解锁大模型长上下文推理(非常详细),LoongRL核心技术从入门到精通,收藏这一篇就够了!
这篇论文主要探讨了如何让大语言模型在长文本场景下具备更强的逻辑推理能力。通常情况下,模型处理长文档更多依赖检索(Retrieval),而在复杂推理(Reasoning)上往往表现不足。微软亚洲研究院的研究者们通过一种名为 LoongRL 的强化学习框架,尝试填补这一空白。
研究的核心在于设计了一套名为 KeyChain 的合成数据,形象地说,就像是在长文中布置了一场“寻宝游戏”,强迫模型在训练过程中学会“规划、检索、推理、反思”的一整套思维链条。这种方法最显著的优势在于极高的性价比:模型只需在 16K 的长度上进行训练,就能将习得的推理能力泛化到 128K 甚至更长的上下文中。
实验结果也相当令人振奋,7B 和 14B 参数量的中小模型在应用此方法后,在多个长文本推理基准测试中取得了与 GPT-4o、o3-mini 等顶级模型相当的成绩。这项工作不仅证明了小模型在长窗口任务上的潜力,也为低成本解决长文本推理问题提供了一个值得借鉴的新范式。

第一章:引言 (Introduction)
现在的“推理模型”(Reasoning Models)如 OpenAI 的 o1 和 DeepSeek-R1 确实火了一把,让大家看到了强化学习(RL)在激发模型 Chain of Thought (CoT) 方面的巨大潜力。但你有没有发现,这些模型“顿悟”的时刻,大多发生在短上下文的场景里,比如解一道数学题或者写一段代码,它们更多依赖的是模型“肚子里”的内隐知识(Internal Knowledge)。
可是,真实世界里大量的工作——比如读几百页的法律文档、给庞大的代码库改 Bug——是需要模型盯着外部输入的长文本(External Input Contexts)来看的。光靠“检索”(Retrieval)找到信息是不够的,还得基于这些信息进行复杂的推理。这就引出了这篇论文的核心痛点:我们如何让模型在长达 128K 甚至更长的上下文中,不仅能“找到”信息,还能像处理短文本一样聪明地“思考”?
我们先来聊聊背景。现在的 LLM 都在卷上下文长度(Context Window),动不动就支持 100K、1M 甚至更多。虽然模型能“吃”进去这么多数据,但它们真的“消化”了吗?
作者在开篇就犀利地指出:目前的模型在长文本上,主要还是在做“检索”(Retrieval),而不是“推理”(Reasoning)。
作者的思路很清晰:既然 RL 在短文本上能通过激发 CoT 带来性能飞跃(DeepSeek-R1, OpenAI o1),那我们是不是可以用同样的思路,通过 RL 去发掘长文本场景下特有的“思维模式”(Thinking Patterns)?
想法虽好,但落地极难。作者列举了横在面前的三座大山,这其实也是目前长文本研究领域的共识痛点:
数据的“不可能三角”:
有效的 RL 训练通常依赖 Outcome-based Reward(结果奖励)来避免 Reward Hacking。这就要求题目必须具备三个苛刻条件:
•
难度够高:不能是靠简单检索就能做对的,必须触发推理。
•
依赖长文:推理过程必须依赖长输入,不能靠模型瞎编。
•
答案确定:必须有标准答案方便验证。
现实中,这种高质量的“长文本推理题”极度稀缺(Extremely Scarce)。
算力成本的“天价”:
长文本推理通常需要在接近目标长度的语境下训练。在短文本(<1K tokens)上跑 RL 还可以接受,但在 128K tokens 的长度上跑 RL Rollouts?那个显存和计算成本(Compute and Memory Costs)是普通实验室甚至大厂都难以承受的。
能力的“跷跷板”:
就算你有钱有数据,只在长文本上训练,很容易导致模型“捡了芝麻丢了西瓜”——灾难性遗忘(Catastrophic Forgetting),把短文本处理能力和通用推理能力给搞丢了。
针对上面这些问题,作者提出了本文的主角——LoongRL。
这是一个数据驱动的 RL 方法,核心在于它是怎么构造数据的。作者提出了一个非常有意思的数据合成方法,叫 KeyChain(关键链)。
此外,为了防止 RL 里的 Reward Hacking(模型刷分),作者还设计了一个 Rule-based Answer Verifier(基于规则的答案验证器),采用 two-way substring exact match(双向子串精确匹配),这比单纯的字符串匹配更鲁棒,能处理 free-form(自由格式)的回答。
在 KeyChain 数据上跑完 RL 后,作者观测到了一个非常漂亮的现象——模型涌现出了一种特定的思维模式(Emergent Pattern),作者将其总结为:
Plan – Retrieve – Reason – Recheck
(规划 – 检索 – 推理 – 反思)
•
Plan:先把大问题拆解。
•
Retrieve:去长文里找证据。
•
Reason:基于证据做推断。
•
Recheck:自己检查一遍对不对。

更令人兴奋的是,这种能力具有极强的泛化性(Generalization)。
虽然训练是在 16K 的长度上进行的,但训练出来的模型在 128K 的任务上依然表现出色!这就完美解决了前面提到的“算力成本”问题——我们不需要在 128K 上做 RL,只要在 16K 上练好“内功”,它自己就能应用到更长的场景里。
