多线程---线程安全和锁
(一).线程安全
一段代码,如果在多线程并发执行的情况下,出现bug,就称为“线程不安全”,反之,如果没有bug,就是“线程安全”
(二).引入
private static int count=0;
public static void main(String[] args) throws InterruptedException {
Thread thread1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
Thread thread2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
thread1.start();
thread2.start();
System.out.println(count);
}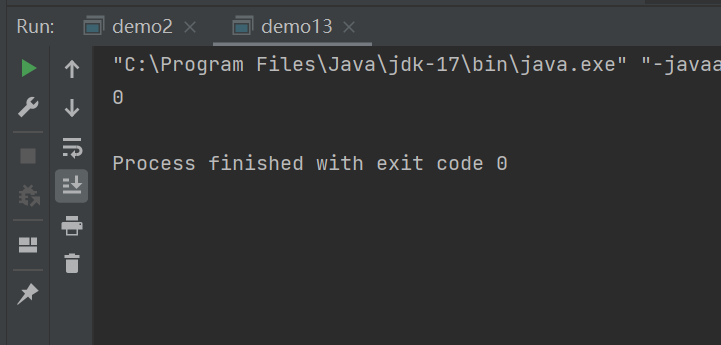
我们的预期结果count=100000,因为两个线程中分别对count++了50000次,所以一共就是100000次,但当运行的结果为0,我们就能意识到,在main线程中先执行了System.out.println(count); 这是因为线程是并发执行的,调度是随机的,当thread1 和 thread2开始执行的时候,已经打印完了所以输出0
那么我们可以通过 join()方法,在main线程中分别执行 thread1.join() 和 thread2.join(),意味着main线程要等到 thread1 和 thread2 线程都结束之后 main线程才能结束
private static int count=0;
public static void main(String[] args) throws InterruptedException {
Thread thread1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
Thread thread2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(count);
}此时就会出现两种情况
1.thread1先结束,thread2后结束
main线程先在thread1.join()中阻塞等待,thread1结束,main线程再在 thread2.join()中阻塞等待,thread2结束,main线程继续执行,然后打印,最终打印的值就是thread1和thread2都执行完的值
2.thread2先结束,thread1后结束
main线程先在thread1.join()中阻塞等待,thread2结束,main线程在thread1.join()中继续阻塞等待,thread1结束,thread.join()继续执行,main执行到 thread2.join(),由于thread2 已经结束了,此时thread2.join()是不会阻塞的,main线程继续执行后续的打印,最终打印的的就是thread1和thread2都执行完的值
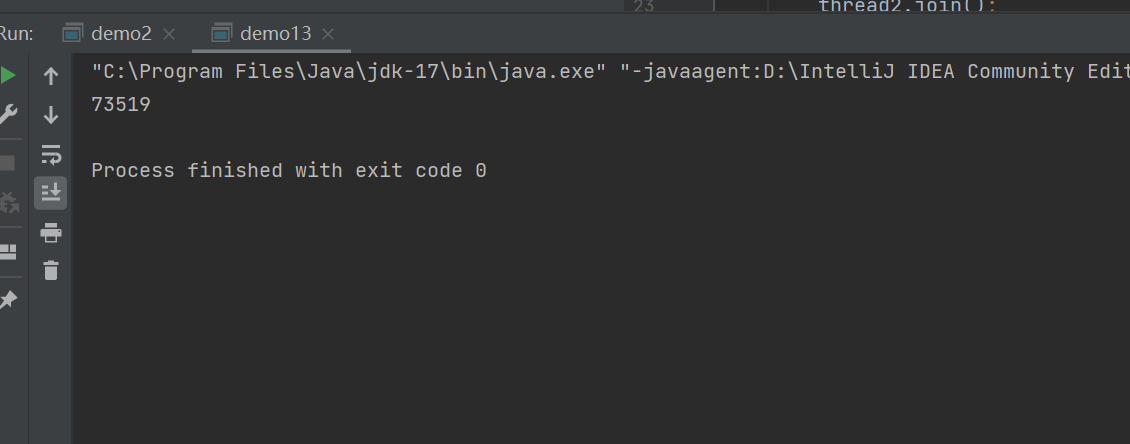
当程序运行起来的时候,发现,并不是我们要的100000
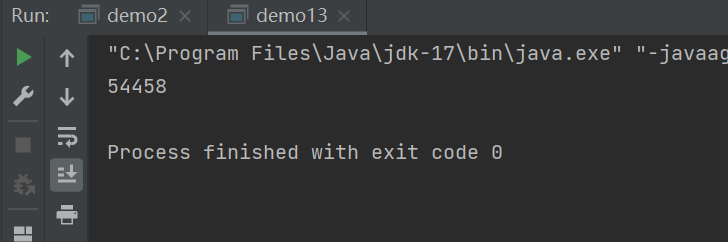
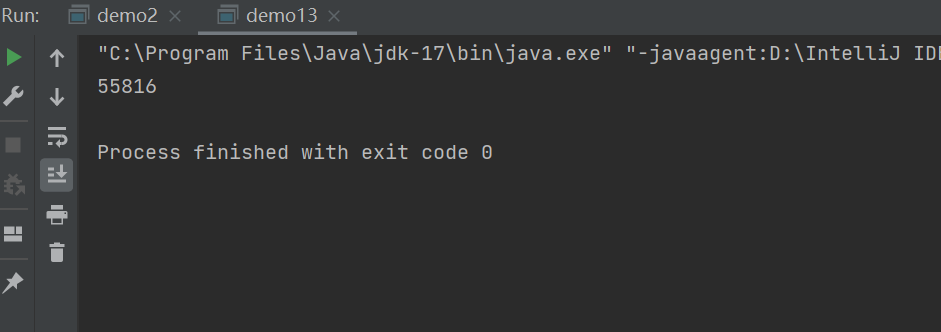
而且每次的值还都不一样,很明显,是有bug的
那么我们应该如何修改这个问题?
private static int count=0;
public static void main(String[] args) throws InterruptedException {
Thread thread1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
Thread thread2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
thread1.start();
thread1.join();
thread2.start();
thread2.join();
System.out.println(count);
}
当我们将两个join()方法分开,发现问题就解决了
我们这样修改的代码,就是让thread2线程一直等到thread1线程执行完成之后才开始执行,也就是串行化执行,这样就确保了程序的正确性
这样的问题,就是由多线程并发执行引起的问题,对于是由多线程并发执行代码引起的bug,我们就称为 “线程安全问题”或者叫做“线程不安全”,反之如果一个代码,在多线程并发执行的环境下,没有出现类似于上述的bug,此时这样的代码就称为“线程安全”
那么为什么会出现这种情况?
