给AI装上“大脑“:LLM Agent记忆机制解析
为什么有些AI Agent能记住你上周说过喜欢川菜,并在今天推荐餐厅?秘密就在于记忆机制——这是让LLM从"聊天机器人"进化为"智能体(Agent)"的核心组件。
本文将解读《A Survey on the Memory Mechanism of Large Language Model based Agents》这篇论文,说明LLM-based Agent的记忆机制并拆解AI记忆的"存储-管理-检索"全链路.
一、为什么Agent必须拥有记忆?
在传统的LLM交互中,每次对话都是独立的。但现实中的智能体需要持续学习和自我进化:
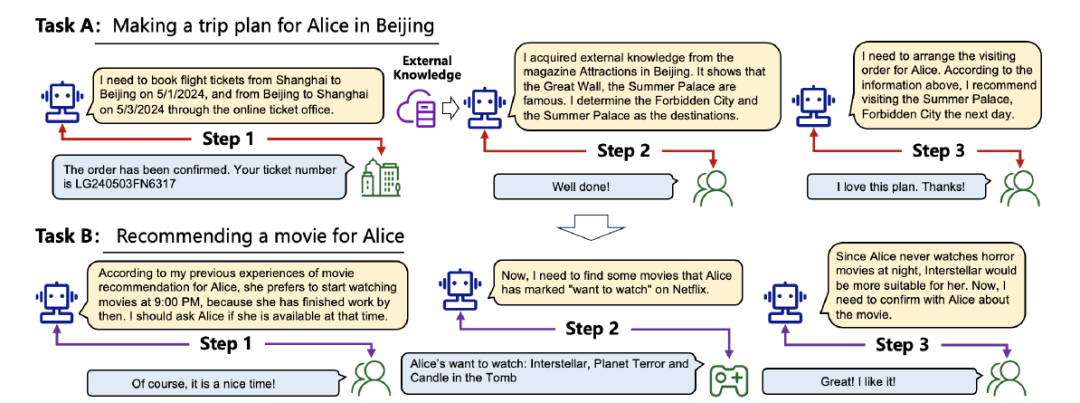
应用场景示例
如图所示,无论是帮Alice规划北京之旅(任务A),还是推荐电影(任务B),Agent都需要:
-
- 记住之前的对话(如Alice偏好9点看电影)
-
- 积累跨任务经验(从任务A了解Alice喜欢古建筑,在任务B推荐相关纪录片)
-
- 调用外部知识(查询实时航班信息、景点开放时间)
没有记忆,Agent就像金鱼——每次互动都从零开始,无法形成个性化服务,更无法在复杂环境中自我提升。
1.1 认知心理学视角
人类依靠记忆来:
- • 积累知识:通过经验抽象出"Alice是上班族,周末才有空"这样的高层概念
- • 形成社会规范:记住文化价值观(如"推荐餐厅时要考虑预算")
- • 行为决策:想象行为的正负后果(“如果推荐恐怖片,Alice可能会不高兴”)
1.2 自我进化视角
记忆支持Agent的三种核心能力:
- • 经验积累:记住失败的预订(如选错机场),避免重蹈覆辙
- • 环境探索:根据历史探索记录决定下一步尝试(优先探索未去过的地方)
- • 知识抽象:从"Alice上周吃川菜很开心"抽象出"Alice喜欢辣"
二、记忆的数学定义:狭义 vs 广义
设任务为 ,第个任务的第步的动作为,环境反馈为。
2.1 狭义记忆(Inside-trial)
仅包含当前任务内的历史交互:
局限:每次任务结束就"失忆",无法跨任务学习。
2.2 广义记忆(Broad Definition)
包含三个维度:
其中:
- • :同任务历史(当前尝试中的步骤记录)
- • :跨任务经验(之前失败或成功的类似任务)
- • :外部知识(维基百科、实时API、专业知识库)
举例说明:
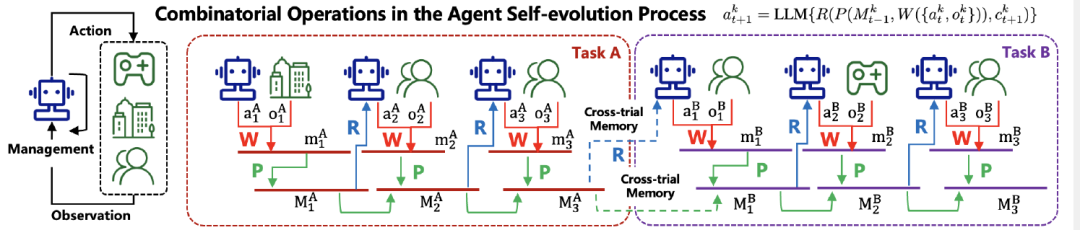
Agent自进化过程
假设Agent先为Alice规划了北京游(任务A),之后为她推荐电影(任务B)。在任务B的Step 3中,Agent的决策函数为:
这里是写入函数,是管理函数,是读取函数。Agent通过检索到任务A中"Alice选择了故宫和颐和园"(跨任务记忆),推断出她喜欢历史文化,于是推荐《长安三万里》而非《星际穿越》。
三、记忆系统架构拆解