最后看看效果,作者在 Qwen2.5-7B 和 14B 上验证了 LoongRL:
•
涨点显著:在长文本多跳 QA 任务上,准确率分别提升了 +23.5% 和 +21.1%。
•
越级挑战:LoongRL-14B 最终得分 74.2。这个分数是什么概念?它几乎追平了庞然大物 OpenAI o3-mini (74.5) 和 DeepSeek-R1 (74.9)。
•
全面发展:不仅长文本推理强了,长文本检索(NIAH 测试)全过,而且短文本能力也没丢(通过 Balanced Data Mixing 策略)。
本章小结
第一章主要立论:长文本推理 \neq 长文本检索。现有的 RL 方法(如 o1)在长文本场景下缺位。作者通过 LoongRL 填补了这一空白,核心创新在于 KeyChain 数据合成方法,它成功地在低成本(16K 训练)下激发出模型通用的长文本推理模式(Plan-Retrieve-Reason-Recheck),让小模型(14B)也能在长窗口推理上硬刚最顶尖的大模型。
第二章:相关工作 (Related Works)
在深入 LoongRL 的技术细节之前,我们需要先环顾四周,看看这个领域里其他的玩家都在做什么。简单的说,现在的 LLM 发展有两条明显的“技能树”:一条是推理(Reasoning),像 o1 和 DeepSeek-R1 那样通过“慢思考”解决复杂问题;另一条是长上下文(Long Context),像 Kimi 或 Claude 那样能读完一整本书。本章的核心议题是:这两条技能树目前是割裂的,谁能把它们合二为一? 也就是实现真正的“长文本推理”。
最近大语言模型(LLM)推理能力的爆发,主要归功于高质量的思维链(Chain of Thought, CoT)。
目前获取 CoT 主要有两种流派:
•
蒸馏派(Distillation):通过更强的教师模型(Teacher Model)生成数据来教学生模型(Yang et al., 2025)。
•
自学派(RL / Self-generation):通过强化学习让模型自己探索,涌现出自我反思(Self-reflection)的能力(Guo et al., 2025)。
⚠️ 现存问题:
这些研究绝大多数都集中在短上下文(Short-context)任务上,比如数学题(Math)和代码生成(Code)。在这些任务中,模型更多依赖的是“内功”(训练时记住的知识),而不是“眼力”(从外部长文中获取信息)。
虽然有一些工作(如 Yen et al., 2024)尝试用 Prompting 技术来激发长文推理,但这受限于基座模型本身的能力天花板;另一些尝试用合成数据进行微调(SFT),但这往往会引入噪声和偏见。
🌟 值得关注的先行者:QwenLong-L1
作者特别提到了 QwenLong-L1 (Wan et al., 2025)。这是一个值得尊敬的尝试,它扩展了 R1-distill-Qwen-32B,在长达 60K tokens 的序列上进行了 RL 训练,鼓励模型探索长距离的推理路径。
但也留下了遗憾:它虽然迈出了这一步,但并没有解决最核心的问题——如何设计高质量的 RL 训练数据? 这正是 LoongRL 想要回答的问题。
要训练长文本模型,数据是老大难。目前主流的数据合成方法(Long-Context Synthetic Data)通常比较简单粗暴:
“注水法”(Padding / Document-filling):
拿现成的短文本问答数据集(如 HotpotQA, MuSiQue),然后在里面塞进去一大堆无关的文档(Irrelevant Documents)。
作者认为,现有的合成数据虽然提升了长度,但在生成高质量、高挑战性(High-quality, Challenging)的训练数据方面,依然捉襟见肘。
本章小结
本章梳理了长文本推理的研究现状。虽然 RL 在短文本推理上已经取得了巨大成功(如 DeepSeek-R1),但在长文本领域的应用还处于起步阶段。现有的数据合成方法大多只是简单地增加无关文档(“物理加长”),而未能提供足够的逻辑挑战(“化学增强”)。这为 LoongRL 的提出——特别是其核心的 KeyChain 数据构造方法——提供了完美的切入点。
第三章:方法论 (Methodology)
这一章是整篇论文的“灵魂”。作者到底用了什么魔法,让模型在 16K 的训练长度下,就能学会 128K 的推理能力?答案就在于两个核心组件:一个是精心设计的数据构造方法 KeyChain,另一个是适配长文本的强化学习策略。
核心思想其实非常直观,甚至有点像是在设计一个“寻宝游戏”。作者并没有堆砌复杂的数学模型,而是通过巧妙的数据工程(Data Engineering)和务实的奖励设计(Reward Design)解决了长文本 RL 训练难、贵、不稳定的问题。
3.1. KeyChain 数据构造:给模型设计个“寻宝游戏”
还记得我们在引言中提到的“不可能三角”吗?我们需要既难、又依赖长文、还有标准答案的数据。作者提出的解法叫做 KeyChain (关键链)。
核心理念:把问题“藏”起来
普通的问答(QA)是直接把问题扔给模型:“请问文章里提到的小明今年几岁?”
