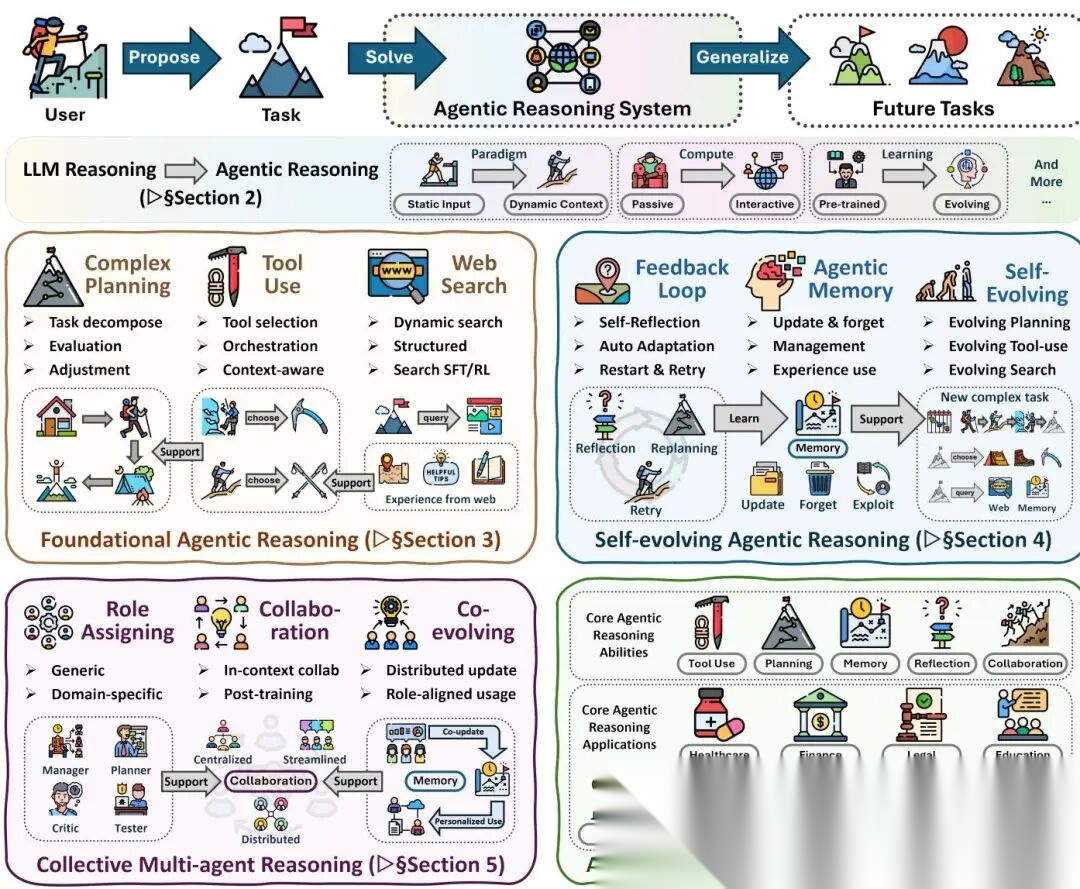
推理即交互核心技术揭秘(非常详细),Agentic Reasoning从入门到精通,收藏这一篇就够了!
亮点
- • UIUC联合Meta、Amazon、Google DeepMind等28位研究者发布百页综述,Hugging Face Paper of the Day第一,197个upvotes
- • 提出三层递进架构:基础智能体推理(规划+工具+搜索)→ 自进化推理(反馈+记忆+持续适应)→ 多智能体协作(角色分工+通信+共进化)
- • 两种互补优化路径贯穿全文:In-context Reasoning(推理时编排扩展,参数不动)与Post-training Reasoning(RL/SFT内化到参数),以DeepSeek-R1、Search-R1为代表
- • 将Agentic Reasoning形式化为POMDP,策略分解为"先思考后行动"的双通道结构,统一解释ReAct、Reflexion、多Agent协作等系统设计
- • 覆盖数学探索、代码生成、科学发现、具身机器人、医疗诊断、Web Agent六大应用,系统整理了对应的benchmark体系
一、推理不再是静态的
传统LLM推理有个根本假设——给定输入,一次性生成输出。CoT也好,分解策略也好,本质都是一次前向传播。模型不会主动查资料,不会发现错误后修正自己,也不会根据环境反馈调整策略。
封闭场景够用。做数学题、写代码片段,一次推理基本就行。但真实世界的任务不是这样。信息在推理过程中动态变化,中间步骤需要调用外部工具验证,长序列决策需要规划和回溯,失败了还得从经验里学。
Agentic Reasoning(智能体推理) 是为解决这个问题提出的范式。核心思想一句话:推理不是被动的序列生成,而是主动的规划-行动-学习循环。LLM被重新定义为能自主规划、执行动作、整合反馈、持续进化的推理智能体。
这篇UIUC联合Meta、Amazon、Google DeepMind等机构28位研究者的综述,系统梳理了这个方向的技术全景。论文在Hugging Face上197个upvotes,登顶Paper of the Day。
二、Agentic Reasoning的定义与形式化
先看对比。传统LLM推理和Agentic推理在五个维度上存在根本差异:
| 维度 | 传统LLM推理 | Agentic推理 |
|---|---|---|
| 范式 | 被动、静态输入 | 交互式、动态上下文 |
| 计算 | 单次内部计算 | 多步、带反馈 |
| 状态 | 上下文窗口、无持久化 | 外部记忆、状态追踪 |
| 学习 | 离线预训练、固定知识 | 持续改进、自我进化 |
| 目标 | 基于提示、被动响应 | 显式目标、主动规划 |
一句话:推理不再靠静态容量扩展,而是通过结构化交互实现规划、适应和协作。
POMDP框架