论文提出,构建记忆系统需回答三个问题:从哪来?存哪?怎么用?
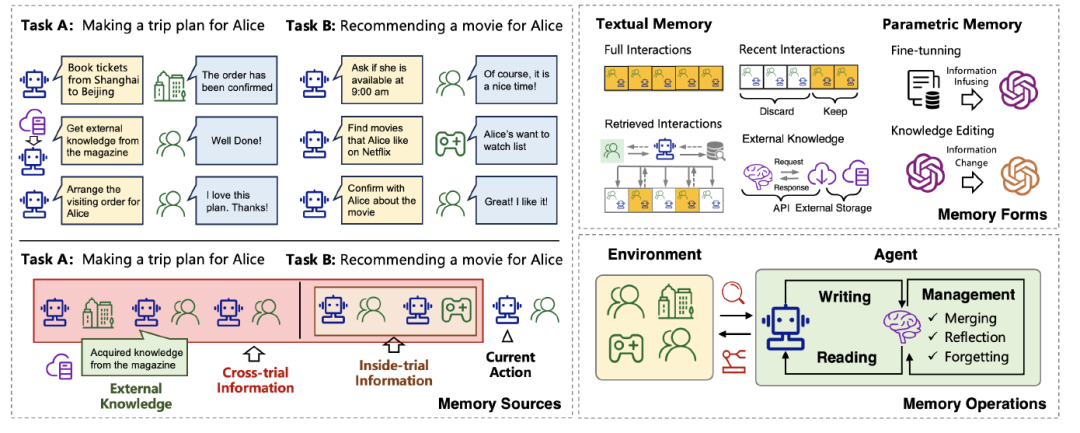
基于LLM的Agent记忆的来源、形式和操作概述
3.1 记忆从哪来?(Memory Sources)
论文将记忆来源分为三类:
| 来源类型 | 技术实现 | 典型案例 | 关键挑战 |
|---|---|---|---|
| Trial内信息 | 直接存储原始交互或压缩摘要 | MemoChat存储对话历史 | 信息噪声过滤,如何提取关键事实 |
| 跨Trial信息 | 反思总结(Reflection)+ 经验回放 | Reflexion将失败原因总结为自然语言"教训"; | 相似任务识别,经验泛化 |
| 外部知识 | API调用 + 向量数据库索引 | ReAct调用维基百科API; | 信息可靠性验证,多源知识冲突解决 |
技术细节:跨Trial记忆的实现
以Reflexion为例,其工作流程如下:
-
- 执行:Agent尝试任务,生成轨迹(Trajectory)
-
- 评估:环境给出成功/失败信号
-
- 反思:LLM生成文字总结:“失败原因:未确认机场代码。教训:上海有两个机场,必须询问用户偏好虹桥(PVG)还是浦东(SHA)”
-
- 存储:将反思文本存入记忆库
-
- 重用:下次遇到订票任务时,检索到该反思, prepend到Prompt中
3.2 记忆存哪?(Memory Forms)
方案A:文本记忆(Textual Memory)
将信息以自然语言、数据库或结构化文本存储。细分为四种实现策略:
① 完整记录(Complete Interactions)
直接将所有历史拼接进Prompt。
- • 技术实现:
prompt = "历史记录:[Step 1]...[Step 2]... 当前问题:..." - • 代表模型:LongChat(支持16K上下文)
- • 致命缺陷:
- • 计算复杂度(Transformer自注意力机制)
- • "Lost in the Middle"现象:LLM对长文本中间部分注意力衰减
- • 上下文长度限制
② 近期缓存(Recent Interactions)
滑动窗口机制,只保留最近轮。
- • 技术实现:队列(Queue)数据结构,FIFO淘汰
- • 代表模型:SCM(Self-Controlled Memory)使用"Flash Memory"缓存最近步观察
- • 类比:人类短期记忆(工作记忆),容量有限(7±2原则)
③ 检索式(Retrieved Interactions)
将记忆编码为向量,按需检索Top-K相关。
- • 技术实现流程:
-
- 索引阶段:使用Embedding模型(如BERT、Ada-002)将记忆文本转为向量,存入FAISS/Annoy向量数据库
-
- 检索阶段:将当前查询向量化,计算余弦相似度,召回最相关的条
-
- 重排序:结合时间衰减(Recency)和重要性(Importance)加权
