软考中级:第6章 数据工程 学习笔记
一、章节核心内容摘要
根据最新考纲及占分分析,本章节 “第6章:数据工程” 在2024下半年至2025上半年(新大纲稳定期)的考查占分为 3~5 分。考查形式包含综合知识+案例分析。趋势分析指出,本章是重点章节,数据治理、数据模型等是热门考点。
【核心内容摘要】本章详细阐述了数据工程的全生命周期管理与技术要求。主要内容涵盖:数据采集和预处理(传感器/日志/网络采集,缺失/异常/不一致/重复数据处理);数据存储及管理(文件/块/对象存储,DAS/LAN/LAN-FREE/SERVER-FREE备份结构,完全/差分/增量备份策略,容灾指标RPO/RTO);数据治理和建模(元数据体系,数据标准化,数据质量评估,概念/逻辑/物理模型);数据仓库和数据资产(数据仓库架构,OLAP,数据资源化与资产化,数据资源编目);数据分析及应用(数据集成机制,Web Services,数据挖掘任务,数据可视化);以及数据脱敏和分类分级(脱敏原则与分级标准)。
二、核心学习笔记
一、数据采集与预处理
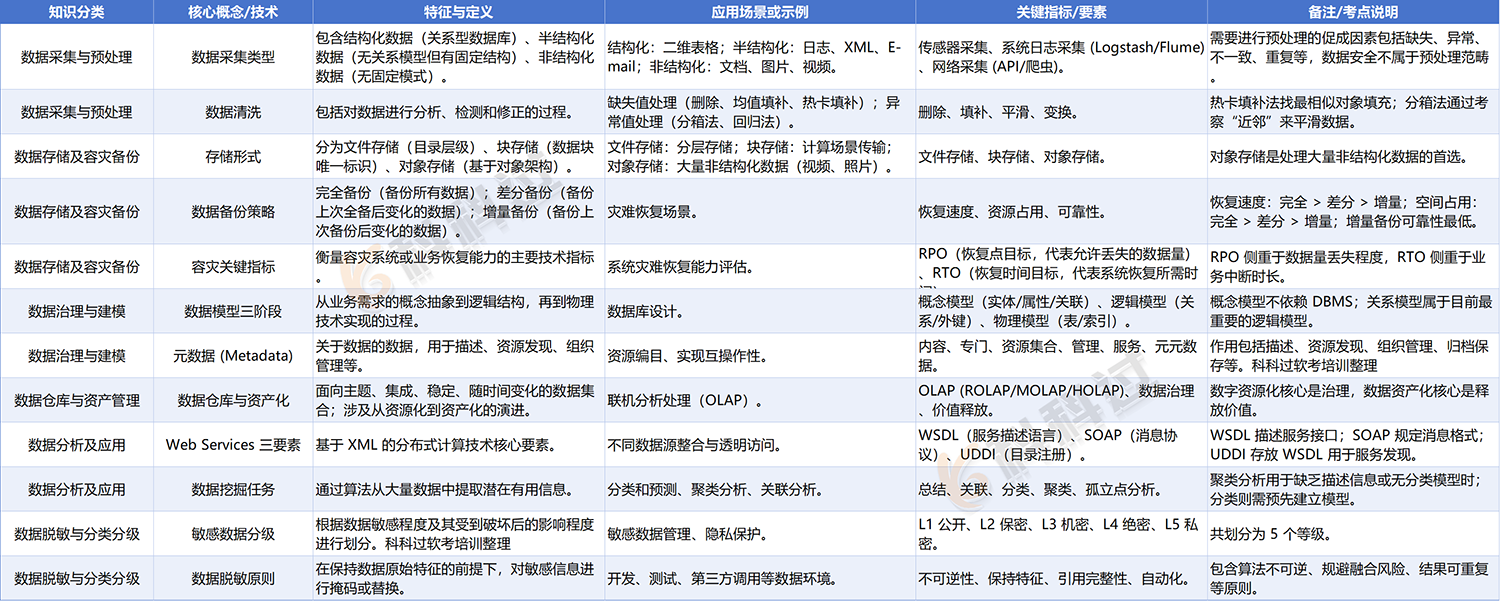
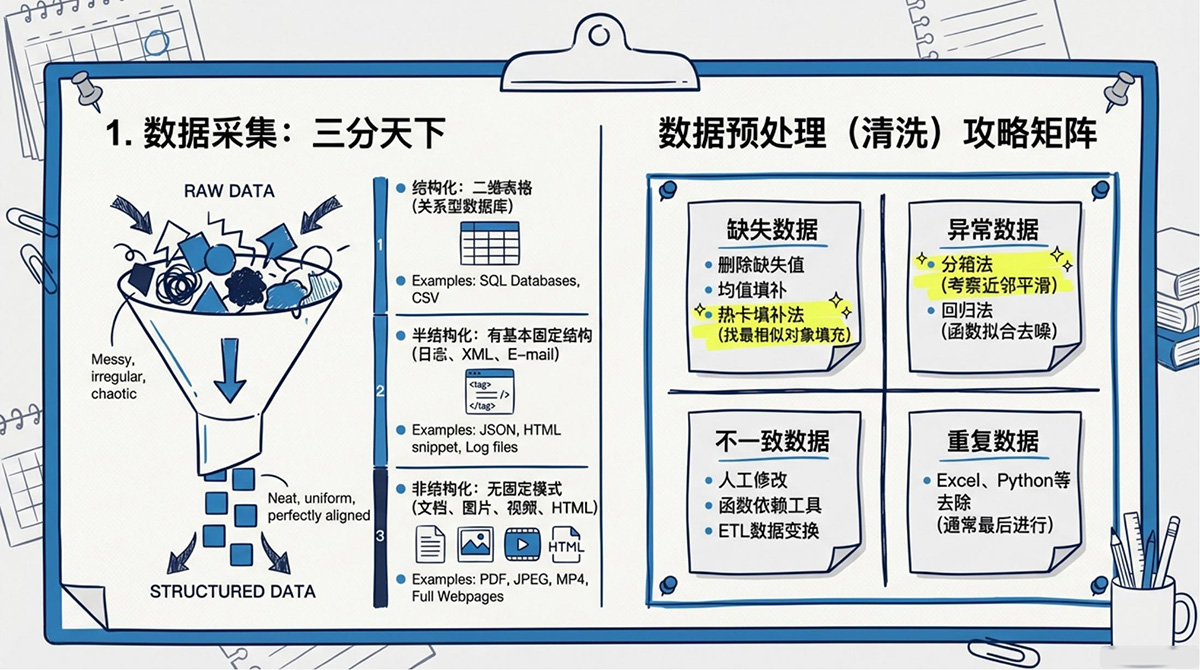
1. 数据采集类型与方法
|
数据类型 |
特征 |
示例 |
|
结构化数据 |
关系型数据库表管理的数据 |
二维表格 |
|
半结构化数据 |
无关系模型但有基本固定结构 |
日志、XML、E-mail |
|
非结构化数据 |
无固定模式 |
文档、图片、视频、HTML |
