赵行老师团队最新!Fast-WAM: 关于WAM核心能力来源的思考
1. World Action Model的近况
其实World Action Model (WAM) 并不是一个很新的概念。例如用video model来做未来规划,然后再接一个IDM的思路从23年开始就有人在做,但这些尝试都很难被称为end-to-end model,因为它们大多都采用分两阶段的结构:先训一个完全基于video gen的视频模型,然后再接一个比较轻的IDM。但众所周知,多阶段拼接的做法会引入累积误差,一般不会是大家想要的最优解,我们总是想要一个end-to-end的模型。基于这个共同的想法,从去年年底到今年年初涌现出了一大批非常优秀的将world model和action联合建模并训练的工作,包括但不限于Motus [3], Cosmos Policy [6], Lingbot-VA [1], DreamZero [2]等,在仿真benchmark和真机实验上展现了非常强大的性能,也是第一次让社区大范围意识到,WAM可能拥有比VLA更强的潜力。
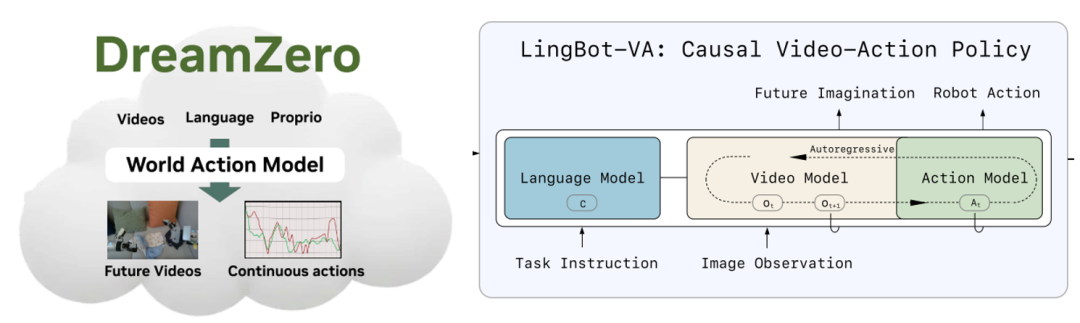
这些工作虽然细节各有不同,但核心做法都是一致的:训练时把future video prediction和future action prediction联合建模;在推理时,对video和action的推理可causal,也可联合,但总之都会让action基于对于future video的想象来输出,来最大限度地利用video model对于future imagination的能力。我们把这些WAM总结为Imagine-then-Execute的范式。注意,这里我们忽略了外层是否套了自回归(AR)这层壳,因为本质上AR只是增加了context window,而没有改变每次action chunk决策的过程。
我们也正式把本篇工作收录到具身智能之心开源知识库内,更多内容欢迎学习~

2. 关于WAM核心能力来源的思考
仔细思考WAM的训练和推理过程我们会发现,future video prediction在训练和推理的时候有两个不同的作用:
-
在训练的时候,future video prediction(我们后续也称cotrain)给video model提供了非常dense的监督信号,而且是和未来action/未来环境演化高度相关的有价值信息监督,这些监督会帮助video model(即WAM的backbone)学到更好的representation。
-
在推理的时候,future video prediction给action expert提供了guidance,action expert则基本起一个类似latent IDM的效果。
我们上面说到近期的WAM都采用Imagine-then-Execute的方式推理,这传递出一种“(2)比(1)重要”的信号,或者至少是“没了(2),WAM就不行”。而熟悉VLA预训练的同学可能在这里会和我们一样有另一种猜想:有没有可能(1)才是目前WAM结构work的关键,而(2)是可以省略的?
