深度学习实战-基于EffcientNetB0与MobileNetV3的植物病害图像识别模型

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录

1.项目背景
植物病害是影响农作物产量和品质的重要因素,白粉病和锈病作为两种常见的真菌性病害,对多种经济作物造成严重威胁。传统病害识别主要依赖农业技术人员或植保专家的现场观察和经验判断,这种方法效率较低且对专业知识要求较高,难以实现大范围的快速监测。随着农业生产规模化发展和精准农业理念的推广,对植物健康状况进行及时、准确的自动化识别需求日益迫切。
近年来,数字图像技术和移动设备的普及使得田间作物图像采集变得更加便捷,大量植物病害图像数据得以积累。这些图像中包含着叶片颜色变化、斑点形态、纹理特征等重要诊断信息,但不同病害之间可能存在相似的视觉表现,如白粉病的白色粉末状斑点与某些生理性白斑容易混淆,锈病的橙黄色孢子堆与自然枯黄也存在区分难度。这些细微差异对人眼识别构成挑战,却为计算机视觉技术提供了应用空间。
本研究旨在探索深度学习技术在植物病害自动识别中的应用效果,通过构建基于卷积神经网络的图像分类模型,实现对健康植物、白粉病和锈病三种状态的准确区分。考虑到实际应用场景中对模型精度和效率的双重需求,实验同时采用了两种不同特点的网络架构,并引入协同学习策略以提升模型性能,为开发实用的农业病虫害监测工具提供技术参考。
2.数据集介绍
本实验数据集来源于Kaggle,该数据集包含三个标签:“健康”、“粉状”和“锈病”,分别指代植物的生长状况。数据集共包含1530张图像,分为训练集、测试集和验证集。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
首先导入必要的Python库、设置随机种子确保实验可重复性,以及配置基本的训练参数。
# 导入基础数据处理和可视化库
import numpy as np # 数值计算库,用于数组和矩阵运算
import pandas as pd # 数据分析库,用于处理表格数据
import matplotlib.pyplot as plt # 绘图库,用于数据可视化
import seaborn as sns # 统计图形库,提供更美观的可视化效果
import warnings # 警告处理模块
warnings.filterwarnings("ignore") # 忽略警告信息,使输出更清晰
import os # 操作系统接口,用于文件路径操作
from PIL import Image # 图像处理库,用于图像加载和转换
# 导入机器学习评估工具
from sklearn.metrics import confusion_matrix, classification_report # 混淆矩阵和分类报告
# 导入PyTorch深度学习框架相关模块
import torch # PyTorch主库
import torch.nn as nn # 神经网络模块
from torch.utils.data import Dataset, DataLoader # 数据集和数据加载器
from torchvision.transforms import InterpolationMode # 图像插值模式
from torchvision import transforms, datasets # 图像转换和数据集工具
import torchvision.models as models # 预训练模型库
# 设置随机种子以确保实验可重复性
def set_seed(seed=42):
"""
设置随机种子,确保实验结果可重复
参数:
seed: 随机种子值,默认为42
"""
np.random.seed(seed) # 设置NumPy随机种子
torch.manual_seed(seed) # 设置PyTorch CPU随机种子
torch.cuda.manual_seed_all(seed) # 设置所有GPU的随机种子
torch.backends.cudnn.deterministic = True # 确保卷积操作具有确定性
torch.backends.cudnn.benchmark = True # 启用cudnn自动优化
set_seed(42) # 调用函数设置随机种子
# 自动选择计算设备:优先使用CUDA(NVIDIA GPU),其次使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")接着定义数据集的路径、类别信息,并配置了图像预处理流程。植物病害图像通常需要在训练时进行充分的数据增强,以应对自然环境中光照、角度、尺度等变化。
# 定义数据集路径
train_dir = "./plant-disease-recognition-dataset/Train/Train" # 训练集目录
test_dir = "./plant-disease-recognition-dataset/Test/Test" # 测试集目录
val_dir = "./plant-disease-recognition-dataset/Validation/Validation" # 验证集目录
# 定义病害类别
categories = ["Healthy", "Powdery", "Rust"] # 健康植物、白粉病、锈病
# 定义图像尺寸和批量大小
image_size = 320 # 图像目标尺寸(EfficientNetB0推荐输入尺寸)
batch_size = 16 # 每个训练批次包含的图像数量
# 定义ImageNet数据集的均值和标准差(用于归一化)
# 这是使用预训练模型时的标准预处理参数
IMAGENET_MEAN = [0.485, 0.456, 0.406]
IMAGENET_STD = [0.229, 0.224, 0.225]
# 训练集的数据增强和预处理流程
train_transform = transforms.Compose([
# 先将图像调整到稍大尺寸(352x352),为后续裁剪留出空间
transforms.Resize((image_size + 32, image_size + 32), interpolation=InterpolationMode.BICUBIC),
# 随机裁剪并调整到目标尺寸,模拟不同拍摄距离
transforms.RandomResizedCrop(image_size, scale=(0.8, 1.0)),
# 随机水平翻转(概率50%),模拟不同拍摄角度
transforms.RandomHorizontalFlip(p=0.5),
# 随机垂直翻转(概率50%)
transforms.RandomVerticalFlip(p=0.5),
# 随机旋转(±20度),模拟不同叶片朝向
transforms.RandomRotation(degrees=20),
# 随机调整颜色属性,模拟不同光照条件
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.02),
