抛开复杂的理论用大白话教你从头开始搭建一个全连接神经网络
1. 前情提要
虽然这是一个面向新手的教程,但是仍然需要读者学习并熟练以下的基本操作:
1、Numpy 、 Pandas 数据的读取
2、Python基本语法
3、Python类的操作
4、Python机器学习
2. 环境配置及检查
首先对于我们的第一个神经网络 ,我个人是推荐从全连接神经网络开始的,因为相较于其它的神经网络,比如:卷积神经网络和其它神经网络的变体,全连接神经网络基本都是在对数字数据进行操作,数据集一般可以直接使用机器学习的数据集,在本篇文章中我们就将使用经典的波士顿房价数据集(需要各位自行下载)。
在正式开始写代码之前,需要各位先下载一此依赖,也就是我们在本篇文章当中需要用到的一些库,在下载之前需要各位先查看一下自己的电脑配置,因为对于深度学习来说,配置还是非常重要的,在其中最关键的是有无独显。那怎么看呢?
1、Windows用户最简单的就是在桌面按 win + R 键输入cmd,然后在出现的窗口中输入以下代码:
nvidia-smi
然后回车,如果展示出了类似于我在Linux上的界面 ,那你的电脑就是有独立显卡并且可以正常使用CUDA的。
如果像这样就是没有独立显卡的
2、Linux用户也是同理,需要调出终端并在终端输入:
nvidia-smi
如果出现了如下图所示的内容 ,也代表你可以使用独立显卡的CUDA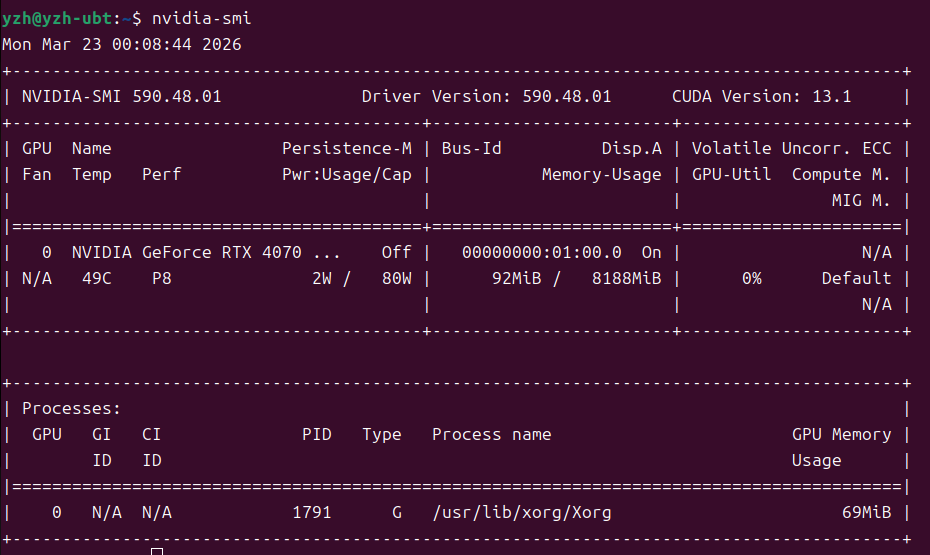
记住自己的CUDA Version 版本,我的是13.1,下面要用!!!!!!!!!!!!!!!!