论文给了统一的形式化。Agentic Reasoning被建模为部分可观测马尔可夫决策过程(POMDP):
是环境状态空间(不可观测), 是观测空间, 是外部动作空间(工具调用、输出答案), 是推理轨迹空间(CoT等), 是记忆空间。
关键在策略分解:
内部思考外部行动
先在 空间思考,再在 空间行动。 这不只是理论抽象。它直接映射到ReAct(交替产生thought和action)、Reflexion(通过记忆跨episode优化策略)、多Agent系统(通信扩展观测空间)的设计逻辑。
两种优化路径
在这个框架下有两条路:
In-context Reasoning:参数 冻结,靠推理时搜索、编排、工作流设计扩展能力。ReAct、Tree-of-Thought、各种多步编排策略,都是在不改模型参数的前提下扩展推理深度。
Post-training Reasoning:通过RL或SFT把推理模式内化到参数中。DeepSeek-R1纯RL训练让AIME准确率从15.6%提到71%,涌现出自我反思、验证、动态策略调整。OpenAI o1/o3、Search-R1系列也走这条路。
两条路互补。ReTool先用SFT冷启动工具使用能力再用RL优化,32B模型在AIME达到67%准确率(仅400训练步,超过o1-preview 27.9%)。ARTIST(微软)用outcome-based RL让LLM自主决定何时调用工具,数学推理提升22%。纯In-context或纯Post-training都不如两者结合。
三、三层架构
论文的核心贡献是构建了三层递进架构,覆盖当前主流Agent系统的设计空间。
3.1 第一层:基础智能体推理
单个Agent在稳定环境中的核心能力:规划、工具使用、搜索。

规划推理
规划是Agent最基本的"思考"能力,把复杂任务分解成可执行步骤。
In-context规划有四种风格。工作流设计把任务分成感知→推理→执行→验证阶段,搭配ReAct风格的反应式控制器,这是最主流的Agent架构。树搜索用BFS、DFS、A*、MCTS探索推理空间,ToT是典型,MCTS尤其流行。过程形式化将规划编码为PDDL程序或代码,保证可组合性。分解/解耦把复杂规划拆成目标识别、记忆检索、计划细化等独立模块,ReWOO分离观测和推理以提升效率。
Post-training规划通过RL设计奖励结构来优化规划行为。Reflexion的自反馈式学习、基于扩散模型的轨迹优化都属于这一类。
实际系统经常组合使用。Web Agent中高层规划器生成子任务树,叶节点绑定到DOM操作;代码Agent里层级任务树递归分解问题,在树上嵌入MCTS选择有前途的编辑路径。
工具使用
工具使用让Agent调用外部模块扩展能力。核心决策有三个:何时用、用哪个、怎么调。
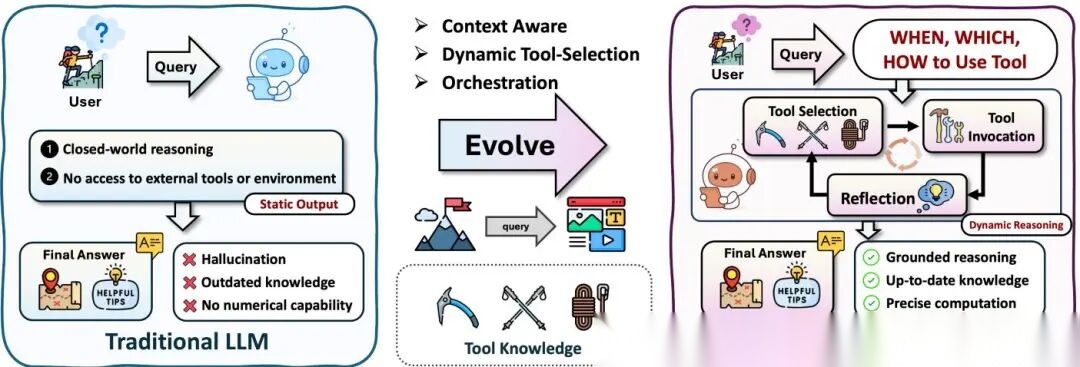
