【论文阅读】Vision-skeleton dual-modality framework for generalizable assessment of Parkinson’s disease ga
论文题目:《Vision-skeleton dual-modality framework for generalizable assessment of Parkinson’s disease gait》
论文链接:https://doi.org/10.1016/j.media.2025.103727
代码链接:https://github.com/FJNU-LWP/PD-gait-VSDF
视觉-骨架双模态框架:通过视频实现帕金森病步态的泛化评估
位置与连接嵌入 (Positions and connections embedding)
关键点自注意力 (Keypoints Self-Attention, KSA)
骨架特征提取 (Skeleton features extraction)
时间融合编码器 (Temporal Fusion Encoder)
研究背景介绍
帕金森病评估与帕金森病评分量表(MDS-UPDRS)
步态评估在衡量帕金森病(PD)患者的病情严重程度中起着至关重要的作用 。通过仔细观察和分析步态表现,医生可以深入了解帕金森病的进展,从而制定更精确的诊断和治疗方案 。目前在临床实践中,被广泛接受的 PD 步态评估标准是基于 MDS-UPDRS(统一帕金森病评分量表)第三部分的内容 。在评估过程中,患者必须遵守 MDS-UPDRS 中规定的测试协议,以准确捕捉其步态特征 。这要求经过专业培训的评估人员仔细观察关键的步态指标,并对步态表现进行全面评估 。然而,这种方法极其耗时,且需要大量的医疗资源 。尽管评估人员具备专业培训和丰富经验,但主观性差异仍可能影响评分,引入了显著的主观性因素 。因此,临床上迫切需要一种客观且精确的 PD 患者步态评估方法 。近年来,许多研究探索了基于可穿戴传感器的各种自动化技术来量化 PD 患者的步态运动 。然而,这些方法依赖于直接接触患者身体的传感器,不可避免地会影响 PD 患者的自然运动,这阻碍了它们在临床实践中的广泛采用 。
帕金森病步态评估
随着计算机视觉技术的进步,基于视频的非接触式 PD 步态评估方法应运而生,克服了基于传感器方法的局限性 。视频技术为 PD 评估提供了一种非接触、可扩展且无创的方法 。近期的研究利用视频技术,辅以深度学习和人体姿态估计算法,来准确量化人体运动,证明了非接触式视频分析技术能够有效、快速地评估 PD 患者的步态 。然而,目前大多数基于视频的方法仅仅依赖于在视频中通过人体姿态估计获取的骨架信息,而忽略了 PD 步态的视觉特征 。而且,它们仅应用于单一录制视角的 PD 步态评估,展现出有限的泛化能力 。此外,大多数现有的基于视频的方法依赖于光流或姿态估计等中层特征,这可能会在提取过程中丢弃原始 RGB 图像中的某些视觉信息 。但是,直接使用视频中的全部 RGB 信息又会引入不必要的背景细节,并显著增加不必要的计算量 。事实上,临床评估人员主要关注的是各个特定身体部位的状态 。不仅如此,由于 PD 步态评估是一个综合的过程,除了局部视觉细节,如何有效地利用更宏观的骨架运动特征也值得进一步考量 。
