十分钟速成:MCP 优化 + OpenAkita 封装,轻松构建高效 AI Agent(收藏必备)
随着 AI 应用从对话式向行动式转变,如何让 AI 模型高效交互并处理海量信息成为关键挑战。MCP 协议解决了模型与外部系统通信问题,但上下文窗口消耗过快限制了应用。本文介绍 Context Mode 优化方案,通过沙盒执行、智能过滤等技术,将工具输出压缩 98%,显著提升会话时长。同时,OpenAkita 框架采用模块化设计、Markdown 内存系统和 ReAct 推理机制,提供可观测的决策过程和多 Agent 协作能力,帮助开发者构建高效 AI Agent。文章包含具体代码示例和性能数据,适合程序员和小白学习实践。
1、引言:AI Agent 时代的基础设施挑战
在 2026 年的 AI 应用开发领域,我们正在经历一场从"对话式 AI"到"行动式 AI"的范式转变。传统的聊天机器人只能回答问题,而现代 AI Agent 需要能够调用工具、访问数据、执行任务。这种转变带来了新的技术挑战:如何让 AI 模型高效地与外部系统交互,同时不被海量的上下文信息淹没。
Model Context Protocol(MCP)作为 Anthropic 在 2024 年 11 月推出的开放标准,试图解决这个问题。它定义了 AI 模型与外部数据源、API、数据库和工具之间的通信规范,被业界称为"AI 的 USB-C 标准"。然而,MCP 在实际应用中暴露出一个严重的性能瓶颈:上下文窗口(context window)的快速消耗。当你使用 Claude Code 或其他 MCP 客户端工作半小时后,会发现 AI 开始"失忆"——回答变慢、理解出错、上下文丢失。这不是模型的问题,而是 MCP 工具调用产生的大量输出数据正在吞噬你的上下文空间。
与此同时,OpenAkita(原名 Clawdbot)作为一个开源 AI Agent 框架,在短短几天内从 9000 星暴涨到 10 万星,成为 AI 历史上增长最快的开源项目之一。它采用了与传统方案截然不同的架构设计:模块化、可观测、基于 Markdown 的内存系统。本文将深入探讨 MCP 的上下文优化方案和 OpenAkita 的工程实践,为构建高效 AI Agent 提供可落地的技术路径。
2、MCP 上下文消耗的系统性问题
2.1 双向消耗机制
MCP 工具调用从两个方向消耗上下文窗口。第一个方向是输入侧:工具定义本身需要占用 token。当你激活 81 个 MCP 工具时,仅工具定义就消耗 143K tokens,占据 200K 上下文预算的 72%。这意味着在你开始对话之前,大部分上下文空间已经被工具描述填满。Cloudflare 曾推出 Code Mode 方案,通过压缩工具定义将这部分消耗降低 99.9%,但这只解决了输入侧的问题。

第二个方向是输出侧:工具执行结果作为原始数据返回,直接写入上下文。一个 Playwright 页面快照包含 56KB 的原始 HTML 结构,20 个 GitHub issues 产生 59KB 文本,一个访问日志文件占用 45KB。这些数字看似不大,但在实际工作流中会快速累积。当你调用几次 Playwright、读取若干 GitHub issue、拉取日志文件后,半小时不到,40% 的上下文已被工具输出填满,而不是你真正需要的代码和对话内容。
2.2 实测数据与影响
根据 fastn.ai 的研究报告,在执行 10-15 个任务后,上下文窗口会被 200K+ tokens 填满。模型开始失去焦点,遗忘早期决策,最终任务失败。开发团队报告称,他们需要花费 30-60 分钟重建上下文。一位开发者的评论很有代表性:“我们现在正淹没在曾经苦苦乞求的上下文中。”
这个问题在长时间会话中尤为明显。开始一个 debug 会话,调用几次 Playwright,再读几个 GitHub issue,拉一下日志——半小时不到,Claude 就开始"失忆"。实际上不是失忆,而是上下文满了,模型被迫开始丢弃早期的对话内容。会话工作时长从理论上的数小时缩短到实际的 30 分钟左右,严重影响开发效率。
3、Context Mode:输出侧优化的工程方案
3.1 核心设计思路
Context Mode 是由 Mert Köseoğlu 开发的开源项目,他运营着 MCP Directory & Hub,每天处理超过 10 万次请求。在审查了所有 MCP 服务器后,他发现一个规律:所有人都在构建会把原始数据塞进上下文的工具,但没有人在解决输出侧的问题。Context Mode 的核心思路是在 Claude Code 和外部工具之间插入一个压缩中间层,工具执行结果不直接进入上下文,而是先经过沙盒处理,只让精简后的结果进入对话。
这个方案完全基于算法实现,没有额外的 LLM 介入。它使用 SQLite FTS5 全文搜索引擎和 BM25 排名算法——这是经典信息检索领域的成熟技术,具有快速、确定性强、无幻觉的特点。当你搜索"authentication JWT token"时,返回的是这些词实际出现的段落,而不是某个 AI 对这些段落的总结。这意味着它不改变 Claude 的能力,只改变它能看到的信息量,但信息仍然准确、完整,没有摘要式的信息损失。
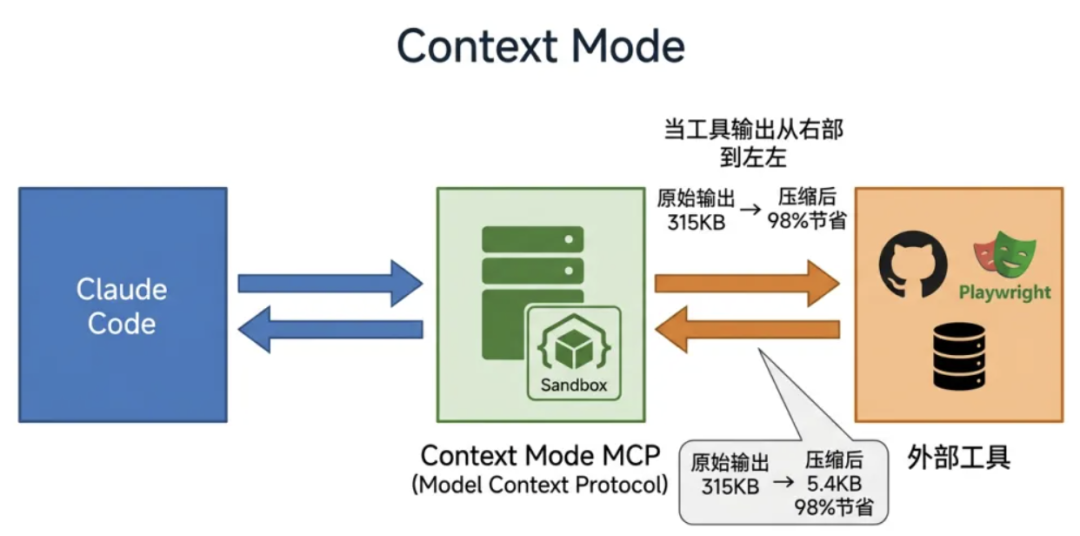
3.2 三层技术架构
Context Mode 的架构包含三个关键组件。第一层是沙盒执行(Sandbox Execution)。每次 execute 调用都在一个隔离的子进程中运行,子进程执行代码并捕获 stdout,只有这个 stdout 最终进入上下文。原始数据——日志文件、API 响应、Playwright 快照——永远不离开沙盒。系统支持 11 种语言运行时:JavaScript、TypeScript、Python、Shell、Ruby、Go、Rust、PHP、Perl、R 和 Elixir。如果检测到 Bun,会自动切换到 Bun 执行 JS/TS,速度提升 3-5 倍。认证过的 CLI 工具(gh、aws、gcloud、kubectl、docker)通过环境变量直通到子进程,不暴露给对话。
第二层是智能过滤机制。当工具输出超过 5KB 且提供了 intent(意图描述)时,Context Mode 会切换到意图驱动过滤模式:把完整输出索引进知识库,搜索匹配你意图的段落,只把相关内容返回。这就像给工具输出建立了一个临时的 RAG(检索增强生成)系统。第三层是知识库系统,使用 SQLite FTS5 虚拟表。index 工具把 Markdown 内容按标题切块存储,搜索使用 BM25 排名算法——一个基于词频和文档长度的概率相关性算法。Porter stemming 在索引时处理词干,所以"running"、“runs”、"ran"都能匹配到同一个词根。搜索还有三层 fallback:Porter stemming → Trigram 子串匹配 → Levenshtein 编辑距离纠错。即使打错字,“kuberntes"也能找到"kubernetes”。
3.3 代码实现示例
以下是 Context Mode 的核心沙盒执行逻辑示例:
// 沙盒执行器的核心实现
class SandboxExecutor {
async execute(code: string, runtime: Runtime, intent?: string): Promise<string> {
