Retrieval-Augmented Perception: High-Resolution Image Perception Meets Visual RAG
首次将视觉检索增强生成(Visual RAG)技术应用于多模态大语言模型(MLLMs)的高分辨率(HR)图像感知任务,解决了现有 MLLMs 处理高分辨率图像时的细节丢失、空间关系破坏等核心问题。论文通过无训练的设计,结合空间感知布局和自适应检索裁剪策略,实现了 MLLMs 在高分辨率图像任务上的性能大幅提升,且具备模型无关性,可适配各类主流 MLLMs。
一、研究背景与问题
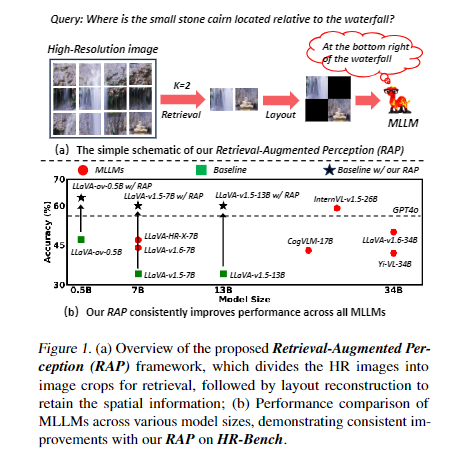
- MLLMs 的高分辨率图像感知瓶颈现有 MLLMs 通常将图像缩放到固定低分辨率(如 448×448)处理,导致高分辨率图像出现形状畸变、细节模糊,严重影响视觉定位、光学字符识别(OCR)等需要细粒度视觉信息的任务性能。
- 现有解决方案的局限性目前提升 MLLMs 高分辨率感知能力的方法分为三类,均存在明显缺陷:
- 裁剪法:将图像切分为多个块独立编码,但仍需下采样,丢失细粒度细节;
- 高分辨率视觉编码器法:通过专用编码器提取特征,未从根本上解决视觉 token 序列过长的问题;
- 搜索法:采用自顶向下的分层检索,但初始阶段难以感知小目标,易产生错误检索路径,且无法并行处理,部署效率低。
- 研究动机借鉴检索增强生成(RAG)在大语言模型长上下文处理中的成功经验,论文提出核心问题:能否将 RAG 直接应用于 MLLMs,通过检索高分辨率图像的关键裁剪块,提升其长上下文视觉感知能力?同时,图像的二维空间特性带来新挑战:①如何组织检索到的图像裁剪块?②检索裁剪块的数量如何影响性能?③如何设计适配 MLLMs 的视觉 RAG 系统?
二、先导研究(Pilot Study)
为解决上述核心挑战,论文在HR-Bench(4K/8K 高分辨率基准数据集) 上开展系统性实验,得到两个关键结论:
- 检索裁剪块的布局策略对比三种布局方式,保留裁剪块的相对空间位置对性能提升最关键,尤其对依赖空间关系的跨实例感知任务(FCP),能平衡单实例感知(FSP)和跨实例感知的性能。
- 检索裁剪块的数量影响
- 单实例感知任务(FSP):少量裁剪块即可实现性能提升,过多会因分辨率过高导致模型推理错误;
- 跨实例感知任务(FCP):需要更多裁剪块保留细节,过少会因信息丢失导致性能下降,但数量过多仍会产生负面影响。
三、核心方法:检索增强感知(RAP)
RAP 是无训练、模型无关的框架,核心设计围绕空间感知布局(Spatial-Awareness Layout) 和检索探索搜索(RE-Search) 两大模块,解决裁剪块的空间保留和自适应数量选择问题,整体流程为:图像分块→检索查询相关块→空间布局重构→自适应选择最优块数→MLLMs 推理。
1. 空间感知布局(Spatial-Awareness Layout)
核心目标:在保留查询相关裁剪块的同时,维持其原始相对空间位置,避免空间关系破坏。
- 构建二进制矩阵M表示图像分块的保留 / 移除状态(1 = 保留,0 = 移除);
- 压缩矩阵M为M′,剔除全 0 行 / 列,仅保留包含有效裁剪块的行 / 列;
- 定义映射函数Φ,将M′的坐标映射回原始矩阵M的坐标,基于此重构新图像V′,确保裁剪块的空间关系不变。
2. 检索探索搜索(RE-Search)
核心目标:基于模型置信度和检索相似度,自适应选择最优的检索裁剪块数K,适配不同任务类型。该模块基于A * 搜索算法设计(兼顾效率和鲁棒性,优于蒙特卡洛树搜索 MCTS 和分层搜索),包含三个核心组件:
- RE-Tree:将高分辨率图像建模为树结构,同一层节点代表保留不同比例裁剪块的图像,从低分辨率开始感知,避免模型收敛到次优解;
- REward 代价函数:结合实际代价g(查询与裁剪块的相似度均值)和估计代价h(模型对当前图像能否回答查询的置信度),并通过深度权重w动态平衡二者:f(ts)=(1−w)⋅g(ts)+w⋅h(ts)其中权重w随树深度增加而增大,解决模型在浅深度对高分辨率图像置信度低的问题;
- 终止条件:当模型对重构图像的回答置信度超过阈值τ=0.6,或搜索步数达到最大值时,停止搜索并输出最优重构图像。
3. RAP 整体工作流
- 将高分辨率图像切分为若干裁剪块,块大小不超过检索器编码器的预定义分辨率;
- 利用 VisRAG 计算每个裁剪块与查询的余弦相似度,筛选候选块;
- 通过空间感知布局重构候选块,维持空间关系;
- 通过RE-Search在 RE-Tree 中搜索,自适应选择最优K,得到最终重构图像Vf;
- 将Vf输入 MLLMs,完成高分辨率图像感知推理。
四、实验设计与结果
论文在高分辨率专用基准和通用多模态基准上开展全面实验,验证 RAP 的有效性、通用性和效率,同时通过消融实验、对比实验分析模块作用和核心特性。
1. 实验基准