In-Context工具集成不改模型,靠提示策略引导。ReAct交替产生reasoning和action,action就是工具调用。ChatCoT将推理轨迹结构化为"thought-tool-observation"交替步骤。ART维护成功任务演示库,检索相似示例做few-shot。
Post-training工具集成分两个阶段。SFT阶段,Toolformer自监督让模型生成、验证、保留有用的API调用,ToolLLM将SFT扩展到16000+真实API。但单靠SFT容易过拟合,泛化差。RL阶段用结果驱动奖励优化策略,ReTool将实时代码执行集成到推理rollout中,ToolRL将范式推广到多样化工具集。RL的工具策略比纯SFT更鲁棒。
编排型集成处理多工具协同。HuggingGPT用中央Agent规划调用顺序,ToolChain把工具动作空间建模为决策树,用A搜索找最优路径。
智能体搜索
传统RAG一次性检索,Agentic Search让Agent自主决定何时检索、检索什么、怎么检索。
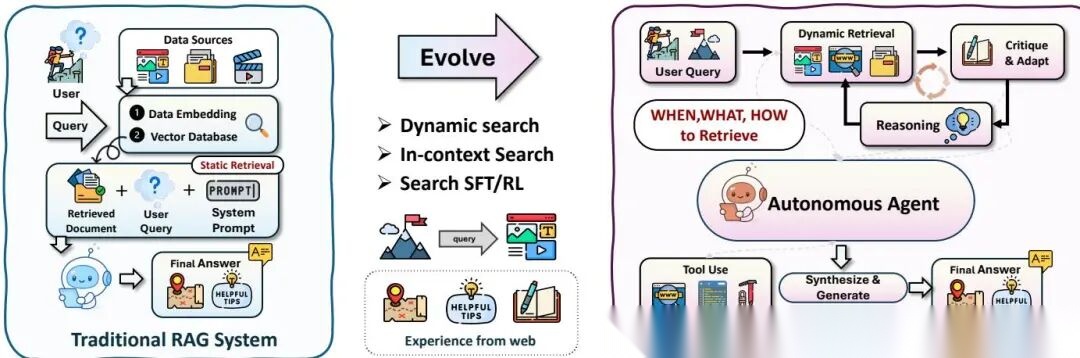
In-Context搜索:ReAct用<Search> token在推理中动态调用搜索,Self-Ask递归分解问题逐步检索子证据,更新的方法引入反思性检索——模型每步显式评估是否需要额外信息。
Post-training搜索的RL路线进展很快。Search-R1训练模型在推理中自动生成<Search> token触发检索,Qwen2.5-7B提升26%。Search-R1++(2026.02)发现Fast Thinking优于Slow Thinking,REINFORCE优于PPO。DeepResearcher将RL扩展到真实Web环境,涌现出迭代分解、再验证、证据规划。
结构增强搜索将非结构化检索与结构化图推理结合。Agent-G集成文档检索和图推理,GeAR将图扩展操作融入Agent控制器,ARG通过主动自反思在知识图谱上实现可解释的逐步推理。
3.2 第二层:自进化智能体推理
基础层解决"Agent能做什么",自进化层解决"Agent如何变得更好"。核心机制是反馈和记忆。
反馈机制
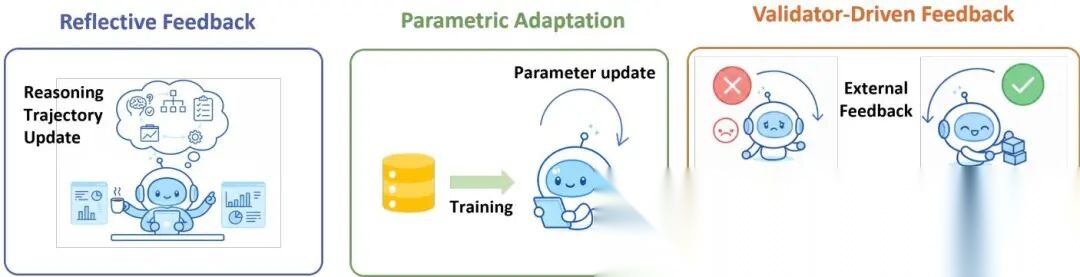
三种反馈形成从灵活到稳定的连续谱。
反思性反馈在推理时不改参数,通过自我批评和修正改善输出。Reflexion是代表,生成→批评→修正循环,HumanEval上91% pass@1。搜索型策略(ToT、GoT)生成和比较多条推理路径提升可靠性。
参数化适应把反馈信号转化为训练目标更新参数。在中间推理轨迹上附加反馈做SFT,或用偏好对齐(DPO、RLHF)形塑推理策略。效果持久,但需要额外训练。
验证器驱动反馈用外部验证器(单元测试、环境信号)判断成功/失败,反复采样直到通过。代码生成和具身Agent场景特别有效。缺点是非诊断性的——只知道错了,不知道错在哪。