采集方法:传感器采集、系统日志采集(Logstash、Flume等工具)、网络采集(API、网络爬虫)。
2. 数据预处理常用方法
数据预处理一般采用数据清洗的方法,包括数据分析、数据检测和数据修正。

|
数据问题 |
常用预处理方法 |
重点说明 |
|
缺失数据 |
删除缺失值、均值填补法、热卡填补法 |
丢弃适用于样本多且缺失比例小;热卡填补法找最相似对象填充 |
|
异常数据 |
分箱法、回归法 |
分箱法考察“近邻”平滑数据;回归法用函数拟合消除噪声 |
|
不一致数据 |
人工修改、借助函数依赖关系工具、数据变换 |
多需通过ETL工具等进行数据变换 |
|
重复数据 |
使用Excel、VBA、Python等去除 |
操作一般最后进行 |
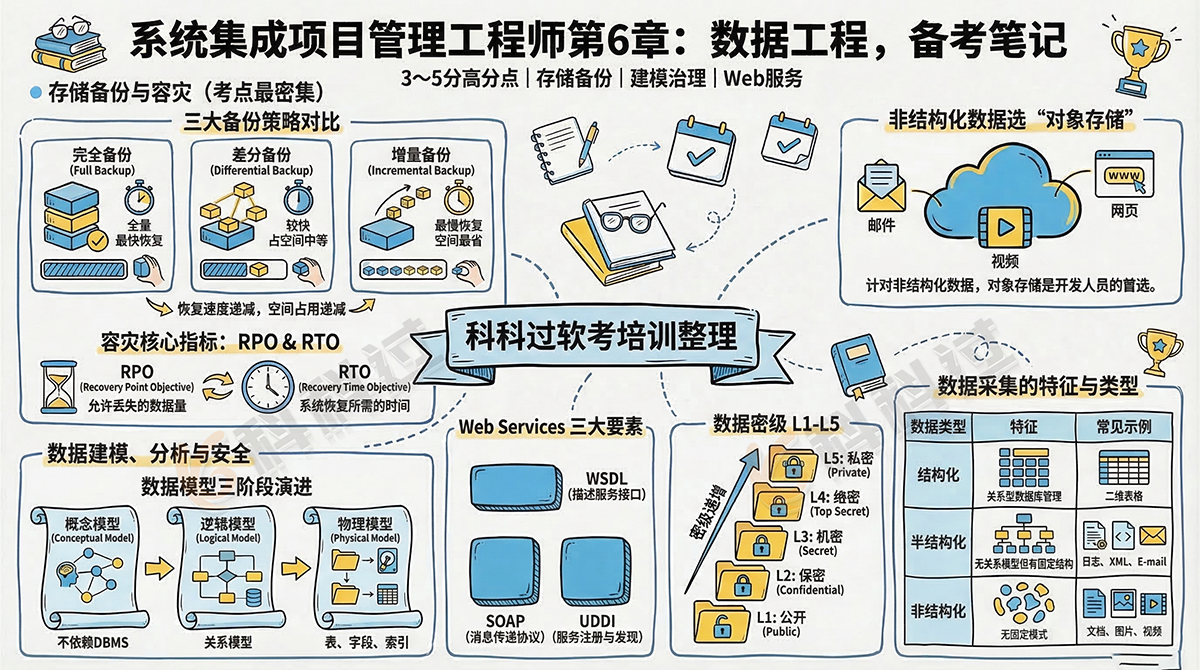
二、数据存储及容灾备份(高频考点)
1. 数据存储形式

|
存储形式 |
特征 |
适用场景 |
|
文件存储 |
基于文件和文件夹目录层级 |
适用于分层存储 |
|
块存储 |
数据分成块,每块有唯一标识 |
适用于快速、高效和可靠传输的计算场景 |
|
对象存储 |
基于对象的存储架构 |
适用于处理大量非结构化数据 (如电邮、视频、照片、网页等) |
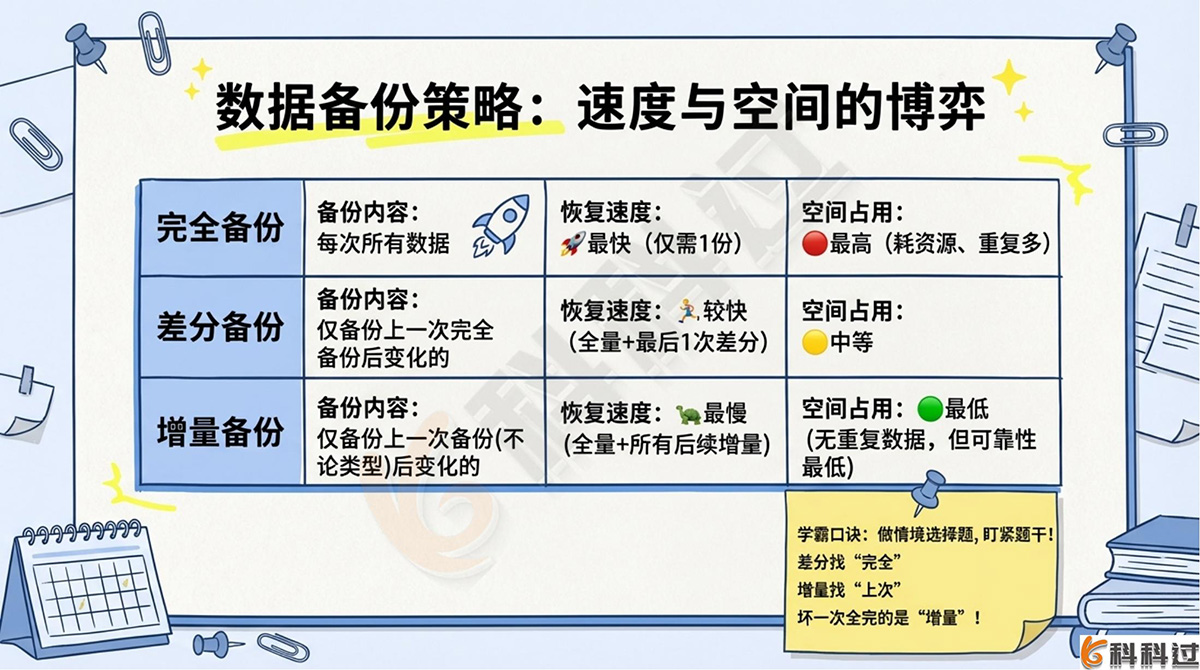
2. 数据备份策略比较
|
备份策略 |
备份内容 |
恢复速度 |
资源占用与存储 |
缺点 |
|
完全备份 |
每次备份所有数据 |
最快 (仅需一份数据) |
最高 (占用大量空间) |
存在大量重复数据,资源消耗大 |
|
差分备份 |