研究内容
总体方法流程
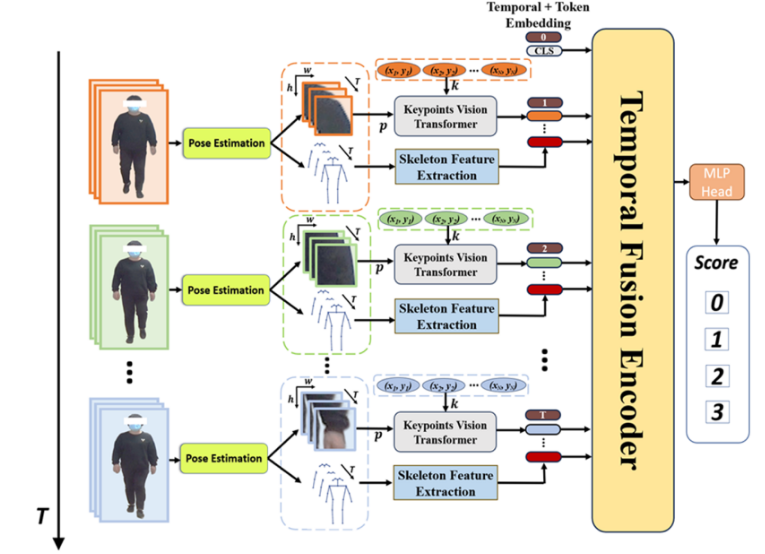
视觉-骨架双模态框架总体工作流程如下图所示 。首先,通过人体姿态估计技术从步态视频中提取关键点的视觉信息和骨架信息 。对于关键点视觉,模型将带有坐标信息的特征块输入到关键点视觉 Transformer(KVT)中以提取视觉特征 。随后,模型将提取到的骨架运动特征与 KVT 提取的关键点视觉特征进行融合,并输入到时间融合编码器(Temporal Fusion Encoder)中,以进一步提取步态的时间动态特征 。最后,最终的评估分数由一个多层感知器(MLP)头部输出 。
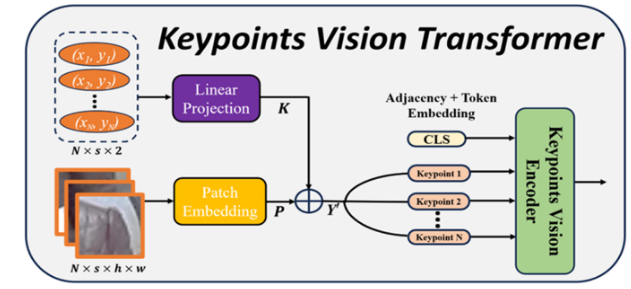
关键点视觉 Transformer (KVT)
为了捕捉局部身体部位在行走时的视觉细节,作者设计了一种全新的 Transformer 模型来提取人体关键点的视觉特征(如下图所示) 。
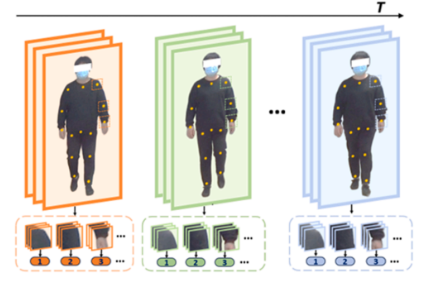
图像块嵌入 (Patches embedding)
模型并非将整张图片输入,而是围绕关键点提取短时间序列的帧序列图像块(如下图)。对于视频![]() ,获取关键点局部视频块
,获取关键点局部视频块![]() 后,使用 3D 卷积来提取反映短期变化的特征,从而生成关键点Tokens (KT)
后,使用 3D 卷积来提取反映短期变化的特征,从而生成关键点Tokens (KT)![]() 。
。
位置与连接嵌入 (Positions and connections embedding)
考虑到关键点不仅具有绝对的坐标位置,关键点之间还存在物理结构上的连通性 。该模型通过可学习的线性投影直接嵌入关键点坐标 ![]() ,并与
,并与 ![]() 拼接得到
拼接得到![]() :
:
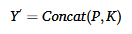
随后,引入了基于关键点邻接矩阵 ![]() 的邻接嵌入(Adjacency Embedding, AE)来表示身体各部位之间的连接信息 :
的邻接嵌入(Adjacency Embedding, AE)来表示身体各部位之间的连接信息 :
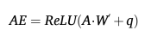
最后,将 AE 加入到特征中,并在序列头部添加一个 CLS Token :
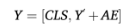
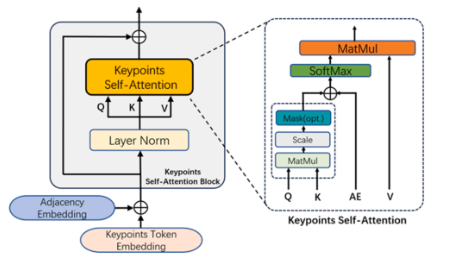
关键点自注意力 (Keypoints Self-Attention, KSA)
如下图所示,输入数据首先通过线性投影转换为 Queries (Q), Keys (K), Values (V) :
