上下文工程的六大支柱之:结构化(Structuring)和 检索(Retrieval)
上下文工程六大支柱:结构化(Structuring)
上下文工程并非一系列孤立技术的简单堆砌,而是一门涉及信息获取、组织、传递和优化的综合性工程学科。
上下文工程的六大支柱分别是:结构化(Structuring)、检索(Retrieval)、压缩(Compression)、编排(Orchestration)、评估(Evaluation)和安全(Security)。
上下文工程的第一大支柱,也是最基础的一环,是结构化(Structuring)。其核心目标是:将来自不同来源的、异构的、无序的信息,转化为一种清晰、一致、可被机器(尤其是LLM)高效理解和利用的格式。
LLM虽然能够处理自然语言,但它们本质上仍然是数学模型,对结构化的、无歧义的输入更为敏感。一个精心结构化的上下文,就像一张重点突出、条理清晰的思维导图,能够极大地降低模型的理解成本,引导其注意力到最关键的信息上,从而显著提升输出的质量和稳定性。
一、为什么要结构化?对抗“熵增”
在一个典型的AI应用中,上下文信息来源众多:用户的自然语言输入、数据库的查询结果、API的JSON返回、网页的HTML内容、PDF的段落文本等等。如果将这些原始信息不加处理地直接拼接在一起,塞给模型,就会形成一个“信息沼泽”。模型需要耗费大量的“认知资源”去分辨哪里是指令,哪里是数据,哪里是重点,哪里是噪声。这种高“熵”状态,是导致模型产生幻觉、忽略关键信息、输出格式不稳定的主要原因之一。
结构化的过程,就是一个主动对抗“熵增”的过程。我们通过引入明确的“秩序”,来降低整个上下文系统的混乱程度。
二、结构化的核心技术
结构化的技术多种多样,但其核心思想都是“元信息”的显式化——即用明确的标签来说明“这段信息是什么”、“它从哪里来”、“它有什么用”。
1、XML/JSON:最通用的结构化语言
使用XML标签或JSON对象,是进行上下文结构化的最通用、最有效的方法。它们为不同类型的信息提供了清晰的“边界”和“身份”。我们在L1记忆的最佳实践中已经看到了XML标签的威力。
一个综合性的结构化上下文示例:
在这个例子中,我们用清晰的标签区分了目标(<goal>)、用户上下文(<user_profile>)、外部知识(<retrieved_knowledge>) 和系统指令(<system_instructions>)。每一部分信息都被赋予了明确的语义身份,模型可以一目了然地知道如何使用它们。
2、Markdown:兼顾可读性与结构化
对于需要呈现给人类阅读的文本,Markdown是一个极佳的结构化工具。通过使用标题(#)、列表(-)、粗体(``)等,可以在保持自然语言流畅性的同时,有效地组织信息层次。
例如,在生成报告或长篇文章时,要求模型使用Markdown格式输出,可以确保结果的条理性和可读性。
3、Pydantic:代码世界的结构化
当我们需要模型生成能被程序直接使用的数据时(例如,API调用的参数),强制其输出遵循某种数据结构至关重要。Pydantic是一个流行的Python库,它允许你用Python类来定义数据模型。许多现代的LLM框架(如LangChain、LlamaIndex)都支持将Pydantic模型作为输出解析器(Output Parser)。
使用Pydantic定义输出结构:
你可以将这个Pydantic模型的JSON Schema表示注入到Prompt中,并指示模型按照这个Schema来生成其JSON输出。这样,你就可以得到一个保证符合格式、可被程序直接反序列化为Python对象的干净结果,彻底告别了用正则表达式去解析模型输出的“脏活累活”。
三、结构化的实施层级
结构化应该贯穿于上下文工程的每一个环节:
在知识注入时:当我们将文档导入L3记忆时,就应该提取其固有的结构信息(如标题、章节、列表),并将其作为元数据与文本块一同存储。这能帮助我们在检索时,不仅仅是匹配内容,还能理解内容在原始文档中的位置和重要性。
在上下文构建时:在将不同来源的上下文(用户输入、L2记忆、L3检索结果)组合成最终的Prompt时,必须使用清晰的结构化标签将它们包裹起来。
在模型输出时:通过在指令中明确要求,并结合Pydantic等工具,强制模型输出结构化的、可被机器解析的格式。
结构化是上下文工程的“基建”。它是一项前期投入,可能会增加一些复杂性,但它带来的回报是巨大的:更高的可靠性、更强的可控性、更低的维护成本。在一个结构化良好的系统中,模型不再是一个难以预测的“黑箱”,而是一个遵循明确规则、行为可期的“逻辑引擎”。
四、最佳实践:基于LangChain官方文档的结构化输出实现
本文将基于LangChain官方文档提供的代码示例,展示如何利用LangChain和Pydantic,强制模型输出我们期望的、完全结构化的JSON对象。
1、使用Provider Strategy(原生结构化输出)
对于支持原生结构化输出的模型(如OpenAI、Anthropic Claude、xAI Grok),LangChain会自动选择Provider Strategy:
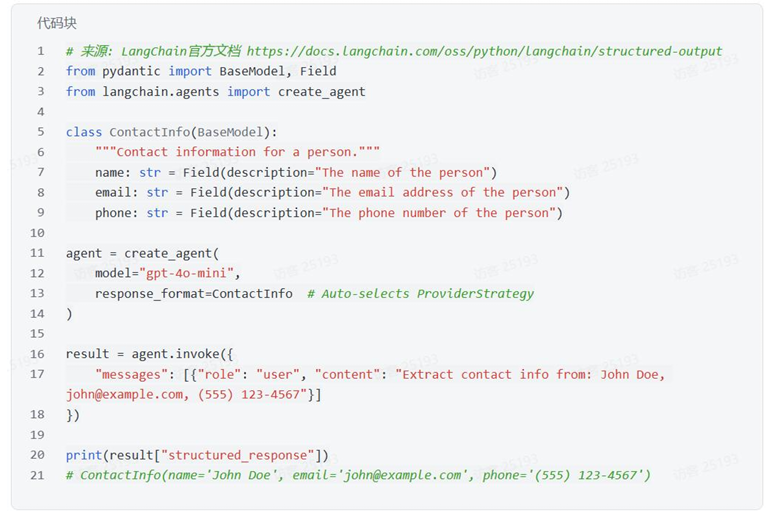
2、使用Tool Strategy(工具调用策略)
对于不支持原生结构化输出的模型,LangChain使用工具调用来实现相同的结果:

tool_message_content参数允许你自定义生成结构化输出时在对话历史中显示的消息:

4、代码分析
这些官方示例展示了LangChain结构化输出的核心优势:
自动策略选择:当你直接传递一个Pydantic模型给response_format时,LangChain会根据模型能力自动选择最佳策略(Provider Strategy或Tool Strategy)。
可靠的输出解析:结构化输出被自动验证并返回在structured_response键中,确保你得到的是符合Schema的、类型安全的数据对象。
灵活的错误处理:ToolStrategy支持handle_errors参数,可以配置自动重试机制来处理模型生成结构化输出时的错误。
通过这种方式,我们利用“结构化”这一支柱,将LLM从一个不稳定的“文本生成器”,转变为一个可靠的、可集成到软件工程流程中的“结构化数据生成器”。这是将LLM的能力从“演示”带向“生产”的关键一步。
二、上下文工程六大支柱:检索(Retrieval)
如果说“结构化”是为上下文信息建立了“骨架”,那么检索(Retrieval)就是为这个骨架填充“血肉”的过程。它是上下文工程的第二大支柱,其核心目标是:从海量的L3语义记忆库(以及可能的L2情景记忆库)中,精准、高效地找到与当前任务最相关的一小部分信息,并将其注入到L1工作记忆中。
在RAG(检索增强生成)框架下,检索的质量直接决定了最终生成答案的质量。一个完美的LLM,如果收到的上下文是错误的或不相关的,也无法生成正确的答案。所谓“垃圾入,垃圾出”(Garbage In, Garbage Out)。因此,掌握先进的检索策略,是构建高性能AI系统的关键所在。
1、超越基础向量搜索
基础的向量搜索,即计算查询向量与文档块向量之间的余弦相似度,是RAG的起点。然而,在复杂的现实场景中,单纯依赖语义相似度往往是不够的。它面临着两大挑战:
1.关键词失配:对于特定的术语、产品ID、代码变量名或缩写词,语义搜索可能无法精确匹配。例如,搜索“RAG”,模型可能会找回关于“布娃娃(rag doll)”的文档,因为它在语义上是相关的。
2.精度与召回的权衡:为了保证召回率(不漏掉相关信息),我们通常会设置一个较大的top-k值(如检索20个文档块)。但这可能导致精度下降,引入大量不相关的“噪声”文档,干扰模型的判断。
为了克服这些挑战,上下文工程师必须采用更先进、更精细的检索策略。
2、混合搜索:两全其美的艺术
混合搜索(Hybrid Search)是解决“关键词失配”问题的最有效方法之一。它将两种经典的搜索范式结合在一起:
关键词搜索(Keyword Search):基于传统的稀疏向量模型(如BM25),擅长精确匹配字词、ID和专有名词。
向量搜索(Vector Search):基于深度学习的密集向量模型(Embedding),擅长理解概念、意图和语义相关性。
混合搜索同时执行这两种搜索,然后通过一个融合算法(Fusion Algorithm)将两组结果合并,并重新计算排名。这样,它就能同时利用两种方法的优势:既能通过关键词锁定特定的实体,又能通过语义理解捕捉概念上的关联。
示例场景:

向量搜索可能会找到关于“大型项目”、“泰坦尼克号”等概念相关的文档。
关键词搜索会精确地匹配到包含字符串"Project-Titan"的文档。
混合搜索则能将两者的结果结合,最精准地返回标题为"Project-Titan v3.0 技术规格书"的文档。
Azure AI Search、Weaviate等现代搜索引擎和向量数据库都内置了对混合搜索的支持。
