深入讲解Transformer架构(详细图解)——大模型学习精讲第五期:Transformer
在前面的第4期,我们已经深入探讨了 Transformer 的自注意力机制(Self-Attention)。但一个独立的机制无法构成完整的生命体。在这一章,我们将视野拉高,看看 Transformer 是如何将注意力机制、前馈神经网络等组件拼接在一起,形成一个能够完成翻译、问答和文本生成的端到端系统的。
Transformer 的经典架构本质上是一个编码器-解码器 (Encoder-Decoder) 结构。打个比方,编码器就像是一位精通外语的“阅读理解专家”,负责把输入文本嚼碎并转化为机器能理解的深层语义;而解码器则是一位“表达专家”,根据编码器提取的精华,逐字逐句地生成最终的输出。
Transformer 整体架构拆解
1.编码器
在《Attention Is All You Need》的原论文中,编码器由 个完全相同的层(Layer)堆叠而成。不要被“堆叠”这个词吓到,它的逻辑非常简单:下一层的输入,就是上一层的输出。

这种层层递进的设计,是为了让模型对语言的理解越来越抽象、越来越深刻。
假设我们要翻译一句话:“The bank of the river.”
-
输入准备:这句话首先会被转化为一系列词向量(这部分我们在第 4 章位置编码会细讲)。假设每个词被表示为一个维度为
的向量。
-
进入 Layer 1:这组向量同时进入第一层 Encoder。在这里,词与词之间发生相互作用,每个词的向量都会吸收周围词的信息,进行一次“自我进化”。
-
向上传递:Layer 1 输出了一组新的向量(维度依然是 512)。这组新向量直接作为 Layer 2 的输入。
-
到达顶层:经过 6 次这样的处理,最后一层输出的向量组,已经不再是简单的字面意思,而是包含了极其丰富的上下文逻辑特征。例如,此时代表“bank”的向量,已经深深打上了“river”的烙印,模型确信它是“河岸”而非“银行”。
-
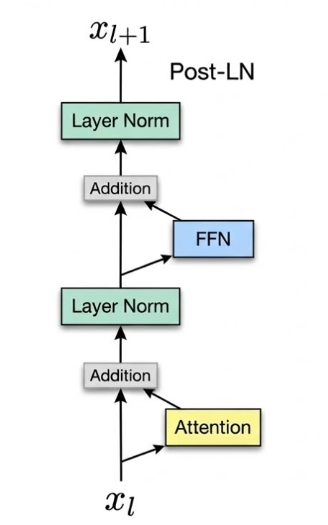
子层一:多头自注意力机制 (Multi-Head Self-Attention)
它的职责是建立全局联系。在这里,句子中的每个词都会去“观察”句子中的其他词,并吸收相关的信息。 -
子层二:前馈神经网络 (Feed-Forward Network, FFN)
自注意力机制负责把不同词的信息“混”在一起,而 FFN 则负责对每一个词的向量进行独立的非线性变换,增强其特征表达。可以理解为:交流大会(注意力层)结束后,每个词回到自己的房间独立消化信息。 -
粘合剂:残差连接与层归一化 (Add & Norm)
在每个子层的周围,都有一个 Add & Norm 结构。Add(残差连接)把输入直接加到子层的输出上,提供信息的高速公路,防止深度网络“梯度消失”;Norm(层归一化)则将数据分布拉回平稳状态,加速模型收敛。
以下是经典Transformer的结构,当然现在都是用Pre-LN了,可以看我第三期层归一化具体讲解。
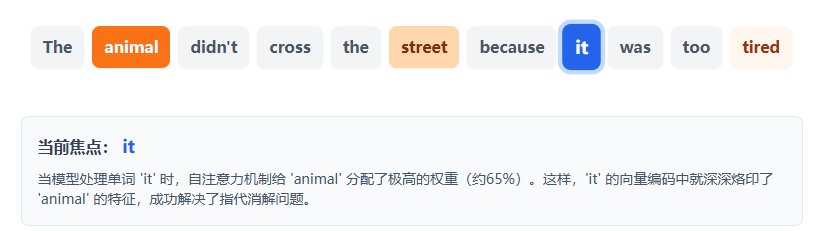
让我们通过一个经典的例子来看看自注意力机制是如何在 Encoder 中发挥作用的。 考虑这句话:“The animal didn't cross the street because it was too tired.”(那只动物没有过马路,因为它太累了。)
对人类来说,显然“it”指的是“animal”。但是机器如何知道呢?在自注意力层中,当模型处理“it”这个词时,它会去评估句子中所有其他词与“it”的关联度。
习题:
1.RNN(循环神经网络)在处理句子时必须从左到右逐个词读取,因此极其缓慢。请结合本节内容解释:为什么 Transformer 的单个 Encoder 层可以做到高度并行的计算?(提示:思考词向量在自注意力层和 FFN 层中的运算方式)
解析:因为自注意力层是通过矩阵乘法一次性计算所有词语间的关联得分的,并不依赖时间步的先后顺序;而 FFN 对序列中每个位置(每个词)的计算是独立且相同的,前一个词的计算结果不会影响后一个词。因此,整个句子的所有词可以同时输入、同时计算,极大提升了训练速度。
在上一节中,我们看到编码器 (Encoder)*像一位阅读理解专家,把输入的所有词语放在一起“开会”,最终输出了一个富含全局上下文信息的特征矩阵。
现在,接力棒交给了解码器 (Decoder)。它的任务是根据编码器提供的“精华提纲”,逐字逐句地生成目标语言(例如翻译结果)。 与编码器一次性看全整个句子不同,解码器在生成文本时,必须遵循时间的先后顺序——这被称为自回归 (Auto-regressive)。简而言之:它只能看到已经生成的词,绝对不能提前“偷看”未来的词。
2.解码器
在上一节中,我们看到编码器 (Encoder)*像一位阅读理解专家,把输入的所有词语放在一起“开会”,最终输出了一个富含全局上下文信息的特征矩阵。
现在,接力棒交给了解码器 (Decoder)。它的任务是根据编码器提供的“精华提纲”,逐字逐句地生成目标语言(例如翻译结果)。 与编码器一次性看全整个句子不同,解码器在生成文本时,必须遵循时间的先后顺序——这被称为**自回归 (Auto-regressive)**。简而言之:它只能看到已经生成的词,绝对不能提前“偷看”未来的词。
如果你把解码器的一层抽出来,你会发现它比编码器多了一层“夹心”。它包含三个子层:
-
掩码多头自注意力层 (Masked Multi-Head Self-Attention)
-
交叉注意力层 (Cross-Attention / Encoder-Decoder Attention)
-
前馈神经网络层 (Feed-Forward Network)
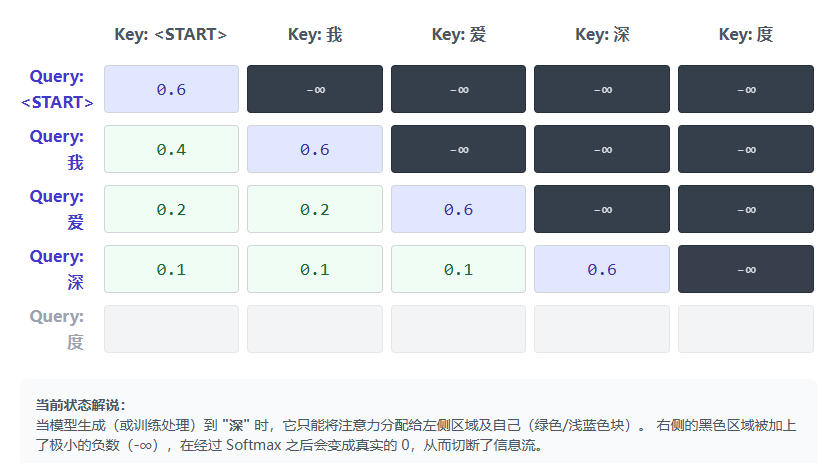
在训练时,我们会把整个目标句子(比如翻译好的标准答案)一次性喂给解码器。但是为了模拟真实生成时的“未知”状态,我们必须把目标句子中“未来的词”遮挡起来。
在数学上,这是通过向注意力分数矩阵(QK^T)中加上一个下三角矩阵掩码**来实现的。对于未来的词,我们将其掩码值设为 -∞。经过 Softmax 激活函数后,e^(-∞) = 0,这意味着模型对未来词的注意力权重完全为 0。
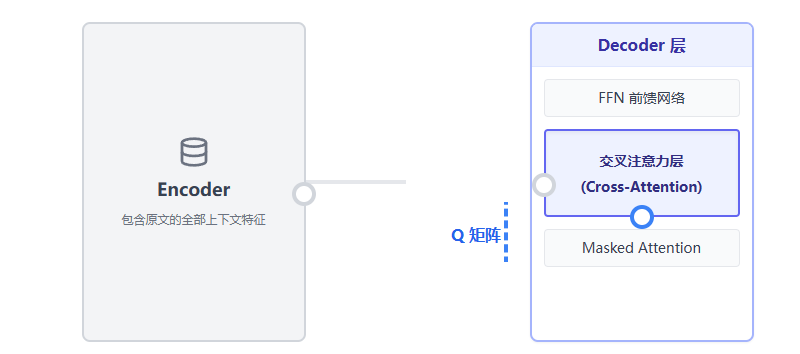
自注意力层让解码器理清了“已经生成的词”之间的逻辑关系。接下来,它需要知道编码器到底说了什么。这就轮到第二个子层——交叉注意力层登场了。
这是 Transformer 中唯一一个 Q, K, V 来源不同的地方:
-
Query (Q):来自解码器自己的上一层输出(代表“我现在生成到这一步了,我接下来需要寻找什么信息?”)。
-
Key (K) 和 Value (V):来自编码器的最终输出(代表“这里有全部原文的上下文特征和内容字典,供你检索”)。
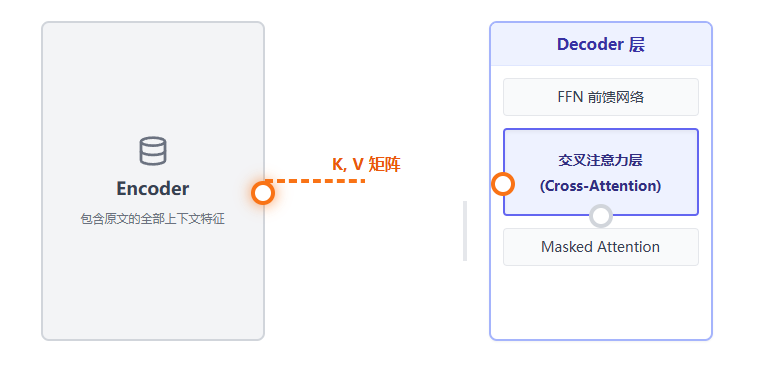
经过堆叠的解码器层后,我们会得到一个代表当前生成位置的向量。但这只是一堆数字,我们需要把它变成具体的词。
最后,向量会通过一个线性层 (Linear),将其映射到词表大小的维度(比如 50,000 个词汇)。接着使用 Softmax 函数,把这些数值转化为概率分布。概率最高的那个词,就是解码器最终给出的预测结果!