OK ,如果你已经完成了配置检查 ,其实你已经领先于其它人一大半了,然后需要大家使用一点点魔法(steam++也可以)来下载我们需要的信赖
请大家访问Pytorch的官网,可以直接点击我下方的“Pytorch官方”可以直接跳转:
Pytorch官方
然后点击“Get Started”进入到下面的界面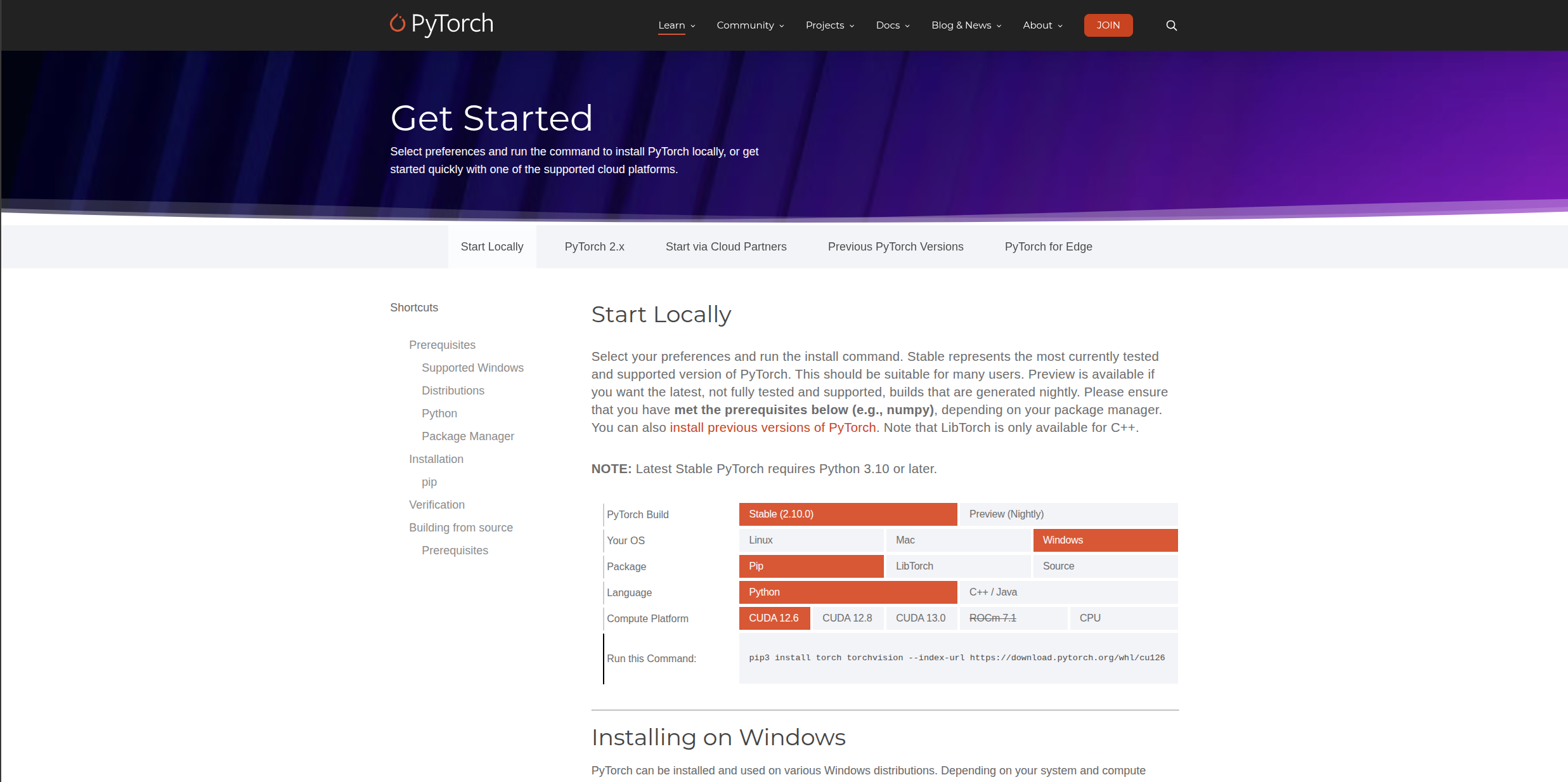
大家是否还记得上一步让大家记住自己的CUDA版本呢?
在这里我们就需要选择和自己对应的CUDA版本,比如我的CUAD版本是13.1,那么在这一页原则上需要选和自己CUDA版本一样的Pytorch的,但是这个页面上并没有我的13.1,那么怎么办?
不需要考虑这么多,直接选相近的即可,比如我就选13.0也是可以的,但是在这里还是要说一声,不太建议大家选太近的版本,比如实际上我还是会选择12.8的版本,因为它更加稳定。
没有独显的同学大家就不用考虑这么多,也不要强行安装CUDA版本的Pytorch,就选择CPU版本的就行,以下是CPU版本和GPU版本的两条安装命令:
# 这是CUDA的
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu128
# 这是CPU的
pip3 install torch torchvision
然后打开我们的Pycharm或者vscode,并在自己的环境下的终端将刚才的命令输入进去,如图:
然后进行耐心的等待,国内用户使用魔法的话大约需要5分钟,如果用的是Steam++需要近15分钟以上,如果以上都没有的话,建议使用国内镜像源,可以自行百度一下,相信各位未来的图灵不会被这点困难打败的!
如果没有报错,那么大家也就基本完成了库的安装,让我们新建一个Python文件来验证一下吧!