而 KeyChain 的逻辑是:我不直接问你问题。我给你一堆线索,你要自己顺藤摸瓜找到真正的问题,然后再回答。
具体是怎么造出来的?(Step-by-Step)
作者制定了三条原则:
真实性 (Reliability,基于真实 QA 数据):数据源必须来自真实世界的问答(如 HotpotQA, MuSiQue),以防止合成数据常见的幻觉问题。
全长依赖 (Full Context Dependency,必须读完全文):解题过程必须依赖对长上下文的完整理解,而不是靠模型内部知识(Internal Knowledge)或简单的直接检索(Direct Retrieval)。
挑战性 (Challenge,逼出推理能力):难度必须足够高,不能让模型一眼看穿,这样才能在 RL 训练中提供足够的梯度信号。
整个构造过程就像是在“加密”一个普通的问题,详见原文 Figure 2:
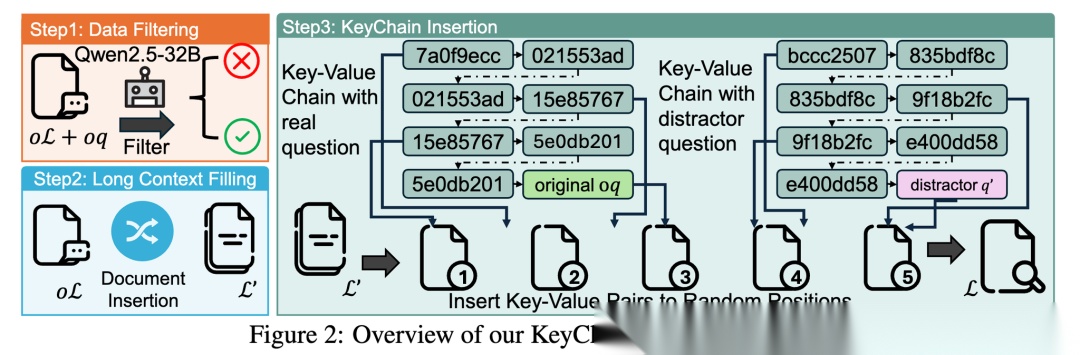
Step 0: 种子数据筛选 (Seed Dataset Curation)
不是所有的问答都适合拿来训练。作者从 HotpotQA, MuSiQue, 2WikiMultiHopQA 中选取了 277K 个原始问答对 o L _ i , o q _ i , o a _ i {oL\_i, oq\_i, oa\_i} oL_i,oq_i,oa_i。
•
筛选策略:使用 Qwen2.5-32B-Instruct 对这些题进行测试,每个题答 8 次。
•
去两头,留中间:剔除掉那些全对(Pass rate=1,太简单)或全错(Pass rate=0,太难或有错)的题目,只保留适中难度的 72K 条数据。
Step 1: 上下文“注水” (Context Extension)
为了模拟真实世界的长文档(往往包含大量无关信息),作者将原始的短上下文 oL_i 扩展到 16K tokens。
•
干扰项来源:为了保证干扰的真实性,作者从那 200K 个被剔除的问答任务中抽取文档作为干扰项(Distractors)。
•
严谨性:确保干扰文档与原始文档没有任何重叠,纯粹是为了增加检索难度。
Step 2: 埋藏“关键链” (KeyChain Insertion)
这是最精彩的一步。作者在长文中插入了一系列 Key-Value 键值对,形成“链条”。
•
链条结构: K e y t o V a l u e ( N e x t K e y ) Key to Value (Next Key) KeytoValue(NextKey)。每个 Key 都是一个 32 位的 UUID 字符串(由 0-9 和 A-F 随机组成,例如 7a0f9ecc…),确保全局唯一且无法通过语义猜测。
•
真假链条:
◦
真链条 (Target Chain):沿着线索走到底,Value 会指向原始问题 (Original Question) o q _ i oq\_i oq_i。
◦
假链条 (Distractor Chains):文中还混入了大量干扰链条,它们最终指向的是从其他数据集随机抽取的干扰问题 (Distractor Questions)。
◦
随机打散:这些 Key-Value 对被打散并随机插入到 16K 的文档中,模型必须像拼图一样把它们找出来。
Step 3: 提出新问题 (New Question Construction)
原来的问题 oq_i 已经被藏在链条尽头了。现在,作者给模型一个新的指令 q _ i q\_i q_i:
“请找到从 [Start UUID] 开始的链条所隐藏的问题,并回答它。”
3. 为什么这样设计有效?