这个猜想是怎么来的呢,其实可以回想一下 为什么work来思考这个问题: 比起 的一大进化点,在于引入了VLM backbone的cotrain,不仅仅是VQA data的cotrain,还有自回归discrete action token的cotrain。这种做法基本已经成为业界预训练VLA的共识。
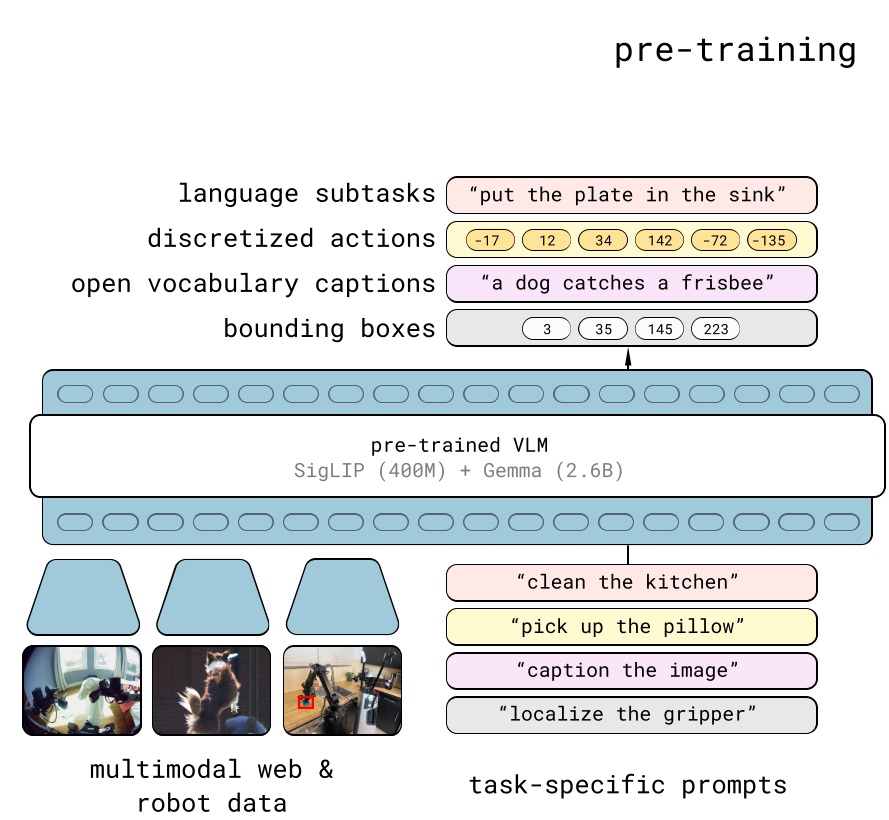
在这里,discrete action token的cotrain作为一种proxy task,它的作用在于给 的VLM backbone提供了更好的监督信号,帮助VLM backbone学到更好的representation,而不会被用来推理。推理的时候,我们并不会让 先自回归预测discrete future action token,再让action expert看着这些action token来做flow matching,这不仅慢,也没必要,action expert完全能通过一次forward,把这些信息从VLM backbone都decode出来。这个道理换到WAM也一样,只不过把discrete action token换成了future video token,而训练时的future video prediction就是那个新的proxy task。
3. 如何解耦?
提出了猜想,那么就需要公平的解耦这两个因素来验证。问题是,如果已有的WAM在训练时video和action是联合建模的,单纯在推理时拿掉肯定不公平。因此,我们提出了一个极简的Fast-WAM结构来方便验证各种component的有效性。本质上来说,我们这篇并不是一个做方法和结构的工作,而是一个提出猜想并验证的研究性工作。
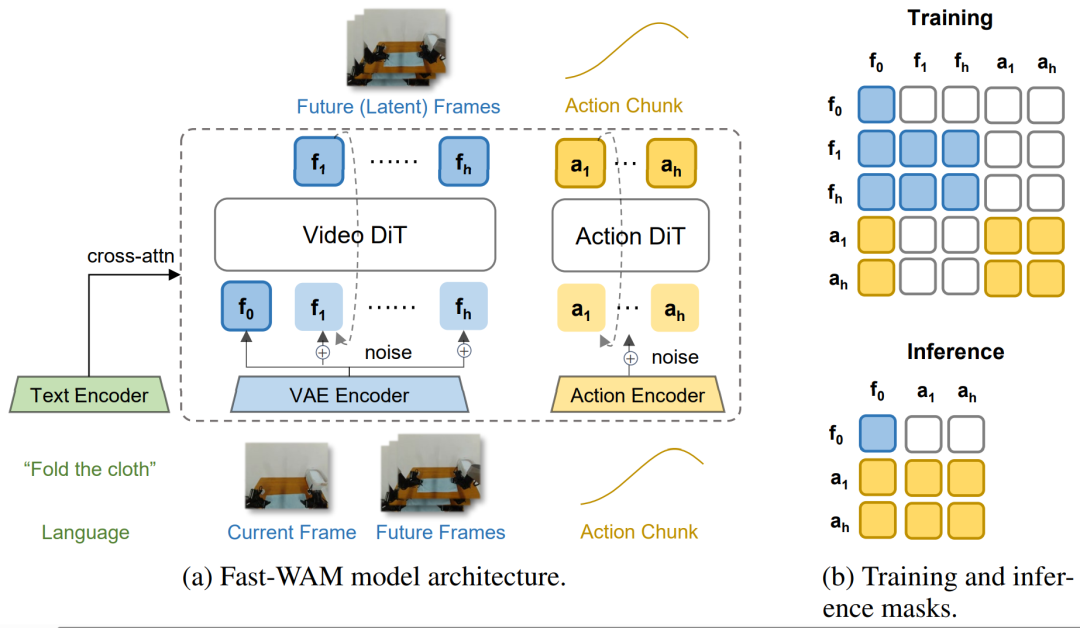
如图,Fast-WAM结构非常简单,就是一个video DiT和一个action DiT做MoT,训练时联合优化,但用attention mask保证action token不看future video token。为了方便比较,我们去掉了AR的外壳,并且统一了一切权重或超参带来的影响,只关注核心结构的解耦。基于这个简单的结构,我们可以用mask来实现多种变体,来模仿近期各种WAM的结构。
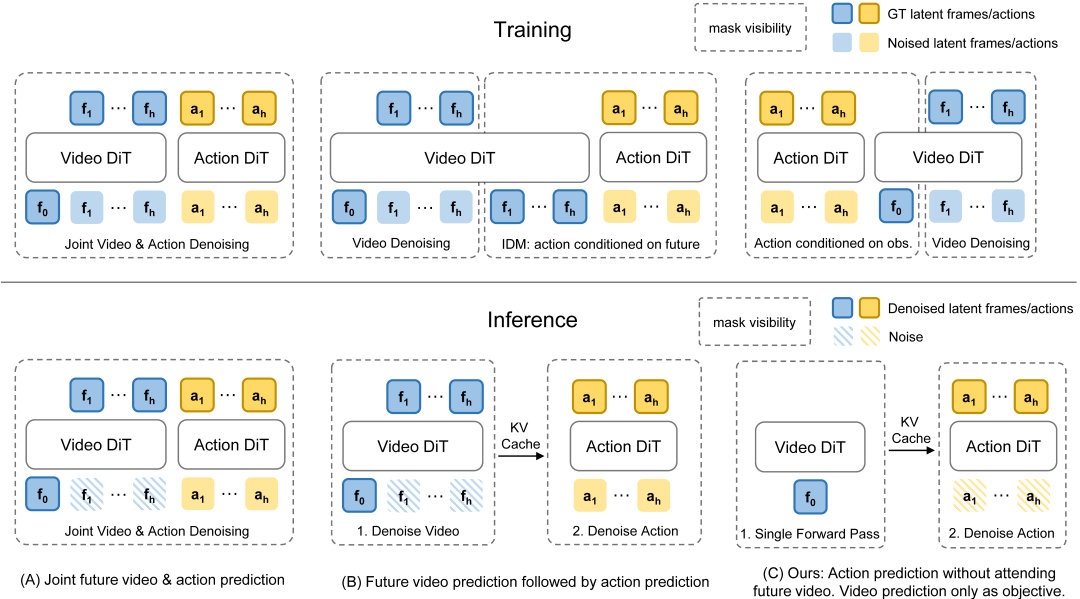