将下面的代码直接复制到文件中,并运行:
import torch
# 检查PyTorch版本
print("PyTorch版本:", torch.__version__)
# 检查是否支持当前系统(CPU/GPU)
print("是否支持CPU:", torch.backends.mkl.is_available()) # CPU加速库
if torch.cuda.is_available():
print("GPU可用,CUDA版本:", torch.version.cuda)
else:
print("GPU不可用(或未安装带CUDA的PyTorch)")
如果是安装GPU版本的同学,应该会有和我差不多一样的输出
如果是CPU版本的同学,其输出应该如下
Pytorch版本:2.10.0+CPU
是否运行CPU:True
GPU不可用(或未安装带CUDA的PyTorch)
3. 正式编写代码
3.1 加载数据集
首先我们得加载一下数据集,标准的波士顿房价数据集结构相信大家学过机器学习的话都不会陌生,我在这里就不赘述了,让我们直接上代码!
# 代码段一
import pandas as pd
df = pd.read_csv("boston_host_prices.csv")
df = df.apply(pd.to_numeric, errors='coerce') # 强制所有列转为数字,转不了的变NaN
df = df.fillna(df.mean()) # 再填充缺失值
X = df.iloc [:, : -1].values.astype(np.float32)
y = df.iloc [:, -1].values.astype(np.float32)
# 为什么要加载为float32精度?留个悬念
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
上述代码和我们在机器学习中加载这个数据集基本是一样的,接下来才是重点!
# 代码段二
import torch
X_train_t = torch.tensor(X_train, dtype=torch.float32)
y_train_t = torch.tensor(y_train, dtype=torch.float32).unsqueeze(1)
X_test_t = torch.tensor(X_test, dtype=torch.float32)
y_test_t = torch.tensor(y_test, dtype=torch.float32).unsqueeze(1)
让我们来逐步拆解刚刚的代码
先解决一下我们上面留的悬念,为什么要使用float32精度?
因为在我们这一次神经网格中,我们需要使用到线性层,而在Pytorch当中,线性层权重默认是float32的,如果我们不增加astype转为float32精度的话,那数据默认使用的是float64精度的,这会导致两者类型不匹配而报错!所以需要强制转换为float32精度的。
细心的同学也注意到了,在我们的第二段代码中,我们使用了dtype这个关键字参数 ,它和代码段一中np.float32其实是相同的作用,但是,出于防御性编程的习惯,在这里我们仍然需要指定加载类型!万一前面忘了转或者数据来源变了,这里兜底确保张量类型正确。
然后让我们来看看为什么需要使用torch.tensor这个方法:
在Pytorch当中,我们其实一直是对张量:Tensor进行运算、处理等操作,那么什么是张量?
3.2 什么是张量:Tensor?
相信大家在小学二年级就知道了,数据其实也是有维度的,举个栗子!
3.2.1 标量
0维:也就是一个单纯的数字,比如3.14 、520 、1314
这些都是0维的,我们平常在计算一些简单的数学题的时候,用的就是这些0维的数据。
3.2.2 向量
1维:也就是我们在python当中使用的一维列表
ls = [1 , 2.5 , 3.0 , 4]
就像这样
3.2.3 矩阵
2维:也就是我们读取excel 、csv那样的数据出来的结果,比如
# 我们现在从某个csv里面读一些数据
df = pd.read_csv("xxx.csv")
print(df.head())
打印出来的就是2维的数据,更形像点
ls = [[1,2],[3,4]]
诶!聪明的同学已经发现了:
1维不就是多个0维组成的吗?
2维不就是多个1维组成的吗?
那么3维是不是也是由多个2维组成的呢?
3.2.4 张量
首先,明确的是,张量不局限于3维的数据,对于3维及以上的数据,我们都称之为张量。
图片大家应该不陌生了,图片是一个标准的3维张量,我们都知道一个RGB的图片,有3个通道,每个通道都由长、宽构成
那么图片的 shape 就是 (3, H, W),3 个通道,每个通道是一个 H×W 的二维矩阵,每个元素是该位置的像素值(0~255)。
如果是一批图片,再加一个 batch 维度,变成 (N, 3, H, W),这就是一个 4 维张量,N 是图片数量。
3.2.5 小结
经过上述的解释,相信图灵们已经大概知道了张量是个什么东西,总的来说呢,PyTorch 的张量和 numpy 的数组非常类似,区别是张量可以放到 GPU 上加速计算,并且支持自动求导(反向传播的基础)。
但是在这里,我不会用公式或者一大堆理论去介绍什么是自动求导,什么是反向传播,尽量使用最浅显的语言给大家说清楚。
让我们继续。
3.3 打包数据
先上代码
from torch.utils.data import DataLoader, TensorDataset
loader = DataLoader(TensorDataset(X_train_t, y_train_t),
batch_size=32, shuffle=True)
让我们来一步一步来观察并理解这个代码
3.3.1 什么是DataLoader?