- • 代表模型:
- • Generative Agents:使用双塔模型(Two-Tower)编码记忆,支持基于相似度、时间、重要度的复合检索
- • MemoryBank:使用FAISS(Facebook AI Similarity Search)实现高效近似最近邻搜索(ANNS)
- • RET-LLM:使用LSH(Locality-Sensitive Hashing,局部敏感哈希)加速检索,将相似记忆映射到同一哈希桶
④ 外部知识(External Knowledge)
通过工具调用(Tool Use)动态获取。
-
• 技术实现: ```plaintext
if “天气” in query: weather_data = call_api(“OpenWeatherMap”, location) memory.inject(weather_data) -
• 代表模型:ReAct、Toolformer、TPTU
文本记忆优缺点分析:
- • 优点:可解释性强(人类可读可编辑)、写入速度快(直接Append)、支持精确删除
- • 缺点:
- • 检索噪声:可能召回表面相关但语义无关的记忆(如"苹果"公司 vs "苹果"水果)
- • 上下文占用:即使只检索Top-3,仍占用数百Token
方案B:参数记忆(Parametric Memory)
将知识编码进模型参数。分为两类:
① 微调(Fine-tuning/SFT)
在领域数据上训练模型。
- • 技术细节:
- • 全量微调:更新所有参数,成本高,易灾难性遗忘
- • LoRA(Low-Rank Adaptation):冻结原参数,注入低秩矩阵,适合消费级GPU
- • 代表模型:
- • Huatuo:在LLaMA-7B上使用中文医学知识库SFT,注入CMeKG(中国医学知识图谱)
- • Character-LLM:使用角色相关对话数据SFT,让模型"内化"角色人格
- • InvestLM:金融投资数据微调,记忆专业术语和投资策略
② 知识编辑(Knowledge Editing)
针对性修改特定事实,不影响其他知识。
- • 技术原理:定位知识在模型中的存储位置(定位-编辑两阶段)
- • 定位:使用因果中介分析(Causal Mediation Analysis)找到关键层和神经元
- • 编辑:修改特定参数或添加约束
- • 代表方法:
- • MEND:训练超网络(Hypernetwork)生成参数更新,将编辑转化为元学习问题
- • ROME(Rank-One Model Editing):在特定层进行秩一矩阵更新
- • MAC:使用元学习实现"在线记忆适应",无需反向传播即可更新记忆
参数记忆优缺点分析:
- • 优点:
- • 零上下文占用(推理时不需要额外Prompt)
- • 信息密度高(连续向量空间 vs 离散Token空间)
- • 推理速度快(无需检索延迟)