习题:
1.在模型进行实际推理(Inference/生成文本)时,我们仍然需要使用 -∞ 的矩阵掩码机制来遮挡未来的词汇。请问这个说法正确吗?为什么?
2.在交叉注意力(Cross-Attention)中,查询矩阵 Query Q 来源于 ________,而键矩阵 Key K 和值矩阵 Value V 来源于 ________。这使得解码器可以在生成每个词时,精准检索原文信息。
解析:
1.错误。 掩码机制(Masking)主要是为了并行训练 (Training) 而设计的。在训练时我们拥有完整的正确答案句子,为了防止提前看到答案才加掩码。而在实际推理时,模型本来就是逐字生成的,未来的词在物理上还不存在,因此自然无法“看到”,也就不需要应用复杂的矩阵掩码了。
2:
填空 1:解码器 (Decoder) 前一层的输出。
填空 2:编码器 (Encoder) 的最终输出。
关键基础组件
在前面的章节中,我们将 Transformer 拆解成了编码器和解码器。我们看到了自注意力机制如何让单词之间互相交流。 但是,如果你只用纯粹的自注意力机制去构建模型,马上就会遇到一个致命的缺陷——它是个“路痴”。
在这一章,我们将深入研究填补 Transformer 架构空白的三个关键基础组件:位置编码、前馈神经网络,以及残差与层归一化。
1.位置编码
痛点:自注意力天生丢失了顺序信息
RNN(循环神经网络)是逐个单词按顺序读取的,天生知道谁在前面谁在后面。而 Transformer 是一次性把所有单词的矩阵塞进自注意力层进行矩阵相乘。 这意味着,对于纯粹的自注意力机制来说,“我 爱 你”和“你 爱 我”产生的注意力分数分布是完全对称且无区别的。这就是所谓的“词袋模型”缺陷。
为了解决这个问题,原论文提出:既然模型不知道顺序,那我们就把“位置序号”作为额外的信息,硬塞进单词的向量里。
精妙的设计:为什么不用简单的 1, 2, 3...?
你可能会问:直接给第一个词加上1,第二个词加上2不行吗? 不行。因为句子长度是不固定的。如果用绝对数字,较长句子末尾的数字会非常大(比如1000),这会干扰词向量原本的语义数值(通常在 0 附近浮动),导致模型崩溃。
作者最终选择了正弦(Sine)和余弦(Cosine)函数的组合。当然这只是最简单的,后面的更新中我会讲解ROPE旋转位置编码
第 pos 个单词,在维度 i 上的位置编码公式:
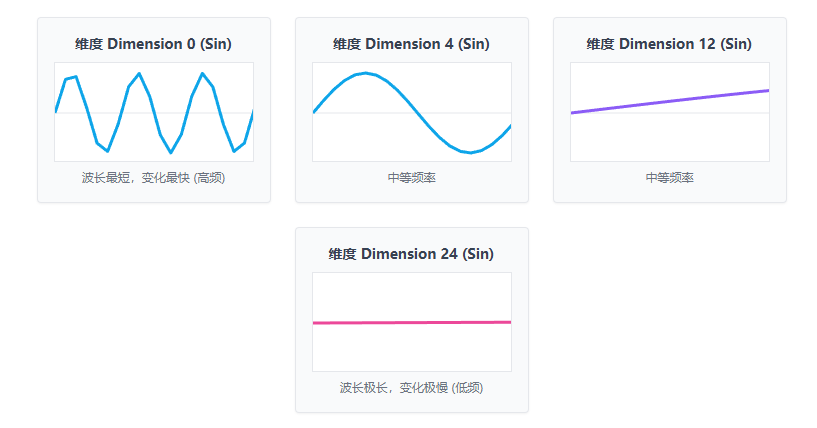
初看这个公式简直令人头大,但它的物理意义极度优雅。你可以把它想象成一组转速不同的时钟指针:
-
维度靠前的部分(低频),就像时钟的秒针,每个位置变化都很大。