就像字面意思,数据的加载,我们在给神经网络的数据,并不能一条一条的给,也不会全部一次性给它,而是需要一批一批的去给网络学习。
如果我们现在有1000行数据,同时我们将batch设置为32,那么我们每个数据批次就是32条数据,那么打包好所有的数据需要多少个batch呢?
1000/32 = 31余7
那么到底是31个batch还是32个batch呢?
当然是32个啦,在深度学习中,数据可是很珍贵的呢,不可以随意删除数据。
所以在每一次学习中,模型都需要学习32个batch的数据,也就是在一个epoch内,要把数据集完整的学习完。
3.3.2 形象举栗
你现在是一个一年级的学习,老师发了1本练习册50页,说:同学们,这就是我们最终考试的内容。
你作为未来之星、图灵天选者,你决定在考试之前把这本练习册里面的题目都学会,为了确保自己都能学会,你决定多做几次这个练习册。你开始规划自己的时间,你决定起床后利用一上午的时间做25页!(这很疯狂了)下午再做25页!这样一天就能做完一本!
(真是太努力了)
在上述的例子当中,你一天有2段时间在学习,每次都学25页,那么你的batch的大小就是25 , 你一天学了2个batch。
在考前有100天的时间给你准备 ,你决定每天都保持这样的学习计划,那么总的学习轮数就是100,也就是Epochs为100。
3.4 构建网络
终于到了最令大家头疼的网络部分了,还是先上代码
import torch.nn as nn
class BostonNet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(13, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1),
)
def forward(self, x):
return self.net(x)
# 另一个版本,建议使用下面这个
class BostonNet(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(13, 64) # 第一层:13 → 64
self.fc2 = nn.Linear(64, 32) # 第二层:64 → 32
self.fc3 = nn.Linear(32, 1) # 输出层:32 → 1
def forward(self, x):
x = self.fc1(x) # 第一层线性变换
x = torch.relu(x) # 激活函数
x = self.fc2(x) # 第二层线性变换
x = torch.relu(x) # 激活函数
x = self.fc3(x) # 输出层
return x
嗯,看不懂,怎么这么复杂?别急,让我们来一步一步拆开看!
基本语法就不给大家介绍了,让我们先看看为什么这个类需要继承nn.Module呢?
这不重要! 对于我们新手来说,我们在构建任何网络都要继承它!在学习的初期我们一定要先了解基本的架构,而不是死啃理论!
我现在即使告诉你为什么继承它,对各位以后写网络架构来说也意义不大(因为我写到现在我也没考虑过为什么要继承这玩意?)
算了,还是写上吧,不然要被说不专业了
nn.Module 是 PyTorch 所有神经网络的基类,它内部实现了很多功能,比如自动追踪模型的所有参数、model.train() / model.eval() 模式切换、model.parameters() 获取参数用于优化器等。继承它就免费获得了这些能力,不用自己实现。
为什么要 super().init():
继承之后,父类 nn.Module 自身也有初始化逻辑(比如初始化内部用来存参数的字典),super().init() 就是显式调用父类的 init,确保父类先把自己初始化好。如果不写,父类的初始化没有执行,后续调用 self.net、model.parameters() 等都会报错。
简单说:继承是为了获得父类的能力,super().init() 是为了确保父类正常启动。
3.4.1 线性层
让我们来分析分析这个代码
self.fc1 = nn.Linear(13 , 64)
nn.Linear是Pytorch中的线性层,所有的线性模型 ,也就是机器学习当中的回归任务都需要用到它。
第一个参数是13,也就是我们的模型输入的大小 ,大家可以看看数据集,我们的X是不是13列
第一层的输入必须是数据集的维度大小!