这里,我们需要站在cpu执行指令的角度去思考
![]()
count++这个操作,看起来只是一段简单的代码,实际上对应到3个cpu指令
①.load,将 内存中的count值读取到cpu寄存器
②.add,把指定的寄存器中的值进行 +1操作,这时结果仍然还是在cpu寄存器中
③.save,把cpu寄存器中的值写回到内存中
由于是三个线程,thread1,thread2,main,所以cpu在执行这三条指令的过程中,线程的调度是随时切换的,所以这时候就会出现多种情况
1,2,3 线程切走
1,2,线程切走······线程切回来 3
1,线程切走······线程切回来 2,3
1,线程切走······线程切回来 2,线程切走······线程切回来 3
由于操作系统的调度是随机的,所以在执行任何一个指令的过程中,都可能会触发上面的“线程切换”,所以导致了最终的结果错误
我们通过一个图来看
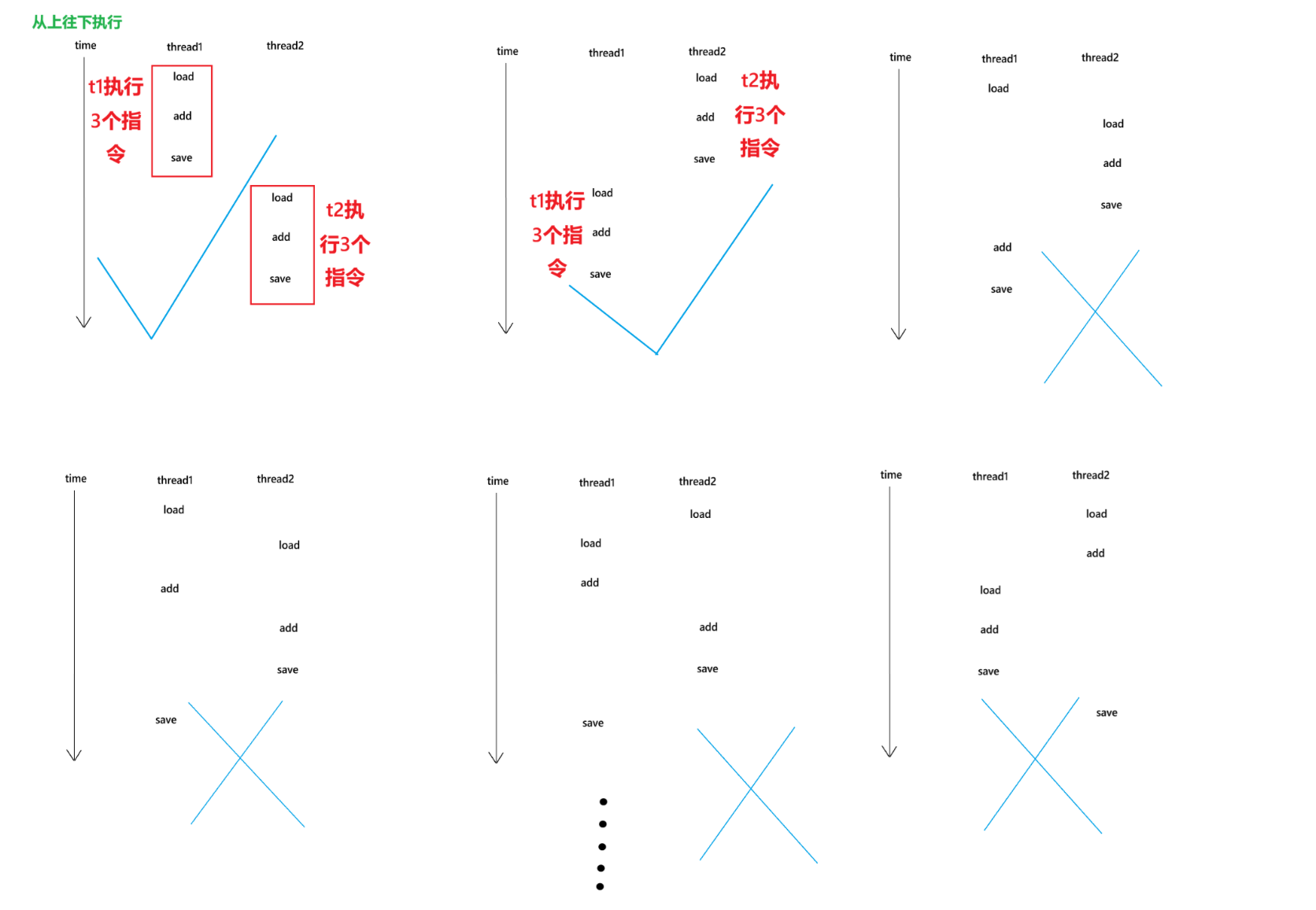
当然图中我只挑选了随机的几种,其实一共有无数种,因为实际上每个线程调度走,都有可能有其他的更多的线程,甚至是别的进程的线程占用cpu执行
下面就模拟几种情况
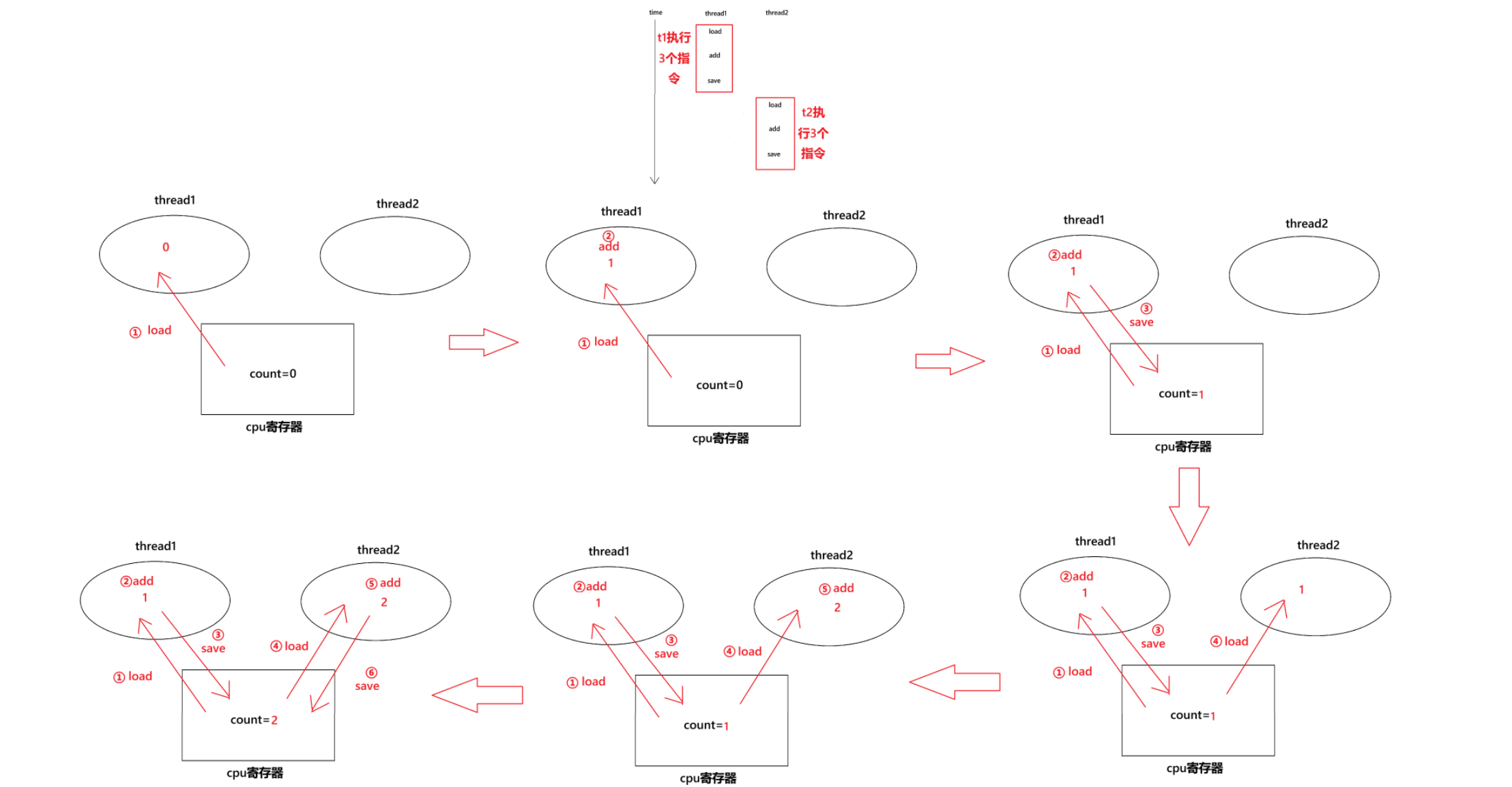
我们发现情况一是正确的
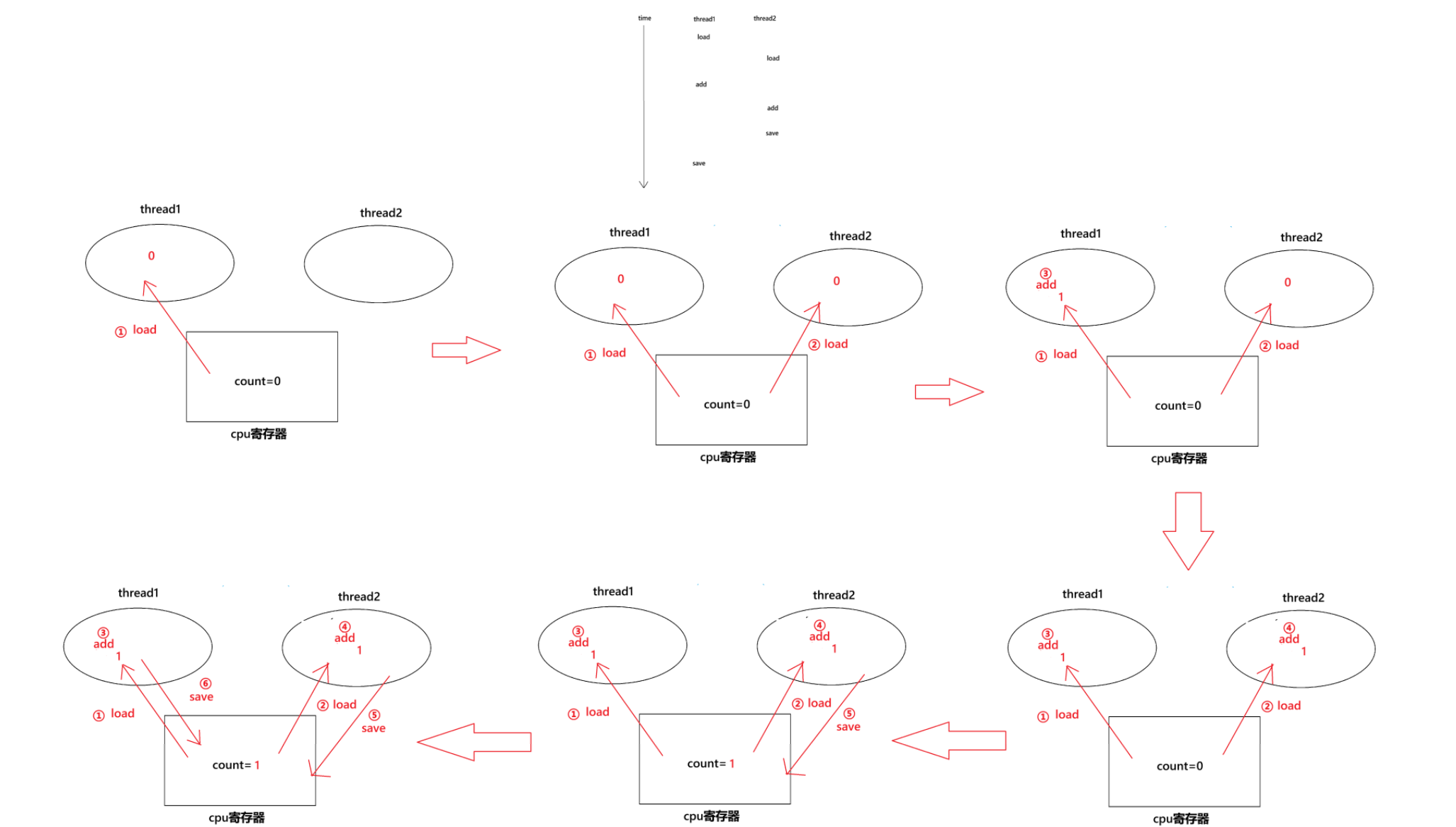