// 创建隔离的子进程
const subprocess = spawn(runtime.command, runtime.args, {
env: this.buildSafeEnv(),
cwd: this.workDir,
stdio: ['pipe', 'pipe', 'pipe']
});
// 写入代码到子进程
subprocess.stdin.write(code);
subprocess.stdin.end();
// 捕获输出
const stdout = await this.captureOutput(subprocess.stdout);
const stderr = await this.captureOutput(subprocess.stderr);
// 如果输出过大且有意图描述,进行智能过滤
if (stdout.length > 5000 && intent) {
return await this.filterByIntent(stdout, intent);
}
return stdout;
}
private async filterByIntent(output: string, intent: string): Promise<string> {
// 将输出索引到 FTS5
await this.indexContent(output);
// 使用 BM25 搜索相关段落
const relevantChunks = await this.searchByIntent(intent);
// 返回精简结果
return relevantChunks.join('\\n\\n');
}
private async searchByIntent(intent: string): Promise<string[]> {
// FTS5 全文搜索查询
const query = `
SELECT content, rank
FROM content_fts
WHERE content_fts MATCH ?
ORDER BY rank
LIMIT 5
`;
const results = await this.db.all(query, [intent]);
return results.map(r => r.content);
}
}
这段代码展示了沙盒执行的核心流程:创建隔离进程、捕获输出、根据输出大小和意图决定是否进行智能过滤。关键在于原始数据永远不进入主上下文,只有经过处理的精简结果才会返回。
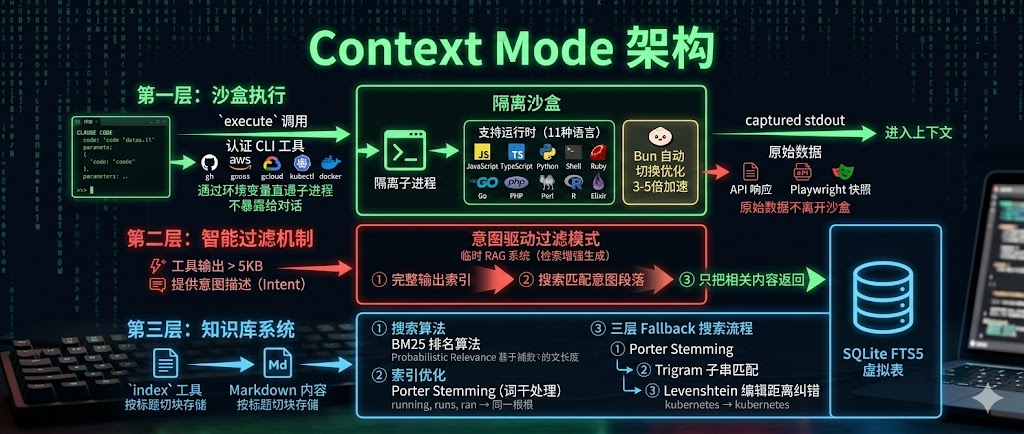
3.4 性能数据与实际效果
Context Mode 的官方基准测试覆盖了 8 个真实场景,数据令人印象深刻。Playwright 页面快照从 56.2KB 压缩到 299B,节省 99%;20 个 GitHub Issues 从 58.9KB 压缩到 1.1KB,节省 98%;500 条访问日志从 45.1KB 压缩到 155B,节省 100%。最复杂的代码仓库研究场景,原本需要 37 次工具调用产生 986KB 数据,使用 Context Mode 后只需 5 次调用产生 62KB 数据,节省 94%。
在完整会话中,315KB 的原始工具输出被压缩到 5.4KB,整体节省 98%。会话工作时长从约 30 分钟延长到约 3 小时,提升 6 倍。45 分钟后的剩余上下文从 60% 提升到 99%。这不是微优化,而是用法层面的质变。开发者可以在同一个会话中完成更复杂的任务,而不需要频繁重建上下文。

安装 Context Mode 非常简单,通过插件市场只需两行命令:
/plugin marketplace add mksglu/claude-context-mode
/plugin install context-mode@claude-context-mode
安装后会自动注册 PreToolUse hook,将工具输出路由经过沙盒。你不需要改变任何工作方式,系统会透明地处理所有优化。Context Mode 还提供三个诊断命令:/context-mode:stats 查看当前会话的上下文节省情况,/context-mode:doctor 运行诊断检查,/context-mode:upgrade 从 GitHub 拉取最新版本。
4、 OpenAkita 模块化 AI Agent 的架构实践
4.1 六层架构体系
OpenAkita 的架构分为六层,每层都有明确的职责边界。最上层是桌面应用层,使用 Tauri + React 构建,提供图形化界面。第二层是推理引擎层,负责任务理解和决策。第三层是 Agent 调度层,包含 AgentOrchestrator 做总调度和 AgentInstancePool 管理 Agent 实例,支持最多 5 层委派深度,防止任务递归失控。
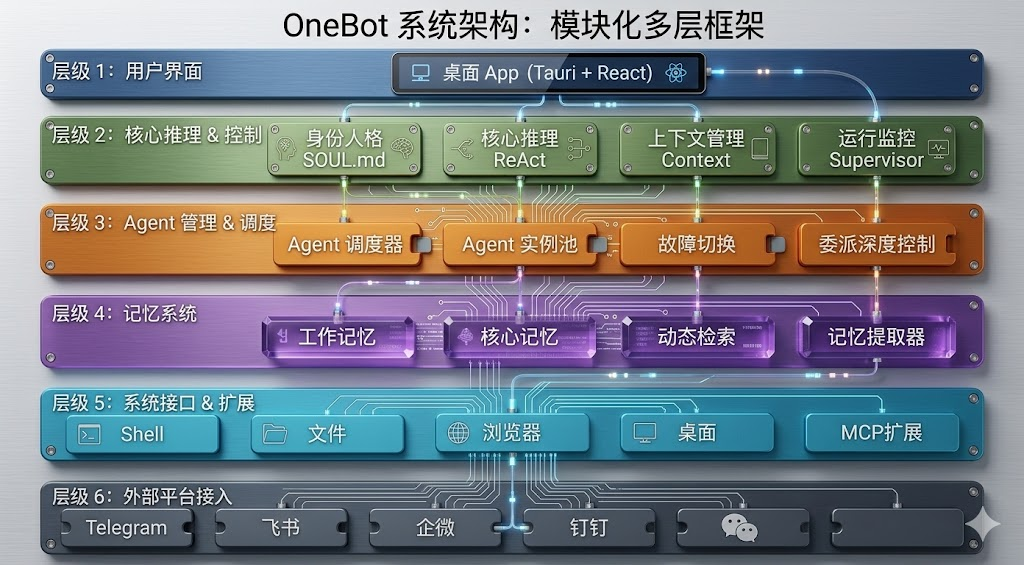
第四层是记忆系统层,这是 OpenAkita 的一大创新。与传统方案使用向量数据库不同,OpenAkita 的整个记忆系统运行在 Markdown 文件上。纯文本文件就放在项目目录中,你可以阅读、编辑、用 git 版本控制,或者随时删除。系统实现了三层记忆:工作记忆(当前任务上下文)、核心记忆(用户画像和偏好)、动态检索(历史经验),支持 7 种记忆类型。两个月前告诉它你喜欢简洁风格,现在写东西它还记得。
第五层是工具层,则是OpenAkita主要的贡献,内置 89 种工具,覆盖 16 个类别。这些工具不是简单的 API 包装,而是具有严格契约的能力单元。每个工具都有明确的输入输出规范、错误处理机制和权限控制。第六层是通信层,对接 6 个 IM 平台:飞书、企微、钉钉、Telegram、QQ、OneBot。在你常用的聊天工具里直接 @ 它,发语音也能识别,不需要单独开一个应用。

两段式 Prompt 架构:Prompt Compiler
OpenAkita 在推理引擎层实现了创新的两段式 Prompt 架构,将任务理解与任务执行分离:
第一阶段:Prompt Compiler(任务编译器)
Prompt Compiler 是一个专门的轻量级模型,负责将用户的自然语言请求转化为结构化的任务定义。它不解决问题,只负责理解和结构化需求。
输出格式(YAML):
task_type: [question/action/creation/analysis/reminder/other]
goal: [一句话描述任务目标]
inputs:
given: [已提供的信息列表]
missing: [缺失但可能需要的信息列表]
constraints: [约束条件列表]
output_requirements: [输出要求列表]
risks_or_ambiguities: [风险或歧义点列表]
第二阶段:主 LLM 执行
主 LLM 接收结构化的任务定义,专注于执行和解决问题。这种分离带来三个优势:
-
- 降低歧义:结构化定义减少主 LLM 的理解偏差
-
- 提升质量:主 LLM 可以专注于解决问题而非理解需求
-
- 成本优化:Compiler 使用小模型,主 LLM 只处理明确任务
渐进式披露工具系统