- • 缺点:
- • 不可解释(黑盒)
- • 编辑副作用:可能引发"邻居扰动"(编辑"苹果CEO"时意外改变"苹果颜色"的知识)
- • 在线更新难:SFT需要大量数据,知识编辑难以处理大规模记忆
3.3 记忆怎么用?(Memory Operations)
完整的记忆生命周期包含三个操作:
① 写入(Writing):
将原始观察压缩为记忆存储。
技术实现策略:
- • 原始存储:直接存储JSON格式
{"action": "订机票", "observation": "用户选择虹桥机场", "timestamp": "2024-01-20"} - • 摘要提取:使用LLM生成摘要
例:将长对话"用户问了很多关于北京的问题,最后选择了故宫…“压缩为"用户偏好:古建筑” - • 结构化提取:抽取实体关系三元组(Entity-Relation-Entity)
例:(Alice, 喜欢, 川菜), (Alice, 厌恶, 恐怖片)
代表模型:
- • TiM(Think-in-Memory):将观察提取为关系对存入数据库
- • ChatDB:生成SQL语句将记忆写入关系型数据库,支持复杂查询
② 管理(Management):
对记忆进行处理,提升质量。
a. 反思(Reflection)——生成高层抽象
Generative Agents的实现细节:
-
- 触发条件:当积累个新观察(通常)时触发反思
-
- 生成问题:“给定这些观察,Alice的核心偏好是什么?”
-
- 抽象输出:生成"Alice是历史爱好者"、"Alice预算敏感"等高层概念
-
- 递归反思:对反思结果再次反思,形成概念层级(如"历史爱好者"→"文化旅行者")
b. 合并(Merging)——去重与聚类
- • 技术实现:使用聚类算法(如K-means)或相似度阈值,将"Alice喜欢川菜"和"Alice爱吃辣"合并为一条记忆
- • 代表模型:MemoryBank使用语义相似度检测冗余
c. 遗忘(Forgetting)——模拟人类记忆衰减
遵循Ebbinghaus遗忘曲线:,其中是记忆强度。
- • 实现方式:为每条记忆添加时间戳和重要性分数,定期清理低于阈值的记忆
- • 代表模型:Generative Agents使用重要性评分(Importance Score),RecAgent模拟人类记忆衰退
③ 读取(Reading):
根据上下文检索相关记忆。
技术实现:
- • 稀疏检索:TF-IDF、BM25(适合关键词匹配)
- • 密集检索:向量相似度(适合语义匹配)
- • 混合检索:稀疏+密集(如ChatDB使用SQL+向量检索)
高级技巧:
- • Chain-of-Memory:ChatDB生成SQL查询链,分步检索(先查用户偏好,再查具体记录)
- • 记忆过滤:MPC(Memory Prompt Compression)使用Chain-of-Thought示例教模型忽略不相关记忆
四、如何评价记忆系统?