当执行这种情况的时候,就出错了,count应该计算出的结果为2,结果最终算的结果1
所以综上所述,如果两个线程分别都load到0,那么一定会少加一次,如果一个线程load到0,另一个线程load到1,那么结果才是正确的,即一个线程的load在另一个线程的save之后

如果是这种情况的话,算的值更小,4次自增,算的值为1
下面再看一个示例
private static int count=0;
public static void main(String[] args) throws InterruptedException {
Thread thread1=new Thread(()->{
for (int i = 0; i < 50; i++) {
count++;
}
});
Thread thread2=new Thread(()->{
for (int i = 0; i < 50; i++) {
count++;
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(count);
}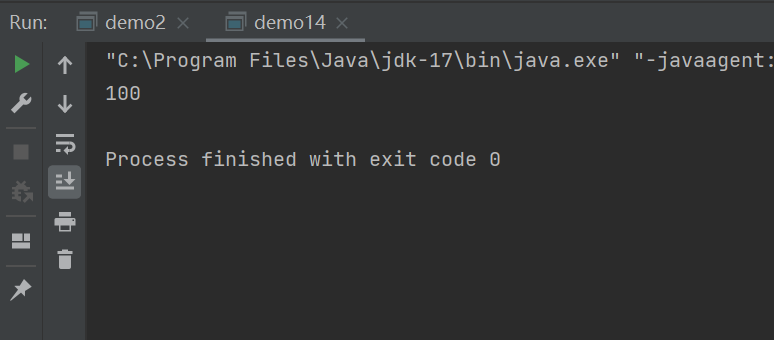
我们发现,当把循环次数调成50的时候,不需要串行化也能正确的运行该程序,而50000次的时候会发生线程安全问题,这又是我为什么?