如图是三种核心的变体:(A)变体把video和action joint denoise,类似于Motus和DreamZero的操作,我们命名为Fast-WAM-Joint。(B)变体把denoise过程变成causal,先video后action,则映射的是Lingbot-VA的结构,我们命名为Fast-WAM-IDM。(C)变体则是训练时保留video prediction训练,推理时跳过,来验证前文提出的因素(2)是否有作用,即我们提出的Fast-WAM。最后,把(C)变体中的video prediction loss设成0,屏蔽了监督信号,来验证我们前文提出的因素(1)到底有多大作用,我们命名为Fast-WAM-no-cotrain。
Simulation上的实验结果一目了然。
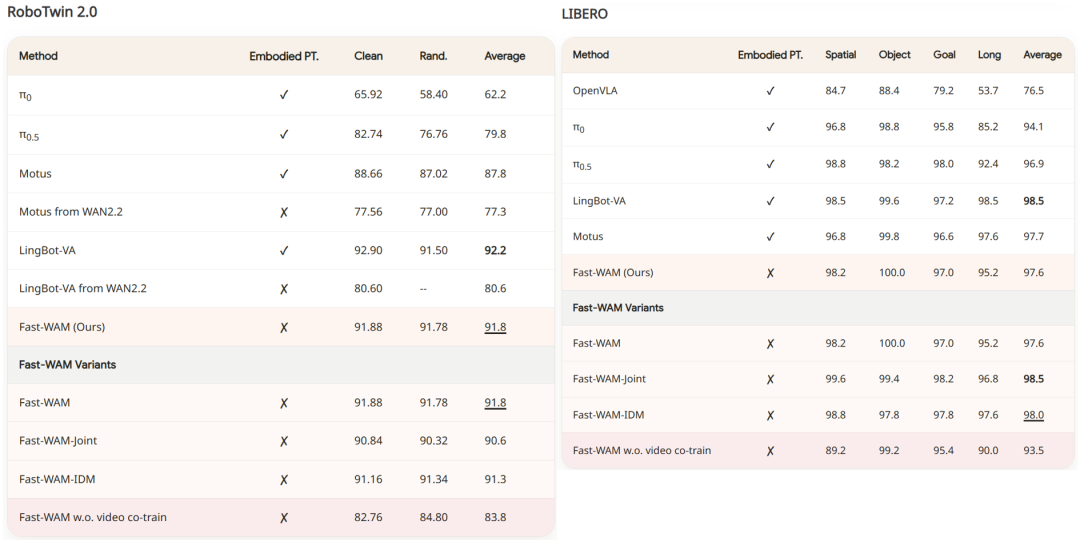
benchmark
可以看到我们的最简化实现的Fast-WAM结构已经足够强,在不用具身数据预训练的情况下已经持平或超过近期的很多预训练WAM,更远远超过它们的非预训练版本。不过,这里和其他WAM或VLA baseline比只是顺带,相比之下,我们专注于讨论Fast-WAM variants之间比较得出的信息。与-Joint和-IDM相比,我们可以看到Fast-WAM跳过了test-time future video generation这步,却几乎没有损失性能,和这两个看future generation的变体打了个五五开。而去掉训练时video cotrain之后,模型能力发生了骤降。这说明我们的猜想很可能是正确的:比起test-time imagination,训练时的cotrain监督才是WAM work的主要原因。除此以外还顺带发现,推理时video和action的交互方式没那么重要:causal和joint denoise基本没区别。
真机上的结果进一步证实了结论。
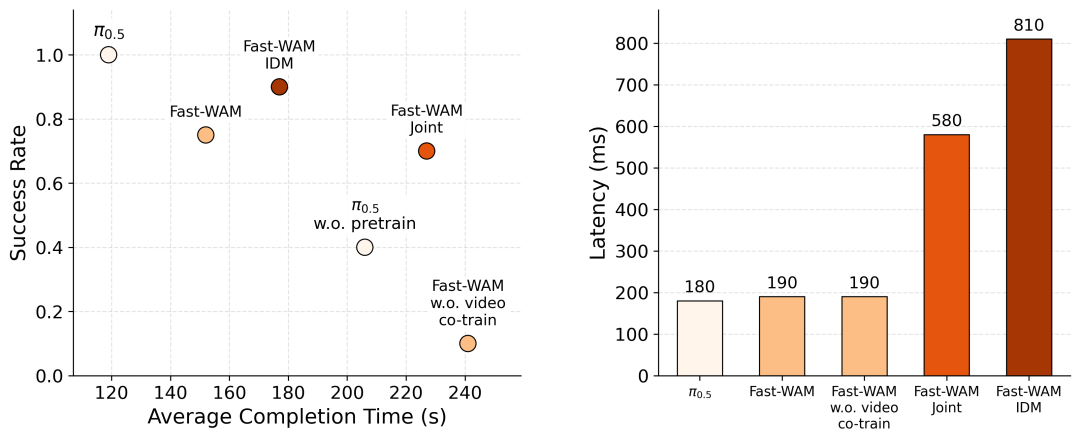
的真机表现依然稳定的强。为了和我们未经过预训练的Fast-WAM系列公平对比,我们还比较了不使用预训练权重(从PaliGemma出发)的 。我们发现Fast-WAM与-Joint、-IDM两个变体的表现没有明显差距,而显著强于去掉video prediction objective的版本。进一步验证了我们的猜想。顺便可以看到,去掉test-time future video generation之后,Fast-WAM的latency也得到了显著改善,持平 。当然,加速只是一个side-effect,不是主要目的,我们的核心依然是收益解耦。
