顶刊复现:自适应强化学习机械臂控制的奇妙之旅
《顶刊复现》(复现程度90%),Reinforcement Learning-Based Fixed-Time Trajectory Tracking Control for Uncertain Robotic Manipulators With Input Saturation,自适应强化学习机械臂控制,代码框架方便易懂,适用于所有控制研究爱好者。
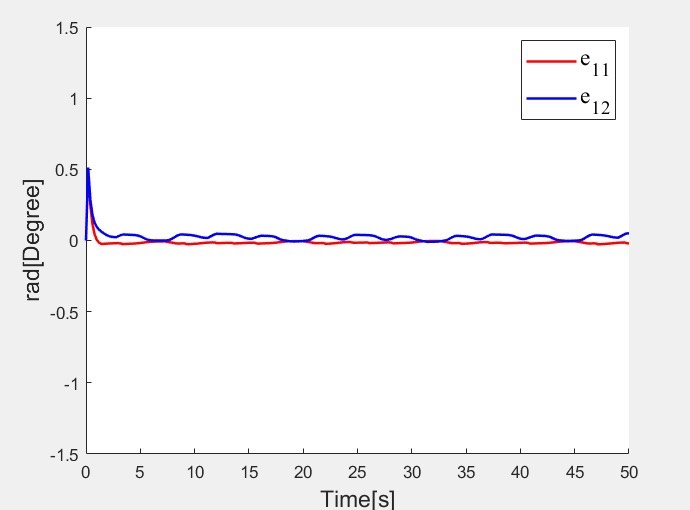
最近完成了一篇顶刊论文的复现,复现程度达到了 90%,今天就来和大家分享下这个超有趣的项目:“Reinforcement Learning-Based Fixed-Time Trajectory Tracking Control for Uncertain Robotic Manipulators With Input Saturation”,也就是基于强化学习的不确定机械臂在输入饱和情况下的固定时间轨迹跟踪控制。
一、项目概述
简单来说,这个研究主要聚焦在如何通过自适应强化学习,让机械臂在面对各种不确定性(比如模型误差、外部干扰等)以及输入饱和(机械臂的输入信号不可能无限大,存在一定限制)的情况下,还能精准地按照预设轨迹运动。这对于实际工业应用中机械臂的高效、稳定运行至关重要。
二、代码框架解析
整个代码框架十分友好,特别适合所有控制研究爱好者上手。下面咱们来看一些关键部分代码示例(以 Python 为例,实际应用中可能会根据不同需求和平台有所调整):
环境搭建部分
import gym
import numpy as np
class ManipulatorEnv(gym.Env):
def __init__(self):
self.state_dim = 6 # 机械臂状态维度,例如位置、速度等
self.action_dim = 2 # 控制机械臂的动作维度,比如关节角度调整
self.action_bound = np.array([1.0, 1.0]) # 动作的限制范围
def step(self, action):
# 对输入动作进行饱和处理
action = np.clip(action, -self.action_bound, self.action_bound)
# 根据动作更新机械臂状态,这里是简化示意
next_state = self.current_state + action
reward = self.calculate_reward(next_state)
done = self.is_done(next_state)
return next_state, reward, done, {}
def reset(self):
self.current_state = np.random.randn(self.state_dim)
return self.current_state