-
维度居中的部分(中频),就像分针,变化比较缓和。
-
维度靠后的部分(高频),就像时针,走得非常非常慢。
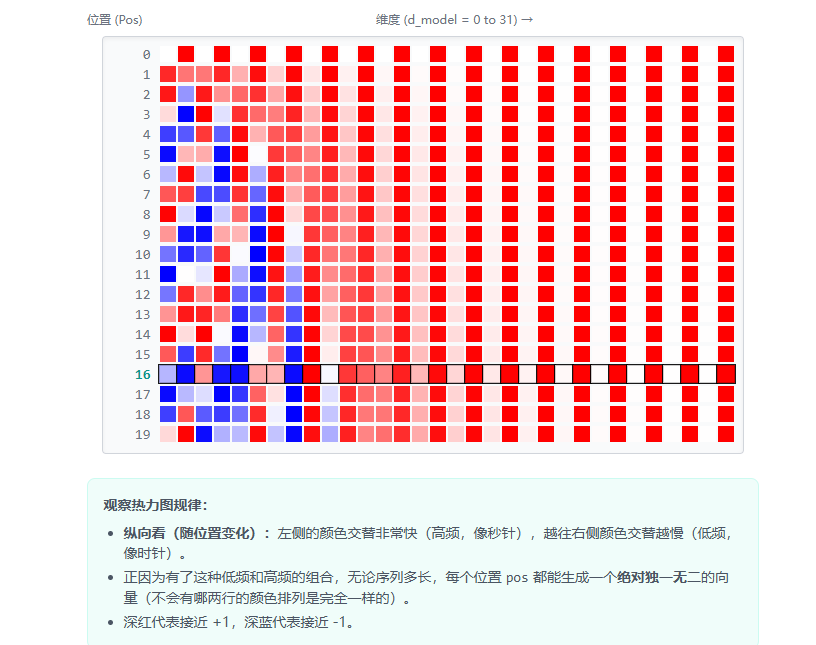
通过读取这几根“指针”的状态,模型就能精确、唯一地确定当前处在什么位置,并且很容易学习到单词之间的相对距离。
2 前馈神经网络 (FFN)
我们在上一章提到过,自注意力机制负责让大家“开会交流”,而 FFN(Feed-Forward Network)负责在会后“独立进修”。
公式非常简单,就是两个线性映射(矩阵乘法)中间夹着一个 ReLU 激活函数:
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂
在标准的 Transformer 中,输入词向量的维度是 512。FFN 的第一层(W₁)会将维度暴力拉升 4 倍,达到 2048 维,进行 ReLU 非线性激活后,第二层(W₂)再将其压回 512 维。
这种“先升维再降维”的操作(类似卷积网络中的逆瓶颈结构),被证明能够极大地增强模型对特征的非线性拟合能力,就像是给大脑的神经元腾出了巨大的空间来记忆复杂的模式。
3.残差连接与层归一化 (Add & Norm)
如果没有 Add & Norm,把 6 层 Encoder 叠在一起,模型在训练初期可能就因为梯度消失(Gradient Vanishing)而彻底瘫痪了。
-
Add (残差连接 / Residual Connection):公式是
Output = x + Sublayer(x)。它相当于在两个网络层之间修了一条“高速公路”。就算子层(Sublayer)初始化得很差,信号也能通过高速公路直接传到下一层,保证了梯度能够顺畅地反向传播。 -
Norm (层归一化 / Layer Normalization):与图像领域常用的 Batch Normalization 不同,NLP 中的句子长度参差不齐,Batch Norm 效果很差。层归一化是对每一个词向量内部进行标准化(减去该向量的均值,除以标准差),让数据分布回到均值为 0,方差为 1 的平稳状态,防止数值在不断相乘后爆炸。
习题
1.论文中提到,位置编码矩阵是直接加 (Add) 到词嵌入矩阵上的,而不是拼接 (Concat)。既然词向量表示“语义”,位置编码表示“位置”,直接相加难道不会把语义信息弄乱吗?
2.为什么在 Transformer 中我们使用 Layer Normalization (LN) 而不是像 ResNet 那样使用 Batch Normalization (BN)?