三种机制不互斥。实际系统往往组合使用,比如先反思性地自我批评,改完后提交验证器测试,测试失败的信号再反馈到参数更新。
智能体记忆
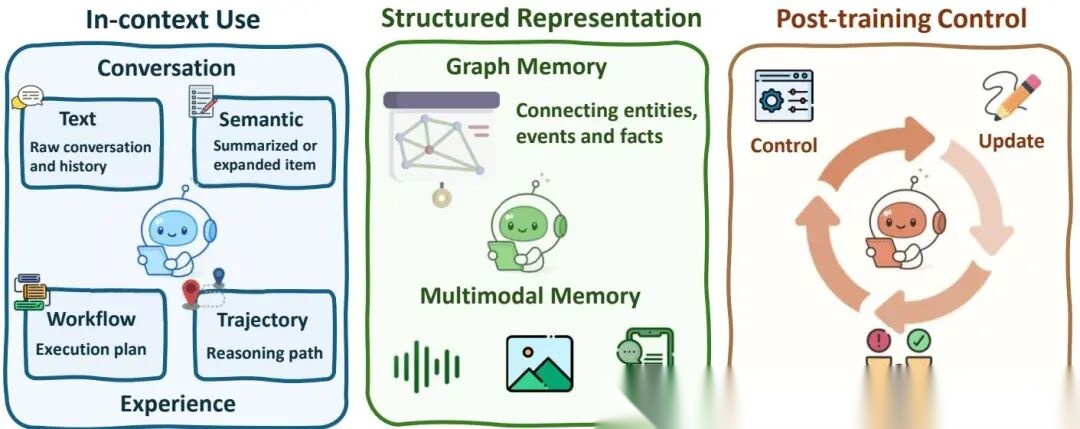
记忆从被动缓冲区进化为推理循环的核心组件。
事实记忆从传统的语义相似度检索(MemGPT、LangChain固定模块)演进到推理感知记忆。Amem自主生成上下文记忆描述并建立动态链接,Memory-R1用双Agent设计(Memory Manager动态决定何时增/改/删记忆条目 + Answer Agent蒸馏最相关记忆引导回答)。
经验记忆关注过程和策略的复用。Workflow Memory追踪过程轨迹支持计划恢复。Sleep-time Compute让Agent在用户交互前预计算推理步骤——“离线思考”。Dynamic Cheatsheet存储可复用策略减少冗余推理。
结构化记忆将记忆组织为更丰富的表示。GraphRAG和MEM0用动态知识图谱,MemTree用层级树结构,Optimus-1和RAP做跨模态记忆检索复用。
后训练记忆控制把记忆管理本身变成RL优化目标。MemAgent将记忆重写建模为RL问题,Memory-as-Action将记忆编辑(插入、删除、修改)直接集成到推理策略中。这是一个很有意思的方向——Agent不只是使用记忆,而是学会怎么管理记忆。
基础能力的自进化
规划、工具、搜索三个基础能力本身也在进化。
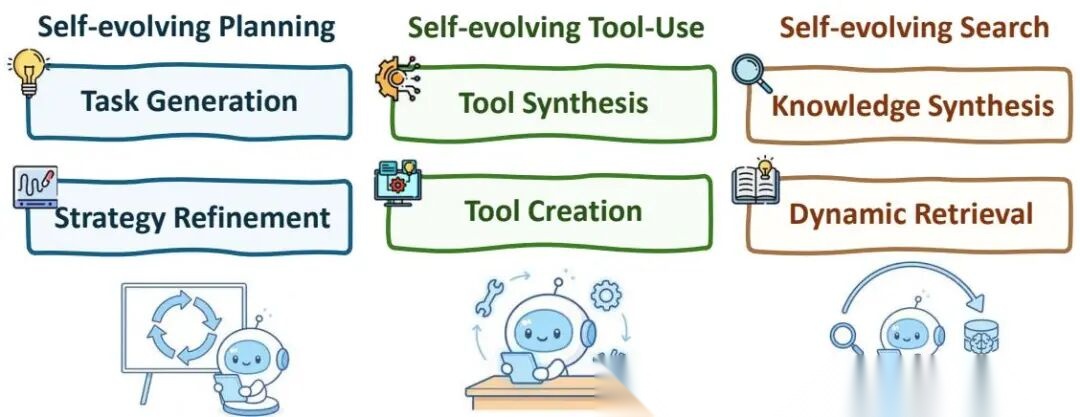
自进化规划:Agent自己生成训练任务(SCA),自己评估输出质量(self-rewarding),从执行反馈中在线适应(TextGrad将语言批评转化为训练奖励)。
自进化工具使用:Agent不仅用工具,还创造新工具。LATM用强模型做一次性"工具制造者",轻量模型做频繁的"工具使用者"。CRAFT和CREATOR为特定领域生成定制工具。ToolMaker能把整个公开代码仓库转化为可用工具。
自进化搜索:搜索和记忆形成共进化循环。Agent在任务执行中持续更新记忆库,同时动态调整搜索策略。MemOS和Memory-as-Action将搜索决策直接集成到推理策略中。
论文还对自进化做了更高层的分类。三种进化模式:语言进化(状态 是文本反思或指南,Reflexion)、程序进化(状态 是可执行技能库,Voyager在Minecraft中合成新代码技能,获得3.3x更多独特物品)、结构进化(状态 是Agent自身的源代码,AlphaEvolve用LLM作为变异算子搜索更优算法,发现56年来首个改进的4×4矩阵乘法算法)。
最后一种最激进,Agent在修改自身的"基因"。
3.3 第三层:集体多智能体推理
单Agent有上限。多Agent协作处理更复杂的任务,但也引入新的挑战:角色分化、通信效率、集体记忆管理。
角色体系