# 将PIL图像转换为PyTorch张量,并自动将像素值归一化到[0,1]
transforms.ToTensor(),
# 使用ImageNet统计量进行标准化(均值和标准差归一化)
transforms.Normalize(IMAGENET_MEAN, IMAGENET_STD),
])
# 验证集和测试集的预处理流程(不进行数据增强)
val_test_transform = transforms.Compose([
# 调整到稍大尺寸
transforms.Resize((image_size + 32, image_size + 32)),
# 中心裁剪到目标尺寸,确保评估时的一致性
transforms.CenterCrop(image_size),
# 转换为张量
transforms.ToTensor(),
# 标准化
transforms.Normalize(IMAGENET_MEAN, IMAGENET_STD),
])4.2数据可视化

在开始模型训练之前,我们需要确认数据增强操作是否按预期工作,以及经过变换后的图像是否仍然保持可识别性。这对于理解数据增强的实际效果和确保后续模型训练质量非常重要。
# 定义反归一化函数,将标准化后的图像还原到可显示的范围
def denormalize(tensor):
"""
将标准化后的图像张量还原到原始像素值范围[0,1]
参数:
tensor: 经过标准化处理的图像张量
返回:
反归一化后的图像张量
"""
# 创建均值和标准差张量,并调整维度用于广播计算
mean = torch.tensor([0.485, 0.456, 0.406]).view(3, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).view(3, 1, 1)
# 克隆张量并分离计算图,将数据移动到CPU
img = tensor.clone().detach().cpu()
# 反归一化:原始值 = 标准化值 * std + mean
img = img * std + mean
# 将像素值限制在[0,1]范围内,确保图像显示正常
return img.clamp(0, 1)
# 创建一个1行3列的子图布局,用于展示3个类别的图像
# figsize=(15, 6)设置图形大小为15x6英寸
fig, axes = plt.subplots(1, 3, figsize=(15, 6))
# 遍历三个病害类别:健康植物、白粉病、锈病
for i, category in enumerate(categories):
# 构建当前类别的文件夹路径
folder_path = os.path.join(train_dir, category)
# 获取该文件夹中的所有图像文件
files = os.listdir(folder_path)
# 选择第68个文件(索引从0开始,所以files[67]是第68个)
# 这个选择是随意的,主要是为了展示一个典型样本
img_path = os.path.join(folder_path, files[67])
# 使用PIL库打开原始图像
original_img = Image.open(img_path)
# 对原始图像应用训练时使用的数据增强变换
transformed_tensor = train_transform(original_img)
# 将标准化后的图像张量反归一化,恢复到可显示的范围
vis_img = denormalize(transformed_tensor)
# 调整张量维度顺序:从PyTorch的(C,H,W)转换为matplotlib的(H,W,C)
vis_img = vis_img.permute(1, 2, 0).numpy()
# 在当前子图中显示处理后的图像
axes[i].imshow(vis_img)
# 设置子图标题,显示对应的病害类别
axes[i].set_title(f"Transformed: {category}")
# 关闭坐标轴,让图像显示更清晰
axes[i].axis('off')
# 自动调整子图布局,避免标题和图像重叠
plt.tight_layout()
# 显示完整图形
plt.show()
4.3特征工程
首先使用PyTorch提供的数据集工具创建标准的数据集对象,并将其包装成数据加载器,为模型训练做好数据准备。
# ------------------- 创建数据集对象 -------------------
# 使用ImageFolder类自动创建数据集,它会根据文件夹结构识别类别
train_dataset = datasets.ImageFolder(root=train_dir, transform=train_transform) # 训练集
val_dataset = datasets.ImageFolder(root=val_dir, transform=val_test_transform) # 验证集
test_dataset = datasets.ImageFolder(root=test_dir, transform=val_test_transform) # 测试集
# ------------------- 创建数据加载器 -------------------
# 训练数据加载器
train_loader = DataLoader(
train_dataset, # 训练数据集
batch_size=batch_size, # 每批16张图像
shuffle=True, # 每个epoch打乱数据顺序,避免模型学习到数据顺序
num_workers=3, # 使用3个子进程加载数据,提高IO效率
pin_memory=True # 使用固定内存,加速数据从CPU到GPU的传输
)
# 验证数据加载器
val_loader = DataLoader(
val_dataset, # 验证数据集
batch_size=batch_size,
shuffle=False, # 验证集不需要打乱,保持固定顺序便于评估
num_workers=3,
pin_memory=True
)
# 测试数据加载器
test_loader = DataLoader(
test_dataset, # 测试数据集
batch_size=batch_size,
shuffle=False, # 测试集也不需要打乱
num_workers=3,
pin_memory=True
)接着定义了一系列用于模型评估和训练辅助的函数,包括混淆矩阵绘制、预测获取、协同学习步骤和评估指标计算等工具。
# 定义混淆矩阵绘制函数
def plot_cm(cm, title):
"""
绘制混淆矩阵热力图
参数:
cm: 混淆矩阵数组
title: 图表标题
"""
plt.figure(figsize=(6, 5)) # 设置图形大小
# 绘制热力图,显示数值,使用整数格式,蓝色调色板
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=categories, yticklabels=categories)
plt.title(title) # 设置标题