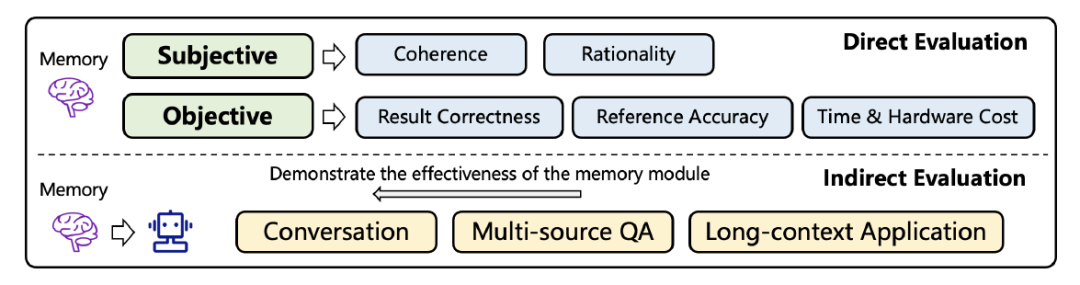
| 评估大类 | 评估维度 | 具体指标 | 评估方法/说明 | 计算公式/实验设置 | 案例/备注 |
|---|---|---|---|---|---|
| 直接评估 | 客观指标 | 结果正确率 (Result Correctness) | 构造问答对测试记忆准确性 | ChatDB论文设置:从历史记录生成问题(如"Alice昨天去了哪里?"),选项A.故宫 B.长城,要求Agent仅基于记忆回答 | |
| 引用准确率 (Reference Accuracy) | 评估检索质量,使用F1分数 | 问题:“Alice喜欢什么菜系?” 理想检索:(A)“Alice昨天吃了川菜”(相关)、©"Alice讨厌粤菜"(相关但负面) 应忽略:(B)“Alice昨天吃了晚饭”(无关) | |||
| 效率指标 | 适应时间 | 写入+管理的延迟 | MemoryBank报告为毫秒级 | ||
| 推理时间 | 检索延迟 | FAISS可在毫秒级检索百万级向量 | |||
| 硬件成本 | 峰值GPU显存占用 | 参数记忆需加载完整模型;文本记忆只需加载Embedding模型 | |||
| 主观评估 | 一致性 (Coherence) | 人类标注员评分:检索的记忆与当前上下文逻辑是否连贯 | 招募人类标注员进行评分 | 定性评估 | |
| 合理性 (Rationality) | 人类标注员评分:记忆内容是否符合常识 | 招募人类标注员进行评分 | 避免"Alice住在月球"等不合理内容 | ||
| 间接评估 | 下游任务 | 对话一致性 | 使用GPT-4作为评判,检测Agent回复是否与历史矛盾 | GPT-4自动评判 | 如:前面说Alice怕辣,后面却推荐火锅 |
| 长文本"大海捞针" (Needle-in-Haystack) | 在长文档中插入关键信息,测试后续回忆能力 | 在100页文档中插入关键信息(如"Alice的生日是3月15日") | 测试Agent能否在后续对话中准确回忆该信息 | ||
| 成功率 (Success Rate) | 在仿真环境中统计Agent完成任务的比例 | 对比"有记忆"vs"无记忆"的基线差异 | AlfWorld(家庭机器人仿真环境)、Minecraft等环境 |
五、记忆驱动的Agent应用
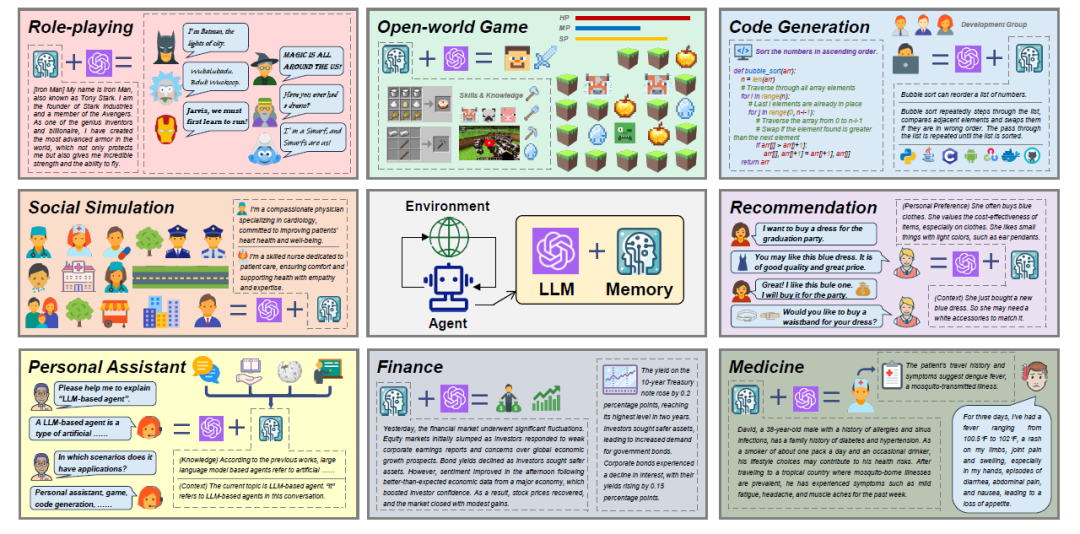
六、工程化实现
将记忆拆分为三层模型
| 层级 | 名称 | 定义/实现方式 | 核心特点 | 持续时间/容量 |
|---|---|---|---|---|
| 第一层 | 感知记忆 (Sensory Memory) | 暂存原始多模态信息 (文本、图像、音频等) | • 容量极小 • 信息若不立即处理即消失 | 极短(几秒内) |
| 第二层 | 短期记忆 (Short-term Memory) | 主要通过上下文窗口 (Context Window) | • 主动处理信息 • 需优化策略扩展容量 | 有限,依赖窗口大小 |
| 第三层 | 长期记忆 (Long-term Memory) | 持久化存储,可跨会话访问 | • 容量大 • 需解决存储与检索效率 | 永久 |
短期记忆解决方案
| 方法 | 核心原理 | 技术特点 |
|---|---|---|
| 滑动窗口 (Sliding Window) | 保留最近N轮对话,丢弃早期信息 | 简单直接,只保留最近token数量 |
| 摘要压缩 (Summary Compression) | 将早期对话压缩为摘要 | • ChatBC:定期压缩对话历史 • MemGPT:分"交互上下文"(当前)和"Agent上下文"(压缩历史) |