至于第一层的输出其实就是我们自己决定的了,可以是代码中的64,也可以是32 、16 甚至是8都可以 ,但是一般不会让第一层的输出小于我们的输入的。
我们设计网络的习惯是先放大->缩小,如图: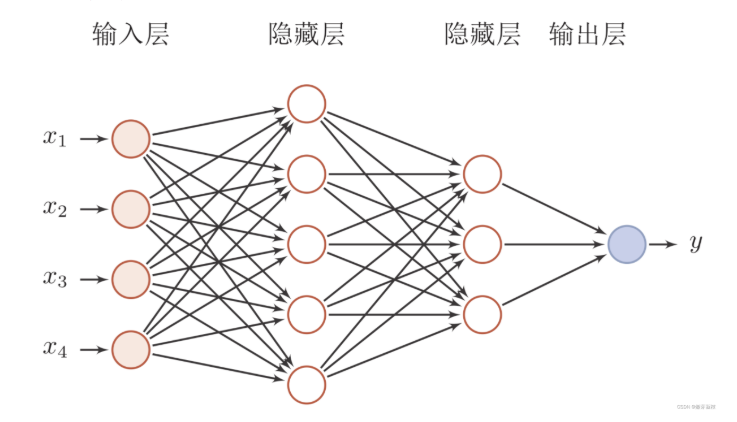
引用:https://blog.csdn.net/qq_14835271/article/details/124784738
如果我们的层数多一点的话,就会像下图这样,是一个明显的纺锤形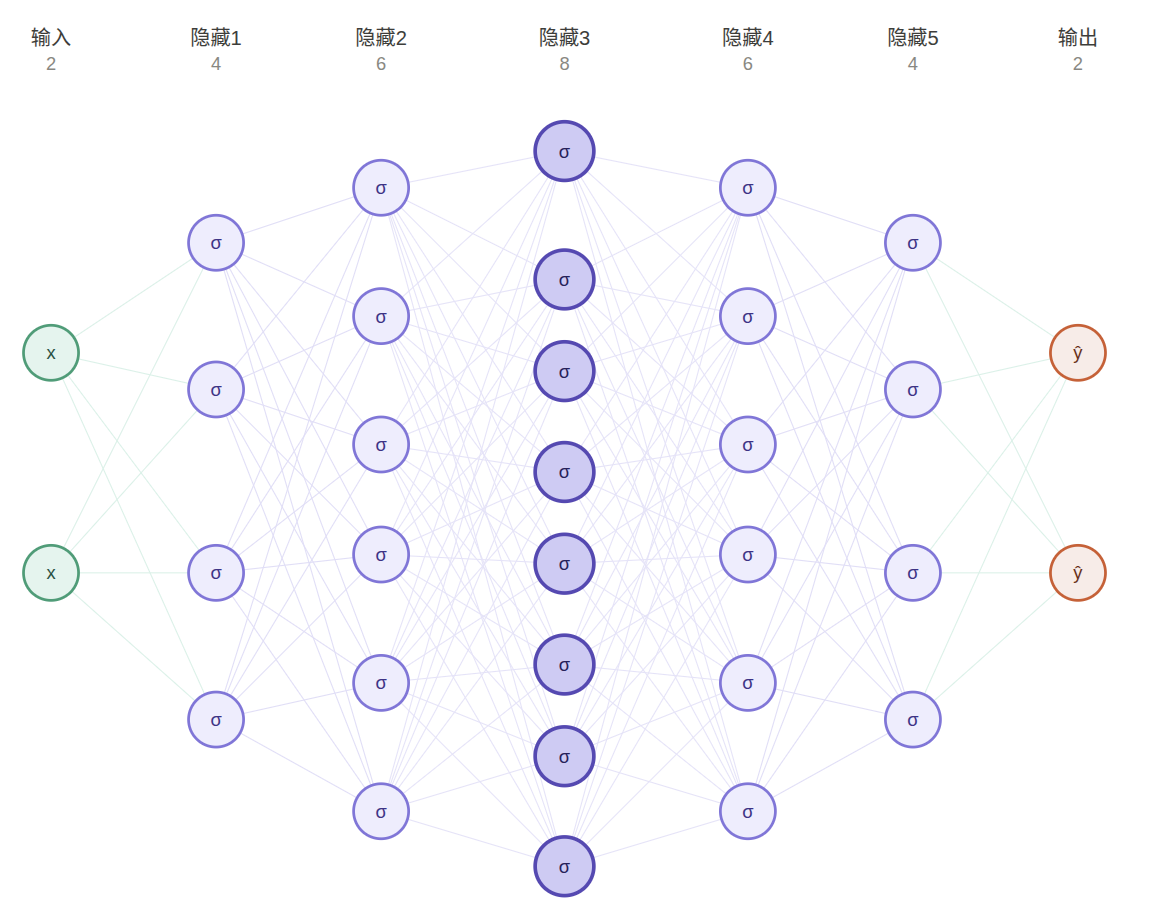
(AI真是太好用了!)
让我们观察一下这个图片,我们发现上一层的输出就是下一层的输入,所以在设计网络时我们要保存上一层输出一定要是下一层的输入,就像代码中一样
self.fc1 = nn.Linear(13, 64) # 第一层:13 → 64
self.fc2 = nn.Linear(64, 32) # 第二层:64 → 32
self.fc3 = nn.Linear(32, 1) # 输出层:32 → 1
3.4.2 激活函数与前向传播
3.4.2.1 什么是前向传播呢?