plt.ylabel("True") # y轴标签:真实类别
plt.xlabel("Predicted") # x轴标签:预测类别
plt.show()
# 定义获取预测结果和真实标签的函数
def get_preds_labels(model, dataloader, device):
"""
获取模型在指定数据集上的所有预测结果和真实标签
参数:
model: 待评估的模型
dataloader: 数据加载器
device: 计算设备
返回:
all_preds: 所有预测结果的数组
all_labels: 所有真实标签的数组
"""
model.eval() # 设置模型为评估模式
all_preds = [] # 存储所有预测结果
all_labels = [] # 存储所有真实标签
with torch.no_grad(): # 禁用梯度计算,节省内存
for x, y in dataloader:
x, y = x.to(device), y.to(device) # 将数据移动到指定设备
out = model(x) # 前向传播
preds = out.argmax(dim=1) # 获取预测类别(最大概率对应的索引)
# 将当前批次的预测和标签添加到列表中
all_preds.extend(preds.cpu().numpy()) # 转移到CPU并转换为numpy数组
all_labels.extend(y.cpu().numpy())
return np.array(all_preds), np.array(all_labels)
# 定义双模型协同学习步骤(DML: Deep Mutual Learning)
def dml_step(images, labels, studentA, studentB):
"""
双模型协同学习的单步训练
两个模型互相学习对方的预测分布作为软标签
参数:
images: 输入图像
labels: 真实标签
studentA: 第一个模型
studentB: 第二个模型
返回:
lossA: 第一个模型的损失
lossB: 第二个模型的损失
"""
images = images.cuda() # 将图像移动到GPU
labels = labels.cuda() # 将标签移动到GPU
# 前向传播:两个模型分别预测
outA = studentA(images)
outB = studentB(images)
# 计算log-softmax,用于KL散度损失
log_pA = torch.log_softmax(outA, dim=1)
log_pB = torch.log_softmax(outB, dim=1)
# 从对方模型获取软标签(经过softmax的预测分布)
pA = torch.softmax(outA.detach(), dim=1) # 分离计算图,防止梯度传播
pB = torch.softmax(outB.detach(), dim=1)
# 计算交叉熵损失(硬标签监督)
ceA = criterion_ce(outA, labels)
ceB = criterion_ce(outB, labels)
# 计算KL散度损失(软标签监督,向对方模型学习)
klA = criterion_kl(log_pA, pB)
klB = criterion_kl(log_pB, pA)
λ = 0.5 # KL散度损失的权重系数
# 总损失 = 交叉熵损失 + λ * KL散度损失
lossA = ceA + λ * klA
lossB = ceB + λ * klB
return lossA, lossB
# 定义准确率评估函数
def evaluate(model, loader):
"""
计算模型在指定数据集上的准确率
参数:
model: 待评估的模型
loader: 数据加载器
返回:
准确率(0-1之间的浮点数)
"""
model.eval() # 设置模型为评估模式
correct = 0 # 正确预测计数
total = 0 # 总样本计数
with torch.no_grad(): # 禁用梯度计算
for images, labels in loader:
images = images.cuda()
labels = labels.cuda()
out = model(images) # 前向传播
preds = torch.argmax(out, dim=1) # 获取预测类别
correct += (preds == labels).sum().item() # 统计正确预测数
total += labels.size(0) # 累加样本数
return correct / total # 返回准确率
# 定义损失和准确率评估函数
def evaluate_loss_and_acc(model, loader, criterion):
"""
同时计算模型在指定数据集上的平均损失和准确率
参数:
model: 待评估的模型
loader: 数据加载器
criterion: 损失函数
返回:
avg_loss: 平均损失
acc: 准确率
"""
model.eval() # 设置模型为评估模式
total_loss = 0 # 总损失
correct = 0 # 正确预测计数
total = 0 # 总样本计数
with torch.no_grad(): # 禁用梯度计算
for images, labels in loader:
images = images.cuda()
labels = labels.cuda()
outputs = model(images) # 前向传播
loss = criterion(outputs, labels) # 计算损失
total_loss += loss.item() # 累加损失
preds = torch.argmax(outputs, dim=1) # 获取预测类别
correct += (preds == labels).sum().item() # 统计正确预测数
total += labels.size(0) # 累加样本数
avg_loss = total_loss / len(loader) # 计算平均损失(除以批次数)
acc = correct / total # 计算准确率
return avg_loss, acc4.4构建模型
这里我们定义了用于植物病害识别的深度学习模型架构,并采用了创新的双模型协同学习策略。我们同时构建了两个不同的模型——基于EfficientNetB0和MobileNetV3,让它们在训练过程中互相学习,这种设计既能利用不同架构的优势,又能通过协同学习提升各自的性能。
# 定义学生模型类(基础模型架构)
class StudentModel(nn.Module):
def __init__(self, model_name, num_classes=4):
"""
初始化学生模型
参数:
model_name: 模型名称,可选"effnet_b0"或"mobilenet_v3_large"
num_classes: 分类类别数,默认为4(根据实际任务调整)