仅备份上一次完全备份后变化的数据 |
较快(需完全备份+最后一次差分备份) |
中等 |
相比增量备份占用空间稍大 |
|
增量备份 |
仅备份上一次备份后(不论全/增)变化的数据 |
最慢 (需全量+所有后续增量) |
最低 (无重复数据) |
可靠性最低 ,中间任何一次损坏即无法恢复 |
3. 数据容灾关键指标
|
指标 |
全称 |
含义 |
|
RPO |
Recovery Point Objective(恢复点目标) |
代表灾难发生时允许丢失的数据量 |
|
RTO |
Recovery Time Objective(恢复时间目标) |
代表系统恢复的时间 |
三、数据治理与建模(热门考点)
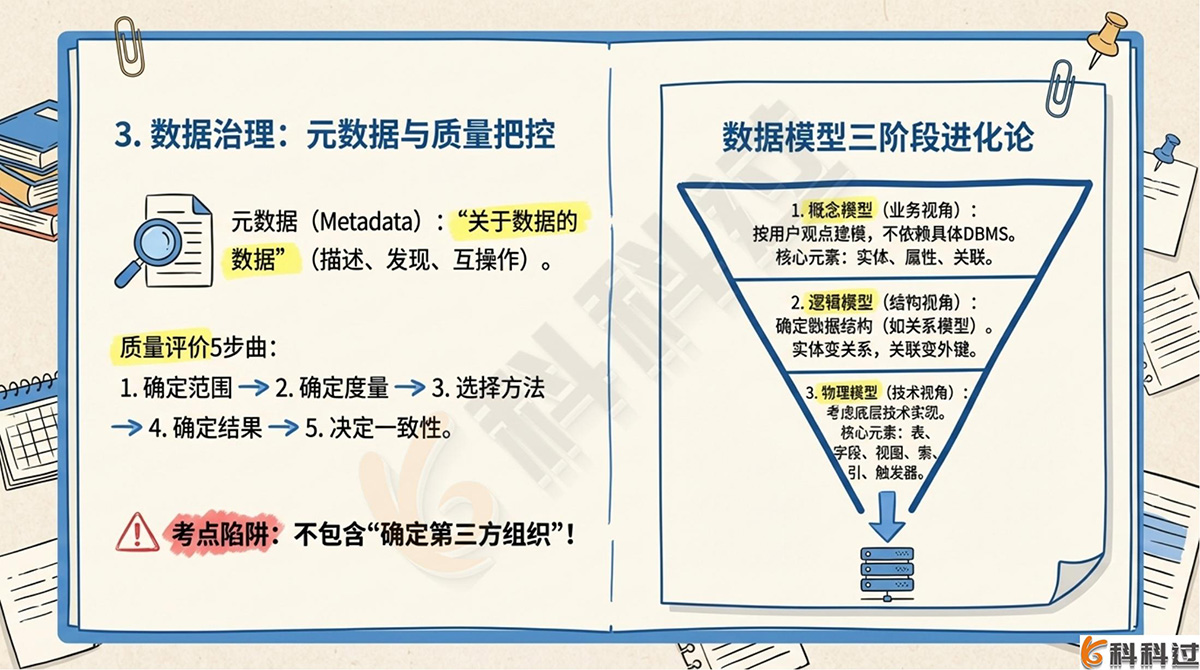
1. 元数据 (Metadata)
元数据是 “关于数据的数据”。元数据体系包括:内容元数据、专门元数据、资源集合元数据、管理元数据、服务元数据、元元数据。作用包括描述、资源发现、组织管理数据资源、互操作性、归档和保存。
2. 数据质量评价
评价过程分为五步:确定范围 ➔ 确定度量方法 ➔ 选择评价方法 ➔ 确定质量结果 ➔ 决定一致性
3. 数据模型三阶段
|
模型阶段 |
核心特征 |
关键要素 |
|
概念模型 |
按用户观点建模,不依赖具体DBMS |
实体、属性、域、键、关联 |
|
逻辑模型 |
在概念模型基础上确定数据结构,目前最重要的是关系模型 |
概念模型中的实体转化为关系,属性转化为关系的属性,关联转化为外键 |
|
物理模型 |
考虑技术实现 |
表、字段、视图、索引、存储过程、触发器 |
四、数据仓库与资产管理
