多Agent辩论+知识图谱推理全攻略(非常详细),AAAI 2026论文从入门到精通,收藏这一篇就够了!

在传统 KGQA 中,方法往往依赖“图谱里已经包含解题所需的实体与关系路径”。但现实世界的知识图谱建设与维护成本很高,内容更新也滞后,导致缺失事实、缺失实体、缺失关系路径的情况十分常见。此时,单纯依赖 KG 的推理会出现关键证据断裂:模型可能检索不到必要三元组,或者沿着错误路径走偏,从而输出不可靠答案。
作者指出,已有 IKGQA 思路大致有两类:
1)KG 内部补全:通过链路预测、嵌入等方式在 KG 内推断缺失链接。但这类方法难以追上现实世界持续变化的新知识。
2)外部信息增强:引入外部文本(如 Wikipedia)或利用大模型参数化知识补足缺口。但现有融合方式往往不够“自适应”和“上下文相关”,很难充分发挥“结构化 KG”与“非结构化文本”之间的互补性;并且如果缺失事实超出大模型预训练覆盖,纯靠参数化知识也可能推错。
基于以上痛点,作者提出一个关键问题:如何更好地利用大模型的推理能力,把结构化知识与非结构化知识进行动态融合,从而提升 IKGQA 的鲁棒性?
作者给出的答案是一个新的多智能体推理框架: Debate over Mixed-knowledge(DoM)。它把“知识图谱推理”和“外部文本推理”交给不同的专门智能体独立完成,再用一个裁判智能体进行评估、对齐与整合,通过迭代式交互实现互相纠错与互补增强。
一、论文的主要贡献概览
作者总结的贡献可以概括为三点:
-
提出 DoM 框架
:一个基于 Multi-Agent Debate(多智能体辩论)思想的 IKGQA 框架,让 KG 证据与外部文本证据在迭代协作中动态融合,提升在 KG 不完整场景下的稳定性与准确性。
-
提出新数据集 IKGWQ
:针对现有 IKGQA 数据集“随机删三元组模拟不完整”不够真实的问题,作者构建了更贴近现实知识更新的基准,用“现实世界的事实更新”自然引入缺失实体/缺失关系,形成更难、更真实的测试。
-
实验显著提升
:DoM 在多个 IKGQA 设置下超过强基线方法,尤其在新数据集 IKGWQ 上带来大幅增益。
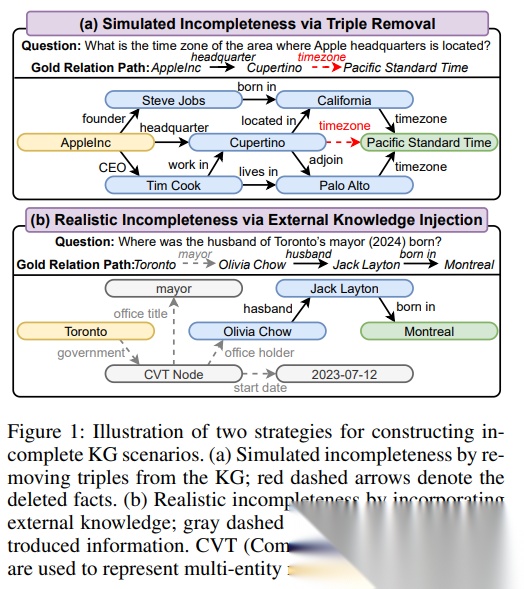
二、为什么作者要做一个新的数据集 IKGWQ
作者认为,许多 IKGQA 基准的“不完整”是通过随机删除 gold relation path 上的关键三元组来实现的。这种删边方式虽然方便控制比例(比如删除 20%、40%、60%、80%),但它具有明显的“规则性”和“可预测性”,并不能代表真实世界的知识缺失模式。现实中 KG 不完整往往来自:知识更新滞后、事件演化、新事实出现、实体新增或属性变更,缺失是更不规则且更难预判的。
因此作者构建了 Incomplete Knowledge Graph WebQuestions(IKGWQ,简称 IKGWQ)。其构造思路是:从已有问答基准(如 CWQ、WebQSP)中抽取样本,围绕样本的 topic entity 去检索“更新后的可信信息”,再生成新的问答对,使得答案所依赖的事实在原始 Freebase KG 中往往是缺失或过时的。
作者给出的数据构建流程大致是:
1)从原数据集中抽取 topic entity;
2)通过 Wikipedia API 获取实体的最新描述;
3)引导大模型基于这些文本生成新的问题与答案,重点围绕“超出原 KG 静态范围的新事实”;
4)再进行人工筛选、改写、标注,保证质量。
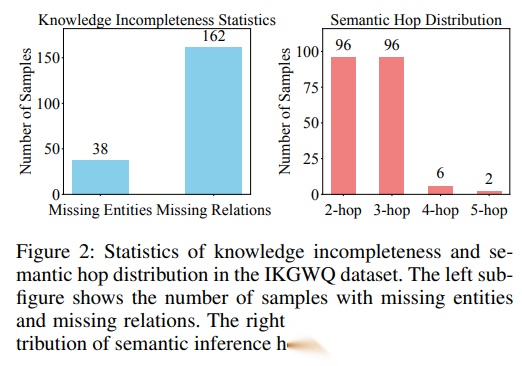
三、任务定义与 DoM 的整体思路
作者将 IKGQA 定义为标准 KGQA 的扩展:在 KG 不完整时,允许引入外部知识 RRR 来辅助推理,从而输出答案实体集合。为组织整个推理过程,作者引入多个“角色化”的 LLM 模块(例如规划模块、实体选择模块、关系选择模块、裁判模块等),并用统一记号表示不同模块输出。
DoM 的核心思想是把推理拆成“可控的子目标序列”,并在每个子目标上让不同知识源的智能体独立推理,然后通过“裁判”做融合决策。整体流程分三阶段:
1)Initialization(初始化/规划):把原问题分解为一串语义连贯的子问题。
2)Sub-question Inference(子问题推理):对每个子问题,同时走两条路径:KG 路径与外部文本路径;再由裁判整合,并动态更新下一步子问题。
3)Final Answer Generation(最终答案生成):将所有子问题的中间结果写入“系统记忆”,最后汇总生成最终答案。
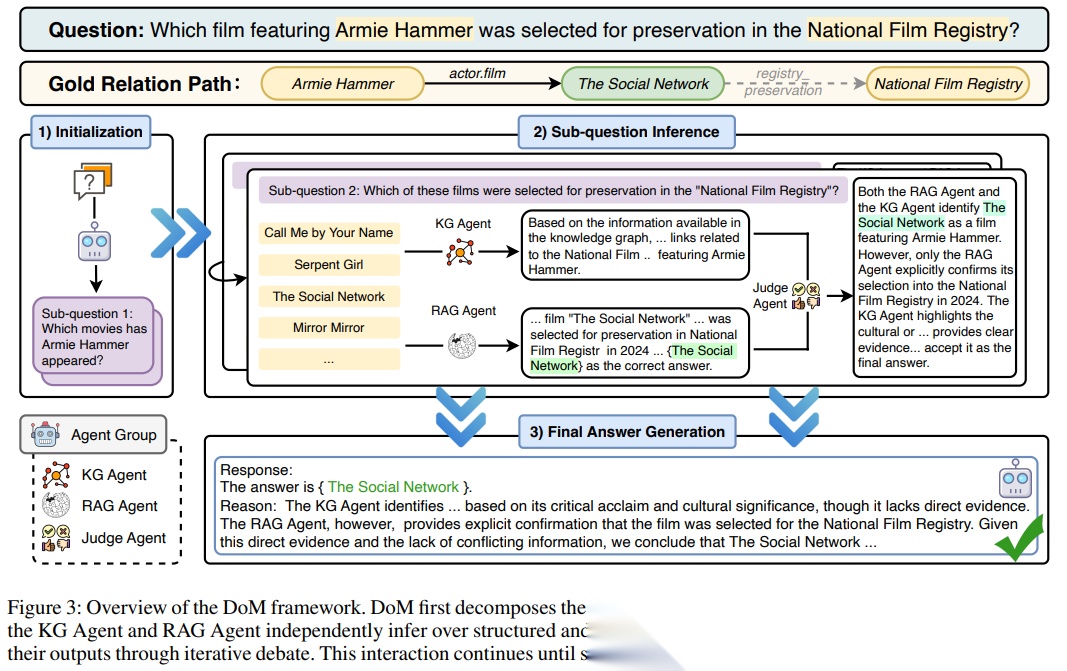
四、DoM 的关键机制:三个智能体如何工作
1)初始化:子问题分解与系统记忆
给定自然语言问题 qqq,作者用规划模块把它分解为有序子问题列表 Q={q1,…,qn}Q={q_1,\dots,q_n}Q={q1,…,qn}。每个子问题是一个阶段目标,后续逐步求解。与此同时,系统维护一个记忆 MMM,用于记录每一步的推理产物,保证后续步骤能够“继承上下文”。
2)子问题推理:KG Agent(结构化证据)与 RAG Agent(外部文本证据)
在第 iii 次迭代中,系统围绕一组 topic entities 展开检索:
- 在 KG 中检索与这些实体相关的关系路径与三元组证据集合;
- 在外部文本中检索相关段落(chunks)证据集合。
KG Agent:实体链接 + 迭代式图探索
KG 路线的困难在于:上一步的中间答案可能来自文本或模型内部知识,不一定能直接对齐 KG 中的机器实体 ID。因此作者先做 Entity Linking(实体链接):
- 用嵌入相似度检索 top-k 候选 KG 实体;
- 再交给 LLM 根据上下文关系从候选中选最合适的实体映射。
若找不到合适候选,作者认为“目标实体可能缺失于 KG”,此时跳过 KG 探索,转而使用大模型内部 CoT 推理以保持流程连续。
当实体链接成功后,KG Agent 进入 Iterative KG Exploration(迭代式探索):
- 通过 SPARQL 拉取当前实体的 1-hop 关联关系(包含正向与反向关系);
- 让 LLM 从所有关系中选出与当前子问题最相关的 top-k 关系;
- 把对应三元组加入证据集合;
- 再判断证据是否足以回答子问题;若不够,则从已获得证据中选一个新实体继续探索。