"""
super().__init__() # 调用父类构造函数
# 根据模型名称选择不同的预训练骨干网络
if model_name == "effnet_b0":
# 加载预训练的EfficientNetB0模型
# weights参数指定使用ImageNet预训练权重
self.backbone = models.efficientnet_b0(weights=models.EfficientNet_B0_Weights.IMAGENET1K_V1)
# 移除原始分类头,保留特征提取部分
self.backbone.classifier = nn.Identity() # 使用恒等映射替换分类器
elif model_name == "mobilenet_v3_large":
# 加载预训练的MobileNetV3-Large模型
self.backbone = models.mobilenet_v3_large(weights=models.MobileNet_V3_Large_Weights.IMAGENET1K_V1)
# 同样移除原始分类头
self.backbone.classifier = nn.Identity()
# 创建一个虚拟输入张量,用于计算骨干网络输出维度
dummy = torch.randn(1, 3, 224, 224) # 批量大小1,3通道,224x224尺寸
# 在不计算梯度的情况下进行前向传播
with torch.no_grad():
out = self.backbone(dummy) # 通过骨干网络
# 获取骨干网络输出的特征维度
in_features = out.shape[1] # 形状为(batch_size, feature_dim)
# 自定义分类头(全连接层部分)
self.head = nn.Sequential(
# 第一层全连接:骨干特征 -> 128维
nn.Linear(in_features, 128),
nn.BatchNorm1d(128), # 一维批归一化,加速训练并提高稳定性
nn.ReLU(), # ReLU激活函数
nn.Dropout(0.4), # 40%丢弃率,防止过拟合
# 第二层全连接:128维 -> 64维
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Dropout(0.3), # 30%丢弃率
# 输出层:64维 -> 类别数
nn.Linear(64, num_classes)
# 注意:这里没有使用激活函数,因为交叉熵损失内部会处理
)
def forward(self, x):
"""
前向传播过程
参数:
x: 输入图像张量
返回:
out: 模型输出(类别得分)
"""
feats = self.backbone(x) # 通过骨干网络提取特征
out = self.head(feats) # 通过自定义分类头进行分类
return out
# 实例化两个不同的学生模型
# 学生A使用EfficientNetB0作为骨干网络
studentA = StudentModel("effnet_b0").cuda() # 创建模型并立即移动到GPU
# 学生B使用MobileNetV3-Large作为骨干网络
studentB = StudentModel("mobilenet_v3_large").cuda()
# 分别为两个模型创建优化器
# 使用AdamW优化器(Adam的改进版,包含权重衰减)
# lr=1e-4: 初始学习率0.0001
# weight_decay=1e-4: L2正则化系数,防止过拟合
optimizerA = torch.optim.AdamW(studentA.parameters(), lr=1e-4, weight_decay=1e-4)
optimizerB = torch.optim.AdamW(studentB.parameters(), lr=1e-4, weight_decay=1e-4)
# 定义损失函数
# 交叉熵损失:用于真实标签的监督学习
criterion_ce = nn.CrossEntropyLoss()
# KL散度损失:用于模型间相互学习的软标签监督
# reduction="batchmean": 在批次维度上取平均
criterion_kl = nn.KLDivLoss(reduction="batchmean")说明:这里我们构建了一个创新的双模型协同学习框架。两个模型采用了不同的骨干网络架构:EfficientNetB0以高精度著称,而MobileNetV3-Large则在精度和效率之间取得了良好平衡。通过移除预训练模型的原始分类头并添加自定义的分类头,我们既利用了预训练模型在ImageNet上学到的通用视觉特征,又针对植物病害识别任务进行了专门调整。
模型的自定义分类头设计了三层全连接结构,并包含批归一化、ReLU激活和Dropout正则化,这种设计适合中等规模的数据集。两个模型将使用深度互学习策略进行协同训练,它们不仅从真实标签学习,还从对方的预测分布中学习,这种互相教学的过程往往能产生比单独训练更好的效果。
优化器选择了AdamW,这是Adam优化器的改进版本,能更好地处理权重衰减。两个损失函数分别用于处理硬标签监督(交叉熵损失)和软标签监督(KL散度损失)。这种双模型协同学习的设计思路在植物病害识别任务中特别有意义,因为不同的网络架构可能捕捉到不同的病害特征,通过互相学习可以形成更好的特征表示。
4.5训练模型
这里我们实现了双模型协同学习的完整训练过程。我们同时训练两个不同的神经网络架构,让它们在训练过程中互相学习对方的预测知识。这种深度互学习策略能够提升单个模型的性能,特别适合植物病害识别这种需要高可靠性的应用场景。
# 初始化最佳验证损失记录
# 使用正无穷作为初始值,确保第一个epoch的结果能更新记录
best_val_loss_A = float("inf") # 学生A的最佳验证损失
best_val_loss_B = float("inf") # 学生B的最佳验证损失
# 设置训练轮数
epochs = 15
# 开始训练循环
for epoch in range(epochs):
# 设置两个模型为训练模式
# 训练模式下会启用Dropout和BatchNorm的随机性
studentA.train()
studentB.train()
# 初始化每个epoch的损失累加器
running_loss_A = 0 # 学生A的训练损失累加
running_loss_B = 0 # 学生B的训练损失累加
# 遍历训练数据加载器中的所有批次
for images, labels in train_loader:
# 清空优化器中的梯度缓存
# 每次迭代前需要清空梯度,防止梯度累积
optimizerA.zero_grad()
optimizerB.zero_grad()
# 执行深度互学习步骤
# 两个模型同时处理同一批数据,并计算相互学习的损失
lossA, lossB = dml_step(images, labels, studentA, studentB)