在代码中它的表示是这样的
def forward(self, x):
x = self.fc1(x) # 第一层线性变换
x = torch.relu(x) # 激活函数
x = self.fc2(x) # 第二层线性变换
x = torch.relu(x) # 激活函数
x = self.fc3(x) # 输出层
return x
在前向传播当中,其实是定义了我们的数据流向。
让我们先忽略relu这个东西
如代码所示 ,我们的X 先是经过了第一个线性层,然后是第二个线性层,然后是第三个线性层,然后返回了X
所以在forward中,我们决定了数据的流向,也就是数据要先到哪一层再到哪一层,就是在forward中决定的!
有聪明的同学就要问了,我能不能先过fc2再去fc1呢?
当然不行因为每一层的输入与输出我们在init中都定义好了,如果你进入的层不对,那么数据就不会再继续向前了,而是直接中断掉,在代码中的表现,当然就是直接报错了!
3.4.2.2 什么是激活函数
没有激活函数的神经网络,不管叠多少层,本质上都只是一个线性函数。
举个例子:你把两个线性函数叠在一起:
y = 2x + 1
z = 3y + 2 = 3(2x+1) + 2 = 6x + 5
叠了两层,结果还是一个线性函数 6x + 5,叠100层也一样,白叠了。
现实中的问题几乎都是非线性的
比如房价不会随面积无限线性增长,超过某个范围就会趋于平稳或者跳跃
激活函数就是在每层之后插入一个"掰弯"的操作,让网络有能力拟合这种弯曲的规律。
ReLU 是最常用的激活函数,规则极其简单:
f(x) = max(0, x)
就是说:输入是负数就输出0,输入是正数就原样输出。就像一个开关,信号太弱就直接截断,信号够强才让它通过。
用生活类比:激活函数就像公司里的筛选机制,每层员工处理完信息之后,不是所有信息都往下传,只有"重要的"才继续传递,不重要的直接丢弃。这样网络才能学会"什么情况下哪些特征重要"。
3.5 训练
先上代码
model = BostonNet() # 实例化我们的网络
criterion = nn.MSELoss() # 确定损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 确定优化器
# ─── 3. 训练 ───────────────────────────────────────────────────
losses = [] # 每轮的损失
for epoch in range(200): # 训练的主循环
model.train() # 将模型设置为训练模式
total = 0 # 本轮的总损失,用于计算本轮的平均损失
for xb, yb in loader: # 从数据集里面加载X 和 Y
optimizer.zero_grad() # 清空梯度
pred = model(xb) # 将X 送入模型,让模型猜测对应的结果
loss = criterion(pred, yb) # 计算损失 将正确结果与模型猜测结果进行对比
loss.backward() # 对损失进行反向传播
optimizer.step() # 根据梯度更新参数
total += loss.item() # 计算总损失
losses.append(total / len(loader)) # 计算平均损失
if (epoch + 1) % 50 == 0: # 打印结果
print(f"Epoch {epoch+1:3d} | Loss: {losses[-1]:.4f}")
在正式开始模型训练前需要给大家再补充两点
如果将训练比作做题,那我们每次做完题都需要找 “老师” 核对答案 ,让老师把我们的错误给标注出来,然后我们订正错题,这样才能进步。
训练也是同理,我们需要有个 “老师” 来帮我们将错误找出来,然后我们来订正。
那么这个老师就是损失函数!
让我们来更细致的划分一下
损失函数 = 试卷上的分数,告诉你错了多少,但不告诉你怎么改
反向传播 = 老师批改试卷,分析每道题错在哪、每个参数该怎么调
优化器(Adam) = 你根据老师的批注订正错题,真正修改参数
3.5.1 什么是损失函数
代码中的表示
criterion = nn.MSELoss() # 确定损失函数
loss = criterion(pred, yb) # 计算损失 将正确结果与模型猜测结果进行对比
就像我们在上述例子说的那样
损失函数是你在做练习题时错了多少 ,就像你做完对答案一样
可恶的出题人只给了你答案,并没有给你具体的解题步骤,一看大题,全是略。
对于不同的任务我们要使用不同的损失函数
按任务类型分,常见的损失函数如下:
回归任务(预测连续值,比如房价)
MSELoss 均方误差,最常用,对大误差惩罚更重
L1Loss 平均绝对误差,对异常值更鲁棒
HuberLoss 结合了两者,小误差用 L1,大误差用 MSE,兼顾稳定性
二分类任务(预测是/否,比如垃圾邮件判断)
BCELoss 二元交叉熵,输出层需要先过 Sigmoid
BCEWithLogitsLoss 把 Sigmoid 和 BCE 合并在一起,数值更稳定,推荐用这个
多分类任务(预测多个类别,比如手写数字0-9)
CrossEntropyLoss 交叉熵,最常用,输出层不需要提前 Softmax,它内部会做
其他场景
KLDivLoss KL散度,用于概率分布之间的差异,常见于变分自编码器
CTCLoss 用于序列对齐任务,比如语音识别
TripletMarginLoss 用于度量学习,比如人脸识别中判断两张脸是否同一个人
我们这个波士顿房价项目是回归任务,所以用的是 MSELoss,是最自然的选择。对于其它的损失函数,如果大家用到了再学也不迟,我们就题论题。
3.5.2 什么是反向传播
代码中的表示
loss.backward()
接着上面的比喻,损失函数只是给了你一个分数,但 **“老师”(反向传播)**会拿着这个分数,从最后一层开始 ,一层一层的往追溯,分析每一个参数对这个错误的责任有多大。
那么这个责任就是 梯度!