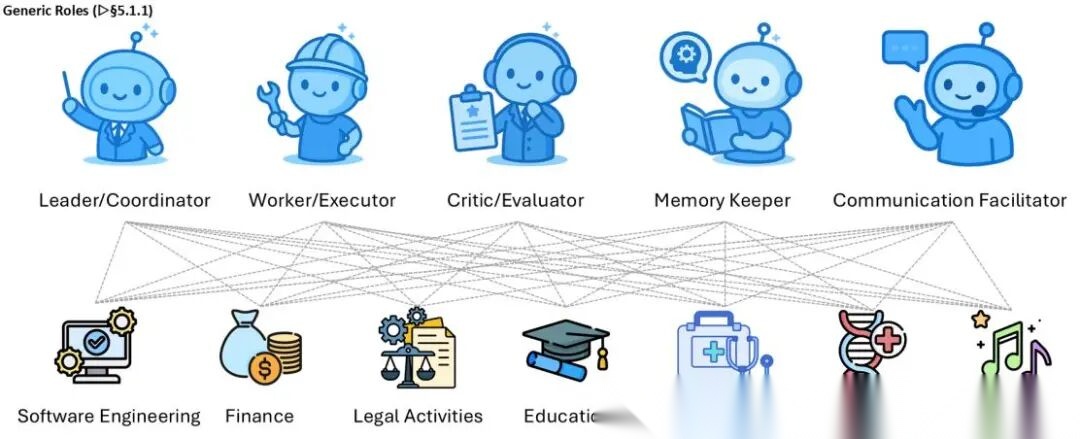
五种通用角色:Leader/Coordinator设定全局目标、分解任务;Worker/Executor执行具体操作;Critic/Evaluator做质量保障和验证;Memory Keeper管理长期知识;Communication Facilitator治理通信协议和共识编排。
领域特化角色映射到具体行业。软件工程:架构师→开发者→代码审查员→CI编排者→发布经理(MetaGPT、ChatDev)。金融:分析师、风险经理、交易员、合规官。医疗:分诊Agent、专科Agent、医生Agent、测量Agent。法律甚至模拟了原告、被告、法官、律师的庭审对抗。
协作与分工

In-context协作不需要训练。手工设计的层级流水线(MetaGPT、AgentOrchestra)直接定义角色和通信规则。LLM驱动的流水线让LLM自动分解目标、路由到特化Agent,Magentic-One用中央Orchestrator做ledger-based路由,在GAIA、WebArena上有竞争力。
一个有趣的方向是心智理论(Theory of Mind)增强协作。给Agent配备显式信念状态表示,让它们推断其他Agent的意图。Li et al.在合作文本游戏中验证了这个方法,Hypothetical Minds进一步将ToM做成模块化假设生成与精化循环。
Post-training协作把协作本身变成可优化对象。拓扑优化分三条路线:
图生成——GommFormer端到端学习通信图,G-designer用变分图自编码器生成查询自适应通信图。图剪枝——AgentPrune将多Agent系统建模为时空图稀疏化问题。拓扑搜索——AFlow用MCTS在算子库上自动化工作流设计,GPTSwarm将搜索空间建模为计算图连接概率并用RL优化。
策略型方法走得更远。MAGRPO提出Dec-POMDP框架,用组相对优势信号替代集中式critic。AT-GRPO在Agent级和Turn级做GRPO,长程规划准确率从14-47%飙升到96-99.5%。COPY用双Agent共训练框架,共享奖励+KL正则化,稳定性和迁移能力都有提升。
多智能体进化
多Agent系统需要随时间共同进化。
从时间维度分两种。任务内进化(Intra-test-time):Reflexion用自然语言自我批评实时适应,AdaPlanner根据环境不匹配动态修正计划,TTRL遇到困难案例时直接局部微调模型。跨任务进化(Inter-test-time):STaR和Quiet-STaR通过自蒸馏把错误推理转化为高质量训练数据,RAGEN和DYSTIL通过在线RL持续更新策略。
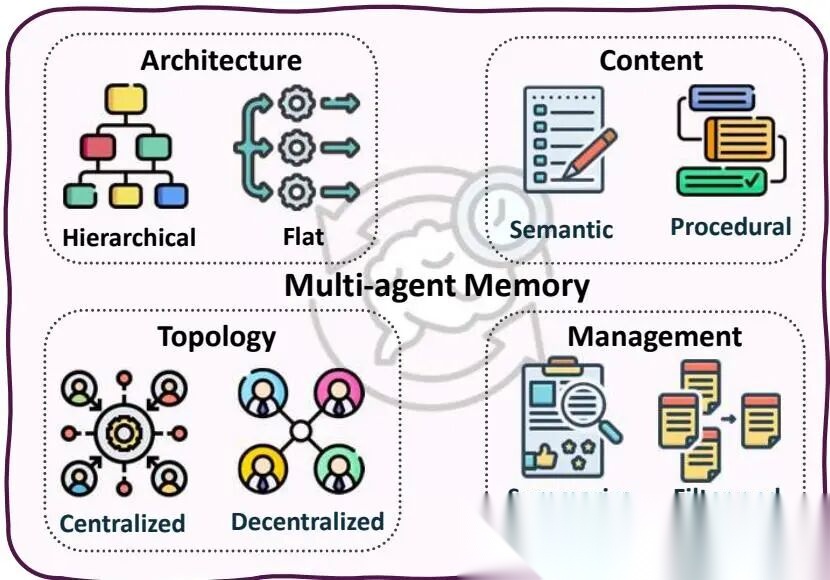