OpenAkita 的 89 种工具采用三层渐进式披露机制,避免一次性加载所有工具定义导致的上下文膨胀:
| 层级 | 内容 | 时机 | Token 消耗 |
|---|---|---|---|
| Level 1 | 工具清单(name + 简短描述) | 系统提示中提供 | ~2K tokens |
| Level 2 | 详细说明(参数、示例、触发条件) | 通过 get_tool_info 按需获取 |
~200 tokens/工具 |
| Level 3 | 直接执行 | LLM 调用工具 | 实际执行 |
高频工具白名单:5 个最常用工具(run_shell, read_file, write_file, list_directory, ask_user)跳过 Level 2,直接提供完整 schema,减少交互轮次。
16 个工具分类(按系统提示展示顺序):
-
- File System - 文件系统操作
-
- Agent - Agent 委派与协作
-
- Skills - 技能管理
-
- Memory - 记忆系统
-
- Web Search - 网络搜索
-
- Browser - 浏览器自动化
-
- Desktop (Windows) - 桌面自动化
-
- Scheduled Tasks - 定时任务
-
- IM Channel - IM 平台集成
-
- User Profile - 用户画像
-
- System - 系统工具
-
- MCP - Model Context Protocol
-
- Plan - 计划模式
-
- Persona - 人格切换
-
- Sticker - 表情包
-
- Config - 配置管理
上下文管理策略
OpenAkita 针对 200K 上下文窗口实现了智能管理策略:
# 上下文预算配置
DEFAULT_MAX_CONTEXT_TOKENS = 160000 # 200K - 4K输出预留 - 10%安全边际
COMPRESSION_RATIO = 0.15 # 压缩到原上下文的 15%
CHUNK_MAX_TOKENS = 30000 # 单次压缩块上限
LARGE_TOOL_RESULT_THRESHOLD = 5000 # 大型工具结果独立压缩阈值
MIN_RECENT_TURNS = 4 # 至少保留最近 4 轮对话
当上下文接近预算时,系统会:
-
- 保护最近对话:最近 4 轮对话永不压缩
-
- 分块压缩:将早期对话分成 30K token 的块,逐块压缩
-
- 大结果独立处理:超过 5K tokens 的工具结果单独压缩
-
- 递归压缩:如果压缩后仍超限,继续压缩直到满足预算
这种策略使得 OpenAkita 可以在长时间会话中保持高质量的上下文,避免传统方案中"越聊越傻"的问题。
4.2 安装与配置
OpenAkita 提供三种安装方式,适合不同使用场景。
方式一:桌面应用(推荐新手)
直接从 GitHub Releases 下载预编译的桌面应用:
# 访问 GitHub Releases 页面
<https://github.com/openakita/openakita/releases>
# 下载对应平台的安装包
# macOS: OpenAkita-{version}.dmg
# Windows: OpenAkita-{version}.exe
# Linux: OpenAkita-{version}.AppImage
桌面应用内置图形化配置向导,首次启动会引导你完成:
- • AI 模型配置(Claude/GPT/Gemini API 密钥)
- • IM 平台连接(可选)
- • 工作目录设置
方式二:pip 安装(推荐开发者)
使用 Python 包管理器安装,适合需要自定义集成的场景:
# 完整安装(包含所有依赖)
pip install openakita[all]
# 最小安装(仅核心功能)
pip install openakita
# 指定版本安装
pip install openakita[all]==1.2.0
安装后需要手动配置:
# 初始化配置文件
openakita init
# 编辑配置文件
vim ~/.openakita/config.yaml
配置文件示例:
# ~/.openakita/config.yaml
llm:
provider: anthropic # anthropic | openai | google
api_key: YOUR_API_KEY
model: claude-3-opus-20240229
memory:
storage_path: ~/.openakita/memory
max_history: 1000
tools:
enabled:
- file_operations
- web_search
- code_execution
disabled:
- system_commands # 禁用危险操作
im_platforms:
telegram:
enabled: true
bot_token: YOUR_BOT_TOKEN
feishu:
enabled: false
方式三:源码安装(推荐贡献者)
从源码构建,适合需要修改或贡献代码的场景:
# 克隆仓库
git clone <https://github.com/openakita/openakita.git>
cd openakita
# 安装依赖
npm install # 前端依赖
pip install -e ".[dev]" # Python 依赖(开发模式)
# 构建桌面应用
npm run build
npm run tauri build
# 或直接运行开发模式
npm run tauri dev
验证安装
安装完成后,验证 OpenAkita 是否正常工作:
# 检查版本
openakita --version
# 运行健康检查
openakita doctor
# 启动交互式会话
openakita chat
如果遇到问题,可以查看日志文件:
# 日志位置
~/.openakita/logs/openakita.log
# 实时查看日志
tail -f ~/.openakita/logs/openakita.log
4.3 ReAct 推理机制
OpenAkita 的底层推理逻辑采用 ReAct(Reasoning and Acting)机制:思考 → 行动 → 观察,三阶段显式循环。这不是黑盒推理,而是可观测的决策过程。系统有 Checkpoint 机制,失败了能回退。遇到卡住的任务,它会自动切换策略,而不是直接告诉你"我不行"。
以下是 ReAct 循环的核心实现(基于 OpenAkita 实际源码):
class ReActAgent:
def __init__(self, llm, tools, memory, tracer):
self.llm = llm
self.tools = tools
self.memory = memory
self.tracer = tracer # AgentTracer 实例
self.max_iterations = 10
async def execute(self, task: str, session_id: str) -> str:
# 开始追踪(非上下文管理器版本,适合多返回路径)
trace = self.tracer.begin_trace(session_id, metadata={"task": task})
try:
context = self.memory.load_context(task)
for iteration in range(self.max_iterations):
# 推理循环 Span
with self.tracer.reasoning_span(iteration=iteration):
# 思考阶段:分析当前状态,决定下一步
with self.tracer.llm_span(model="claude-3-opus") as llm_span:
thought = await self.llm.think(
task=task,
context=context,
history=self.memory.get_history()
)
llm_span.set_attribute("input_tokens", thought.input_tokens)
llm_span.set_attribute("output_tokens", thought.output_tokens)
# 行动阶段:选择工具并执行
if thought.action:
# 决策节点 Span(Agent Harness 扩展)
with self.tracer.decision_span(
decision_type="tool_selection",
reasoning=thought.reasoning
) as decision_span:
decision_span.set_attribute("selected_tool", thought.action.name)
# 工具执行 Span
with self.tracer.tool_span(tool_name=thought.action.name) as tool_span:
tool = self.tools.get(thought.action.name)
observation = await tool.execute(thought.action.params)
tool_span.set_attribute("result_size", len(str(observation)))
# 观察阶段:记录结果,更新上下文
context.append({
'thought': thought.reasoning,
'action': thought.action,
'observation': observation
})
# 保存 checkpoint(记忆操作 Span)
with self.tracer.memory_span(operation="save_checkpoint"):
self.memory.save_checkpoint(iteration, context)
# 验证节点 Span(Agent Harness 扩展)
with self.tracer.verification_span(
verification_type="task_completion"
) as verify_span:
if thought.is_complete:
verify_span.set_attribute("result", "completed")
return observation
verify_span.set_attribute("result", "continue")
else:
# 无需行动,直接返回答案
return thought.answer
# 达到最大迭代次数,返回当前状态
return self.memory.summarize(context)
finally:
# 结束追踪
self.tracer.end_trace(metadata={"iterations": iteration + 1})
这段代码展示了 ReAct 循环与追踪系统的深度集成:
-
- 完整追踪生命周期:使用
begin_trace/end_trace管理整个任务的追踪
- 完整追踪生命周期:使用
-
- 嵌套 Span 结构:REASONING → LLM/DECISION/TOOL/MEMORY/VERIFICATION 形成父子关系
-
- Agent Harness 扩展:DECISION 和 VERIFICATION Span 记录关键决策点
-
- 属性记录:每个 Span 记录 token 消耗、工具名称、结果大小等关键指标
-
- 异常安全:finally 块确保追踪数据始终被导出
关键在于整个过程是可观测的,每个决策点、工具调用、LLM 推理都被记录为独立的 Span,你可以在神经网络仪表盘实时看到每个 Agent 的工作状态。
Ralph Wiggum 循环引擎:永不放弃的执行哲学
OpenAkita 的 ReAct 实现基于 Ralph Wiggum 循环引擎,这是一个受 Claude Code 插件启发的持久化任务执行系统。其核心设计哲学是:
核心理念:
- 任务未完成,绝不终止
- 通过文件持久化状态
- 每次迭代 fresh context
- 通过 backpressure(测试验证)强制自我修正
Ralph 引擎的任务状态机包含 5 种状态:
| 状态 | 说明 | 转换条件 |
|---|---|---|
| PENDING | 待执行 | 初始状态或重试 |
| IN_PROGRESS | 执行中 | 开始执行时 |
| COMPLETED | 已完成 | 任务成功 |
| FAILED | 失败 | 达到最大重试次数(10次) |
| BLOCKED | 阻塞 | 依赖未满足 |
与传统 ReAct 实现的关键区别在于失败恢复机制。当任务执行失败时,系统不会立即放弃,而是:
-
- 记录失败原因:保存错误信息到任务状态
-
- 重置为 PENDING:允许重试(最多 10 次)
-
- Fresh Context:每次重试使用新的上下文,避免错误累积
-
- Backpressure 验证:通过测试结果强制 Agent 自我修正
以下是 Ralph 任务状态管理的实际实现:
@dataclass
class Task:
"""任务定义"""
id: str
description: str
session_id: str | None = None
status: TaskStatus = TaskStatus.PENDING
priority: int = 0
attempts: int = 0
max_attempts: int = 10 # 最大重试 10 次
created_at: datetime = field(default_factory=datetime.now)
completed_at: datetime | None = None
error: str | None = None
result: Any = None
subtasks: list["Task"] = field(default_factory=list)
def mark_failed(self, error: str) -> None:
"""标记为失败"""