通过这种设计,模型面对的不再是一个简单的 QA 任务,而是一个被迫的 多阶段推理过程:
定位 (Localize):首先在 16K 的大海中找到起始 Key。
追踪 (Trace):顺着 UUID 一步步跳转(Multi-hop),直到解码出真正的问题。注意,如果模型偷懒随便找个问题回答,很可能会撞上那堆“干扰问题”而导致任务失败。
推理 (Reason):拿到真正的问题后,结合原始文档进行长文本推理。
这就逼迫模型不能偷懒,必须在长文中进行复杂的逻辑游走。
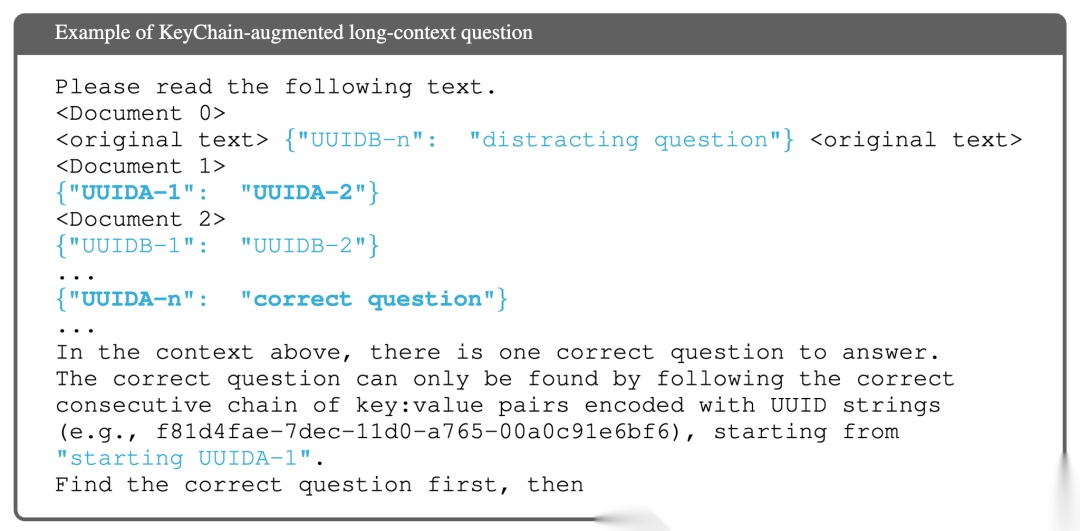
4. 涌现的长文本推理模式 (Emergent Long-Context Reasoning Patterns)
原文中特别提到了一个令人惊讶的发现:使用 KeyChain 数据进行强化学习训练,能让模型涌现出类似人类的长文本推理模式 (Emergent, human-like long-context reasoning patterns)。
正如原文 Fig. 1(a) 所示,面对一个长文本 QA 任务,模型表现出了非常结构化的思考过程:
•
制定计划 (Explicit Plan):首先生成一个明确的计划,将大问题分解为子问题和子步骤。
•
分步检索 (Retrieve):为每一步检索相关信息。
•
主动反思 (Actively Re-check):在不确定时,会主动重新检查检索到的内容,然后再继续。
这种 Plan-Retrieve-Reason-Recheck 的循环,带来了高度逻辑化和可靠的解决方案。
此外,这种推理模式甚至改进了传统的长文本检索任务。在 Appendix A.5 的 RULER vt benchmark 案例中,模型不再像传统检索那样直接跳到答案,而是进行一步步、人类可读的检索 (Step-by-step, human-readable retrieval),逐步定位正确答案。
核心亮点:从 16K 到 128K 的泛化
最重要的一点是,这种在短上下文 (16K tokens) 上学到的“规划-检索-推理-反思”行为,能够泛化到更长的上下文 (up to 128K tokens)。这意味着我们可以在 16K 序列上训练,同时保持强大的超长上下文性能,极大地体现了 KeyChain RL 方法的鲁棒性和可扩展性。
3.2. 长文本强化学习:如何低成本训练?
有了数据,接下来就是怎么练(Training)。长文本 RL 训练非常昂贵,作者在这里做了一系列极具性价比的工程决策。
3.2.1 算法选型:GRPO
作者选择了 Group Relative Policy Optimization (GRPO)。
熟悉 DeepSeek-R1 的朋友对这个词肯定不陌生。相比于传统的 PPO,GRPO 省去了 Value Model(Critic),直接通过一组采样(Group Sampling)来计算优势(Advantage),这大大节省了显存。
目标函数公式如下:
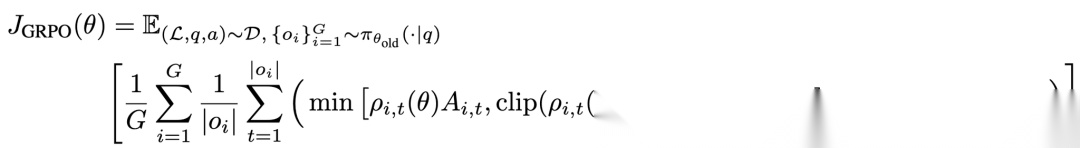
这里有一个细节:作者设置了很小的 KL 惩罚 b e t a = 0.001 beta = 0.001 beta=0.001,并且移除了熵正则项(Entropy Loss)。
注意:通常熵正则项是为了鼓励探索,但在长文本场景下,它容易导致熵不可控地增长,导致训练不稳定。去掉它是一个根据实践得出的重要 trick。
3.2.2 奖励设计:拒绝 LLM-as-a-judge
怎么给模型的回答打分?