这是因为,50 和 50000 ,线程执行的时间长短不同,对于50次而言,很可能出现一种情况,就是执行thread2.start()之前,thread1就已经执行完了,等执行thread2.start()的时候,变成串行化执行了,但是也是有概率发生线程安全的问题的,只不过概率很小
(三).线程安全问题产生的原因
1.[根本原因] 操作系统对于线程的调度是随机的,抢占式的执行
2.多个线程同时修改一个变量
thread1和thread2都是针对的count这个成员变量进行的修改
如果是一个线程修改一个变量,则没有问题
如果多个线程,不是同时修改同一个变量,则没问题
如果多个线程修改不同的变量,不会出现中间结果相互覆盖的情况,则没问题
如果多个线程读取同一个变量,则没问题
3.修改操作,不是原子的
这里的“原子”和当时学习数据库事务中的“原子性”中的原子的意思是一样的,如果修改操作只是对应到一个cpu指令,就可以认为是 “原子” 的,这样cpu就不会出现 “一条指令执行一半”的情况,如果对应到多个cpu,就不是原子的
4.内存可见性问题,引起的线程不安全
这个留到后面再进行介绍
5.指令重排序,引起的线程不安全
这个也留到后面再进行介绍
(四).如何解决线程安全问题
1.[根本原因] 操作系统对于线程的调度是随机的,抢占式的执行
这个是操作系统的底层设定,我们修改不了
2.多个线程同时修改一个变量
这个问题和代码的结构直接相关,我们可以通过调整代码的结构,规避一些线程不安全的代码,但是这样的方法不太通用
Java中的String就是采取了“不可变”性来确保线程安全,String没有提供public的修改方法,所以我们无法进行修改,和 final无关,final是用来实现 “不可继承”的
3.修改操作,不是原子的
Java中解决线程安全问题的最主要的方案,就是“加锁”,通过“加锁”让不是原子的操作,打包成一个原子的操作
(1).锁
Ⅰ.概念
计算机中的 “锁” 和我们家里的“锁”同样的概念,互斥/排他
在计算机中,不允许暴力拆锁,只能阻塞等待
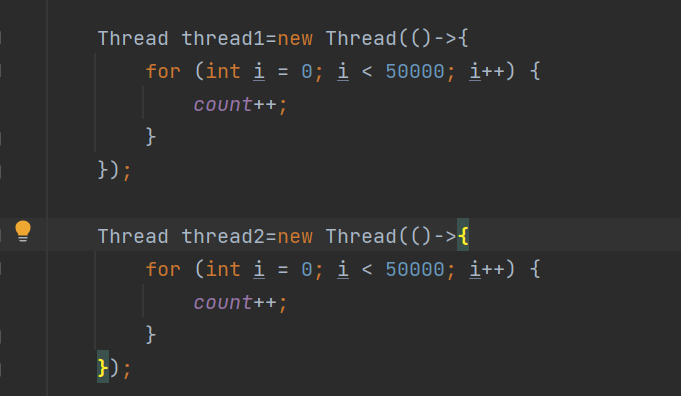
针对于这部分代码,我们就可以通过 “锁”,把不是原子的 count++给锁起来,在count++之前先加锁,然后进行count++,计算完毕之后,再解锁,这样其他的线程就没有办法插队了
注意:加锁操作,不是把线程锁死到cpu上,禁止这个线程调度走,而是禁止其他线程重新加这个锁,避免其他线程的操作在当前线程执行过程中插队
Ⅱ.关键字
加锁和解锁本身是操作系统提供的api,很多编程语言对这样的api进行了封装,大多数的封装风格都采用了两个函数
加锁 lock();
//执行保护起来的逻辑
解锁 unlock();
在java中,使用 synchronized 关键字,搭配代码块,来实现类似的效果
synchronized (加锁的对象){ //加锁
//执行保护起来的逻辑
}//解锁对于 ”加锁的对象“,在java中任何一个对象都可以用作 “锁”
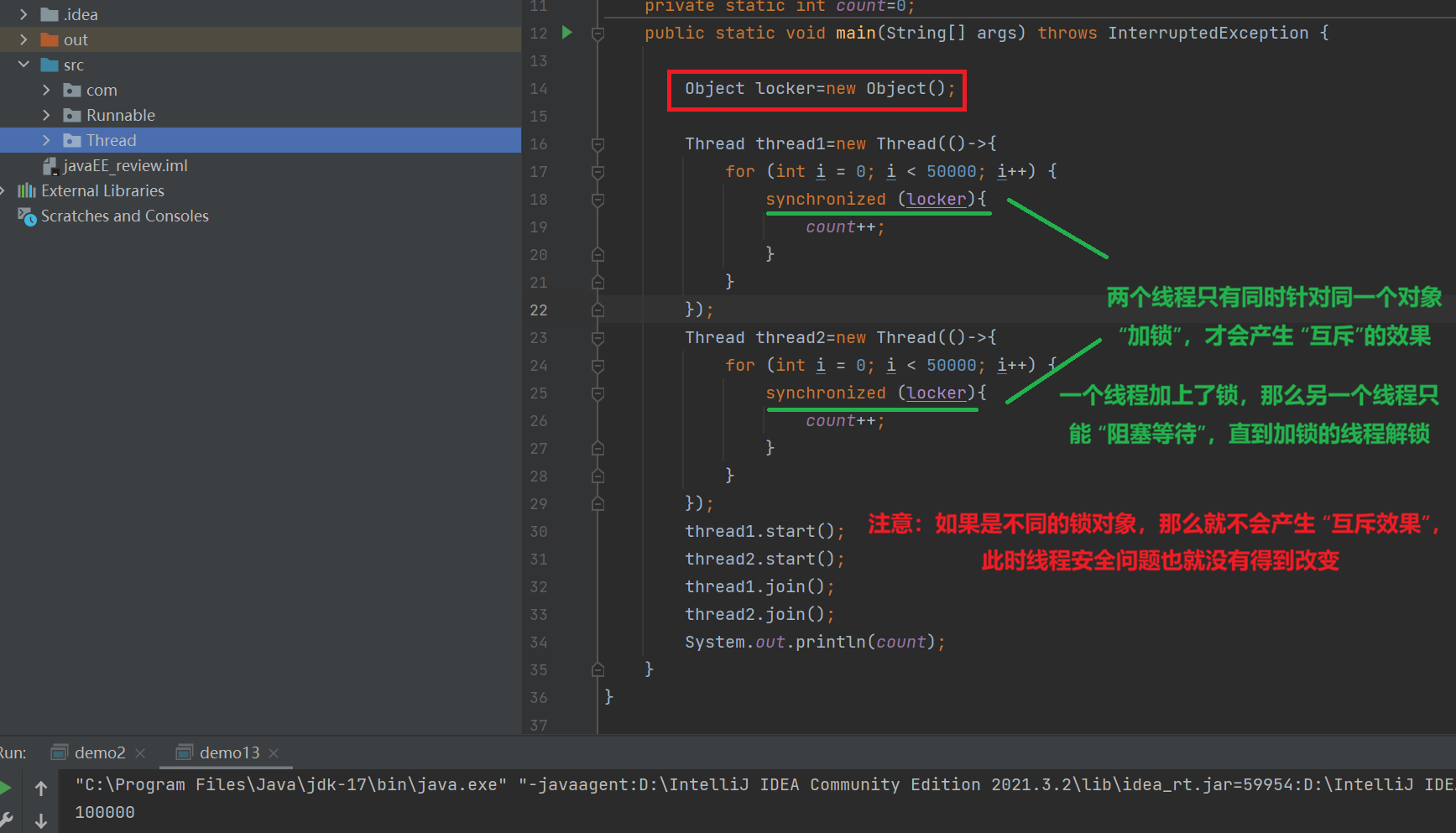
Ⅲ.不同位置加锁的区别
我们通过一个代码来看
private static int count=0;
public static void main(String[] args) throws InterruptedException {