self.error = error
if self.attempts >= self.max_attempts:
self.status = TaskStatus.FAILED # 真正失败
else:
self.status = TaskStatus.PENDING # 可重试
@property
def can_retry(self) -> bool:
"""是否可以重试"""
return (
self.status in (TaskStatus.PENDING, TaskStatus.FAILED)
and self.attempts < self.max_attempts
)
这种设计使得 OpenAkita 在面对复杂任务时具有极强的韧性。即使某次执行因为网络波动、API 限流、临时错误而失败,系统也会自动重试,直到成功或达到最大重试次数。
12 种追踪 Span:全链路可观测性
OpenAkita 实现了完整的分布式追踪系统,通过 12 种 Span 类型记录 Agent 执行的每个环节。这不仅用于调试,更是理解 AI 决策过程的关键工具。
基础 Span 类型(8种):
| Span 类型 | 说明 | 典型用途 |
|---|---|---|
| LLM | LLM 调用 | 记录模型推理耗时、token 消耗 |
| TOOL | 工具执行 | 单个工具调用的执行时间和结果 |
| TOOL_BATCH | 工具批量执行 | 并行工具调用的整体性能 |
| MEMORY | 记忆操作 | 记忆检索、存储的耗时 |
| CONTEXT | 上下文管理 | 上下文压缩、清理的性能 |
| REASONING | 推理循环 | 完整 ReAct 循环的迭代过程 |
| PROMPT | 提示词构建 | Prompt 组装的耗时 |
| TASK | 完整任务 | 端到端任务执行的总时长 |
Agent Harness 扩展 Span(4种,2026年3月新增):
| Span 类型 | 说明 | 监督场景 |
|---|---|---|
| DECISION | 决策节点 | 工具选择、策略选择的决策过程 |
| VERIFICATION | 验证节点 | 任务完成验证、Plan 步骤验证 |
| SUPERVISION | 监督节点 | 循环检测、异常干预决策 |
| DELEGATION | 委派节点 | 多 Agent 委派的协调过程 |
每个 Span 包含以下核心信息:
@dataclass
class Span:
span_id: str # 唯一标识(UUID)
name: str # Span 名称
span_type: SpanType # 类型(12种之一)
start_time: float # 开始时间(Unix 时间戳)
parent_id: str | None = None # 父 Span ID(支持嵌套)
end_time: float | None = None # 结束时间
status: SpanStatus = OK # 状态:OK/ERROR/CANCELLED
attributes: dict = {} # 自定义属性(token数、工具名等)
error_message: str | None = None
@property
def duration_ms(self) -> float | None:
"""耗时(毫秒)"""
if self.end_time is None:
return None
return (self.end_time - self.start_time) * 1000
def set_attribute(self, key: str, value: Any) -> None:
"""设置属性"""
self.attributes[key] = value
def set_error(self, message: str) -> None:
"""标记为错误"""
self.status = SpanStatus.ERROR
self.error_message = message
def finish(self, status: SpanStatus | None = None) -> None:
"""结束 Span"""
self.end_time = time.time()
if status is not None:
self.status = status
def to_dict(self) -> dict[str, Any]:
"""序列化为字典(用于导出)"""
result = {
"span_id": self.span_id,
"name": self.name,
"type": self.span_type.value,
"start_time": self.start_time,
"status": self.status.value,
"attributes": self.attributes,
}
if self.parent_id:
result["parent_id"] = self.parent_id
if self.end_time is not None:
result["end_time"] = self.end_time
result["duration_ms"] = self.duration_ms
if self.error_message:
result["error"] = self.error_message
return result
Span 的父子关系与嵌套:
OpenAkita 的追踪系统通过 parent_id 字段建立 Span 的父子关系。当使用上下文管理器(with tracer.xxx_span())时,系统会自动维护一个 Span 栈,新创建的 Span 自动将栈顶 Span 设为父节点。这种设计使得追踪数据天然形成树状结构,完整反映了 Agent 的执行层次。
# AgentTracer 的 Span 栈管理
class AgentTracer:
def __init__(self):
self._span_stack: list[Span] = [] # Span 栈
self._current_trace: Trace | None = None
def start_span(self, name: str, span_type: SpanType, **attributes) -> Span:
"""创建并开始一个新的 Span"""
# 自动使用栈顶 Span 作为父节点
parent_id = self._span_stack[-1].span_id if self._span_stack else None
span = Span(
span_id=str(uuid.uuid4()),
name=name,
span_type=span_type,
start_time=time.time(),
parent_id=parent_id,
attributes=attributes,
)
if self._current_trace:
self._current_trace.add_span(span)
return span
@contextmanager