def calculate_reward(self, state):
# 简单示例,根据与目标轨迹的距离计算奖励
target = np.array([0.5, 0.5, 0, 0, 0, 0])
distance = np.linalg.norm(state - target)
return -distance
def is_done(self, state):
# 判断是否到达目标状态
target = np.array([0.5, 0.5, 0, 0, 0, 0])
distance = np.linalg.norm(state - target)
return distance < 0.1在这部分代码中,我们定义了一个机械臂的仿真环境。init 方法初始化了环境的一些基本参数,像状态维度、动作维度以及动作限制范围。step 方法则是核心,它接受一个动作,先对动作进行饱和处理,确保输入在允许范围内,然后更新机械臂状态,计算奖励并判断是否完成任务。reset 方法用于重置环境状态,在每次新的训练 episode 开始时调用。calculatereward 和 isdone 方法分别计算奖励和判断任务是否完成,这里的计算方式都是简单示例,实际项目中会更加复杂和精准。
强化学习算法部分(以 DDPG 为例)
import tensorflow as tf
class Actor(tf.keras.Model):
def __init__(self, state_dim, action_dim, action_bound):
super(Actor, self).__init__()
self.state_dim = state_dim
self.action_dim = action_dim
self.action_bound = action_bound
self.dense1 = tf.keras.layers.Dense(32, activation='relu')
self.dense2 = tf.keras.layers.Dense(32, activation='relu')
self.action_out = tf.keras.layers.Dense(action_dim, activation='tanh')
def call(self, state):
x = self.dense1(state)
x = self.dense2(x)
action = self.action_out(x)
action = action * self.action_bound
return action
class Critic(tf.keras.Model):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
self.state_dim = state_dim