# 反向传播:计算梯度
lossA.backward() # 计算学生A的梯度
lossB.backward() # 计算学生B的梯度
# 更新模型参数
optimizerA.step() # 根据梯度更新学生A的参数
optimizerB.step() # 根据梯度更新学生B的参数
# 累加当前批次的损失值
running_loss_A += lossA.item() # .item()将标量张量转换为Python浮点数
running_loss_B += lossB.item()
# ------------------- 计算训练指标 -------------------
# 计算平均训练损失:总损失除以批次数量
train_loss_A = running_loss_A / len(train_loader)
train_loss_B = running_loss_B / len(train_loader)
# 计算训练准确率
train_acc_A = evaluate(studentA, train_loader)
train_acc_B = evaluate(studentB, train_loader)
# ------------------- 计算验证指标 -------------------
# 计算验证损失和准确率
val_loss_A, val_acc_A = evaluate_loss_and_acc(studentA, val_loader, criterion_ce)
val_loss_B, val_acc_B = evaluate_loss_and_acc(studentB, val_loader, criterion_ce)
# ------------------- 打印训练进度 -------------------
# 打印当前epoch的详细结果
print(f"\nEpoch [{epoch+1}/{epochs}]")
print(f" Student A → TrainLoss: {train_loss_A:.4f} | TrainAcc: {train_acc_A:.4f} | ValLoss: {val_loss_A:.4f} | ValAcc: {val_acc_A:.4f}")
print(f" Student B → TrainLoss: {train_loss_B:.4f} | TrainAcc: {train_acc_B:.4f} | ValLoss: {val_loss_B:.4f} | ValAcc: {val_acc_B:.4f}")
# ------------------- 保存最佳模型 -------------------
# 如果学生A的当前验证损失优于历史最佳,则保存其状态
if val_loss_A < best_val_loss_A:
best_val_loss_A = val_loss_A # 更新最佳验证损失记录
best_state_A = studentA.state_dict().copy() # 深度复制模型的状态字典
# 如果学生B的当前验证损失优于历史最佳,则保存其状态
if val_loss_B < best_val_loss_B:
best_val_loss_B = val_loss_B
best_state_B = studentB.state_dict().copy()
# ------------------- 加载最佳模型状态 -------------------
# 训练结束后,将两个模型恢复到验证集上表现最好的状态
studentA.load_state_dict(best_state_A)
studentB.load_state_dict(best_state_B)
说明:这里我们实现了完整的双模型协同训练流程。每个epoch中,两个模型同时处理相同的训练数据,不仅从真实标签学习(通过交叉熵损失),还从对方的预测分布学习(通过KL散度损失)。这种互相教学的过程使得两个模型能够互相促进,往往能比单独训练获得更好的性能。
训练过程中,我们实时监控并记录每个模型的训练损失、训练准确率、验证损失和验证准确率。每轮训练结束后,如果某个模型在验证集上的表现创造了新的最佳记录,我们就保存该模型的状态字典。这种基于验证损失选择最佳模型的方法能够有效防止过拟合,确保我们最终得到的是泛化能力最好的模型。
对于植物病害识别任务,这种训练策略特别有价值:不同的网络架构可能擅长识别不同类型的病害特征,比如EfficientNetB0可能更擅长捕捉细微的纹理变化(如白粉病的粉末状斑点),而MobileNetV3可能对形状和边缘更敏感。通过互相学习,两个模型能够融合对方的优势,提升各自的识别能力。训练结束后,我们加载验证集上表现最好的模型状态,确保部署时使用最优的模型版本。
4.6模型评估
首先计算两个模型在测试集上的最终性能指标,包括损失值和准确率,这是评估模型好坏的最直接指标。
# 评估学生A(EfficientNetB0)在测试集上的表现
# evaluate_loss_and_acc函数同时返回平均损失和准确率
test_loss_A, test_acc_A = evaluate_loss_and_acc(studentA, test_loader, criterion_ce)
# 评估学生B(MobileNetV3-Large)在测试集上的表现
test_loss_B, test_acc_B = evaluate_loss_and_acc(studentB, test_loader, criterion_ce)
# 打印最终的测试结果
print("===== FINAL TEST RESULTS =====")
print(f"Student A (EffNetB0): Loss={test_loss_A:.4f} | Acc={test_acc_A:.4f}")
print(f"Student B (MobV3-Large): Loss={test_loss_B:.4f} | Acc={test_acc_B:.4f}")
接着对EfficientNetB0模型进行更细致的评估,包括生成分类报告和混淆矩阵,帮助我们了解模型在各个类别上的具体表现。
# 获取学生A(EfficientNetB0)在测试集上的所有预测结果和真实标签
# get_preds_labels函数返回预测结果数组和真实标签数组
a_preds, a_labels = get_preds_labels(studentA, test_loader, device)
# 打印EfficientNetB0模型的分类报告
print("=== EfficientNetB0 Classification Report ===")
# classification_report提供精确率、召回率、F1分数等详细指标
# target_names参数指定类别名称,使报告更易读
print(classification_report(a_preds, a_labels, target_names=categories))
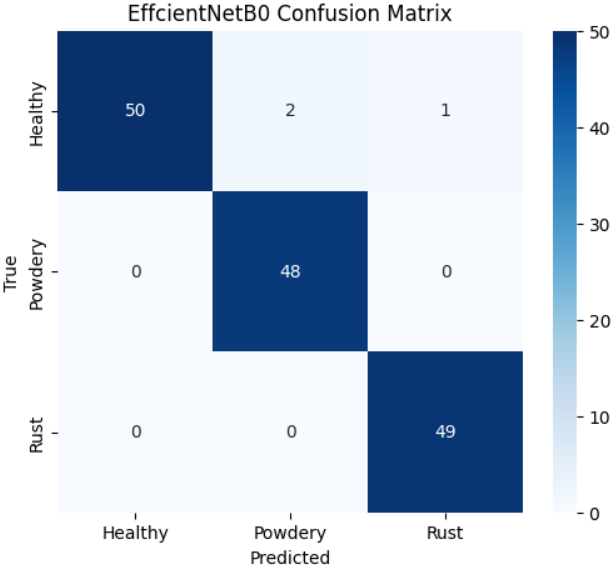