| 检索增强 (RAG) | 用户查询→检索文档→插入上下文→生成 | 不直接存储历史,按需检索相关信息 |
长期记忆存储方式
| 存储方式 | 原理 | 关键技术/方法 | 主要挑战 |
|---|---|---|---|
| 参数化记忆 | 知识存储在模型参数中 (通过微调) | • EWC (弹性权重巩固) • 梯度投影法 • 回放法 | 灾难性遗忘 (学习新任务时忘记旧知识) |
| 非参数化记忆 | 记忆存储在外部数据库 | A. 向量数据库 • Embedding模型 • 相似度检索 B. 结构化数据库 • 键值对存储 | 检索精度、存储效率 |
| 混合记忆架构 | 结合多种存储方式 | • 向量检索+结构化规则 • 知识图谱+向量库 | 系统复杂度 |
向量数据库技术细节
| 技术环节 | 具体实现 | 代表模型/方法 |
|---|---|---|
| 文本向量化 | 文本→Embedding模型→高维向量 | • BERT系列 • SimCSE • E5 • OpenAI Embeddings |
| 存储系统 | 向量数据库 | • FAISS • Pinecone • ChromaDB |
| 检索策略 | • 密集检索:向量相似度 • 稀疏检索:TF-IDF/BM25 • 混合检索:两者结合 | • Dense: Karpukhin et al. • Sparse: Robertson & Zaragoza • Hybrid: Dai & Callan |
| 重排序 (Reranking) | 初次检索后用精确模型重排 | • 步骤1:BM25检索top-100 • 步骤2:Cross-Encoder重排top-10 • 步骤3:输入LLM |
将记忆机制拆分为五大工程模块
| 模块 | 核心功能 | 关键技术 | 主要挑战 | 决策公式/阈值 |
|---|---|---|---|---|
| 写入 (Write) | 将交互信息编码并持久化 | • Embedding编码 • 元数据标注 • 触发器机制 | 如何判断"重要性" 避免存储膨胀 | score = importance × (1+0.1×repeat) × decay |
| 存储 (Store) | 高效存储与索引向量数据 | • 向量数据库 • ANN算法 • 混合索引 | 平衡召回率与延迟 海量数据内存占用 | HNSW(在线)/IVF+PQ(离线) |
| 检索 (Retrieve) | 从记忆库召回相关信息 | • Dense+Sparse混合 • Cross-Encoder重排 • 时间加权 | 上下文长度限制 噪声过滤 | 先召回200→重排→选top-k |
| 更新 (Update) | 合并重复、摘要历史 | • 语义聚类 • 增量摘要 | 合并时机与粒度控制 | 定期聚类(天/周) |
| 遗忘 (Forget) | 清理低价值记忆 | • 多因子评分 • LRU/LFU | 避免误删重要信息 | score = 0.5×importance + 0.4×freq - 0.1×age |
写入模块 (Write / Encoding)
| 维度 | 实现方案 | 技术细节与建议 |
|---|---|---|
| 触发时机 | 多维度触发器 | • 显式事件:用户保存指令、关键确认语句(“记住我喜欢X”) • 频次触发:同一信息被重复提及N次 • 模型判定:判别器预测重要度>阈值 |
| 编码方式 | Embedding + 元数据 | • 文本→Embedding模型→高维向量 • 归一化:保留normalized embedding确保余弦相似度稳定 • 元数据:timestamp、source、重要度评分、主题标签、模型版本 |