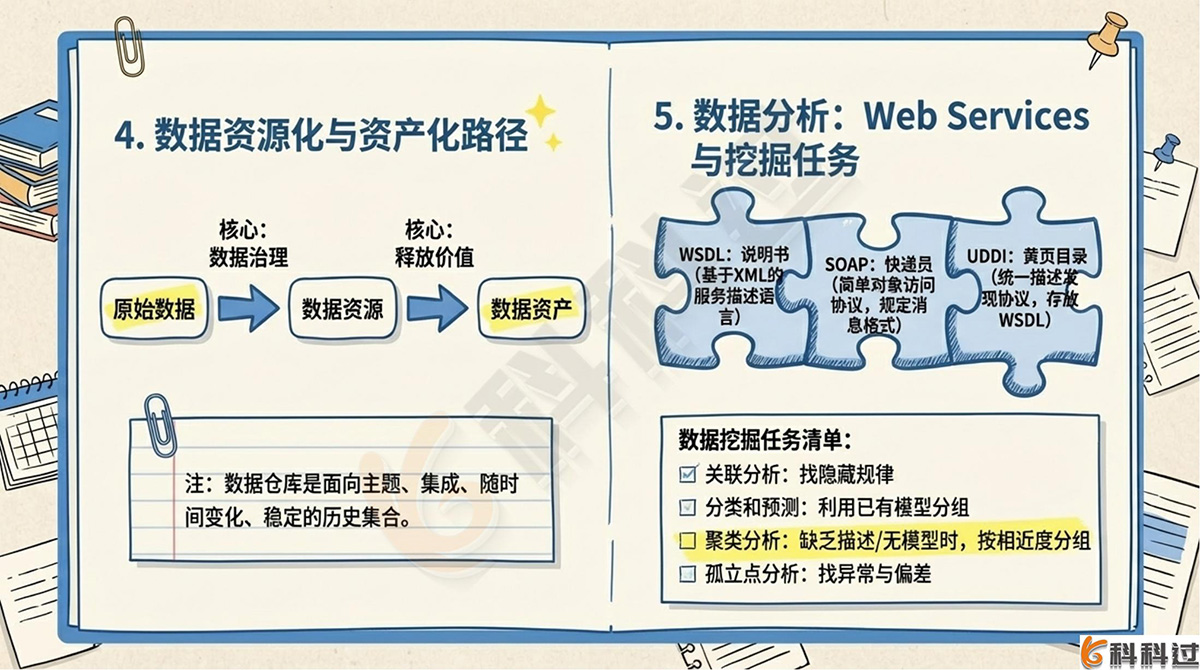
- 数据仓库定义:面向主题的、集成的、随时间变化的、稳定的历史数据集合。
- OLAP(联机分析处理):分为ROLAP(关系型)、MOLAP(多维型)、HOLAP(混合型)。
- 数据资产管理:
- 数字资源化:原始数据 ➔ 数据资源(核心是数据治理,保质保安全)
- 数据资产化:数据资源 ➔ 数据资产(核心是释放价值、显性化成本效益)
五、数据分析及应用
1. 数据集成与 Web Services
- 数据访问接口:ODBC(基于SQL)、JDBC(Java接口)、OLE DB(基于COM)、ADO。
- Web Services 三要素:
|
要素 |
全称 |
作用 |
|
WSDL |
Web Services Description Language |
基于XML格式的服务描述语言,描述服务接口等 |
|
SOAP |
Simple Object Access Protocol |
简单对象访问协议 ,规定消息传递格式和远程方法调用 |
|
UDDI |
Universal Description, Discovery and Integration |
统一描述、发现和集成协议 ,目录服务器,存放WSDL |
2. 数据挖掘主要任务
|
任务 |
核心含义 |
|
数据总结 |
对数据浓缩,给出总体综合描述 |
|
关联分析 |
找出隐藏的关联网,发现变量间的规律 |
|
分类和预测 |
利用分类器或模型将数据分派到不同组 |
|
聚类分析 |
缺乏描述信息时 ,按相近程度将数据分成有意义的子集 |