# 计算并绘制EfficientNetB0的混淆矩阵
a_cm = confusion_matrix(a_preds, a_labels) # 计算混淆矩阵
plot_cm(a_cm, "EffcientNetB0 Confusion Matrix") # 绘制混淆矩阵热力图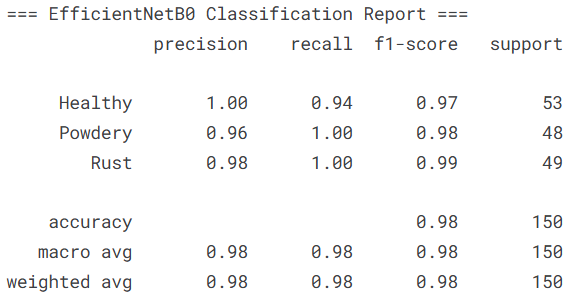
接着对MobileNetV3-Large模型进行同样的详细评估,便于与第一个模型进行比较。
# 获取学生B(MobileNetV3-Large)在测试集上的所有预测结果和真实标签
b_preds, b_labels = get_preds_labels(studentB, test_loader, device)
# 打印MobileNetV3-Large模型的分类报告
print("=== MobileNetV3-Large Classification Report ===")
print(classification_report(b_preds, b_labels, target_names=categories))
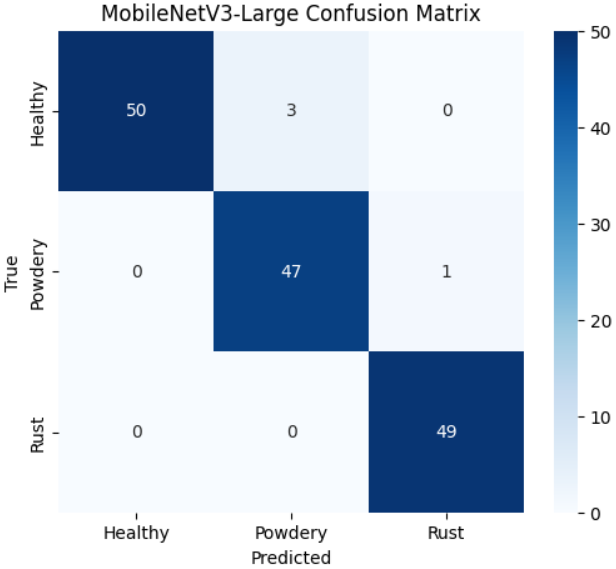
# 计算并绘制MobileNetV3-Large的混淆矩阵
b_cm = confusion_matrix(b_preds, b_labels)
plot_cm(b_cm, "MobileNetV3-Large Confusion Matrix")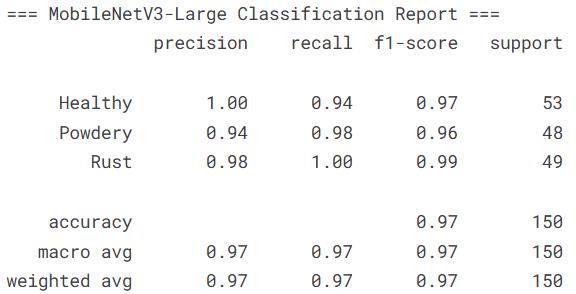
5.总结
本文基于EfficientNetB0和MobileNetV3-Large构建了植物病害图像识别模型,采用深度互学习策略进行协同训练,在包含健康、白粉病和锈病三类植物状态的数据集上取得了优异性能。实验结果表明,两个模型在测试集上均表现出色,其中EfficientNetB0模型达到98.00%的准确率,MobileNetV3-Large模型达到97.33%的准确率,均能有效区分不同植物健康状态。分类报告显示两个模型在各病害类别上的精确率、召回率和F1分数均超过0.94,表明模型不仅整体识别准确率高,且在不同病害类型上的表现均衡稳定。通过深度互学习训练策略,两个不同架构的模型互相促进学习,有效提升了各自的识别能力。混淆矩阵分析表明模型对锈病的识别最为准确,白粉病与健康植物之间存在轻微混淆但总体可控。该研究为植物病害的自动化识别提供了可行的深度学习解决方案,模型具备较高的实际应用价值,可为农业病虫害监测提供技术支持。
源代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
import os
from PIL import Image
from sklearn.metrics import confusion_matrix, classification_report
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import InterpolationMode
from torchvision import transforms,datasets
import torchvision.models as models
# For Reproducibility
def set_seed(seed=42):
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
set_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_dir = "./plant-disease-recognition-dataset/Train/Train"
test_dir = "./plant-disease-recognition-dataset/Test/Test"
val_dir = "./plant-disease-recognition-dataset/Validation/Validation"
categories = ["Healthy", "Powdery", "Rust"]
image_size = 320
batch_size = 16
IMAGENET_MEAN = [0.485, 0.456, 0.406]
IMAGENET_STD = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((image_size + 32, image_size + 32), interpolation=InterpolationMode.BICUBIC),
transforms.RandomResizedCrop(image_size, scale=(0.8, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.RandomRotation(degrees=20),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.02),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_MEAN, IMAGENET_STD),
])
val_test_transform = transforms.Compose([
transforms.Resize((image_size + 32, image_size + 32)),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_MEAN, IMAGENET_STD),
])
# checking how our images will look after Data Augmentation
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).view(3, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).view(3, 1, 1)
img = tensor.clone().detach().cpu()
img = img * std + mean
return img.clamp(0, 1)
fig, axes = plt.subplots(1, 3, figsize=(15, 6))
for i, category in enumerate(categories):
folder_path = os.path.join(train_dir, category)
files = os.listdir(folder_path)
img_path = os.path.join(folder_path, files[67])
original_img = Image.open(img_path)
transformed_tensor = train_transform(original_img)
vis_img = denormalize(transformed_tensor)