多Agent记忆设计有四个维度需要同时考虑。架构:G-Memory的三层图层级(洞察图→查询图→交互图)vs 每个Agent独立的角色对齐模板,前者优化全局一致性,后者优化角色保真度。拓扑:集中式验证写入 vs 私有/共享分离 vs 自由池化。MIRIX的6种语义类型分解在多模态QA上带来35%准确率提升。管理:Lyfe Agents的摘要-遗忘、AGENT-KB的结构化三元组学习,实际系统通常组合策略,关键记忆用验证,低价值记忆用遗忘。
训练多Agent进化是最新的前沿方向。Multi-Agent Evolve构建Proposer-Solver-Judge三角色闭环共进化,所有角色源自同一LLM骨干,通过RL联合优化,无需外部监督。MARFT形式化了多Agent强化微调框架,处理角色异质性、动态协调和长序列对话等LLM-based MARL特有的挑战。
四、应用场景
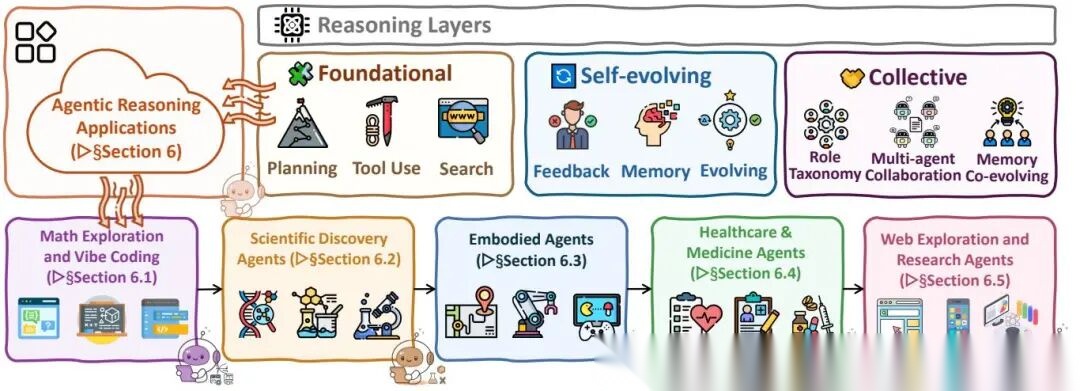
论文覆盖六大领域,每个领域沿三层架构组织。这里重点展开几个。
数学探索与Vibe Coding
传统数学基准在饱和。GSM8K、MATH、AIME难以区分当前高性能模型,且只测最终答案准确率,不测推理过程。
Agentic推理让数学从"解题"变成"探索"。AlphaEvolve(Google DeepMind)用LLM作为变异算子搜索更优算法,发现56年来首个改进的4×4矩阵乘法算法(48次标量乘法),恢复了Google约0.7%的全球计算资源。FunSearch在Nature上发表,通过程序搜索框架发现数学新结构。Trinh et al.同样Nature发表,通过构造→引理生成→验证的分阶段规划解决奥赛级几何题。
代码领域在经历类似转变。Karpathy提出的"Vibe Coding"成为新范式——自然语言对话迭代编程。模型维护上下文,适应演进需求,持续自纠正。
技术上,多Agent代码生成从简单角色分工(Self-Collaboration的黑板记忆)发展到自进化协作(EvoMAC的迭代策略调整、SEW的运行时协作路径重组)。OpenHands作为开源AI编码平台,在SWE-bench上领先,Docker沙箱安全执行,OpenHands Versa在VersaBench 8个基准中5个达SOTA。
科学发现
科学Agent在加速研究全生命周期。
工具集成是关键。ChemCrow链接多种化学工具实现端到端自主合成。TxAgent整合211个经审核的药理学工具,跨药物标签和患者上下文做治疗推理。AgentMD先从文献中挖掘2000+临床计算器,再在推理时选择合适的工具。
检索增强方面,PaperQA/PaperQA2将检索作为主循环——决定读哪些文档、归因每个声明、检测冲突,产出可验证的专家级文献综述。AI Scientist-v2用agentic树搜索框架,在假设形成和论文撰写中主动查询文献数据库。