|
孤立点分析 |
从数据库中检测出异常、偏差记录 |
六、数据脱敏与分类分级
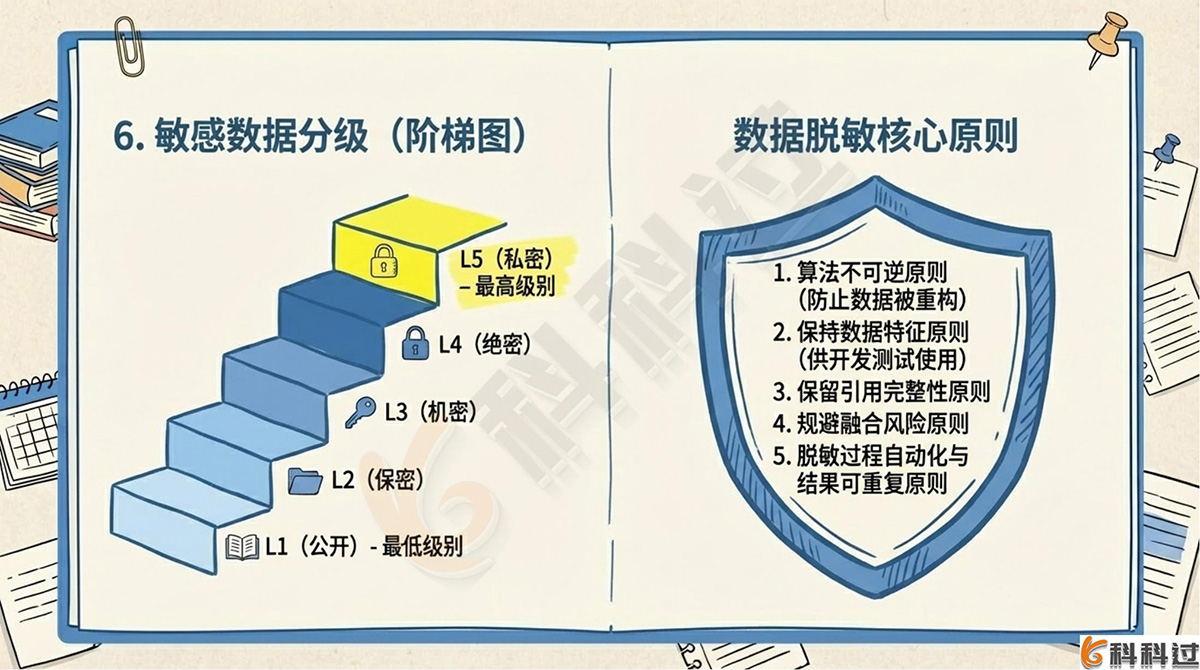
1. 敏感数据分级
通常将数据密级划分为5个等级:
|
等级 |
名称 |
|
L1 |
公开 |
|
L2 |
保密 |
|
L3 |
机密 |
|
L4 |
绝密 |
|
L5 |
私密 |
2. 数据脱敏原则
算法不可逆原则(防止重构)、保持数据特征原则(供开发测试使用)、保留引用完整性原则、规避融合风险原则、脱敏过程自动化原则、脱敏结果可重复原则。

三、本章精选习题及详细解析
题目1:________不属于需要进行数据预处理的促成因素。
A. 数据缺失
B. 数据不一致
C. 数据安全
D. 数据重复
答案:C
详细解析:一般而言,需要进行预处理的数据主要包括数据缺失、数据异常、数据不一致、数据重复、数据格式不符等情况。数据安全属于安全架构或治理范畴,不是引发日常预处理的直接数据特征因素。
教材页码:第236页、第257页(课后习题)
题目2:衡量容灾系统或能力的主要指标是________。
A. 远程镜像技术
B. RTO/RPO
C. 异地容灾
D. 数据备份策略
答案:B
详细解析:从技术上看,衡量容灾系统有两个主要指标,即 RPO(恢复点目标,代表允许丢失的数据量) 和 RTO(恢复时间目标,代表系统恢复的时间)。
教材页码:第240页、第257页
题目3:________不属于常见的数据质量评价过程。
A. 确定使用的数据质量定量元素及数据质量范围
B. 确定数据质量度量方法
C. 确定数据质量评价的第三方组织