除了上述几个变体,我们还尝试了一下训练时让FAST-WAM的video prediction conditioned on future action,把video监督称forward dynamics model,实验下来发现policy质量略差于unconditional版本(即Fast-WAM)。我个人推测可能是future action condition版本强调模型学习forward dynamics知识,但失去了在video prediction中学习latent action的机会,而unconditional版本同时保留了两者。
4. FAQ
和VPP等模型的核心区别是什么
可能看到模型结构的时候就有人想问了,这个模型结构和Video Prediction Policy (VPP) [5]有什么区别?从推理时的表现来说确实很相似:都是video backbone一次forward,action expert用这个feature做action prediction。但二者无论是在训练方法上,还是在研究的问题上,都有很本质的不同:
-
VPP是两阶段训练,先把video backbone在想做的任务上单独训练一轮,再freeze住给action expert再训一轮。而我们的Fast-WAM是end-to-end联合训练,从训练效率和上限都更有优势。相信做过VLA训练的同学都能看出来区别:如果把后者类比成end-to-end训练的VLA,那前者就是拿frozen CLIP或DINO等encoder做DP的前VLA时代做法,上限会比较低,研究的显然也不是同一类范式。我们也试过类似的freeze backbone的做法,效果相比之下会比较烂。
-
VPP的核心研究问题是:video prediction model这种生成式模型学到的representation,会不会比encoder模型更好,更适合robotics?而我们这篇文章的核心研究问题是:解耦训练时的video prediction objective和推理时的future imagination,并证明了前者可能比我们想象的更重要,而非后者。 显然研究的不是一个问题,实验证据的侧重也不同。