实验执行已经落地到物理实验室。Organa将LLM推理与任务运动规划连接,用自主机器人执行多步化学实验。Chemist-x生成控制脚本驱动自动化平台验证条件,无需人工干预。
多Agent协作方面,ProtAgents用文献检索、结构分析、物理模拟、结果分析等Agent协作做蛋白质设计。CellAgent编排规划者、执行者、评估者三种角色完成单细胞分析流水线。
具身Agent
LLM与物理世界的连接。
从SayCan(语言→技能可行性估计)到SayPlan(3D场景图对齐目标引用),再到Cosmos-Reason1(空间-时间-动力学本体让CoT编码物理先验),每一步都在把推理锚定到更丰富的物理理解。
RL显著增强了具身规划。Robot-R1训练大型VLM预测关键点转换,ManipLVM-R1利用可验证物理奖励信号(轨迹匹配、可行性正确性)减少对密集标注的依赖。Embodied-R让VLM处理感知、小LM处理推理,整体通过RL训练空间推理。
Voyager仍然是具身Agent里程碑——首个LLM驱动的开放式具身Agent,在Minecraft中实现终身学习。三大组件:自动课程、技能库、迭代提示。获得3.3x更多独特物品,解锁里程碑快15.3x,不需要参数微调。
医疗
安全约束最严格的领域。
MDAgents根据任务复杂度自动分配协作结构——简单问题单Agent处理,复杂问题拉多Agent会诊。DoctorAgent-RL将临床咨询建模为不确定性下的动态决策,用RL优化提问策略和诊断路径。MedAgent-Pro生成疾病级诊断计划再调度工具Agent执行。
记忆在医疗场景极为关键,需要跨就诊追踪病史。EvoPatient通过医患Agent共进化维护跨对话的临床状态演变,同时产生高质量诊断对话数据用于训练真人医生。
Web Agent与自主研究
三个逐渐增强自主性的层次:Web Agent检索证据 → GUI Agent操作软件界面 → 自主研究Agent编排完整科学工作流。
Web Agent方面,WebRL引入自进化在线课程从失败尝试生成新任务。DeepResearcher将RL扩展到真实Web环境,涌现出计划制定、跨来源验证、自反思行为。WebAgent-R1做端到端多轮RL,直接从在线rollout学习交互策略。
GUI Agent方面,OS-Copilot将桌面作为统一控制空间。Agent S构建经验增强的规划栈,分解任务为子目标并检索过去轨迹和外部知识。ComputerRL和ARPO直接通过RL优化多步GUI轨迹。
自主研究Agent方面,AI Scientist-v2增加实验管理器和渐进式agentic树搜索来调度实验分支。NovelSeek构建统一闭环多Agent框架,跨越假设生成、方法构建和多轮自动实验。Agent Laboratory将工作组织为文献综述→实验→报告撰写三阶段,支持工具钩子自动化代码执行和实验运行。
五、Test-Time Compute的反思
一个值得停下来想想的问题:更多推理时计算就一定更好吗?
