字节开源OpenViking全解(非常详细),Agent上下文存储从入门到精通,收藏这一篇就够了!
告别向量数据库的碎片化存储,用文件系统范式重新定义 Agent 记忆管理
一、为什么需要 OpenViking?
在构建 AI Agent 时,开发者常常面临这些痛点:
-
上下文碎片化
:记忆散落在代码里,资源存在向量库,技能到处乱放
-
上下文爆炸
:长时任务产生的海量信息,简单截断会丢失关键内容
-
检索效果差
:传统 RAG 平铺存储,缺乏全局视角
-
黑盒不可观测
:检索链路不透明,出错难定位
-
记忆无法迭代
:只记录对话,不沉淀任务经验
OpenViking 是一个专为 AI Agent 设计的上下文数据库,用"文件系统范式"统一管理记忆、资源、技能,让 Agent 越用越聪明。
二、实现原理:五大核心创新
1. 文件系统范式(Filesystem Paradigm)
OpenViking 抛弃传统向量数据库的平铺模型,将所有上下文映射到 viking:// 协议的虚拟文件系统中:
viking://├── resources/ # 项目文档、代码仓库│ └── my_project/├── user/ # 用户记忆│ └── memories/│ ├── preferences/ # 用户偏好│ ├── entities/ # 关注的人/项目│ └── events/ # 重要事件└── agent/ # Agent 记忆 ├── skills/ # 技能库 ├── memories/ │ ├── cases/ # 任务案例 │ └── patterns/ # 可复用模式 └── instructions/ # 指令集
优势:Agent 可以用 ls、find、read 等确定性操作精确定位信息,告别模糊匹配。
2. 三级上下文加载(L0/L1/L2)
自动将内容处理为三级结构,按需加载,大幅降低 Token 消耗:
| 层级 | 名称 | 大小 | 用途 |
|---|---|---|---|
| L0 | 摘要 | ~100 tokens | 快速筛选 |
| L1 | 概览 | ~2k tokens | 决策参考 |
| L2 | 详情 | 完整内容 | 深度阅读 |
效果:实测减少 91% 的 Token 消耗(vs LanceDB)。
3. 目录递归检索(Directory Recursive Retrieval)
五步检索策略,像人类专家一样理解信息上下文:
-
意图分析
:根据会话生成多维度查询
-
初始定位
:向量检索锁定高相关目录
-
细化探索
:目录内二次检索
-
递归深入
:子目录逐层探索
-
结果聚合
:返回最相关的上下文
4. 自动会话管理与记忆提取
会话结束时自动提取六类记忆:
| 类型 | 归属 | 说明 | 可合并 |
|---|---|---|---|
| profile | user | 用户身份属性 | ✅ |
| preferences | user | 用户偏好 | ✅ |
| entities | user | 关注的人/项目 | ✅ |
| events | user | 事件/决策 | ❌ |
| cases | agent | 问题+解决方案 | ❌ |
| patterns | agent | 可复用模式 | ✅ |
流程:消息 → LLM 提取 → 向量去重 → LLM 决策 → 写入存储
5. Viking URI 系统
统一资源标识,支持多租户隔离:
viking://{scope}/{path}
-
resources
:独立资源,长期有效
-
user
:用户数据,长期有效
-
agent
:Agent 数据,长期有效
-
session
:会话数据,会话生命周期
三、主要功能
资源管理
-
add-resource- 导入本地文件或 URL
-
export/import- 导出/导入 .ovpack
-
ls/tree/read- 文件系统操作
语义检索
-
find- 语义检索
-
search- 上下文感知检索
-
grep/glob- 模式匹配
会话管理
-
session new/list/get/delete- 会话生命周期
-
session add-message/commit- 消息提交与记忆提取
系统观测
-
system status/health- 健康检查
-
observer queue/vikingdb/vlm- 组件状态
四、使用场景
1. 个人 AI 助手
长期维护用户偏好、习惯,跨会话保持一致性。
2. 开发团队协作
共享项目知识库,新成员快速上手,知识沉淀不流失。
3. 企业知识管理
多租户隔离,不同团队数据独立,支持权限控制。
4. 自主 Agent 系统
任务经验自动积累,Agent 能力持续进化。
五、如何配合 OpenClaw 使用
OpenClaw 是一款流行的 AI Agent 框架,OpenViking 为其提供长期记忆后端。
快速开始(一键安装)
cd /path/to/OpenVikingnpx ./examples/openclaw-memory-plugin/setup-helperopenclaw gateway
安装助手会自动检查环境、创建配置、部署插件。