D. 选择并使用数据治理评价方法
答案:C
详细解析:数据质量评价过程的五步包括:范围限定的数据集(确定定量元素及范围)、确定度量方法、选择并使用评价方法、确定质量结果、决定一致性。不包含“确定第三方组织”。
教材页码:第243页(图6-4)、第257页
题目4:关于数据集成定义的描述较为准确的是________。
A. 通过应用软件接口,将不同系统的数据进行共享
B. 将不同表单中的结构化数据融合为一个表单
C. 通过网络或数据标准,实现数据的共享与交换
D. 将驻留在不同数据源中的数据进行整合
答案:D
详细解析:教材对数据集成的明确定义是:“数据集成就是将驻留在不同数据源中的数据进行整合,向用户提供统一的数据视图,使得用户能以透明的方式访问数据”。
教材页码:第249页、第258页
题目5:为了更加有效地管理敏感数据,通常会对敏感数据的敏感程度进行划分,以下属于常见程度划分的是________。
A. L1(公开)、L2(保密)、L3(机密)、L4(绝密)、L5(私密)
B. L1(个人)、L2(组织)、L3(商业)、L4(技术)、L5(国家)
C. L1(公共)、L2(保密)、L3(机密)、L3(加密)、L5(绝密)
D. L1(互联网)、L2(局域网)、L3(保密网)、L4(专网)、L5(绝密网)
答案:A
详细解析:为了有效地管理敏感数据,通常把数据密级划分为5个等级,分别是 L1(公开)、L2(保密)、L3(机密)、L4(绝密)和 L5(私密)。
教材页码:第255页、第258页
题目6:在数据存储形式中,针对需要处理大量非结构化数据(如电子邮件、视频、照片、网页等),开发人员一般倾向于使用哪种存储架构?