解析:
1.这是一个非常经典的问题。虽然直觉上拼接(Concat)更合理,但直接相加(Add)在几百维的高维空间中是可行的。因为在高维空间里,向量非常稀疏,它们很大可能是近似正交的。 此外,模型在后续的线性层中,有能力学习到将“语义子空间”和“位置子空间”解耦的权重映射。直接相加的巨大优势是:不增加矩阵的维度,从而大大节省了内存和计算开销。
2.文本序列长度是动态的,且序列维度(Seq_Len)对于每个 Batch 都不一样。BN 是对同一个 Batch 里的同一维度计算,这在 NLP 这种变长序列、小 Batch Size 的场景下表现很差。LN 则是对单个样本的单个时间步(词向量)内部的所有特征维度进行归一化,完美避开了长度问题。
训练与推理细节
在前面的章节中,我们已经搭建好了 Transformer 的宏伟建筑:多头注意力、前馈网络、位置编码一应俱全。 但这就像是造好了一台超级计算机,里面却没有安装任何软件。这一章,我们将探讨如何把人类的语言转化为机器能懂的数字(数据预处理),如何指导模型修正错误(训练),以及最终它是如何开口说话的(推理)。
词表与分词 (Tokenizer)
神经网络只能处理数字(向量),无法直接读取“Apple”或“苹果”这样的字符。因此,第一步必须建立一个词表 (Vocabulary)。
最古老的做法是按空格分词,一个完整的单词算作一个 Token。但这样会导致词表无限庞大(比如 play, playing, played 会被当成三个毫无关联的词),并且容易遇到“未登录词 (Out-Of-Vocabulary, OOV)”。 现代 Transformer(包括 GPT 系列)普遍采用子词分词算法 (Subword Tokenization),其中最著名的是 BPE (Byte-Pair Encoding)。
BPE 的核心思想:从最基础的单字母开始,统计语料库中相邻出现频率最高的两个片段,将它们合并成一个新的整体,不断迭代,直到达到预设的词表大小。这样既能保留常见单词的整体性,又能把生僻词拆解为常见的词根词缀。
接下来我用个可视化来带大家理解:



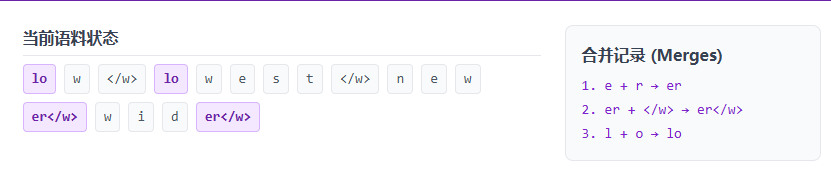
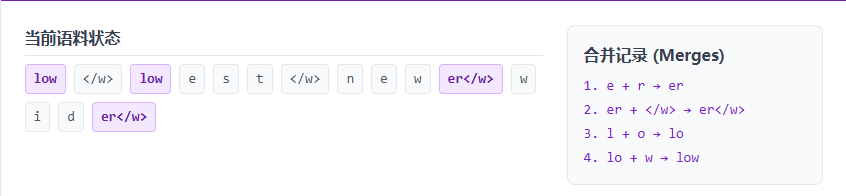
解析:在上面的例子中,我们从字母级别开始。模型发现 e 和 r 经常挨在一起(在 newer, wider 中),于是把它们合成了代表比较级后缀的 er。接着 l, o, w 逐渐合并成了完整的词 low。这就是现代 LLM 切分单词的核心逻辑!
Teacher Forcing 与并行计算
我们之前提到,模型在真正使用时(推理)是自回归的,也就是必须等上一个词生成出来,才能预测下一个词。这就引出了一个严重的问题:如果训练时也这样做,不仅速度慢如蜗牛,而且万一模型第一个词就预测错了,后面的词就会“一步错,步步错”(误差累积),导致模型根本学不到东西。
Transformer 的破局之法叫做 Teacher Forcing(导师强迫)。
既然在训练时我们手里已经有了完整的正确答案(Ground Truth),我们就不需要等待模型自己慢慢猜了。我们直接把正确答案作为解码器的输入!
-
输入错位 (Shifted Right):我们将正确答案向右平移一位,最前面加上
<START>标记。 -
