls
)
if not status_checked:
return Guide(
reason="Check book status before renewing."
" Use get_book_status first, then retry."
)
# Is the book recalled?
for c in tool_calls:
if (
c["tool_name"] == "get_book_status"
and c["status"] == "success"
):
result = json.loads(c["result"][0]["text"])
if result.get("status") == "RECALLED":
return Guide(
reason="Cannot renew a RECALLED book."
)
# Does the library card match the user's actual card?
renewal_card = tool_use.get("input", {}).get(
"library_card_number"
)
for c in tool_calls:
if (
c["tool_name"] == "get_user_info"
and c["status"] == "success"
):
result = json.loads(c["result"][0]["text"])
user_card = result["library_card_number"]
if renewal_card != user_card:
return Guide(
reason=f"Wrong library card."
f" Use {user_card} instead."
)
return Proceed(reason="Workflow validation passed")
这段代码是纯 Python,完全确定性,零 LLM 调用。它做了三重验证:
- 步骤顺序:续借前必须先调用
get_book_status - 业务规则:被召回(RECALLED)的书不能续借
- 数据真实性:图书馆卡号必须来自
get_user_info,不能用用户自报的值(防幻觉、防注入)
4.4 Handler:用 LLM 检查语气
对于"语气是否积极"这类难以用代码规则表达的需求,Steering 支持用另一个 LLM 作为裁判:
async def steer_after_model(
self, *, agent, message, stop_reason, **kwargs
):
if stop_reason != "end_turn":
return Proceed(reason="Not a final response")
text = " ".join(
block.get("text", "")
for block in message.get("content", [])
)
# Run an LLM judge agent to evaluate tone
steering_agent = Agent(
system_prompt=TONE_PROMPT,
model=steering_model,
)
result = steering_agent(
f"Evaluate this message:\n\n{text}",
structured_output_model=ToneDecision,
)
if result.structured_output.decision == "guide":
return Guide(reason=result.structured_output.reason)
return Proceed(reason="Tone check passed")
这个 handler 在模型生成响应之后触发,用一个独立的小 LLM 来评估语气。如果语气不符合要求,返回 Guide 让主模型重新生成。确定性规则 + LLM 裁判,两种策略组合使用。
几个关键设计亮点:
-
Ledger 机制:SDK 自动记录每次工具调用的名称、输入、输出和状态,你不需要手动维护状态机。完整的调用历史就在
ledger["tool_calls"]里。 -
三种返回值:
Proceed(放行)、Guide(软纠偏,模型重新规划)、还有Interrupt(硬中断)。Guide是最常用的——它不报错,只是给模型一个方向。 -
可组合性:多个 handler 作为
plugins串联执行,各司其职,可以独立单元测试。
五、失败案例解剖:简单 Prompt 为什么不够用?
回到那个图书馆实验,让我们看看简单 Prompt 指令(82.5% 通过率)是如何失败的:
失败原因分布:
- 43% 的失败:Agent 跳过了状态检查,直接尝试续借。原因是用户的请求很直接(“帮我续借《深入理解计算机系统》”),模型判断"任务明确,无需额外检查"。
- 40% 的失败:Agent 完成续借后忘记发确认邮件。原因是模型认为"主要任务完成了",后续步骤在紧凑的推理中被省略。
这两个失败模式揭示了 Prompt 控制的本质局限:模型是在用"理解"来执行规则,而不是在"强制执行"规则。
当用户的表达与规则之间存在隐性冲突时,模型往往选择满足用户的显性需求,而忽略规则中的隐性要求。
更深层的原因是:Prompt 中的规则在模型看来,和用户说的话是同等地位的"文本"。当用户强烈表达了某个意图,模型会在"遵守规则"和"满足用户"之间做权衡——而这个权衡的结果是概率性的,不可预测的。
你可能今天跑出 90%,明天换个用户措辞就跌到 70%。这种不稳定性,在生产环境中是致命的。
Graph 工作流的失败则更有意思:在定义好的单一流程中,它表现不错(96.6%);但当用户发出"查询 + 续借"的混合请求时,Graph 直接崩了——因为它没有处理这种组合的节点路径。固定图结构的代价,是对多样性的零容忍。
这个场景很典型:用户说"帮我查一下《深入理解计算机系统》还能借多久,顺便帮我续一下"。这是一个完全合理的自然语言请求,但预定义的工作流图里没有"先查后续"这条路径,Agent 就懵了。
Steering Hooks 因为是"运行时介入"而非"预定义流程",可以优雅地处理各种混合场景。无论用户的请求多么随机,只要满足了业务规则,就放行;不满足,就纠偏。这才是真正的灵活与可靠并存。
六、决策指南:什么时候用什么方案?