•
数学题:容易,答案唯一。
•
长文问答:难,答案是开放的(Free-form)。
通常的做法是用另一个 LLM 当裁判(LLM-as-a-judge),但这对长文本来说太奢侈了——你训练一个 128K 的模型,还得跑一个 128K 的裁判模型?
作者提出了一个朴实无华但极其有效的 Rule-based Reward(基于规则的奖励):
格式约束:强行要求模型把答案写在 \boxed{} 里。
双向子串精确匹配 (Two-way substring exact match):
不要求 100% 一模一样。只要:
•
预测答案 \subseteq 标准答案
•
或者 标准答案 \subseteq 预测答案
就算对!
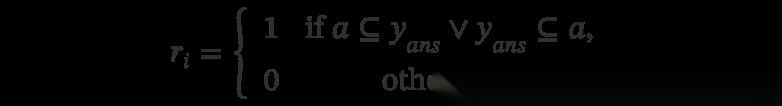
💡 思考
这个设计非常聪明。它容忍了模型多说几个字或者少说几个字,只要核心信息对上了就行。这在保证了评估效率(计算极快)的同时,避免了传统 Exact Match 过于死板的问题。
3.2.3 训练配方:混合数据与三阶段策略 (Training Recipe)
如果说 KeyChain 是“食材”,GRPO 是“炉灶”,那么这一节就是具体的“烹饪菜谱”。作者的目标很明确:既要练成长文本推理的“绝世武功”,又不能丢了短文本的基础能力(General Abilities)。
为此,作者制定了两条核心策略:混合数据集 (Data Mixing) 和 三阶段训练 (Multi-Stage Training)。
- 混合数据集:营养均衡不偏科
为了防止模型练了长文本就忘了短文本(灾难性遗忘),作者构建了一个包含四类数据的“营养套餐”:
| 数据类型 | 数量 | 长度范围 | 难度 | 作用 (Role) |
| KeyChain Data | 7,500 | ~16K | Hard | 主菜。包含 HotpotQA, MuSiQue 等数据集的 KeyChain 变体。专门用来逼出“Plan-Retrieve-Reason”的思维模式。 |
| Medium QA | 7,500 | ~12K-16K | Medium | 副菜。标准的多跳 QA。对于像 7B 这样的小模型来说,KeyChain 太难了,需要这类中等难度题目过渡一下。 |
| Needle Retrieval | 1,024 | ~16K | Varies | 维生素。纯粹的“大海捞针”任务。保持模型在长文中精准定位信息的能力。 |
| Math Data | 5,000 | <1K | Mixed | 甜点。短文本数学题(DAPO & MATH)。防止模型变成“只会读长文的傻子”,保持通用的逻辑推理能力。 |
关键决策
作者特意选择在 16K 的长度上进行训练,而不是直接上 128K。这是一个极其务实的 trade-off:用 16K 的成本练出逻辑,然后泛化到 128K。 事实证明这完全可行。

- 三阶段训练:循序渐进,专攻错题
一口吃不成胖子,作者设计了一个三阶段的课程表(Curriculum):
•
阶段 0:热身 (Warm-up)
◦
内容:除了 KeyChain 以外的所有数据。
◦
目的:先让模型把检索(Retrieval)和基础推理练熟。如果一上来就给 7B 模型看 KeyChain 这种“天书”,模型可能会直接崩盘(Optimization instability)。
◦
注:14B 模型底子好,直接跳过此阶段。
•
阶段 I:进阶 (KeyChain Augmentation)
◦
内容:加入 KeyChain 数据。
◦
目的:正式上强度。逼迫模型学会规划、检索、整合证据链。
•
阶段 II:攻坚 (Difficulty-focused Training)
◦