掩码保护 (Masking):虽然把整句话都喂给了模型,但我们用下三角掩码遮住未来的词,确保模型在预测第 N 个词时,只能看到前 N-1 个正确答案。
-
并行计算损失 (Parallel Loss):模型同时输出所有位置的预测概率,我们将它们与原本的正确答案逐位对比,计算交叉熵损失(Cross-Entropy Loss),然后一次性反向传播更新参数。
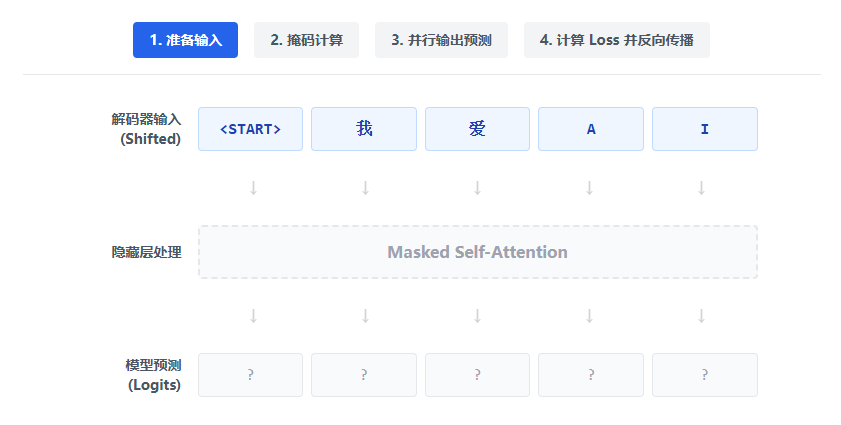



重点解析:在推理阶段,模型每次只输出最右边的一个词。但在训练阶段(即当前演示),输入序列是一次性完整的传入,输出的 5 个概率分布也是并行同时计算出来的!然后统一与下方的“标准答案”计算损失,极大提升了 GPU 的训练效率。
优化器 Optimizer与预热 Warm-up
Transformer 在刚被提出时,是以“极难训练”著称的。如果不掌握特定的训练技巧,模型很容易在最初的几步就陷入梯度爆炸,彻底崩溃。
为了驯服这头猛兽,原论文使用带有特定学习率调度(Learning Rate Schedule)的 Adam 优化器。这个调度的精髓在于:先预热 (Warm-up),再衰减 (Decay)。
-
预热阶段:在训练刚开始的
warmup_steps步内(通常是 4000 步),学习率从极小的值线性增长。这是因为模型刚初始化时内部参数一片混乱,步子迈得太大容易“摔倒”。 -
衰减阶段:度过预热期后,模型已经找到了大致的正确方向,此时学习率按照步数的平方根反比(inverse square root)缓慢下降,以便在最优解附近进行精细的微调。

训练技巧:
在计算损失(Loss)时,标准的做法是让模型预测正确答案的概率无限接近 100%,错误答案为 0%。但这会导致模型过于“自大”,容易过拟合。
Transformer 引入了 Label Smoothing 技术:它强行从正确答案的概率中匀出一点点(例如 0.1),平分给所有其他错误的词。这就相当于告诉模型:“虽然这个词是标准答案,但也别太绝对,其他词在某些语境下也许也说得通。”这极大地提高了模型的泛化能力。
推理 (Inference)
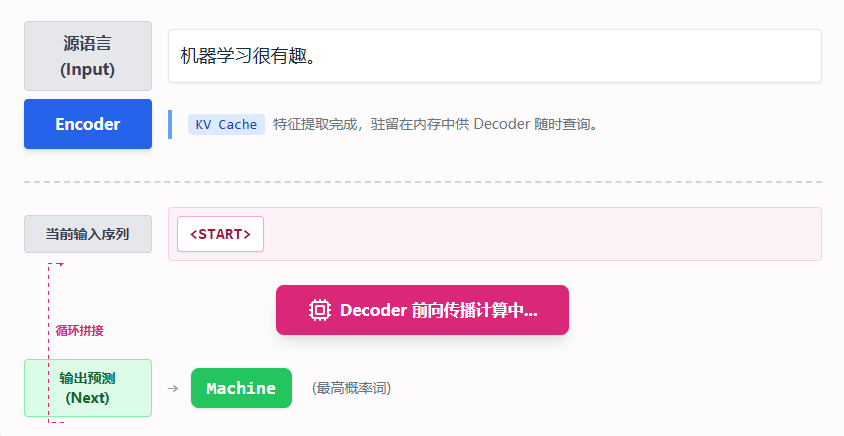
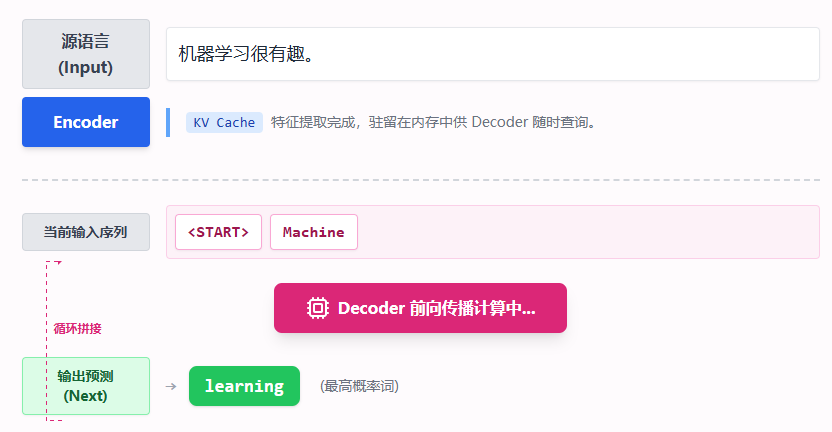
训练完成后,模型就出师了。当我们让它生成文本时,这个过程被称为推理 (Inference)。
与训练时“一次性看完全文进行并行计算”不同,推理必须遵循严谨的自回归 (Auto-regressive) 原则: 每次只预测一个词。然后把预测出的词重新拼接到输入序列中,作为下一轮的已知条件,再次喂给模型。
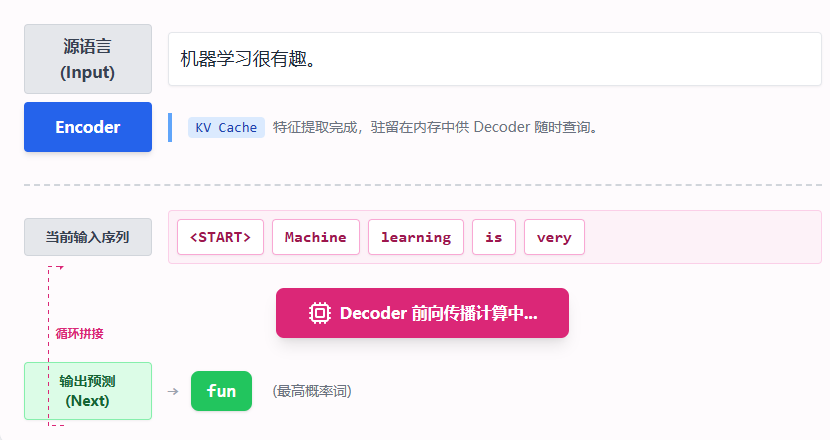
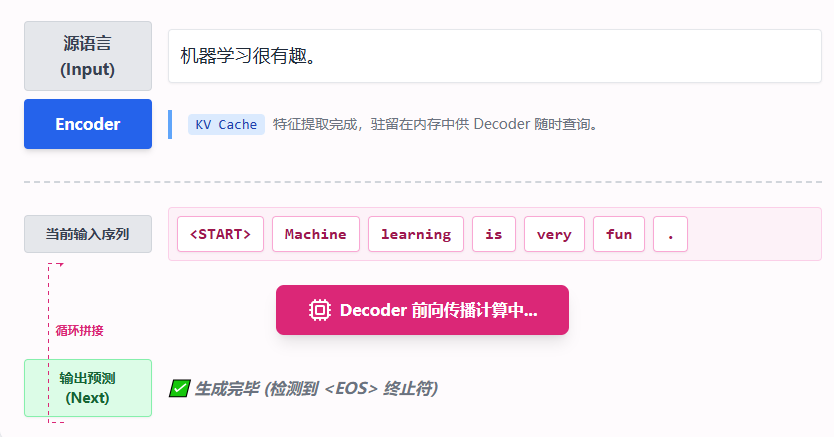
Transformer 的家族演进与影响
2017 年的《Attention Is All You Need》论文,最初只是谷歌为了改进机器翻译系统而提出的。完整的 Encoder-Decoder 架构非常适合这种“序列到序列 (Seq2Seq)”的任务。
但在随后的几年里,研究人员发现了一个惊人的事实:自注意力机制的普适性极强。我们甚至不需要完整的 Transformer,只要拆下它的一半(单纯的 Encoder 或单纯的 Decoder),通过海量数据的“预训练 (Pre-training)”,就能在几乎所有自然语言处理任务上碾压过去的模型。