vis_img = vis_img.permute(1, 2, 0).numpy()
axes[i].imshow(vis_img)
axes[i].set_title(f"Transformed: {category}")
axes[i].axis('off')
plt.tight_layout()
plt.show()
# Datasets
train_dataset = datasets.ImageFolder(root=train_dir, transform=train_transform)
val_dataset = datasets.ImageFolder(root=val_dir, transform=val_test_transform)
test_dataset = datasets.ImageFolder(root=test_dir, transform=val_test_transform)
# Dataloaders
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=3,
pin_memory=True
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=3,
pin_memory=True
)
test_loader = DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=3,
pin_memory=True
)
def plot_cm(cm, title):
plt.figure(figsize=(6,5))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=categories, yticklabels=categories)
plt.title(title)
plt.ylabel("True")
plt.xlabel("Predicted")
plt.show()
def get_preds_labels(model, dataloader, device):
model.eval()
all_preds = []
all_labels = []
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
out = model(x)
preds = out.argmax(dim=1)
all_preds.extend(preds.cpu().numpy())
all_labels.extend(y.cpu().numpy())
return np.array(all_preds), np.array(all_labels)
def dml_step(images, labels, studentA, studentB):
images = images.cuda()
labels = labels.cuda()
# forward
outA = studentA(images)
outB = studentB(images)
# log-softmax for KLDivLoss
log_pA = torch.log_softmax(outA, dim=1)
log_pB = torch.log_softmax(outB, dim=1)
# soft targets from the partner
pA = torch.softmax(outA.detach(), dim=1)
pB = torch.softmax(outB.detach(), dim=1)
ceA = criterion_ce(outA, labels)
ceB = criterion_ce(outB, labels)
klA = criterion_kl(log_pA, pB)
klB = criterion_kl(log_pB, pA)
λ = 0.5
lossA = ceA + λ * klA
lossB = ceB + λ * klB
return lossA, lossB
def evaluate(model, loader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in loader:
images = images.cuda()
labels = labels.cuda()
out = model(images)
preds = torch.argmax(out, dim=1)
correct += (preds == labels).sum().item()
total += labels.size(0)
return correct / total
def evaluate_loss_and_acc(model, loader, criterion):
model.eval()
total_loss = 0
correct = 0
total = 0
with torch.no_grad():
for images, labels in loader:
images = images.cuda()
labels = labels.cuda()
outputs = model(images)
loss = criterion(outputs, labels)
total_loss += loss.item()
preds = torch.argmax(outputs, dim=1)
correct += (preds == labels).sum().item()
total += labels.size(0)
avg_loss = total_loss / len(loader)
acc = correct / total
return avg_loss, acc
class StudentModel(nn.Module):
def __init__(self, model_name, num_classes=4):
super().__init__()
if model_name == "effnet_b0":
self.backbone = models.efficientnet_b0(weights=models.EfficientNet_B0_Weights.IMAGENET1K_V1)
self.backbone.classifier = nn.Identity() # remove FC
elif model_name == "mobilenet_v3_large":
self.backbone = models.mobilenet_v3_large(weights=models.MobileNet_V3_Large_Weights.IMAGENET1K_V1)
self.backbone.classifier = nn.Identity()
dummy = torch.randn(1, 3, 224, 224)
with torch.no_grad():
out = self.backbone(dummy)
in_features = out.shape[1]