Object locker=new Object();
Thread thread1=new Thread(()->{
synchronized (locker){
for (int i = 0; i < 50000; i++) {
count++;
}
}
});
Thread thread2=new Thread(()->{
synchronized (locker){
for (int i = 0; i < 50000; i++) {
count++;
}
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(count);
}
public static void main1(String[] args) throws InterruptedException {
Object locker=new Object();
Thread thread1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
synchronized (locker){
count++;
}
}
});
Thread thread2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
synchronized (locker){
count++;
}
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(count);
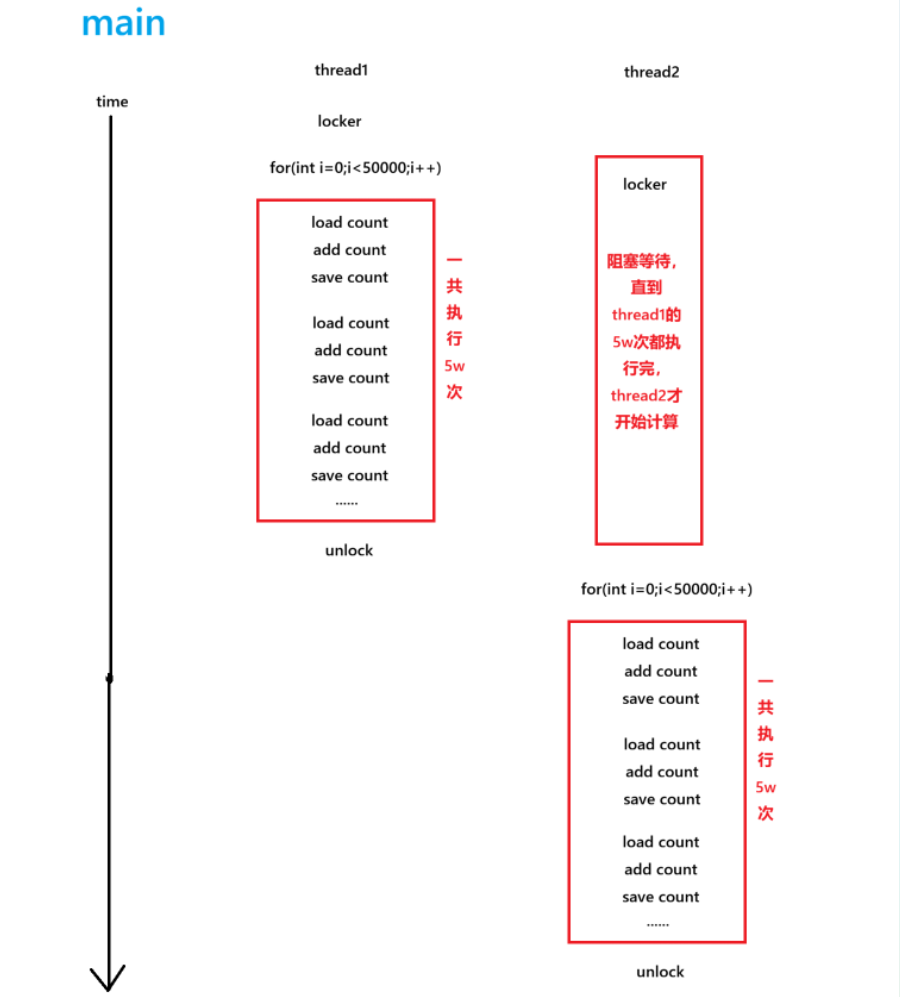
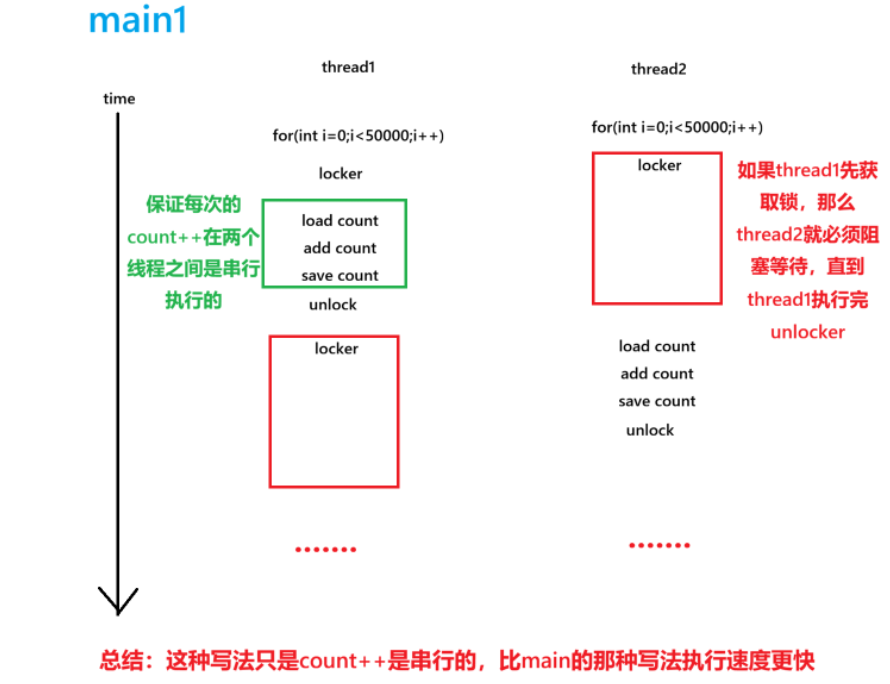
}对于main中的代码我们可以看到,我们加的锁是将整个for循环给包裹起来了
对于main1中的代码可以看到,我们加的锁只将count给包裹起来
虽然这两种代码最终的运行效果没有区别,但是二者在运行的时候,也是有不同的地方的
注意:当在“锁”种出现,break,return这样的语句时,Java的处理方式就是,一旦出了synchronized(){}的右花括号(}),那么就会自动解锁
Ⅳ.锁的变种写法
可以使用synchronized修饰方法
class Counter{
private int count=0;
//锁变种
synchronized public void add(){
synchronized (this){
count++;
}
}
// //锁优化
// public void add(){
// synchronized (this){
// count++;
// }
// }
public int getCount(){
return count;
}
}
public class demo15 {
public static void main(String[] args) throws InterruptedException {
Counter counter=new Counter();
Thread thread1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
counter.add();
}
});
Thread thread2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