可能还有同学会觉得这篇和Unified Video Action Model (UVA) [4]有点像。没错,UVA提出了训练时使用video prediction作为监督,而推理时跳过future generation的思路来加速推理。但它和我们这篇还是有两个重要区别:
-
UVA的核心目标是做一个unified video-action model,提出一个新的结构,而我们的贡献依然是回答一个更具体的机制问题:WAM 的收益主要来自 training-time video co-training,还是来自 test-time explicit future imagination,将二者解耦。这是最根本的不同。
-
UVA仅在DP量级的小模型上进行实验,与近期的WAM工作在范式上存在很大差别,量级上小几十倍,且没有使用pretrained model。而我们的模型对齐了近期WAM工作的scale,video backbone对齐了最常用的Wan2.2 5B,和近期的WAM工作形成公平的比较。
5. 总结和Future Work
Fast-WAM是我个人比较满意的一篇很回归科研的一篇工作,比起现在工业界常见的搬出来一个很大很全面很work的工程的做法,我们更专注于提出一个问题,并通过controlled variants来验证这个假设。并不是说前者不重要,而是后者在这个时代也是我们该重视的方向,在一把梭哈scale up前,应该先搞清楚一些关键component的作用。当然,小而美的验证也有其局限性,这篇的结论能否适用于更大规模的pretraining,在训练规模scale up后会不会有一些不同的结论,也是我们未来打算验证的一个方向。Stay tuned!
Arxiv: https://arxiv.org/pdf/2603.16666
Project page: https://yuantianyuan01.github.io/FastWAM/
Code: https://github.com/yuantianyuan01/FastWAM 计划月内开源,而且我们不仅会开源Fast-WAM版本,还会开源这几个variants,让大家比的透明,比的安心。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)