策略:“错题本”策略。
◦
做法:对每个问题生成 8 个回答(Rollouts)。
▪
如果 8 个全对 \rightarrow 简单题,扔掉不练。
▪
如果有错 \rightarrow 难题,保留下来重点练。
◦
效果:这样筛选下来,只剩下 30%-40% 的高难度数据。这不仅节省了计算资源,还避免了模型在已经会的题目上“过拟合”(Over-fitting)。
- 训练参数 (Training Setup)
对于技术党,这里还有一些硬核参数供参考:
•
显卡:7B 模型用了 16 张 A100,14B 模型用了 8 张 MI300X。
•
Rollout 配置:Temperature = 0.6, Top-p = 0.95。
•
学习率:1e-6。
本章小结
第三章详细阐述了 LoongRL 的核心方法论,可以概括为"数据 + 算法 + 训练配方"三位一体:
•
KeyChain 数据构造:通过"改写-切分-打散-拼接"四步法,将传统 QA 数据集改造成需要多跳推理的长文本挑战。这是 LoongRL 能够激发模型"Plan-Retrieve-Reason"思维模式的关键。
•
GRPO 强化学习算法:采用 Group Relative Policy Optimization,通过组内排名奖励(而非绝对分数)来引导模型学习。配合巧妙的基于规则的奖励函数(双向子串匹配),既高效又准确。
•
混合数据与三阶段训练:在 16K 长度上训练,混合 KeyChain、Needle、Math 等多类数据,通过"热身-进阶-攻坚"三阶段课程式学习,既练就了长文本推理能力,又保持了短文本的通用能力。
核心洞察:LoongRL 的成功不是靠"暴力堆数据"或"盲目拉长上下文",而是通过精心设计的数据增强和高效的强化学习,让模型学会了一种可泛化的推理范式。这种范式在 16K 上训练,却能无缝迁移到 128K 甚至更长的上下文中。
第四章:实验 (Experiments)
这一章是 LoongRL 的“验金石”。作者不仅要证明这个方法“有效”(能做长文推理),还要证明它“高效”(用小模型打败大模型),更要证明它“鲁棒”(长文强了,短文也没变弱)。
让我们看看 LoongRL 是如何在 Qwen2.5 的基础上,上演一场“以小博大”的精彩好戏。
4.1. 实验设置:角斗场与参赛者 (Setup)
首先,我们来看看这场“比武招亲”的擂台设置。
1. 参赛选手 (Models)
作者选取了两个不同量级的模型作为基座(Base Model):
•
Qwen2.5-7B-Instruct:轻量级选手。
•
Qwen2.5-14B-Instruct:中量级选手。
这也暗示了作者的野心:如果能在 7B/14B 这种尺寸上跑通长文本推理,那其实际应用价值将远超那些 70B+ 的巨无霸。
2. 强劲对手 (Baselines)
为了证明含金量,作者找来的对比对象个个都是“狠角色”:
•
顶级闭源模型:OpenAI o3-mini, GPT-4o。
•
顶级开源推理模型:DeepSeek-R1, QwQ-32B。
•
长文本竞品:QwenLong-L1-32B, R1-Distill-Qwen 系列。
3. 训练细节 (Training Details)
•
算法:GRPO (Group Relative Policy Optimization)。
•
上下文长度:16K(敲黑板!训练只用了 16K,但测试要测到 128K)。
•
计算资源:
◦
7B 模型:16 张 A100 GPU。
◦
14B 模型:8 张 MI300X GPU。
观察
这个计算资源相对来说是非常亲民的。相比于动辄几千张卡预训练,或者几百张卡做长文本微调,LoongRL 的训练成本可以说非常低。
4.2. 核心战绩:以小博大 (Main Results)