counter.add();
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(counter.getCount());
}
}
通过上图代码的运行,可以看到能获取到正确的结果
使用synchronized修饰方法,相当于时针对this进行加锁
特殊情况:
如果静态方法,那么静态方法不存在this,这时候,我们加锁的时候,相当于针对的是类对象进行加锁
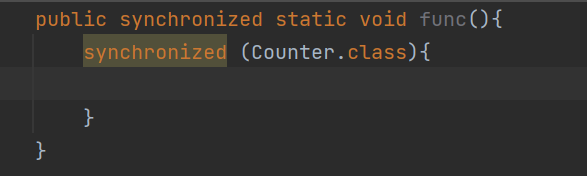
这两种加锁的方式等价,选其中一种即可
Ⅴ.监视器锁 monitor lock
JVM中的一个术语,使用锁的过程中抛出一些异常,可能会看到监视器锁这样的报错信息
Ⅵ.可重入
我们依旧是通过一个示例来看
示例
package Thread;
class Counter1{
private int count=0;
synchronized public void add(){
synchronized (this){
count++;
}
}
public int getCount(){
return count;
}
}
public class demo16 {
public static void main(String[] args) throws InterruptedException {
Counter1 counter1=new Counter1();
Object locker=new Object();
Thread thread1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
synchronized (locker){
counter1.add();
}
}
});
Thread thread2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
synchronized (locker){
counter1.add();
}
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(counter1.getCount());
}
}
通过上面的代码我们可以看到,当thread1加第一个锁的时候,确实能加上锁,但是当调用add()方法的时候,发现在add()方法中,又加了一层锁,当运行到这的时候,需要阻塞等待,必须等到第一层锁被释放,第二层加锁的阻塞才会被解除,这时候就会出现矛盾
要想解除阻塞就必须往下执行,而要想往下执行,就必须等到第一次的锁被释放,此时这种现象就被称为 “死锁”
为了解决该 “死锁”问题,Java 的synchronized()方法就引入了可重入的概念
可重入:当某个线程针对一个锁加锁成功后,后面该线程再次针对这个锁进行加锁,不会触发阻塞,而是继续往下走,因为当前这把锁就是被这个线程持有,但是如果其他线程尝试加锁,则会正常阻塞
可重入锁的实现原理:让锁对象内部保存,当前是哪个线程持有的这把锁,后续有线程针对这个锁加锁的时候,对比一下,锁持有者线程是否和当前加锁的线程是同一个
针对加了多层锁的情况,JVM会先引入一个计数器,初始化成0,每次触发"{"的时候,计数器++;每次触发"}"的时候,计数器--,当计数器--为0的时候,就是真正需要解锁的时候
面试题:如何自己实现一个可重入锁?