- 高分辨率专用基准:V∗Bench(平均分辨率 2246×1582)、HR-Bench 4K/8K(含 FSP/FCP 子任务);
- 通用多模态基准:MME-RealWorld(真实场景,含监控、自动驾驶、OCR 等子任务);
- 辅助基准:DocVQA、ChartQA、TextVQA 等经典多模态数据集。
2. 核心实验结果
(1)高分辨率任务性能大幅提升
RAP 适配各类开源 / 闭源 MLLMs(LLaVA、InternVL、Yi-VL、GPT4o 等),均实现显著性能提升:
- LLaVA-v1.5-13B 在V∗Bench 提升43%,HR-Bench 提升19%;
- 平均在高分辨率基准上实现24%的准确率提升,HR-Bench 8K 上最大提升21.7%;
- 对空间推理任务提升尤为显著,如 LLaVA-v1.5-7B 在V∗Bench 空间任务上提升39.5%。
(2)通用多模态任务泛化性良好
在 MME-RealWorld 的真实场景任务中,RAP 对监控、自动驾驶、OCR等依赖细粒度视觉的任务提升明显(OCR / 车牌识别提升 10.3%,自动驾驶意图识别提升 6.0%);仅对图表、表格类任务无明显提升(受限于 MLLMs 自身的空间推理能力)。
(3)模型无关性与通用性
RAP 在不同参数量、不同架构的 MLLMs 上均实现稳定提升,包括小模型 LLaVA-ov-0.5B、大模型 LLaVA-v1.6-34B、专用高分辨率模型 LLaVA-HR-X,验证了其模型无关的核心特性。
3. 消融实验:验证各模块作用
以 LLaVA-v1.5-7B 在 HR-Bench 8K 上的实验为例,逐步添加模块的性能变化如下:
- 仅用 VisRAG 检索:平均提升 4.5%,FSP 提升显著但 FCP 下降;
- 加入空间感知布局:FCP 性能恢复,解决空间关系破坏问题;
- 加入RE-Search:自适应选择K,最终平均提升21.7%,FSP 和 FCP 均大幅提升。
4. 对比实验:优于现有高分辨率处理方法
与当前 SOTA 的搜索法(DC²、Zoom Eye)对比,RAP 在性能和效率上均占优:
- 性能:LLaVA-v1.5-7B 在 HR-Bench 8K 上,RAP 较 Zoom Eye 再提升 6.8%;
- 效率:RAP 的吞吐量(4.2 样本 / 分钟)高于 DC²(2.1)和 Zoom Eye(3.3),因无需分层分区,直接计算查询与裁剪块的相关性,加速检索过程。
5. 鲁棒性与扩展性实验
- 置信度替代方案:针对闭源模型无法获取 logit 置信度的问题,提出生成式置信度(通过 prompt 让模型生成 0-10 的置信度分数),虽性能略低于 logit 置信度,但仍比基线提升 7.4%,且二者余弦相似度达 0.97,适配性良好;
- 裁剪块大小:不同裁剪块尺寸(224×224/448×448/896×896)下,RAP 均大幅优于基线,性能差异小,鲁棒性强;
- 检索器替换:即使替换为性能较弱的检索器 SigLIP,RAP 仍能提升 9.1%,验证了框架对检索器的低依赖性;
- 超参数敏感性:代价函数的偏置值b在 0.2-1.0 范围内变化时,RAP 始终优于基线,且小b(0.2)性能最优,超参数鲁棒性良好。
五、关键分析与发现
- 检索相关块的必要性:随机保留裁剪块的性能远低于检索查询相关块,证明定向检索是提升高分辨率感知的核心;
- 最优K的任务适配性:RAP 为 FSP 任务选择小K,为 FCP 任务选择大K,精准匹配先导研究的结论;
- 空间关系的重要性:丢失裁剪块的相对空间位置会导致 FCP 任务性能大幅下降,证明空间感知布局是 RAP 的核心设计之一。
六、局限性与未来工作
- 当前局限性:RAP 依赖外部检索器实现图像块与查询的相关性匹配,未利用 MLLMs 自身的视觉感知能力自适应选块;
- 未来研究方向:
- 探索模型内部视觉感知机制,无需外部检索器即可自适应选择关键图像块;
- 结合更多token 压缩技术,进一步提升高分辨率图像的处理效率和感知能力;
- 优化空间感知布局,适配更复杂的空间推理任务(如图表、表格分析)。
七、论文贡献
- 首次探索:将视觉 RAG 技术应用于 MLLMs 的高分辨率图像感知,为解决高分辨率视觉瓶颈提供了新范式;
- 提出无训练框架:设计 RAP,通过空间感知布局和 RE-Search,在不训练的前提下实现 MLLMs 高分辨率感知能力的大幅提升,且具备模型无关性,易于部署;
- 系统性验证:在多个高分辨率和通用基准上开展全面实验,验证了 RAP 的有效性、鲁棒性和效率,为后续研究提供了可靠的基准和分析;
- 关键结论:明确了检索相关块、保留空间关系、自适应选择块数是提升 MLLMs 高分辨率感知的三大核心因素。
八、代码与数据
论文开源了 RAP 的代码,地址为:https://github.com/DreamMr/RAP,为后续研究和工业界应用提供了可复现的基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)