梯度我们可是理解为: 这个参数如果稍微变大一点,损失会变大还是变小,变化有多剧烈
loss.backward()这一行代码做的事情就是把所有参数的梯度全部算出来,存在每个参数的grad属性里面,等着优化器来用
在我们初步学习的过程中,最容易忽略的一点就是
loss.backward() 只是计算梯度的,并不会去修改任何参数,真正修改参数的是下一行optimizer.step() 的事
3.5.3 什么是优化器
代码中的表示
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
optimizer.step()
优化器就是拿着反向传播算出来的梯度 ,真正去修改每一个参数的步骤
还是用订正的比喻:反向传播告诉你"第3题的第2步错了,方向反了",优化器就是你拿起笔,把那个错误的地方擦掉重写。
lr=0.001 是学习率,控制每次修改的幅度,可以理解为你订正时下笔的轻重
学习率太大,每次改动太猛,模型可能在最优解附近来回震荡收敛不了
学习率太小,改动太慢,训练要花很长时间
0.001 是一个经过大量实验验证的稳健默认值,新手直接用就好
Adam 是目前最常用的优化器,它会自动给不同的参数分配不同的学习率,比最基础的 SGD(随机梯度下降)聪明很多,新手无脑选 Adam 就对了。
3.6 评估
model.eval() # 将模型设置为评估模型
with torch.no_grad(): # 在评估时不需要我们计算梯度,所以要使用no_grad()
y_pred = model(X_test_t).numpy().flatten() # 对测试集进行推理,并将结果保存到y_pred里面
y_true = y_test_t.numpy().flatten()
mae = np.mean(np.abs(y_pred - y_true)) # 然后计算mae
rmse = np.sqrt(np.mean((y_pred - y_true) ** 2)) # 及rmse
print(f"MAE: {mae:.2f} 千美元")
print(f"RMSE: {rmse:.2f} 千美元")
评估也就是考试了,完全闭卷,看不了答案,只能通过刚刚训练的知识来做题
在做完题之后将给老师进行批改,给出你的分数: 数MAE 与 RMSE
3.7 可视化
这里不再多做阐述了,直接上代码
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
ax1.plot(losses)
ax1.set_title('训练损失曲线')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('MSE Loss')
ax2.scatter(y_true, y_pred, alpha=0.6)
ax2.plot([0, 50], [0, 50], 'r--', label='完美预测线')
ax2.set_xlabel('真实房价(千美元)')
ax2.set_ylabel('预测房价(千美元)')
ax2.set_title('真实 vs 预测')
ax2.legend()
plt.tight_layout()
plt.show()
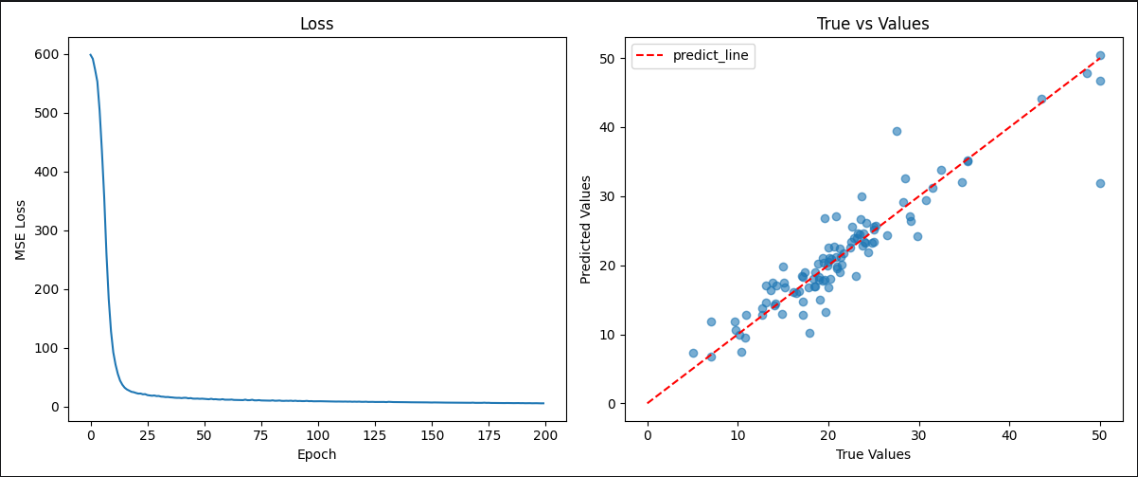
可以看到 ,我们的损失还是不错的,拟合也非常好!