A. 文件存储
B. 块存储
C. 对象存储
D. 关系型存储
答案:C
详细解析:对象存储通常称为基于对象的存储,是一种用于处理大量非结构化数据的数据存储架构。这些数据无法轻易组织到关系数据库中,如电邮、视频、传感器数据等。
教材页码:第237页
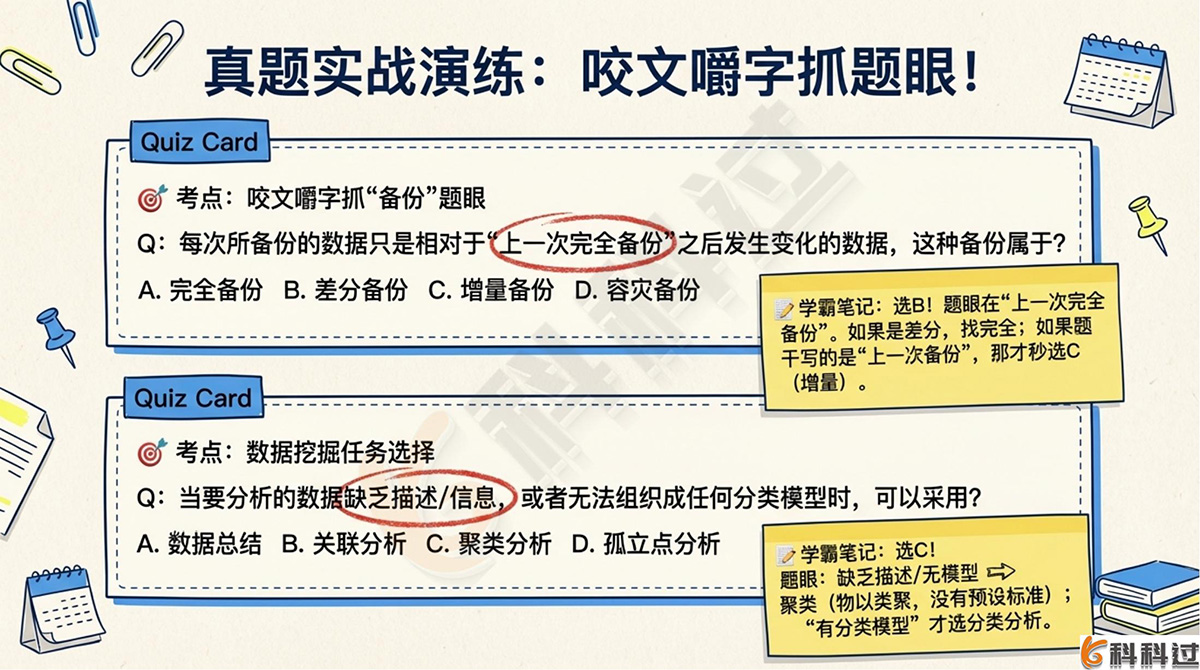
题目7:在数据备份策略中,每次所备份的数据只是相对于“上一次完全备份”之后发生变化的数据,这种备份属于________。
A. 完全备份
B. 差分备份
C. 增量备份
D. 容灾备份
答案:B
详细解析:差分备份的定义是每次所备份的数据只是相对“上一次完全备份”之后发生变化的数据。增量备份则是相对于“上一次备份”(不区分全量或增量)后改变的数据。
教材页码:第240页
题目8:在Web Services的三大要素中,________是一种基于XML格式的关于Web服务的描述语言,主要目的在于将服务的所有相关内容(如传输方式、方法接口等)生成文档发布给使用者。
A. SOAP
B. UDDI
C. HTTP
D. WSDL
答案:D
详细解析:WSDL(Web Services Description Language) 是基于XML的描述语言,用于生成描述服务细节的文档;SOAP是消息传递的协议;UDDI是集中存放和查找WSDL描述文件的注册服务规范。
教材页码:第250页
题目9:在数据建模中,不依赖于具体的计算机系统,把现实世界中的客观对象抽象为某一种信息结构,包含实体、属性、域、键、关联等基本元素的模型是________。