实验结果可以说是全方位的胜利,作者总结了三个维度的表现。
1. 长文本推理:越级挑战 (Competitive at smaller scale)
这是本论文最核心的指标。数据来自 LongBench 等权威榜单。
•
惊人的 7B:LoongRL-7B 拿到了 72.4 分。
◦
对比:这个分数直接碾压了 QwenLong-L1-32B (70.1),甚至比 R1-Distill-Qwen-32B (65.5) 还要高一大截。
◦
含义:一个 7B 的小模型,通过正确的 RL 训练,在长文推理上干掉了比它大 4 倍的模型。
•
强悍的 14B:LoongRL-14B 拿到了 74.2 分。
◦
对比:这个分数已经和 DeepSeek-R1 (74.9) 以及 o3-mini (74.5) 处于同一梯队了。
◦
含义:LoongRL 让 14B 模型拥有了媲美顶级闭源模型的长文推理能力。
❓ 为什么 R1-Distill 系列表现不佳?
作者发现,直接用 DeepSeek-R1 的数据蒸馏(Distillation)出来的模型(如 R1-Distill-Qwen),在长文本任务上表现并不好,甚至有退化(-17.7%)。
核心洞察:DeepSeek-R1 的训练数据主要集中在短文本推理(数学/代码),它并没有针对“长文本检索+推理”的模式进行优化。 这再次证明了 KeyChain 数据的独特价值。
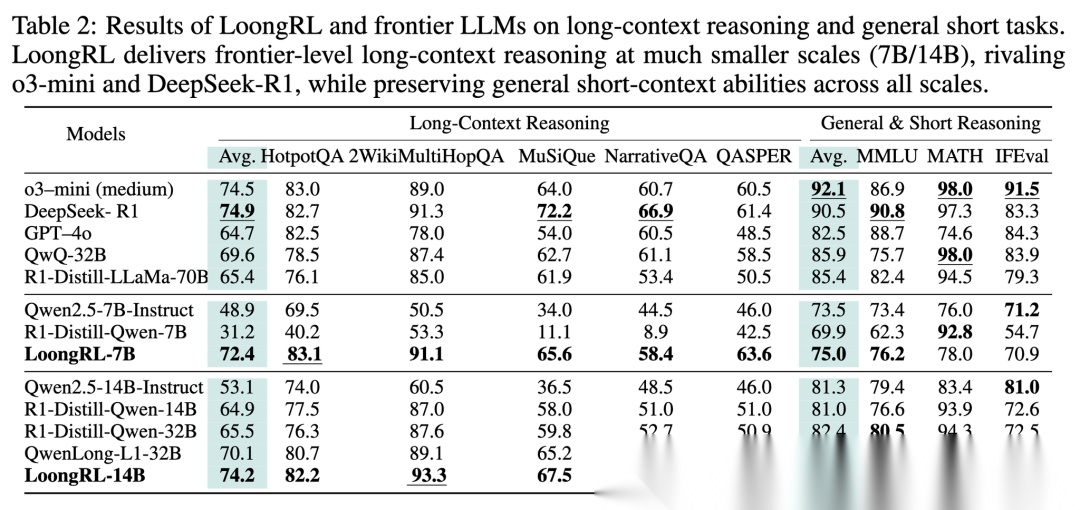
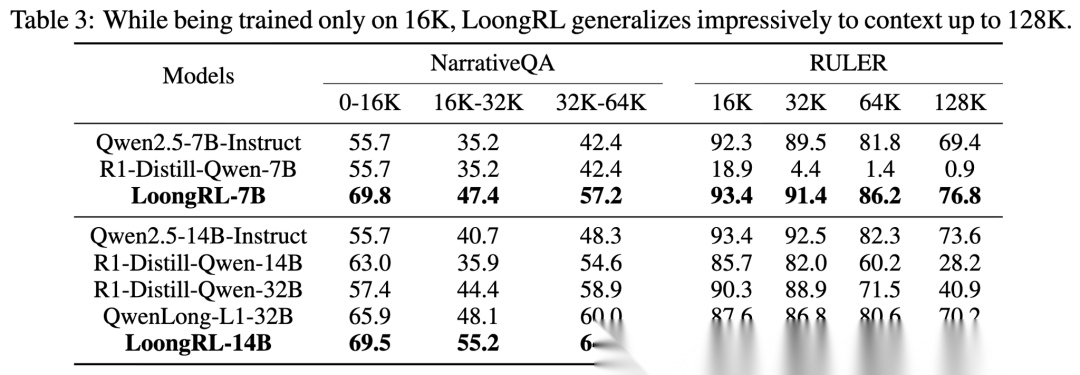
2. 泛化能力:举一反三 (Generalize better to long)
LoongRL 最让人惊喜的一点是它的泛化性。
•
训练:只看了 16K 长度的文本。
•
测试:在 128K 长度的 RULER 测试中,LoongRL-7B 依然保持了 93.4 (16K) -> 76.8 (128K) 的高分。
•
对比:作为对比,普通的 SFT 模型或者 R1 蒸馏模型,随着长度增加,性能呈现断崖式下跌(Degrade sharply)。
核心观点
这说明模型学到的不是简单的“在第几行找答案”,而是一种通用的“Plan-Retrieve-Reason”思维范式。这种范式与文本长度无关,因此可以无缝迁移到更长的上下文中。
3. 短文本能力:不仅没丢,反而更强 (Near-lossless short reasoning)
做长文本最怕的就是“捡了芝麻丢了西瓜”。但 LoongRL 甚至在短文本上也涨点了!
•
MMLU:提升 +2.8% (7B)。
•
MATH:保持高水准。
这得益于我们在第三章提到的“混合数据策略”(Data Mixing),让模型在修炼长文内功的同时,也没落下基础知识。
4.3. 消融实验:缺一不可 (Ablation Study)
为了证明每个组件都在起作用,作者做了详细的消融实验。
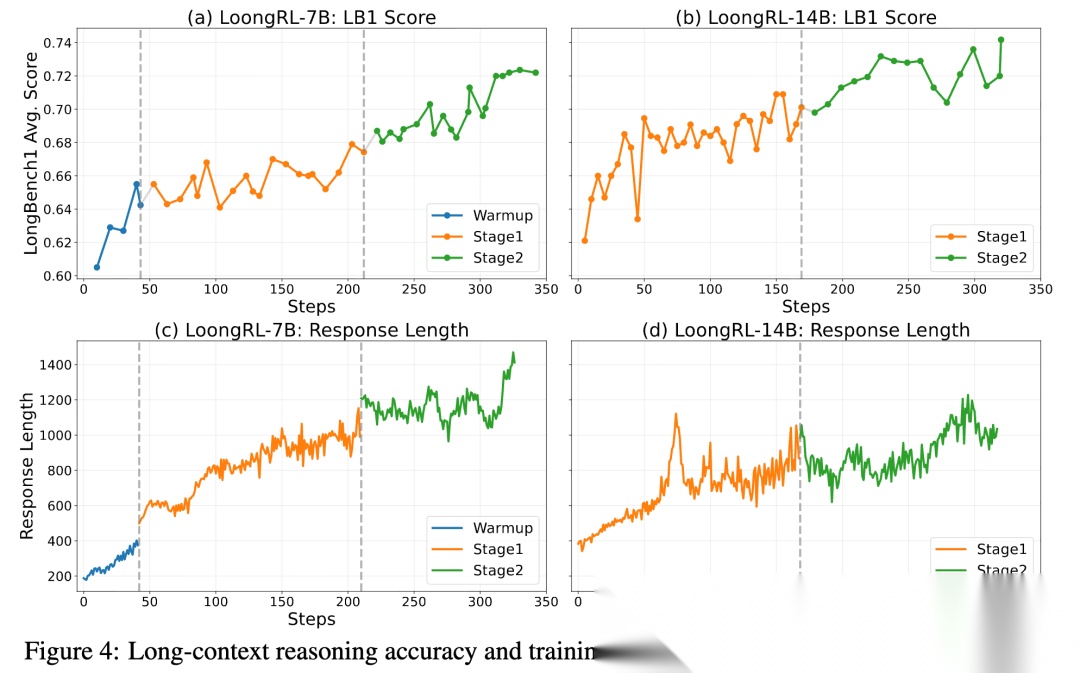
1. 多阶段 RL 训练维持改进 (Multi-stage RL training sustains improvements)
为了探究 LoongRL 如何获得强劲的性能,作者展示了 7B 和 14B 模型在三个 RL 阶段的逐步增益。
•
准确率提升:如原文 Fig. 4 (a,b) 所示,长文本推理准确率在每个阶段(Warm-up -> Stage I -> Stage II)都保持持续增长。
•
思考变长:如原文 Fig. 4 (c,d) 所示,平均回答长度(Response Length)在训练过程中稳步增加。这说明模型在课程学习的引导下,正在学会进行越来越深入的思考。