3.8 完整代码
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import pandas as pd
# ─── 1. 数据准备 ───────────────────────────────────────────────
df = pd.read_csv("/home/yzh/Fire/all/boston_house_prices.csv")
df = df.apply(pd.to_numeric, errors='coerce') # 强制所有列转为数字,转不了的变NaN
df = df.fillna(df.mean()) # 再填充缺失值
X = df.iloc[:, :-1].values.astype(np.float32)
y = df.iloc[:, -1].values.astype(np.float32)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
X_train_t = torch.tensor(X_train, dtype=torch.float32)
y_train_t = torch.tensor(y_train, dtype=torch.float32).unsqueeze(1)
X_test_t = torch.tensor(X_test, dtype=torch.float32)
y_test_t = torch.tensor(y_test, dtype=torch.float32).unsqueeze(1)
loader = DataLoader(TensorDataset(X_train_t, y_train_t),
batch_size=32, shuffle=True)
# ─── 2. 定义模型 ───────────────────────────────────────────────
class BostonNet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(13, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1),
)
def forward(self, x):
return self.net(x)
model = BostonNet()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# ─── 3. 训练 ───────────────────────────────────────────────────
losses = []
for epoch in range(200):
model.train()
total = 0
for xb, yb in loader:
optimizer.zero_grad()
pred = model(xb)
loss = criterion(pred, yb)
loss.backward()
optimizer.step()
total += loss.item()
losses.append(total / len(loader))
if (epoch + 1) % 50 == 0:
print(f"Epoch {epoch+1:3d} | Loss: {losses[-1]:.4f}")
# ─── 4. 评估 ───────────────────────────────────────────────────
model.eval() # 将模型设置为评估模型
with torch.no_grad(): # 在评估时不需要我们计算梯度,所以要使用no_grad()
y_pred = model(X_test_t).numpy().flatten() # 对测试集进行推理,并将结果保存到y_pred里面
y_true = y_test_t.numpy().flatten()
mae = np.mean(np.abs(y_pred - y_true)) # 然后计算mae
rmse = np.sqrt(np.mean((y_pred - y_true) ** 2)) # 及rmse
print(f"MAE: {mae:.2f} 千美元")
print(f"RMSE: {rmse:.2f} 千美元")
# ─── 5. 可视化 ─────────────────────────────────────────────────
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
ax1.plot(losses)
ax1.set_title('Loss')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('MSE Loss')
ax2.scatter(y_true, y_pred, alpha=0.6)
ax2.plot([0, 50], [0, 50], 'r--', label='predict_line')
ax2.set_xlabel('True Values')
ax2.set_ylabel('Predicted Values')
ax2.set_title('True vs Values')
ax2.legend()
plt.tight_layout()
plt.show()
4. 结论
恭喜你!如果你跟着这篇文章把代码跑通了,那你已经从零搭建了一个真正意义上能跑的神经网络,而不是背了一堆概念却不知道怎么用。
接下来你可以试着"动手破坏"一下这个网络:
把隐藏层从2层改成4层,看看效果会不会更好
把学习率从 0.001 改成 0.01 或者 0.0001,观察损失曲线有什么变化
把 batch_size 从32改成64或者16,感受一下训练速度的差异
这些小实验比看十篇理论文章都有用,因为你会亲眼看到参数变化对结果的影响。
等你玩明白了全连接神经网络,下一站推荐去学卷积神经网络(CNN),它是专门为图像设计的,原理和我们这篇文章是一脉相承的,只是多了几个新概念。
最后,送给大家一句话:
神经网络不是玄学,跑通一个,剩下的都是举一反三。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)