①.在锁内部确定是哪个线程持有这把锁,后续每次加锁的时候都进行判定
②.通过计数器,记录当前加锁的次数,从而确定何时解锁
Ⅶ.死锁的情况
①.一个线程,一把锁,连续加锁两把
也就是上面的这种情况
②.两个线程,两把锁,每个线程获取到一把锁之后,尝试获取对方的锁
示例
public static void main(String[] args) throws InterruptedException {
Object locker1=new Object();
Object locker2=new Object();
Thread thread1=new Thread(()->{
synchronized (locker1){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker2){
System.out.println("thread1 线程两把锁都获取到了");
}
}
});
Thread thread2=new Thread(()->{
synchronized (locker2){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker1){
System.out.println("thread2 线程两把锁都获取到了");
}
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
}通过上面的代码,可以看出 thread1线程拿到 locker1后尝试拿locker2,thread2线程拿到locker2后尝试拿locker1,两者互不相让,最终构成了 “死锁”
当代码运行起来之后,通过 “jconsole.exe”可执行文件查看线程的状态
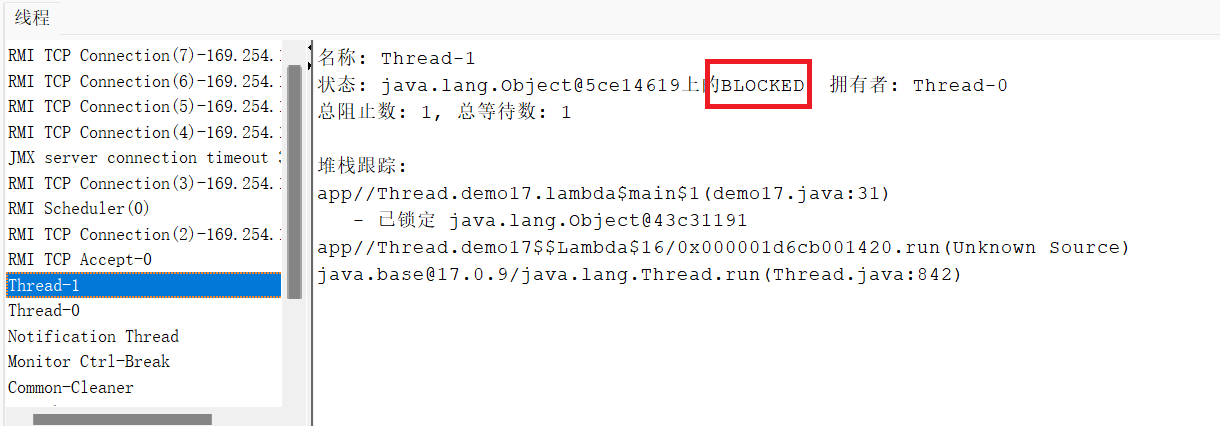
发现,线程状态为BLOCKED,说明该线程因为竞争锁而阻塞了
注意:这里加sleep(1000)的原因是为了避免构不成死锁,因为如果不加sleep(1000),很有可能thread1一口气就把locker1和locker2都拿到了,这个时候thread2可能还没开动呢
③.N个线程,M把锁
有一个经典的模型,“哲学家就餐问题”
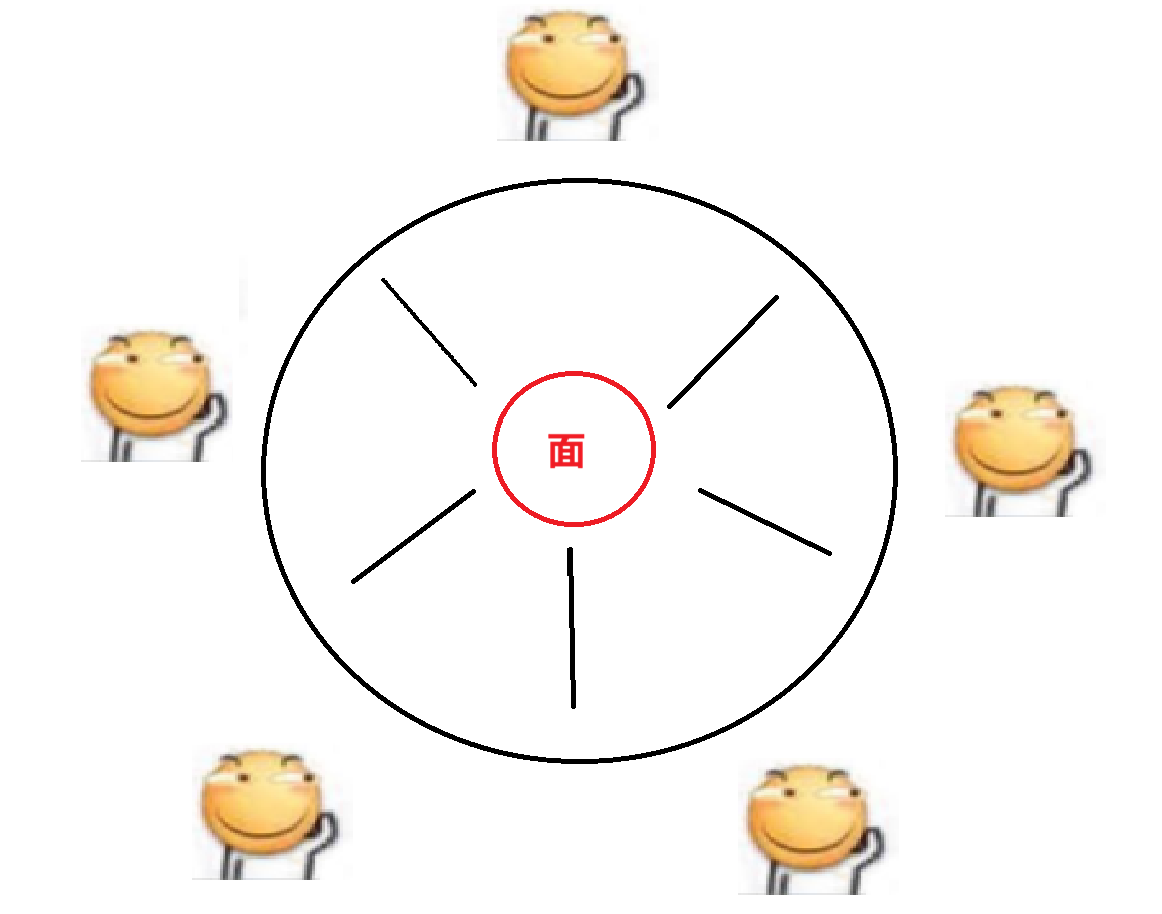
这五个“哲学家”只会有这两种情况,一种情况是 “思考人生”,另一种情况是 “吃面条(需要拿筷子)”,每个哲学家的左右手两边都各有一根筷子,这5根筷子就对应的是5把锁,哲学家相当于线程,所以每个哲学家只需要拿到两根筷子即可,对应的每个线程只需要拿到两把锁即可
那么有一种情况就会出现死锁问题,就是5个哲学家同时都想吃面条,5个哲学家同时去拿左手的筷子
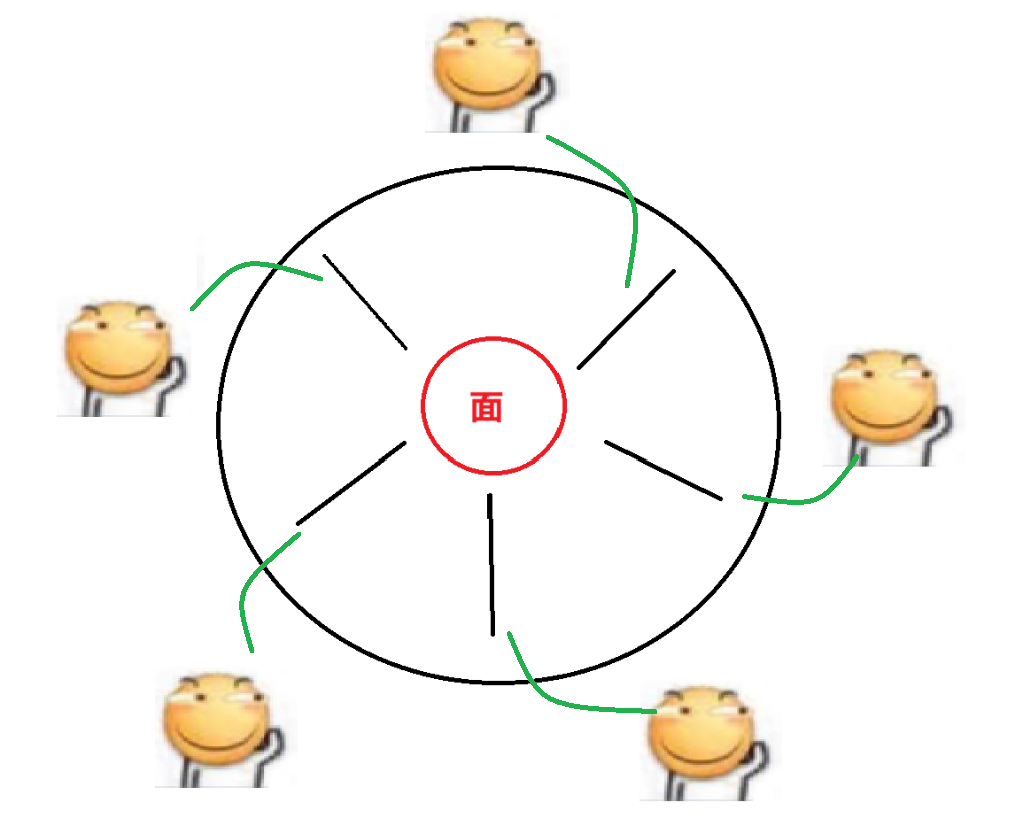
那么现在每个哲学家都拿不到右手的筷子,所以任何一个哲学家都吃不了面条,同时每个哲学家都不愿意放下左手的筷子,而是等待,此时就会出现死锁
Ⅷ.死锁的构成
①.锁是“互斥”的。
一个线程拿到锁之后,另一个线程再尝试获取锁,必须要阻塞等待
②.锁是不可“抢占”的。
对于两个线程,线程1拿到锁后,线程2也尝试获取这个锁,线程2必须阻塞等待,而不是线程2直接把锁抢过来
③.请求和保持。
一个线程拿到锁1后,不释放锁1,然后继续获取锁2,此时就会构成死锁。
类似于“哲学家就餐”的问题,如果某个哲学家放下左手的筷子,然后另一个哲学家拿右手的筷子,那么这个哲学家就可以吃上面条了,等这个哲学家吃完面条之后放下左手和右手的筷子,然后其他哲学家就可以吃上面条了
所以说,在代码中,我们要避免的“嵌套”锁
public static void main(String[] args) throws InterruptedException {
Object locker1=new Object();
Object locker2=new Object();
Thread thread1=new Thread(()->{
synchronized (locker1){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker2){
System.out.println("thread1 线程两把锁都获取到了");
}
}
});
Thread thread2=new Thread(()->{
synchronized (locker2){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker1){
System.out.println("thread2 线程两把锁都获取到了");
}
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
}对于上面这个代码,就属于“嵌套”了锁,解决的办法就是将“嵌套锁”改成 “并列锁”