这充分证明了多阶段 RL 课程设计的有效性。
2. KeyChain 数据真的有用吗?
作者尝试把 KeyChain 数据换成普通的 Long-context QA 数据。
•
结果:分数从 72.4 掉到了 66.2。
•
结论:普通的 QA 数据只能教模型做简单的阅读理解,只有 KeyChain 这种复杂的“寻宝游戏”,才能逼出模型深层次的推理规划能力。

3. 为什么要用双向子串匹配?
作者对比了三种奖励计算方式:
Exact Match (完全匹配):太严格,模型少写个标点就判错,效果最差。
LLM-as-a-judge (用大模型打分):效果不错,但太慢太贵。
Two-way Substring (双向子串):本文方法。
•
效果:不仅计算飞快,而且最终训出来的模型效果最好(72.4 分)。
•
结论:在 RL 中,Reward 的“宽容度”和“准确度”同样重要。 过于苛刻的 Reward 会打击模型的探索积极性。

本章小结
第四章用扎实的实验数据为 LoongRL 正名。实验结果传递了三个极其积极的信号:
小模型大有可为:7B/14B 模型在长文推理上完全可以挑战 32B 甚至 70B 的模型。
RL > Distillation:在长文本这个特定领域,针对性的 RL 训练比盲目蒸馏通用的 CoT 数据更有效。
泛化是关键:通过 KeyChain 习得的思维模式,让模型突破了训练长度的物理限制,实现了低成本的长文本能力扩展。
第五章:结论 (Conclusion)
这篇论文提出了 LoongRL,这是一种数据驱动的强化学习方法(Data-driven Reinforcement Learning Approach),专门用于解决长上下文推理(Advanced Long-context Reasoning)的难题。
回顾全篇,它的成功建立在一个核心基石之上:KeyChain 数据集。
❓ 为什么 KeyChain 这么重要?
作者通过 KeyChain,把普通的、模型看一眼就能答对的多跳问答(Multi-hop QA),强制转化成了高难度任务(High-difficulty Tasks)。这就像是把“开卷考试”变成了“寻宝游戏”,逼迫模型不能只靠“翻书”(检索),而必须学会“思考”。
作者在结论中再次点出了模型在训练过程中涌现出的独特思维模式:
“Plan - Retrieve - Reason - Recheck”
(规划 - 检索 - 推理 - 反思)
这不仅仅是一个流程,更代表了模型认知能力的质变。它不再是一个简单的“文本匹配器”,而变成了一个具备主动规划能力的智能体。
这可能是这篇论文最具有工业界价值的一个发现:
这种涌现出的推理能力,具有极强的泛化性(Generalizes Remarkably Well)。
•
训练:模型仅仅是在 16K token 的上下文长度上训练的。
•
推理:模型却能有效地解决长达 128K tokens 的任务。
这意味着我们不需要为了长文本推理去烧那一千倍的显存。只要方法对,小窗口里也能练出大智慧。
•
分数:LoongRL-14B 模型在长文本 QA 基准测试中拿到了 74.2 的高分。
•
对手:这个成绩足以让它与 o3-mini 和 DeepSeek-R1 这样的大体量前沿模型(Frontier Models)分庭抗礼。
•
无损:更重要的是,这种长文本能力的提升,并没有以牺牲短文本能力为代价。模型成功保留了关键的短上下文推理和检索能力(Short-context Reasoning and Retrieval Capabilities)。
LoongRL 证明了通过构建高质量的合成数据(KeyChain),配合低成本的 RL 训练,我们完全可以在中小参数模型(7B/14B)上实现顶级的长文本推理能力。这打破了“长文本推理=昂贵计算”的刻板印象,为未来的 Agent 和长文档分析应用开辟了一条极具性价比的新路。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)