| 切分粒度 | 语义完整性优先 | • 对话粒度:按句/按轮/按主题切分 • 长文本处理:滑动窗口或基于语义的chunking |
| 质量控制 | 过滤-摘要-评分 | • 使用小型分类器预测重要性 • 避免"全部写入"导致的噪声与存储膨胀 |
存储模块 (Store)
| 维度 | 技术选型 | 策略与优化 |
|---|---|---|
| 存储介质 | 分层存储架构 | • 热数据:内存向量库(FAISS/Milvus/Weaviate) • 冷数据:磁盘/对象存储(低成本) • 元数据:传统数据库+倒排索引 |
| 向量索引 | ANN算法选择 | • HNSW:高召回、低延迟,适合在线检索 • IVF+PQ:海量数据下显著降低内存占用 |
| 混合索引 | 向量+倒排 | • 向量索引:语义相似度 • 倒排索引:精确匹配(user_id、topic等字段联合筛选) |
| 元数据字段 | 结构化标注 | user_id、timestamp、topic、importance、source_id、embedding_model_version |
检索模块 (Retrieve)
| 环节 | 技术方案 | 实现细节 |
|---|---|---|
| 召回阶段 | 混合检索 (Dense + Sparse) | 1. BM25/ES:先做精确匹配和关键词过滤 2. 向量检索:ANN搜索语义候选(top-200) 3. 合并去重:融合两种检索结果 |
| 精排阶段 | Cross-Encoder重排序 | • 使用较小Transformer对候选评分 • 仅对top-N(N≈50)应用,控制延迟 • 按任务相关性重新排序 |
| Prompt组装 | 多策略选择 | • 语义优先:按cross-encoder得分选top-k • 时间加权:近期事件提升分数(避免过时) • 压缩注入:每条记忆生成一行summary再拼接 |
| 检索时机 | 策略驱动 | 每轮问答时自动触发,或特定策略驱动 |
更新模块 (Update / Consolidation)
| 维度 | 策略 | 实现细节 |
|---|---|---|
| 更新目标 | 记忆优化 | • 合并重复条目 • 摘要历史交互(抽象化) • 提升长期重要信息权重 |
| 聚类合并 | 定期批量处理 | • 周期:每天/每周对情节层聚类 • 操作:主题一致条目合并为摘要,替换冗余数据 |
| 增量更新 | 实时冲突检测 | • 新事件命中已有条目(高相似度)时: - 方案A:追加为子条目 - 方案B:生成新摘要替换旧条目 |
遗忘模块 (Forgetting / Pruning)
| 维度 | 策略 | 实现细节 |
|---|---|---|
| 遗忘理由 | 系统优化 | • 控制存储成本 • 降低检索噪声 • 避免过拟合历史错误信息 |
| 多因子评分 | 综合衰减模型 | score = α×importance + β×access_freq - γ×age • importance:初始重要度 • access_freq:访问频次(常用提升) • age:时间衰减(天) |
| 淘汰策略 | 分层淘汰 | • 热缓存层:LRU(最近最少使用)或LFU(最少频次) • 冷存储层:阈值删除或归档迁移 |
| 冲突检测 | 一致性维护 | 发现信息矛盾时降权或标记删除 |
结语
对于AI Agent而言,没有记忆,就没有真正的智能。记忆工程(Memory Engineering)将成为LLM应用开发的必备技能。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)