3、重排:从“粗筛”到“精选”
为了解决“精度与召回的权衡”问题,我们引入了重排(Reranking)机制。这是一种两阶段检索(Two-Stage Retrieval)策略:
1.第一阶段:召回(Recall):使用一个计算速度快、成本低的模型(如向量搜索或混合搜索),从海量文档中快速“粗筛”出一个较大的候选集(例如,top-50)。这个阶段的目标是“宁可错杀,不可放过”,保证所有可能相关的文档都被包含进来。
2.第二阶段:重排(Rerank):使用一个更强大、但计算成本更高的跨编码器(Cross-Encoder)模型,对第一阶段召回的候选集进行“精选”。跨编码器会同时处理“查询”和“每个候选文档”,并输出一个更精确的相关性分数。最后,根据这个分数对候选集进行重新排序,只将最顶部的几个(例如,top-3)文档传递给LLM。
重排的优势在于,它将昂贵的计算(跨编码器)限制在一个很小的候选集上,从而在保持高效的同时,极大地提升了最终上下文的“信噪比”。Cohere Rerank等是业界常用的重排模型。
4、查询转换:从“用户问题”到“机器问题”
很多时候,用户提出的原始问题,并非是送入检索系统的最佳形式。查询转换(Query Transformation)是一种在检索前对用户查询进行优化和重写的技术,旨在生成更适合机器检索的查询语句。
常见的查询转换技术包括:
子查询生成(Sub-Query Generation):对于复杂问题,可以先让LLM将其分解为多个更简单的子问题,然后对每个子问题分别进行检索,最后汇总结果。例如,对于“比较一下RAG和微调在知识更新上的优劣?”,可以分解为“RAG如何更新知识?”和“微调如何更新知识?”两个子查询。
假设性文档生成(Hypothetical Document Generation, HyDE):这是一种非常巧妙的技术。它首先让LLM根据用户的查询,生成一个“假设性的”、理想的答案文档。然后,它并不使用原始查询,而是使用这个生成的“伪文档”的向量来进行检索。其背后的逻辑是,一个理想的答案文档,在向量空间中应该与真实包含答案的文档块非常接近。这往往比直接用简短的查询进行检索效果更好。
查询扩展(Query Expansion):让LLM为原始查询生成同义词、相关术语或不同的表述方式,然后将这些扩展后的查询一并或分别送入检索系统,以提高召回率。
5、构建一个智能的检索流水线
一个先进的检索系统,不再是一个简单的“查询-返回”过程,而是一个精心设计的、多阶段的流水线(Pipeline):
用户问题→ [查询转换] → 优化后的查询 → [混合搜索] → 粗筛候选集 → [重排] → 精选的上下文 → LLM
通过综合运用结构化、混合搜索、重排和查询转换等方法论,上下文工程师可以构建出一个强大、智能的检索系统。这个系统能够从浩如烟海的知识库中,为每一次交互都“量身定制”出最精准、最简洁、最有效的上下文信息,为最终生成高质量的AI响应奠定坚实的基础。
6、最佳实践:基于LlamaIndex官方文档的重排实现
基于LlamaIndex官方文档提供的代码示例,展示如何使用Node Postprocessor实现重排(Reranking)机制。
1、使用SentenceTransformerRerank
LlamaIndex提供了SentenceTransformerRerank后处理器,使用sentence-transformer包中的跨编码器(Cross-Encoder)来重新排序节点,并返回前N个节点:

默认模型是cross-encoder/ms-marco-TinyBERT-L-2-v2,它提供最快的速度。你可以参考sentence-transformer文档获取更完整的模型列表(以及速度/准确度的权衡)。
2、使用CohereRerank
如果你有Cohere API密钥,可以使用Cohere的重排功能:

3、使用LLMRerank
使用LLM来重新排序节点,通过让LLM返回相关文档及其相关性分数:

4、使用ColbertRerank
使用Colbert V2模型作为重排器,根据查询token和段落token之间的细粒度相似度来重新排序文档:

5、完整的两阶段检索示例
以下是一个将重排器集成到查询引擎中的完整示例:

6、其他有用的后处理器
LlamaIndex还提供了其他有用的后处理器来优化检索结果:
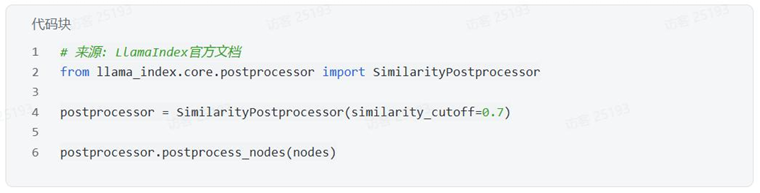
SimilarityPostprocessor - 移除相似度分数低于阈值的节点:
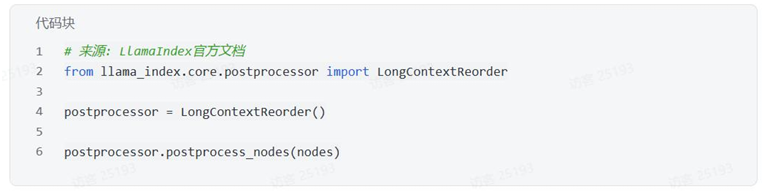
LongContextReorder - 重新排序检索到的节点以优化长上下文处理。研究表明,模型在处理长上下文时,对位于开头或结尾的信息表现更好:
通过这些官方提供的后处理器,你可以灵活地构建适合自己场景的两阶段检索流水线,显著提升RAG系统的检索精度和最终生成质量。
以上内容为《大模型上下文工程(Context Engineering)指南》的部分内容节选,完整版指南请扫描下方二维码下载。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献107条内容
已为社区贡献107条内容

所有评论(0)