A. 概念模型
B. 逻辑模型
C. 物理模型
D. 关系模型
答案:A
详细解析:概念模型也称为信息模型,按用户观点建模,不依赖于具体DBMS。它的基本元素包括实体、属性、域、键、关联。关系模型属于逻辑模型。
教材页码:第244页
题目10:当要分析的数据缺乏描述信息,或者无法组织成任何分类模型时,可以采用________。它按照相近程度,将数据分成一系列有意义的子集。
A. 数据总结
B. 关联分析
C. 聚类分析
D. 孤立点分析
答案:C
详细解析:聚类分析是在要分析的数据缺乏描述信息时使用的方法,按照相近程度度量,将数据分成性质相近的子集。分类分析则通常预先有一个分类函数或模型。
教材页码:第252页


💡 备考小贴士
第6章是数据工程的核心章节,建议重点关注:
- 数据存储形式:文件存储、块存储、对象存储的适用场景(特别是对象存储用于非结构化数据)
- 备份策略:完全备份、差分备份、增量备份的区别(恢复速度、资源占用、可靠性)
- 容灾指标:RPO(数据丢失量)和RTO(恢复时间)
- 数据模型三阶段:概念模型(实体、属性、关联)、逻辑模型(关系模型)、物理模型(表、索引)
- Web Services三要素:WSDL(描述)、SOAP(消息)、UDDI(注册)
- 数据挖掘任务:聚类分析(无分类模型时使用)vs 分类分析(有分类模型时使用)
- 数据密级:L1公开、L2保密、L3机密、L4绝密、L5私密
把这些核心考点记牢,3-5分轻松到手,案例分析也能从容应对!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)