核心功能
| 功能 | 说明 |
|---|---|
| autoCapture | 自动从对话中提取记忆 |
| autoRecall | 自动注入相关记忆到上下文 |
| 记忆去重 | 基于摘要/URI 自动去重 |
| 智能排序 | 偏好提升、时序提升、词法重叠 |
性能提升(实测数据)
基于 LoCoMo10 长对话数据集(1,540 例):
| 方案 | 任务完成率 | 输入 Token |
|---|---|---|
| OpenClaw (原生) | 35.65% | 24,611,530 |
| OpenClaw + LanceDB | 44.55% | 51,574,530 |
| OpenClaw + OpenViking | 52.08% | 4,264,396 |
提升:
- 相比原生:+46% 完成率,-91% Token 成本
- 相比 LanceDB:+17% 完成率,-92% Token 成本
配置示例
{ "vlm": { "backend": "volcengine", "api_key": "<your-key>", "model": "doubao-seed-1-8-251228", "api_base": "https://ark.cn-beijing.volces.com/api/v3" }, "embedding": { "dense": { "backend": "volcengine", "api_key": "<your-key>", "model": "doubao-embedding-vision-250615", "dimension": 1024 } }}
六、与 PageIndex 的对比
| 维度 | OpenViking | PageIndex |
|---|---|---|
| 定位 | 通用上下文数据库 | 专业文档检索系统 |
| 核心创新 | 文件系统 + 分层存储 + 会话记忆 | 无向量 + LLM 推理检索 |
| 存储模型 | viking:// 虚拟文件系统 |
章节层级树结构 |
| 检索方式 | 向量 + 目录递归 + 意图分析 | 纯 LLM 推理 |
| 记忆系统 | 6 类自动提取与去重 | 无 |
| 基础设施 | 需要向量数据库 | 无需向量数据库 |
| Token 优化 | L0/L1/L2 三级加载(-91%) | 无 |
| 最佳场景 | Agent 长期记忆、多类型资源 | 专业文档 QA(财报/法律) |
| 准确性 | 52.08% 任务完成率 | 98.7% FinanceBench |
如何选择?
选 OpenViking 如果:
- 构建长期运行的 AI Agent
- 需要管理多种上下文(文档+代码+技能+记忆)
- 需要会话记忆自动迭代
- 需要生产级部署(多租户、权限控制)
选 PageIndex 如果:
- 主要做专业文档问答
- 对准确性要求极高
- 不想维护向量数据库
- 文档有清晰目录结构
七、快速开始
1. 安装
pip install openviking# CLI 工具(可选)curl -fsSL https://raw.githubusercontent.com/volcengine/OpenViking/main/crates/ov_cli/install.sh | bash
2. 配置
创建 ~/.openviking/ov.conf:
{ "storage": { "workspace": "/path/to/workspace" }, "embedding": { "dense": { "provider": "volcengine", "api_key": "<key>", "model": "doubao-embedding-vision-250615", "dimension": 1024 } }, "vlm": { "provider": "volcengine", "api_key": "<key>", "model": "doubao-seed-1-8-251228" }}
3. 启动与使用
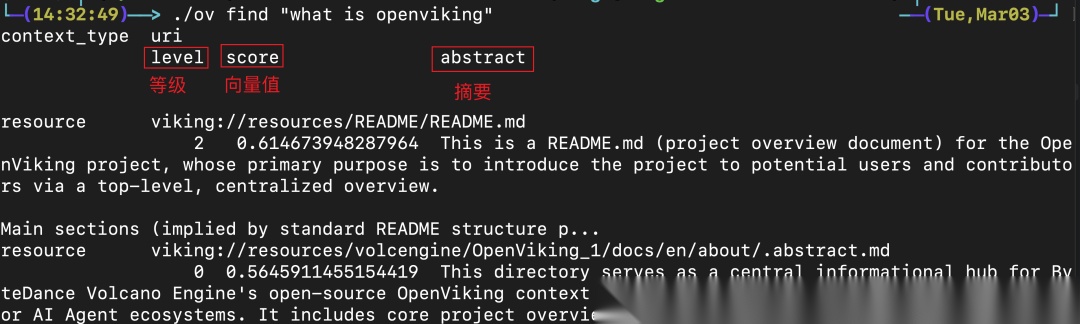
# 启动服务openviking-server# 添加资源ov add-resource https://github.com/volcengine/OpenViking --wait# 语义检索ov find "what is openviking"# 查看文件树ov tree viking://resources/OpenViking -L 2
八、总结
OpenViking 不仅是一个工具,更是** AI Agent 上下文管理的新范式**:
- 用文件系统思维统一管理记忆、资源、技能
- 三级加载机制大幅降低 Token 成本
- 目录递归检索提升上下文理解能力
- 自动记忆提取让 Agent 越用越聪明
如果你正在构建 AI Agent,不妨试试 OpenViking,让上下文管理不再是痛点。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献171条内容
已为社区贡献171条内容

所有评论(0)