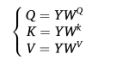
在 Transformer 的自注意力计算阶段,模型将上述的邻接嵌入(AE)融入其中,使得注意力权重的计算不仅基于特征相似度,还能充分考虑到人体关键点之间的物理连接性 :
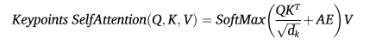
骨架特征提取 (Skeleton features extraction)
在获取了人类关键点的视觉特征后,模型采用经典的时空图卷积网络(ST-GCN)来提取 PD 步态的全局骨架特征 。该部分将空间连接与时间维度相结合,能够从宏观角度提取人体行走的运动规律 :
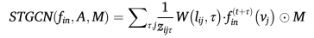
时间融合编码器 (Temporal Fusion Encoder)
对于同一时间段内提取到的“局部关键点视觉特征”与“全局骨架运动特征”,模型首先通过拼接(Concatenation)的方式进行特征融合![]() 。为了提取整个视频的全局时间动态特性,融合后的特征序列被输入到时间融合编码器中,该编码器还加入了时间嵌入(Temporal Embeddings, TE) :
。为了提取整个视频的全局时间动态特性,融合后的特征序列被输入到时间融合编码器中,该编码器还加入了时间嵌入(Temporal Embeddings, TE) :
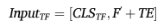
最后,评估分数由 MLP 头部计算输出 :
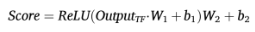
实验结果
在作者的研究中,由于单独特征在不同评分等级上的表现存在差异,因此作者在实验部分首先进行了骨架运动与关键点视觉的消融实验 。作者列举了所提框架中两个分支之间相互比较,该实验结果如下表:

由该结果可以看出,在双模态方法中,关键点视觉在非0评分的量化中表现比骨架运动更好 。这表明关键点视觉能够更好地捕捉步态中细微特征的变化。此外,还可以看出双模态特征融合能有效提升对视频中PD步态的整体评估准确性 。
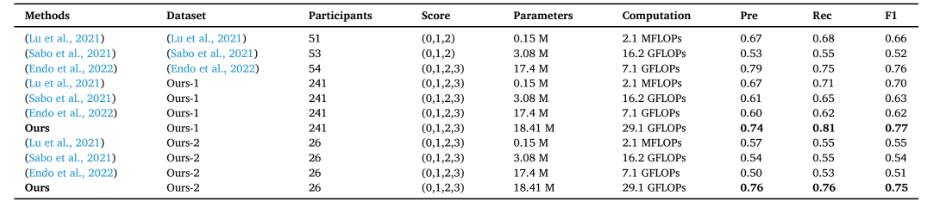
此外,作者还比较了目前几种帕金森步态严重程度评估的方法 。表明了本文提出的方法以视频方式在一个更多参与者的数据集中实现了更为准确的帕金森步态评估,并在更一般的录制条件下(Ours-2 跨视角)展现出了极其显著的泛化优势 。
结论
该研究开创性地提出了一种用于评估 MDS-UPDRS 步态严重程度的视觉-骨架双模态深度学习框架 。通过引入独特的关键点视觉 Transformer 以及时间融合编码器,该模型不仅有效弥补了传统骨架方法在微小视觉特征上的丢失,还显著提高了多类别评分的准确性 。更重要的是,该模型在更一般化的跨视角监控数据上表现出了极高的鲁棒性,这为未来在家庭和社区环境中实现无约束的帕金森病远程监测与评估提供了极其可行的技术方案 。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)