由此,Transformer 家族走向了不同的进化分支,诞生了 AI 史上最著名的两大门派:BERT 系与 GPT 系。



仅编码器 (Encoder-Only):BERT 的“完形填空”
2018 年,谷歌推出了 BERT (Bidirectional Encoder Representations from Transformers)。它完全抛弃了解码器,只保留了编码器(Encoder)。
既然没有了解码器,它怎么训练呢?谷歌天才般地提出了 掩码语言建模 (Masked Language Modeling, MLM)。简单来说,就是给模型做“完形填空”。把句子中随机 15% 的词挖空(替换为 [MASK]),让模型利用上下文(包含左边和右边的词)去猜被挖掉的词是什么。
由于没有了生成任务的限制,BERT 可以肆无忌惮地进行双向 (Bidirectional) 注意力计算,它对语言的“理解”极其深刻,迅速统治了文本分类、情感分析、命名实体识别等“自然语言理解 (NLU)”领域。
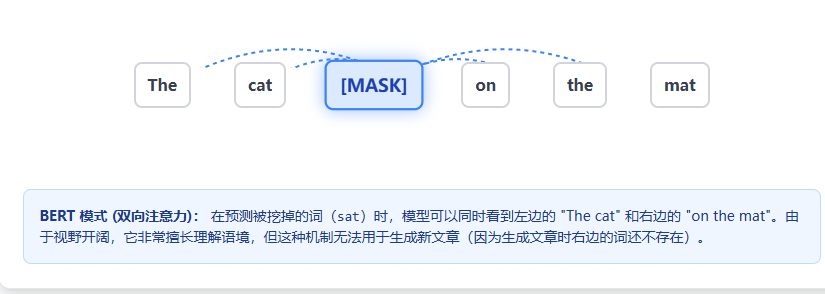
仅解码器 (Decoder-Only):GPT 的“文字接龙”
几乎在同一时期,OpenAI 走上了另一条截然不同的道路:GPT (Generative Pre-trained Transformer)。它抛弃了编码器,只保留了解码器。
GPT 的训练目标极其简单纯粹:单向的下一个词预测 (Next Word Prediction)。它就像是在玩极其硬核的“文字接龙”。因为采用了我们第 3 章讲过的“下三角掩码”,GPT 在预测时永远只能看到左边的词,绝对看不到右边(未来)的词。
虽然早期的 GPT-1 和 GPT-2 在“理解”任务上不如 BERT 惊艳,但 OpenAI 坚信大力出奇迹。随着模型规模的不断扩大(GPT-3, GPT-4),量变引起了质变(涌现能力)。如今,这种 Decoder-Only 架构已经成为了大语言模型(LLM)的绝对统治者。

跨界破圈:Vision Transformer (ViT)
如果说 Transformer 在 NLP 领域的成功是意料之中,那么它在计算机视觉(CV)领域的降维打击则让所有人大跌眼镜。
2020 年,ViT (Vision Transformer) 证明了:我们甚至不需要改动 Transformer 的架构!只要把一张图片切成一个个 16x16 的小方块(Patches),然后把这些小方块当成“单词”一样排成一个序列,送进标准的 Transformer Encoder 中,它在图像分类上的表现就能击败霸占 CV 领域多年的卷积神经网络(CNN,如 ResNet)。
这种跨模态的通用性,证明了 Transformer 的自注意力机制实际上学习到的是一种通用的信息聚合模式,无论输入是文字、像素块,还是音频波形,它都能找到其中的内在关联。
从专用工具到通用计算引擎
Transformer 的意义已经远远超越了“一个好用的 NLP 模型”。它正在演变为一种类似于 CPU 架构一样的通用计算范式。从 ChatGPT (文本) 到 Sora (视频),从 AlphaFold3 (生物蛋白质) 到具身智能 (机器人控制),Transformer 正在重塑整个人工智能的版图。
Transformer 的局限与 AI 的未来