def span(self, name: str, span_type: SpanType, **attributes):
"""通用 Span 上下文管理器"""
span = self.start_span(name, span_type, **attributes)
self._span_stack.append(span) # 入栈
try:
yield span
except Exception as e:
span.set_error(str(e))
raise
finally:
if self._span_stack:
self._span_stack.pop() # 出栈
span.finish()
实际应用示例:
当用户请求"分析这个 GitHub 仓库的架构"时,追踪系统会生成如下 Span 树:
TASK (总任务: 45.2s)
├─ PROMPT (提示词构建: 0.3s)
├─ REASONING (推理循环: 44.8s)
│ ├─ DECISION (决策: 选择 web_search 工具: 0.1s)
│ ├─ TOOL (web_search: 2.3s)
│ ├─ LLM (分析搜索结果: 8.5s, 12K tokens)
│ ├─ DECISION (决策: 选择 read_file 工具: 0.1s)
│ ├─ TOOL_BATCH (并行读取 5 个文件: 1.2s)
│ ├─ LLM (架构分析: 15.3s, 28K tokens)
│ ├─ VERIFICATION (验证: 分析是否完整: 0.2s)
│ └─ MEMORY (存储分析结果: 0.5s)
└─ CONTEXT (上下文压缩: 16.3s, 压缩率 85%)
这种细粒度的追踪使得开发者可以:
- • 性能优化:识别瓶颈环节(如上例中 CONTEXT 压缩耗时 16.3s)
- • 成本分析:统计 LLM token 消耗(上例总计 40K tokens)
- • 故障诊断:定位失败的具体步骤和原因
- • 行为审计:回溯 Agent 的完整决策链
4.4 多 Agent 协作机制
OpenAkita 的真正威力在于多 Agent 协作。当你说"帮我做一份竞品分析报告",系统会把任务拆解:搜索 Agent 去找竞品资料,分析 Agent 处理数据,写作 Agent 负责出报告。三个 Agent 同时运行,各司其职,最后汇总结果。这不是营销噱头,而是实实在在的架构设计。
核心组件架构
OpenAkita 的多 Agent 系统包含四个核心组件:
-
- AgentOrchestrator(总调度器):负责任务分解、Agent 分配和结果汇总。决定任务如何拆解、哪些 Agent 参与、如何协调执行顺序。
-
- AgentInstancePool(实例池):管理 Agent 实例的生命周期,包括创建、复用、销毁。采用对象池模式,避免频繁创建销毁带来的性能开销。
-
- FallbackResolver(故障转移器):当某个 Agent 执行失败或卡住时,自动切换到备用 Agent 或调整策略。确保任务不会因单点故障而中断。
-
- Agent Harness(运行时监督框架):2026 年 3 月新增的治理框架,实时监控 Agent 行为,检测工具滥用、资源超限、推理循环等异常,并自动干预。
系统支持最多 5 层委派深度,防止任务递归失控。每个 Agent 都有独立的上下文和工具访问权限,通过消息传递进行通信。
以下是多 Agent 协作的核心实现(基于 OpenAkita 实际源码):
class AgentOrchestrator:
"""Agent 总调度器"""
def __init__(self, pool: AgentInstancePool, tracer: AgentTracer):
self.pool = pool
self.tracer = tracer
self.max_depth = 5 # 最大委派深度
async def execute_task(self, task: Task, depth: int = 0) -> Result:
"""执行任务(支持递归委派)"""
# 深度限制检查
if depth >= self.max_depth:
raise MaxDelegationDepthError(
f"达到最大委派深度 {self.max_depth},任务可能存在循环依赖"
)
# 委派节点 Span(Agent Harness 扩展)
with self.tracer.delegation_span(
from_agent="orchestrator",
to_agent=task.type,
) as delegation_span:
delegation_span.set_attribute("depth", depth)
delegation_span.set_attribute("task_id", task.id)
# 分析任务,决定是否需要分解
plan = await self._plan_task(task)
if plan.needs_delegation:
# 创建子任务
subtasks = [
Task(
id=f"{task.id}.{i}",
description=st.description,
type=st.type,
parent_id=task.id,
depth=depth + 1,
)
for i, st in enumerate(plan.subtasks)
]
# 并行执行子任务
results = await asyncio.gather(
*[self._delegate_to_agent(st) for st in subtasks],
return_exceptions=True # 捕获异常,不中断其他任务
)
# 处理失败的子任务
failed = [r for r in results if isinstance(r, Exception)]
if failed:
# 触发故障转移
return await self._handle_failures(task, failed)
# 汇总结果
return await self._aggregate_results(results, task)
else:
# 直接执行(无需分解)
agent = await self.pool.acquire(task.type)
try:
return await agent.execute(task)
finally:
await self.pool.release(agent)
async def _delegate_to_agent(self, subtask: Task) -> Result:
"""委派子任务给 Agent"""
agent = await self.pool.acquire(subtask.type)
try:
# 执行子任务
result = await agent.execute(subtask)
# 如果子任务需要进一步分解,递归调用
if result.needs_further_work:
return await self.execute_task(result.next_task, subtask.depth)
return result