public static void main(String[] args) {
Object locker1=new Object();
Object locker2=new Object();
Thread thread1=new Thread(()->{
synchronized (locker1){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//将 “嵌套锁” 改成 “并列锁”
synchronized (locker2){
System.out.println("thread1获取到两把锁了");
}
});
Thread thread2=new Thread(()->{
synchronized (locker2){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//将 “嵌套锁” 改成 “并列锁”
synchronized (locker1){
System.out.println("thread2获取到两把锁了");
}
});
thread1.start();
thread2.start();
}④.循环等待。
多个线程多把锁之间的等待过程,构成了“循环”,A等待B,B等待A 或者是其他情况
解决方法:约定好加锁的顺序,就可以破除循环等待了,例如:每个线程加锁的时候,永远是先获取序号小的锁,后获取序号大的锁
public static void main(String[] args) throws InterruptedException {
Object locker1=new Object();
Object locker2=new Object();
Thread thread1=new Thread(()->{
synchronized (locker1){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker2){
System.out.println("thread1 线程两把锁都获取到了");
}
}
});
Thread thread2=new Thread(()->{
synchronized (locker2){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker1){
System.out.println("thread2 线程两把锁都获取到了");
}
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
}对于上面的这个代码,thread1线程先加的locker1锁,然后 后加的locker2锁,thread2线程先加的locker2锁,然后 后加的locker1锁,此时就会出现死锁,我们要约定好一个规则,先加序号小的锁,后加序号大的锁
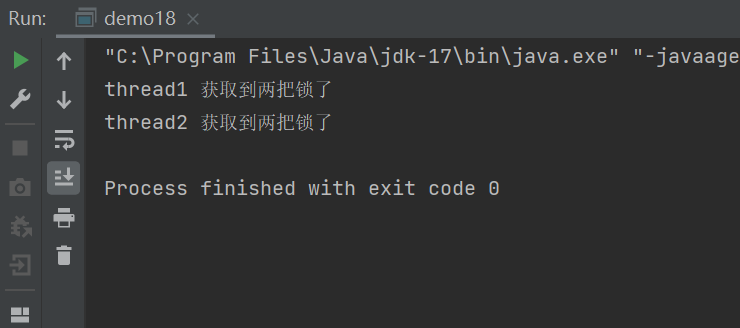
public static void main(String[] args) {
Object locker1=new Object();
Object locker2=new Object();
Thread thread1=new Thread(()->{
synchronized (locker1){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker2){
System.out.println("thread1 获取到两把锁了");
}
}
});
Thread thread2=new Thread(()->{
synchronized (locker1){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker2){
System.out.println("thread2 获取到两把锁了");
}
}
});
thread1.start();
thread2.start();
}
总结:针对死锁构成的这四个原因,①和②是锁的基本性质,我们只需要打破③和④就可以避免死锁的形成
(五).Java标准库中的线程安全类
1.Vector
2.HashTable
3.ConcurrentHashMap
4.SrtingBuffer
对于1,2,4来说,虽然有synchronized,但是都不推荐使用,不是写了synchronized就是100%安全的,3是针对2进行的优化,后面再具体介绍
一旦代码中使用了锁,就意味着代码可能因为锁的竞争而发现阻塞,那么程序的执行效率就会大打折扣,一旦发生阻塞,那么就意味着线程会从cpu上调度走,具体什么时候能够回来就不好说了
对于String来说,虽然没有加锁,但是String没有提供修改String的方法,所以说线程是安全的

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)