【由浅入深探究langchain】第七集-语义相似度评分详解
前言
在第五集中,我们说了RAG语义检索时,可以使用带分数的搜索(similarity_search_with_score):不仅给你结果,还告诉你“有多像”。那么在本集中,我们详细来看一下这个相似度评分是怎么回事。
编码
1.初始化,定义好嵌入模型
# 语义相似度评分详解
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
#嵌入模型
embeddings = OllamaEmbeddings(
model="qwen3-embedding:4b",
base_url="http://172.23.2.18:11434"
)2.定义评分方式
这里定义了三种方式,首先是默认方式,其次分别是:
cosine余弦相似度:
它是衡量两个向量之间夹角的余弦值。结果范围通常在 $[-1, 1]$ 之间。当文本的含义比长度更重要时(例如:长文章和短摘要如果讲的是一件事,它们的余弦相似度会很高)
l2欧氏距离:
它是数学中定义最直观的距离,即两点之间的直线距离。计算两个向量各维度差值的平方和再开方。对数值大小敏感的场景,比如图像识别、传感器数据分析。注意,如果向量没有经过归一化,长文本生成的向量可能会因为维度数值大而产生较大的欧氏距离。
ip内积(Inner Product):
内积结合了向量的夹角和向量的模长(长度),使用两个向量对应维度的坐标相乘并求和计算。如果某个向量模长很大,通常代表该权重很高(比如热门商品或活跃用户)。如果所有向量都提前做过归一化(模长为 1),那么 IP 的结果在数学上等同于 Cosine。许多大规模向量数据库为了性能,会先归一化再跑 IP。
score_measures = [
"default", #默认
"cosine", #用两个向量的夹角
"l2", #用两个向量的距离
"ip"#用两个向量的内积/点积
]3.创建向量库和四个collecttion
遍历上一步手动创建的数组,建了四个collection,命名是my_collection+评分方式的名字。collection_metadata是集合元数据,它是一个字典,用于向底层的向量引擎(Chroma 使用的是 HNSW 算法库)传递特殊的指令。{"hnsw:space": "..."}: 这个特定的键值对告诉数据库用哪种**度量空间(Space)**来计算相似度。如果不传这个参数(即代码里的 None),Chroma 会使用它的默认算法。
persist_dir = "./chroma_score_db"
vector_stores=[]
for score_measure in score_measures:
collection_metadata={"hnsw:space":score_measure}
if score_measure == "default":
collection_metadata=None
collection_name = f"my_collection_{score_measure}"
vector_stores.append(Chroma(
collection_name=collection_name,
embedding_function=embeddings,
persist_directory=persist_dir,
collection_metadata=collection_metadata
))4.定义方法,将文本向量化放入库中
def indexing(docs):
print("\n加入文档:")
for vector_store in vector_stores:
ids=vector_store.add_documents(docs)
print(f"\n集合:{vector_store._collection.name}")
print(ids)
5.定义方法,参数为查询的文本,去使用四种方式做语义搜索
def query_with_score(query):
for i in range(len(score_measures)):
results=vector_stores[i].similarity_search_with_score(query)
print(f"\n搜索:{query}")
for doc,score in results:
print(doc.page_content,end='')