# FC layer
self.head = nn.Sequential(
nn.Linear(in_features, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(64, num_classes)
)
def forward(self, x):
feats = self.backbone(x)
out = self.head(feats)
return out
studentA = StudentModel("effnet_b0").cuda()
studentB = StudentModel("mobilenet_v3_large").cuda()
optimizerA = torch.optim.AdamW(studentA.parameters(), lr=1e-4, weight_decay=1e-4)
optimizerB = torch.optim.AdamW(studentB.parameters(), lr=1e-4, weight_decay=1e-4)
criterion_ce = nn.CrossEntropyLoss()
criterion_kl = nn.KLDivLoss(reduction="batchmean")
best_val_loss_A = float("inf")
best_val_loss_B = float("inf")
epochs = 15
for epoch in range(epochs):
studentA.train()
studentB.train()
running_loss_A = 0
running_loss_B = 0
for images, labels in train_loader:
optimizerA.zero_grad()
optimizerB.zero_grad()
lossA, lossB = dml_step(images, labels, studentA, studentB)
lossA.backward()
lossB.backward()
optimizerA.step()
optimizerB.step()
running_loss_A += lossA.item()
running_loss_B += lossB.item()
# train metrics
train_loss_A = running_loss_A / len(train_loader)
train_loss_B = running_loss_B / len(train_loader)
train_acc_A = evaluate(studentA, train_loader)
train_acc_B = evaluate(studentB, train_loader)
# validation metrics
val_loss_A, val_acc_A = evaluate_loss_and_acc(studentA, val_loader, criterion_ce)
val_loss_B, val_acc_B = evaluate_loss_and_acc(studentB, val_loader, criterion_ce)
print(f"\nEpoch [{epoch+1}/{epochs}]")
print(f" Student A → TrainLoss: {train_loss_A:.4f} | TrainAcc: {train_acc_A:.4f} | ValLoss: {val_loss_A:.4f} | ValAcc: {val_acc_A:.4f}")
print(f" Student B → TrainLoss: {train_loss_B:.4f} | TrainAcc: {train_acc_B:.4f} | ValLoss: {val_loss_B:.4f} | ValAcc: {val_acc_B:.4f}")
if val_loss_A < best_val_loss_A:
best_val_loss_A = val_loss_A
best_state_A = studentA.state_dict().copy()
if val_loss_B < best_val_loss_B:
best_val_loss_B = val_loss_B
best_state_B = studentB.state_dict().copy()
studentA.load_state_dict(best_state_A)
studentB.load_state_dict(best_state_B)
test_loss_A, test_acc_A = evaluate_loss_and_acc(studentA, test_loader, criterion_ce)
test_loss_B, test_acc_B = evaluate_loss_and_acc(studentB, test_loader, criterion_ce)
print("===== FINAL TEST RESULTS =====")
print(f"Student A (EffNetB0): Loss={test_loss_A:.4f} | Acc={test_acc_A:.4f}")
print(f"Student B (MobV3-Large): Loss={test_loss_B:.4f} | Acc={test_acc_B:.4f}")
a_preds, a_labels = get_preds_labels(studentA, test_loader, device)
print("=== EfficientNetB0 Classification Report ===")
print(classification_report(a_preds, a_labels, target_names=categories))
a_cm = confusion_matrix(a_preds, a_labels)
plot_cm(a_cm, "EffcientNetB0 Confusion Matrix")
b_preds, b_labels = get_preds_labels(studentB, test_loader, device)
print("=== MobileNetV3-Large Classification Report ===")
print(classification_report(b_preds, b_labels, target_names=categories))
b_cm = confusion_matrix(b_preds, b_labels)
plot_cm(b_cm, "MobileNetV3-Large Confusion Matrix")资料获取,更多粉丝福利,关注下方公众号获取


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 35
35 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)