不是所有项目都需要 Steering Hooks。这里给一个清晰的选择框架:
用简单 Prompt 指令,当:
- ✅ 场景简单,步骤少(1-3步)
- ✅ 对准确率要求不高(85% 以上够用)
- ✅ 快速原型,还在验证方向
- ❌ 不适合:生产环境、有法务/合规要求、步骤有严格顺序依赖
用 SOP 文档,当:
- ✅ 流程非常复杂,需要详细的上下文说明
- ✅ Token 成本不敏感(内部工具、低频场景)
- ✅ 团队有大量现成的 SOP 文档可复用
- ❌ 不适合:高并发场景、成本敏感型应用
用 Graph 工作流,当:
- ✅ 流程完全固定,没有分支和意外情况
- ✅ 需要可视化流程图(给非技术人员展示)
- ✅ 每个节点都有明确的输入输出定义
- ❌ 不适合:需要处理多种混合请求、流程动态变化的场景
用 Steering Hooks,当:
- ✅ 准确率要求高(95%+),生产环境
- ✅ 流程有步骤依赖(A 必须在 B 之前)
- ✅ 需要可测试、可维护的控制逻辑
- ✅ 场景多样,包含混合请求
- ✅ Token 成本需要控制(优于 SOP)
- ❌ 不适合:超简单场景(杀鸡用牛刀)
一句话原则:如果你的 Agent 要上生产,并且有任何步骤顺序要求,请认真考虑 Steering Hooks。
七、总结:Steering 不是银弹,但它是目前的最优解
让我们最后做一次清醒的评估。
Steering Hooks 确实解决了 Prompt 工程的核心痛点:它将行为控制从"语言层"移到了"代码层",从"概率性建议"变成了"确定性拦截"。600 次测试全部通过,不是运气,是机制。
但它也不是万能的:
- 需要开发者理解 Agent 的推理循环(学习曲线存在)
- Handler 需要维护,随业务变化需要更新
- 对于简单场景,反而是过度设计
我的建议:
-
新项目先用简单 Prompt,快速验证方向。不要一上来就过度设计,简单 Prompt 能带你走到 80%,这个阶段够用了。
-
出现"规律性出错"就引入 Steering。当你发现"每次在某个步骤 Agent 都会犯同样的错误",这就是 Steering Hooks 的用武之地。把那个规律,从 Prompt 文字变成确定性的 Python 判断。
-
每个 Handler 必须有单元测试。这是 Steering Hooks 相比 Prompt 最大的工程优势。你可以 mock 一个
tool_use,验证 handler 的返回值,完全不需要跑真实的 LLM。 -
保持 Handler 细粒度。不要把所有逻辑塞进一个 handler,就像你不会把所有业务逻辑塞进
main()函数一样。一个 handler,一个关注点。 -
监控 Ledger 数据。Strands SDK 的 Ledger 机制记录了每次工具调用的详细信息,这是排查 Agent 行为问题的金矿。生产环境一定要把 Ledger 数据持久化。
AI Agent 开发正在从"Prompt 魔法"走向"工程化"。但这条路的难点不是技术——技术已经有了——而是承认"写更多 Prompt"已经不是正确答案这件事。
很多团队还在 Prompting 跑步机上跑着,只是因为没人愿意停下来说:我们在用错误的工具解决问题。
有意思的是,AWS 选择把这个机制做成开源 SDK,而不是封装成黑盒服务。这背后的信号是:Agent 可靠性不是一个"托管就能解决"的问题,它需要开发者深度介入。这既是挑战,也是护城河。
你现在的 Agent,是在第几步出错的?
把那个规律性的"坑",从 Prompt 文字变成一个 steer_before_tool。可能只需要 10 行代码,你就能从 82% 跳到 100%。
欢迎在评论区说说你 Agent 最常翻车的步骤——说不定你的案例可以写成下一篇。
参考资源
- Strands Agents SDK 官网:https://strandsagents.com
- GitHub 仓库:https://github.com/strands-agents/sdk-python
- Steering Hooks 文档:https://strandsagents.com/latest/documentation/docs/user-guide/concepts/plugins/steering/
本文基于 AWS Strands Agents SDK 官方评估数据撰写,实验数据来自 600 次自动化测试。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)