finally:
# 释放 Agent 实例回池
await self.pool.release(agent)
async def _plan_task(self, task: Task) -> Plan:
"""分析任务,生成执行计划"""
# 决策节点 Span
with self.tracer.decision_span(
decision_type="task_decomposition",
reasoning=f"分析任务 {task.id} 是否需要分解"
) as decision_span:
# 简单任务直接执行
if task.complexity < 3:
decision_span.set_attribute("needs_delegation", False)
return Plan(needs_delegation=False)
# 复杂任务分解为子任务
subtasks = await self._decompose_task(task)
decision_span.set_attribute("needs_delegation", True)
decision_span.set_attribute("subtask_count", len(subtasks))
return Plan(needs_delegation=True, subtasks=subtasks)
关键设计要点:
-
- 深度限制保护:最大委派深度为 5 层,防止任务递归失控导致栈溢出
-
- 并行执行优化:使用
asyncio.gather并行执行子任务,提升效率
- 并行执行优化:使用
-
- 异常隔离:
return_exceptions=True确保单个子任务失败不影响其他任务
- 异常隔离:
-
- 资源管理:使用
try-finally确保 Agent 实例始终被释放回池
- 资源管理:使用
-
- 追踪集成:DELEGATION 和 DECISION Span 记录完整的委派和决策过程
AgentInstancePool:对象池模式实现
AgentInstancePool 采用对象池模式管理 Agent 实例的生命周期,避免频繁创建销毁带来的性能开销:
class AgentInstancePool:
"""Agent 实例池"""
def __init__(self, max_size: int = 10):
self.max_size = max_size
self._pools: dict[str, asyncio.Queue] = {} # 按类型分池
self._active: dict[str, int] = {} # 活跃实例计数
self._lock = asyncio.Lock()
async def acquire(self, agent_type: str) -> Agent:
"""获取 Agent 实例"""
async with self._lock:
# 初始化该类型的池
if agent_type not in self._pools:
self._pools[agent_type] = asyncio.Queue(maxsize=self.max_size)
self._active[agent_type] = 0
pool = self._pools[agent_type]
try:
# 尝试从池中获取空闲实例(非阻塞)
agent = pool.get_nowait()
logger.debug(f"复用 Agent 实例: {agent_type}")
return agent
except asyncio.QueueEmpty:
# 池为空,检查是否可以创建新实例
async with self._lock:
if self._active[agent_type] < self.max_size:
# 创建新实例
agent = await self._create_agent(agent_type)
self._active[agent_type] += 1
logger.debug(f"创建新 Agent 实例: {agent_type} (活跃: {self._active[agent_type]})")
return agent
# 达到上限,等待空闲实例
logger.debug(f"等待 Agent 实例: {agent_type}")
return await pool.get()
async def release(self, agent: Agent) -> None:
"""释放 Agent 实例回池"""
agent_type = agent.type
pool = self._pools.get(agent_type)
if pool is None:
logger.warning(f"未知的 Agent 类型: {agent_type}")
return
try:
# 重置 Agent 状态
await agent.reset()
# 放回池中(非阻塞)
pool.put_nowait(agent)
logger.debug(f"释放 Agent 实例: {agent_type}")
except asyncio.QueueFull:
# 池已满,销毁实例
async with self._lock:
self._active[agent_type] -= 1
await agent.cleanup()
logger.debug(f"销毁多余 Agent 实例: {agent_type}")
async def _create_agent(self, agent_type: str) -> Agent:
"""创建新的 Agent 实例"""
# 根据类型创建对应的 Agent
agent_class = AGENT_REGISTRY.get(agent_type)
if agent_class is None:
raise ValueError(f"未注册的 Agent 类型: {agent_type}")
return await agent_class.create()
async def shutdown(self) -> None:
"""关闭池,清理所有实例"""
for agent_type, pool in self._pools.items():
while not pool.empty():
agent = await pool.get()
await agent.cleanup()
logger.info(f"清理 Agent 池: {agent_type}")
对象池的性能优势:
| 指标 | 无池化 | 有池化 | 提升 |
|---|---|---|---|
| Agent 创建耗时 | 200-500ms | 0-5ms(复用) | 40-100x |
| 内存占用峰值 | 不稳定 | 稳定(max_size限制) | 可控 |
| 并发任务处理 | 受限于创建速度 | 受限于池大小 | 10x+ |
委派深度限制的实际意义:
5 层委派深度的设计基于以下考虑:
-
- 防止循环依赖:任务 A 委派给 B,B 又委派回 A,形成死循环
-
- 控制复杂度:超过 5 层通常意味着任务分解过细,应该重新设计
-
- 资源保护:每层委派都会占用内存和 Agent 实例,深度过大会耗尽资源