最新研究给出了警告。
Overthinking问题。更长的推理链不一定提升性能。模型在简单问题上容易"过度思考",过多token反而有害。Claude在有干扰信息时容易分心,o系列模型容易过拟合问题框架。不同领域存在最优推理长度分布,超过就是负收益。
并行优于串行深度。ParaThinker引入原生并行推理替代顺序深度扩展,在AIME-24上提升6.5%-20.7%。这暗示推理效率的提升空间在结构优化而非单纯堆长度。
推理计算正在超过训练计算。Deloitte预测2026年推理将占所有AI计算的2/3(2023年是1/3)。GPT-4级模型每百万token成本从降到0.40,1000倍暴跌,但推理模型生成的token量是普通模型的数量级倍数。2026年推理需求预计超过训练需求118倍。
对Agentic系统设计的启示很明确:不是无脑堆token,而是用结构化的方法(工具调用、并行采样、分层规划)在关键处集中计算资源。这也是这篇综述里三层架构的工程意义——每一层都在提供更高效地使用推理计算的手段。
六、开放问题
论文总结了六个前沿方向。
个性化。 当前Agent针对任务优化,不针对用户。用户偏好在变化,短期任务奖励和长期用户体验之间有张力。怎么在POMDP框架中把用户作为环境的一部分建模?
长程交互。 短序列表现不错,长任务中错误快速累积。Voyager这样的具身Agent就面临这个问题。核心是跨token、工具调用、技能、记忆更新的信用分配,以及跨episode的泛化学习。
世界模型。 世界模型通过内部模拟和前瞻缓解短视推理。DreamerV3展示了想象rollout的有效性,WebWorld训练了100万+网络交互的大规模World Model(WebArena提升+9.2%,达GPT-4o水平)。但当前设计依赖ad hoc表示,如何在非平稳环境中联合训练和评估世界模型仍未解决。
多Agent协作训练。 大多数协作结构仍是手工设计。多Agent RL开始把协作作为可训练技能,但群体级信用分配知之甚少。扩展到更大Agent群体带来拓扑适应、协调开销和安全挑战。
潜在推理。 在内部潜在空间而非显式自然语言中做规划和决策。效率高但可解释性差,中间推理不可观察时诊断故障很难。
治理。 最现实的挑战。Agentic系统的新风险:长程规划导致不可预见后果,持久记忆被污染,多Agent交互产生涌现行为。86%组织对AI数据流缺乏可见性,80%遇到过危险agent行为。现有基准和护栏主要关注短序列行为,模型层面、Agent层面、生态系统层面的联合治理是关键开放问题。McKinsey估计Agentic AI可释放2.6-4.4万亿美元/年价值,但1/3组织已在生产环境部署的同时,治理框架远未跟上。
七、总结
几个最有价值的洞察。
推理=交互。 这是最核心的范式转变。一旦把推理理解为Agent与环境的交互而非静态序列生成,规划、工具使用、记忆、反馈、多Agent协作就自然成为推理的组成部分,而非外挂组件。
POMDP形式化的解释力。 策略分解为"思考+行动"两通道,直接解释了ReAct为什么有效(交替思考和行动)、Reflexion为什么有效(通过记忆跨episode优化)、多Agent为什么需要通信(扩展观测空间)。形式化不是装饰,是设计指导。
自进化是分水岭。 从第一层到第二层——从"能执行"到"能自我改进"——是Agent接近智能体的关键跨越。AlphaEvolve连自身架构都能进化了。从第二层到第三层——从个体进化到集体协作——是扩展智能上界的方向。
两条路径的最优组合。 纯In-context或纯Post-training都不如两者结合。SFT冷启动+RL精化、In-context编排+Post-training策略优化,具体怎么组合取决于任务特性和资源约束。
从工程角度看,这篇综述是Agent系统设计的索引。每个组件(规划、工具、搜索、反馈、记忆、协作)都有多种设计选择和trade-off分析。推理计算到2026年预计超过训练计算118倍,设计高效、可靠、可控的Agentic推理系统,是接下来最重要的工程挑战之一。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献176条内容
已为社区贡献176条内容

所有评论(0)