该过程有最大探索深度上限,若超过仍无法回答,就回退到 CoT 推理。
RAG Agent:Wikipedia 检索 + 证据段落选择 + 推理
外部文本路线中,作者选用 Wikipedia 作为外部知识源以提高事实可靠性。对于 topic entity:
- 先检索最相关的 Wikipedia 文章;
- 切分为文本 chunks;
- 用嵌入相似度为 chunks 与子问题打分,取 top-k chunks 作为上下文;
- 在这些证据上让 LLM 生成子问题答案。
如果外部证据不足,同样回退到 CoT 推理,避免流程中断。
3)Judge Agent:辩论式整合与动态更新子问题
当 KG Agent 与 RAG Agent 都产出“答案 + 推理链”之后,Judge Agent 扮演裁判:
- 对比两边证据强度与一致性;
- 决定当前子问题的综合答案;
- 并据此“修订下一子问题”,或在必要时生成新的子问题继续查缺补漏。
整个迭代有最大轮数上限 III,用于保证可终止性。
4)最终答案生成:基于记忆的全局一致性汇总
所有子问题处理结束后,系统把记忆 MMM(包含每一步的子问题、两位检索智能体答案、裁判综合结论)交给最终验证/生成模块,输出最终答案;若记忆仍不足以支撑答案,则回退到 CoT。
五、实验设计:作者怎么验证 DoM 的有效性
作者围绕五个研究问题组织实验:
RQ1:DoM 是否优于现有基线?
RQ2:DoM 对不同程度 KG 不完整是否更鲁棒?
RQ3:换不同大模型骨干,DoM 是否依然有效?
RQ4:各模块(KG / RAG / 混合 + 裁判)分别贡献多少?
RQ5:DoM 的代价(token 与时间)如何?
数据方面,作者使用两类评测:
- “传统 IKGQA 模拟集”:在 CWQ、WebQSP 上按比例删除 gold-path 关键三元组(20/40/60/80%)
- “更真实的 IKGWQ”:由现实知识更新构建的新数据集
评价指标使用 Hits@1(精确匹配)。
方法对比覆盖三类基线:
- 提示词类:IO、CoT
- 微调类:ChatKBQA、RoG
- 检索增强推理类:ToG、PoG、GoG
六、主要结果与分析
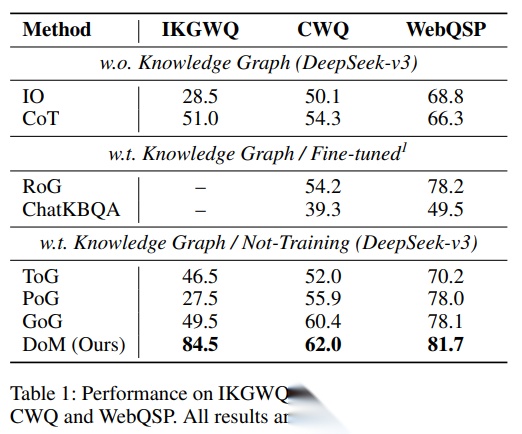
表1报告 IKGWQ 以及 CWQ/WebQSP 的 IKG-40% 设置上的 Hits@1(%)。其中 DoM 在 IKGWQ 上达到 84.5,在 CWQ IKG-40% 上 62.0,在 WebQSP IKG-40% 上 81.7;整体显著优于对比方法。
七、消融实验:只有 KG 或只有 RAG 都不如“混合 + 裁判”
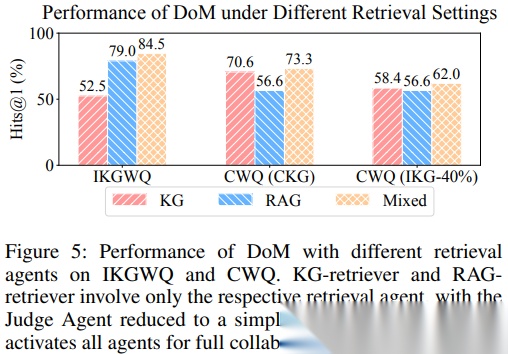
建议插入方式:在讲“RQ4:DoM 组件贡献”时插入。图5比较三种设置:
- 仅 KG 检索智能体
- 仅 RAG 检索智能体
- 混合(KG + RAG + Judge 全部启用)
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献194条内容
已为社区贡献194条内容

所有评论(0)