-
- 可追踪性:5 层以内的调用链人类可以理解,超过则难以调试
实际案例中,大多数任务的委派深度在 2-3 层:
层级 1: 用户请求 → AgentOrchestrator
层级 2: 搜索任务 → SearchAgent
层级 3: 网页抓取 → BrowserAgent
故障转移与容错机制
OpenAkita 的 FallbackResolver 实现了三层容错策略:
-
- Agent 级故障转移:当某个 Agent 执行失败时,自动切换到同类型的备用 Agent。例如,搜索 Agent A 超时,立即启用搜索 Agent B。
-
- 策略级降级:如果所有同类型 Agent 都失败,系统会调整策略。例如,网络搜索失败后,切换到本地知识库检索。
-
- 任务级重试:对于临时性错误(网络波动、API 限流),系统会使用指数退避算法自动重试,最多 3 次。
以下是故障转移的实现示例:
class FallbackResolver:
def __init__(self, max_retries=3):
self.max_retries = max_retries
self.backoff_base = 2 # 指数退避基数
async def execute_with_fallback(self, task: Task, agents: List[Agent]) -> Result:
"""带故障转移的任务执行"""
last_error = None
for agent in agents:
for attempt in range(self.max_retries):
try:
result = await agent.execute(task)
return result
except TemporaryError as e:
# 临时错误,指数退避后重试
wait_time = self.backoff_base ** attempt
await asyncio.sleep(wait_time)
last_error = e
except PermanentError as e:
# 永久错误,立即切换到下一个 Agent
last_error = e
break
# 所有 Agent 都失败,尝试策略降级
fallback_result = await self.try_fallback_strategy(task, last_error)
if fallback_result:
return fallback_result
raise AllAgentsFailedError(f"所有 Agent 执行失败: {last_error}")
async def try_fallback_strategy(self, task: Task, error: Exception) -> Optional[Result]:
"""策略降级"""
if isinstance(error, NetworkError):
# 网络错误,切换到离线模式
return await self.execute_offline(task)
elif isinstance(error, RateLimitError):
# 限流错误,切换到备用 API
return await self.execute_with_backup_api(task)
return None
可视化 Agent 仪表盘
OpenAkita 桌面应用内置神经网络风格的 Agent 仪表盘,实时显示每个 Agent 的工作状态:
- • 节点图:每个 Agent 显示为一个节点,连线表示任务委派关系
- • 状态指示:颜色编码显示 Agent 状态(绿色=运行中,黄色=等待,红色=失败,灰色=空闲)
- • 实时追踪:12 种 Span 类型追踪 Agent 行为(推理、工具调用、内存访问、委派等)
- • 性能指标:显示每个 Agent 的 token 消耗、执行时间、成功率
用户可以在仪表盘上:
- • 点击节点查看 Agent 详细日志
- • 暂停/恢复特定 Agent
- • 手动触发故障转移
- • 导出完整追踪数据用于调试
实际应用案例
以"生成竞品分析报告"为例,展示完整的多 Agent 协作流程:
用户输入:"帮我做一份 OpenAI 和 Anthropic 的竞品分析报告"
AgentOrchestrator 分析:
├─ 任务类型:复杂报告生成
├─ 需要分解:是
└─ 子任务规划:
├─ 子任务1:搜索 OpenAI 最新动态
├─ 子任务2:搜索 Anthropic 最新动态
├─ 子任务3:对比分析两家公司
└─ 子任务4:生成 Markdown 报告
执行流程:
[并行执行]
├─ SearchAgent-1 → 搜索 OpenAI
│ ├─ 调用 web_search 工具
│ ├─ 提取关键信息
│ └─ 返回结构化数据
│
└─ SearchAgent-2 → 搜索 Anthropic
├─ 调用 web_search 工具
├─ 网络超时 ❌
├─ FallbackResolver 触发
├─ 切换到 SearchAgent-3
├─ 重试成功 ✅
└─ 返回结构化数据
[串行执行]
├─ AnalysisAgent → 对比分析
│ ├─ 接收两个搜索结果
│ ├─ 调用 LLM 进行深度分析
│ └─ 生成对比表格
│
└─ WritingAgent → 生成报告
├─ 接收分析结果
├─ 调用 file_write 工具
└─ 输出 report.md
总耗时:45 秒
Token 消耗:12,500 tokens
Agent 调用:4 个(含 1 次故障转移)
这个案例展示了 OpenAkita 多 Agent 系统的三个核心优势:
-
- 并行加速:搜索任务并行执行,节省 50% 时间
-
- 自动容错:SearchAgent-2 失败后自动切换,用户无感知
-
- 专业分工:搜索、分析、写作各司其职,输出质量更高
4. 总结与展望
MCP 协议作为 AI Agent 的基础设施标准,在 2026 年已被 OpenAI、Microsoft、Google 等主要厂商采用,成为事实上的"AI 的 USB-C"。然而,上下文窗口的快速消耗是 MCP 应用中的主要瓶颈。Context Mode 通过沙盒执行、智能过滤和 FTS5 知识库三层架构,将工具输出压缩 98%,会话时长延长 6 倍,为 MCP 的实际应用提供了可行的优化方案。
OpenAkita 作为开源 AI Agent 框架,采用模块化架构、Markdown 内存系统和 ReAct 推理机制,展示了构建生产级 AI Agent 的工程实践。其核心设计哲学——分离认知与执行、可观测的决策过程、基于纯文本的状态管理——为 AI Agent 开发提供了新的思路。多 Agent 协作机制让复杂任务的自动化成为可能,从竞品监控到代码审查,从数据分析到内容生成,都可以通过 Agent 编排实现。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2026 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献190条内容
已为社区贡献190条内容

所有评论(0)