从 2017 年的《Attention Is All You Need》到如今参数量动辄数千亿的 GPT-4、Claude 3,Transformer 毫无疑问已经封神。它优美的数学结构、极强的并行计算能力,完美契合了现代 GPU 的脾气,掀起了大模型时代的狂欢。
然而,当我们试图让模型阅读整本百万字的小说,或者处理超长视频时,Transformer 却露出了它最致命的软肋。
平方级诅咒
在第 2 章中我们讲过,自注意力机制的核心是:序列中的每一个词,都要和其他所有的词计算一次注意力分数。
如果在序列长度(Context Length)比较短时(比如 1000 个词),这不算什么。但如果你想输入 10 万个词,计算量的增长不是线性的,而是平方级 (Quadratic) 的!这意味着序列长度增加 10 倍,计算量和显存占用会暴涨 100 倍。这被称为大模型的“上下文窗口瓶颈”。
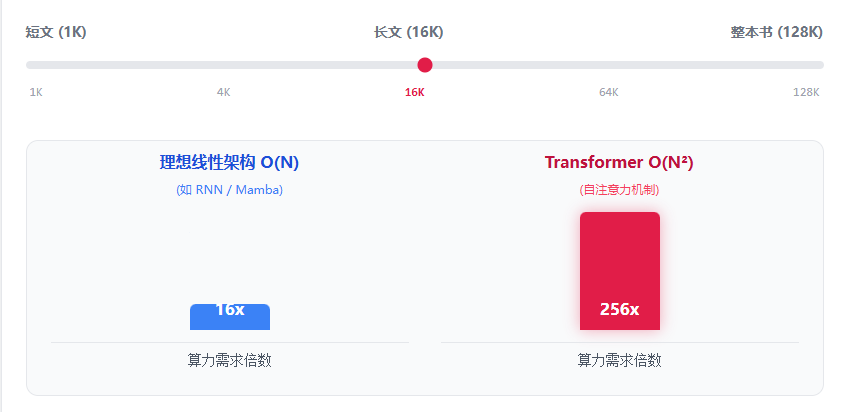
当你把输入长度从 1K 扩展到 128K(约等于一本长篇小说)时,序列长度增加了 128 倍。 但对于 Transformer 而言,它需要计算的注意力矩阵大小暴涨了 16,384 倍!这就解释了为什么支持超长上下文的模型在推理时极其昂贵。
FlashAttention 与 MoE
面对昂贵的算力账单,AI 研究员和工程师们并没有坐以待毙。在 Transformer 框架内部,诞生了许多天才般的工程优化:
-
FlashAttention (硬件级优化): 传统的注意力机制需要把巨大的
分数矩阵读写到 GPU 显存(HBM)中。FlashAttention 利用底层 CUDA 编程,对矩阵进行分块(Tiling)计算,将其全部塞在 GPU 极其高速但极小的 SRAM 缓存中完成,直接将计算速度飙升了数倍,同时大幅降低了显存占用。

-
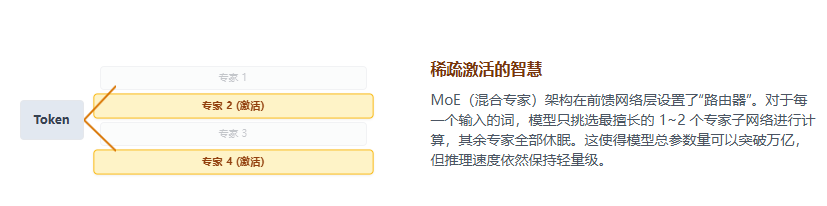
混合专家架构 (MoE, Mixture of Experts): 既然每次生成一个词不需要动用所有神经元,不如把 FFN 层拆分成多个“专家”。每次推理只激活相关的 1~2 个专家。这让我们可以训练极其庞大的模型(如 GPT-4 的上万亿参数),而每次推理的计算成本只相当于一个小模型。
RNN 的复兴与 SSM
虽然 Transformer 被各种“魔改”优化,但 的物理定律始终存在。于是,学术界开始寻找能在数学原理上实现
线性复杂度 的全新架构。这其中最著名的就是 状态空间模型 (State Space Models, SSM) 和 Mamba。

结语:Attention Is All You Need?
2017 年的那篇论文标题极其狂妄——《Attention Is All You Need》。而在随后的 7 年里,它竟然真的兑现了它的狂言,带领人类触摸到了通用人工智能(AGI)的门槛。
尽管我们在这期博客的最后探讨了它的诸多缺陷和新兴的挑战者,但 Transformer 留给我们的财富绝不仅仅是一个具体的公式。它向我们证明了:简单、统一的架构架构,配合海量的数据与算力,能够涌现出超越人类设计的复杂智能。
“机器的觉醒,源于对周围世界的『注意力』。”
— 感谢您阅读本博客,祝您在 AI 时代乘风破浪!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)