多尺度注意力机制,为什么正在成为视觉智能的新主线?
过去几年,注意力机制已经从“提升性能的模块”,逐渐演变为许多智能视觉模型中的核心建模方式。而在最新一轮研究中,一个越来越清晰的方向正在浮现出来——多尺度注意力机制。无论是图像分割、目标检测、医学影像分析,还是点云理解、图像篡改定位与超分辨率重建,研究者都在尝试回答同一个问题:模型如何同时看清局部细节,又理解全局结构?近三年 CVPR、ICCV、ECCV、ICLR 等顶会论文表明,多尺度注意力不再只是简单的“多层特征融合”,而是正在向跨尺度交互、频域协同、层级建模与高效计算不断演进。本文将结合近年的代表性论文,带你快速看懂这一方向的核心思路、技术脉络,以及它为什么会成为当前视觉智能领域的重要研究热点。
1.M2SFormer: Multi-Spectral and Multi-Scale Attention with Edge-Aware Difficulty Guidance for Image Forgery Localization
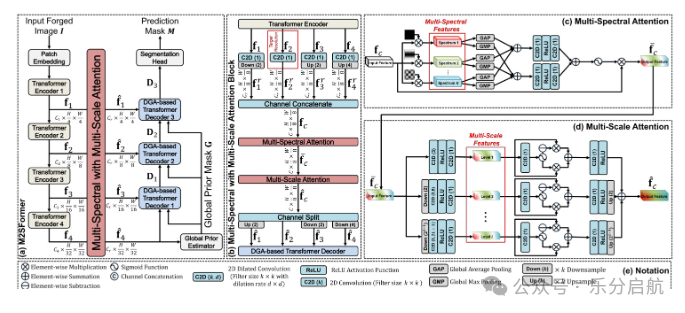
【创新点】
① 设计 MLAB 在浅层做多层级注意,突出细粒度表情线索;把多频谱信息和多尺度注意力统一放进 skip connection,而不是频域/空域分开做;
② 用全局先验图构造 difficulty-guided attention,重点保留细微伪造痕迹;
③ 在多个伪造定位基准上强调对 unseen domain 的泛化能力。
【方法】M2SFormer使用Transformer编码器框架,在跳接中统一处理多频段和多尺度注意力,并采用全局先验图和曲率度量的边缘感知难度引导模块,以更好地捕捉细微的伪造痕迹。
【实验】作者在多个基准数据集上进行了大量实验,证明了M2SFormer在检测和定位伪造图像方面优于现有最佳模型,并在未见过的领域展现出卓越的泛化能力。
2.HOTFormerLoc: Hierarchical Octree Transformer for Versatile Lidar Place Recognition Across Ground and Aerial Views
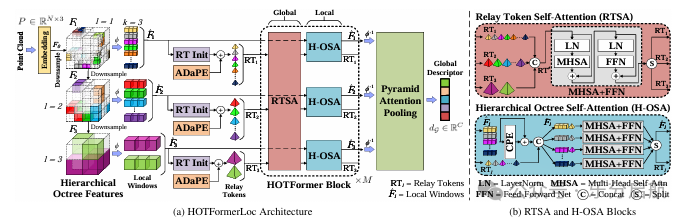
【创新点】
①提出八叉树多尺度注意力,在不同粒度上同时建模空间和语义特征;
② 用 cylindrical octree attention windows 适配旋转激光雷达点云的非均匀密度;
③ 通过 relay tokens + pyramid attentional pooling,实现更高效的全局—局部交互和检索描述子构建。
【方法】通过八叉树多尺度注意机制捕捉不同粒度下的空间和语义特征,并采用圆柱形八叉树注意窗口处理激光雷达点云密度变化问题,同时引入relay tokens以实现高效的全局-局部交互和降低计算成本。
【实验】在CS-Wild-Places数据集上评估HOTFormerLoc的性能,该数据集包含从地面和空中激光雷达扫描获得的点云数据,HOTFormerLoc在困难环境下实现了端到端的位姿识别,并取得了比现有最佳方法平均召回率高出5.5%的改进,以及5.8%的性能提升。
3.SegMAN: Omni-scale Context Modeling with State Space Models and Local Attention for Semantic Segmentation
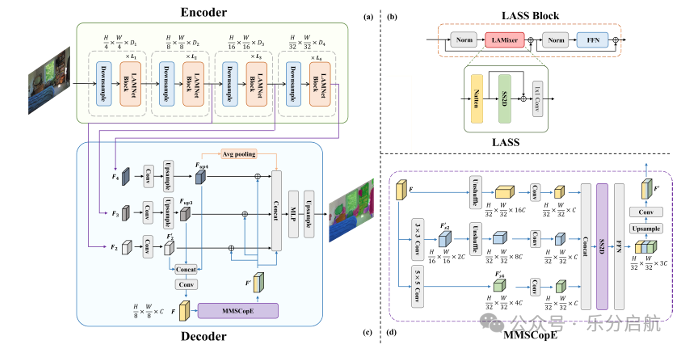
【创新点】
①把局部注意力和状态空间模型结合,兼顾局部细节与高效全局建模;
② 在解码端加入 MMSCopE,针对不同输入分辨率自适应增强多尺度上下文;
③ 以线性时间复杂度实现较强分割性能,在 ADE20K、Cityscapes、COCO-Stuff 上都有竞争力。
【方法】SegMAN模型包括SegMAN编码器和基于状态空间模型的解码器。SegMAN编码器通过结合滑动局部注意力和动态状态空间模型,实现了高效的全球上下文建模,同时保留了细粒度的局部细节。
【实验】作者在ADE20K、Cityscapes和COCO-Stuff三个具有挑战性的数据集上全面评估了SegMAN模型。SegMAN-B在ADE20K数据集上达到了52.6的得分,超过了SegNeXt-L和SegFormer-B3,并在COCO-Stuff数据集上提高了VWFormer-B3的性能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)