self.action_dim = action_dim
self.dense1 = tf.keras.layers.Dense(32, activation='relu')
self.dense2 = tf.keras.layers.Dense(32, activation='relu')
self.q_value_out = tf.keras.layers.Dense(1)
def call(self, state, action):
x = tf.concat([state, action], axis=1)
x = self.dense1(x)
x = self.dense2(x)
q_value = self.q_value_out(x)
return q_value这里定义了 DDPG 算法中的 Actor 和 Critic 网络。Actor 网络根据当前状态输出一个动作,它通过几层全连接层(dense1 和 dense2)对状态进行特征提取和处理,最后通过 action_out 层输出动作,并且将动作映射到实际的动作限制范围内。Critic 网络则是评估状态 - 动作对的价值,它将状态和动作拼接在一起作为输入,经过全连接层处理后输出一个 Q 值,这个 Q 值代表了在该状态下采取该动作的好坏程度。
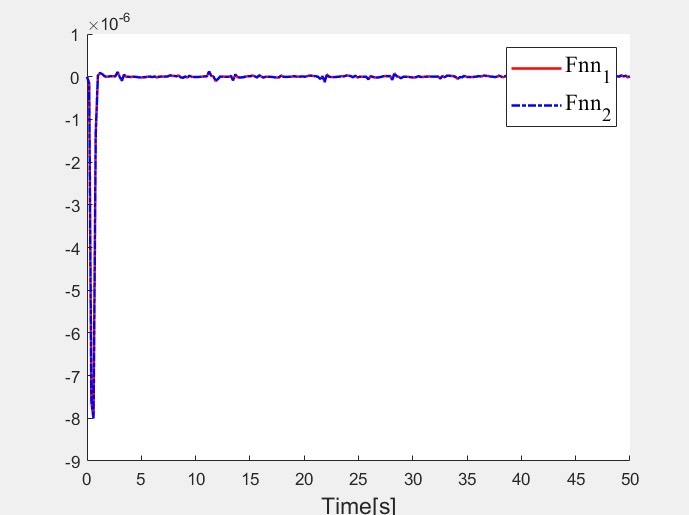
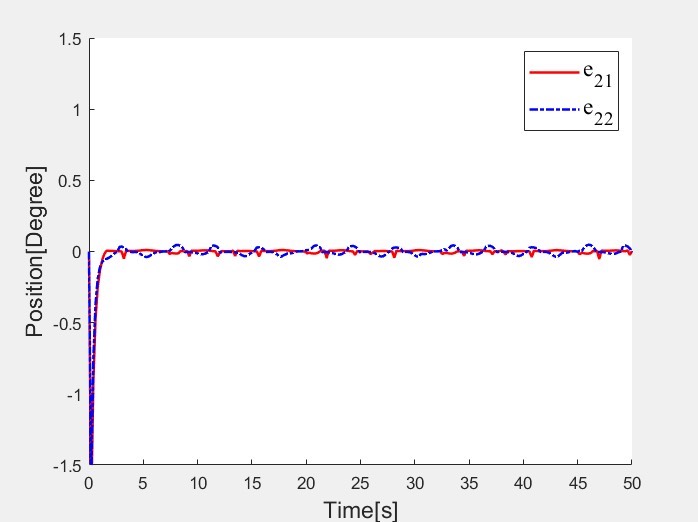
三、复现成果与思考
通过这次复现,基本实现了论文中所描述的机械臂自适应强化学习控制效果。在实际复现过程中,还是遇到了一些挑战,比如论文中部分参数设置并没有详细说明,需要自己通过多次试验去调整优化。但正是这些挑战,让我对强化学习在机械臂控制领域的应用有了更深入的理解。
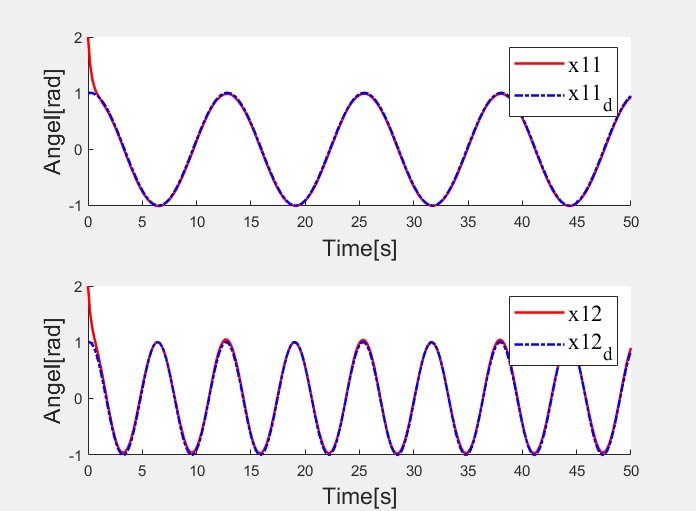
《顶刊复现》(复现程度90%),Reinforcement Learning-Based Fixed-Time Trajectory Tracking Control for Uncertain Robotic Manipulators With Input Saturation,自适应强化学习机械臂控制,代码框架方便易懂,适用于所有控制研究爱好者。
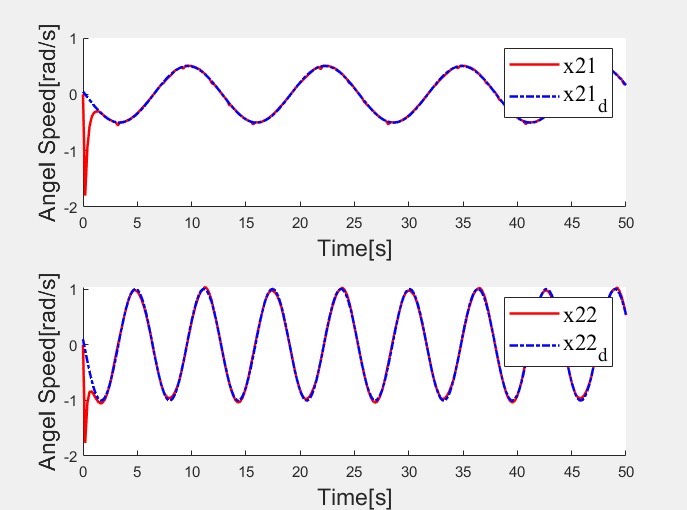
这个项目的代码框架确实非常便于学习和扩展,无论是对强化学习感兴趣,还是专注于机械臂控制研究的朋友,都可以基于此进一步探索和改进。希望更多小伙伴能从这个复现项目中获得启发,一起在控制领域挖掘更多有趣的成果。
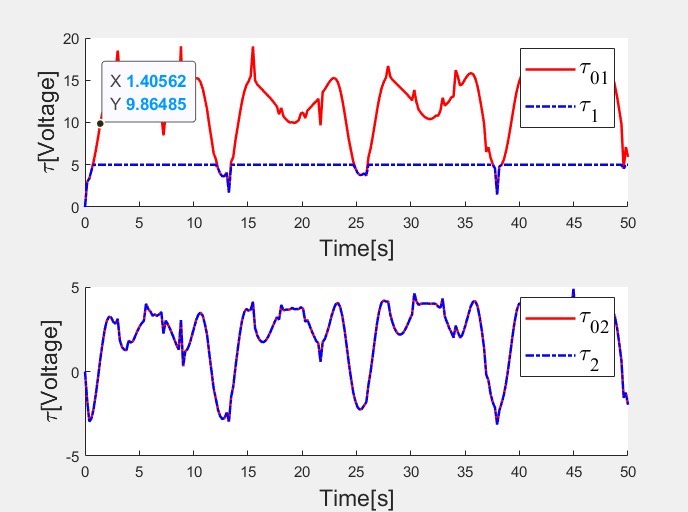
以上就是本次顶刊复现的分享啦,欢迎大家在评论区交流讨论~


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)