print(f"\n{score_measures[i]}:{score}")以上整个代码的作用是:在同一个数据库文件夹下,创建了四个“规则不同”的房间。
-
房间 A 默认规则;
-
房间 B 按照“角度”找邻居;
-
房间 C 按照“直线距离”找邻居;
-
房间 D 按照“投影长度”找邻居。
测试和结果
首先定义两句文本,分别加入到不同的collection中。
这两句话都提到了“苹果”字样,但是意思是完全不同的。
docs=[
Document(page_content="苹果手机预计将在2026年9月发布iPhone 17系列,涵盖标准版、Pro版及Air版等多个型号。其中,iPhone 17将搭载A19芯片"),
Document(page_content="中国苹果的种植历史可追溯至新疆伊犁河谷的野苹果林,现代苹果栽培体系始于19世纪70年代西洋苹果引入山东。")
]
indexing(docs)运行结果:
可以看到这两句话分别被插入到了四个不同的collection中,各自都返回了id。
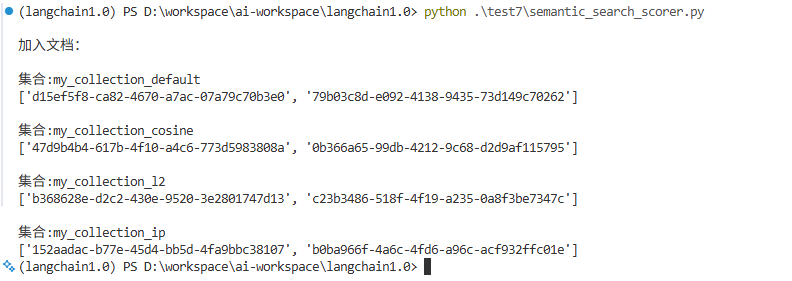
注释掉上一步插入的代码,因为我们已经插入成功了,不需要重复操作插入向量库的操作。执行搜索的方法,文本我使用“早上我打了个电话给我朋友”,这句话按照人为想法,应该是和测试语句中,“苹果手机”那句话语义比较接近,我们运行query_with_score方法看看结果。
# docs=[
# Document(page_content="苹果手机预计将在2026年9月发布iPhone 17系列,涵盖标准版、Pro版及Air版等多个型号。其中,iPhone 17将搭载A19芯片"),
# Document(page_content="中国苹果的种植历史可追溯至新疆伊犁河谷的野苹果林,现代苹果栽培体系始于19世纪70年代西洋苹果引入山东。")
# ]
# indexing(docs)
query_with_score("早上我打了个电话给我朋友")运行结果:

结果解析:
通过测试数据(“iPhone手机” vs “种苹果”),我们可以清晰地看到不同度量标准下的数值特征。
以下是针对这四种结果的详细总结:
搜索:早上我打了个电话给我朋友
苹果手机预计将在2026年9月发布iPhone 17系列,涵盖标准版、Pro版及Air版等多个型号。其中,iPhone 17将搭载A19芯片
default:1.3729732036590576
中国苹果的种植历史可追溯至新疆伊犁河谷的野苹果林,现代苹果栽培体系始于19世纪70年代西洋苹果引入山东。
default:1.436326503753662
这一段结果可以看到是使用的默认评分方式,“苹果手机”这一句语义更接近我们的测试文本,他的值是1.3729732036590576,也略低于第二句,我们可以理解为,在默认评分方式下面,分值越低,语义越接近。
搜索:早上我打了个电话给我朋友
苹果手机预计将在2026年9月发布iPhone 17系列,涵盖标准版、Pro版及Air版等多个型号。其中,iPhone 17将搭载A19芯片
cosine:0.6864866018295288
中国苹果的种植历史可追溯至新疆伊犁河谷的野苹果林,现代苹果栽培体系始于19世纪70年代西洋苹果引入山东。
cosine:0.7181635499000549
这一段结果可以看到是使用的cosine评分方式,Chroma 中返回的是 1-cosine_similarity,说明如果两个向量完全指向同一个方向,Score 是 0,如果完全正交(无关),Score 是 1。
我们结果在 0.7 左右,说明模型认为你的提问和这两篇文档在语义方向上有约 30% 的相关性(可能是因为“电话”和“手机/iPhone”在语义空间里稍微近那么一点点)。
搜索:早上我打了个电话给我朋友
苹果手机预计将在2026年9月发布iPhone 17系列,涵盖标准版、Pro版及Air版等多个型号。其中,iPhone 17将搭载A19芯片
l2:1.3729732036590576
中国苹果的种植历史可追溯至新疆伊犁河谷的野苹果林,现代苹果栽培体系始于19世纪70年代西洋苹果引入山东。
l2:1.436326503753662
首先可以发现,在 Chroma 中,Default 的结果与 L2 完全一致,L2 计算的是空间中两点之间的绝对距离。数值越小代表越近(越相似)。
搜索:早上我打了个电话给我朋友
苹果手机预计将在2026年9月发布iPhone 17系列,涵盖标准版、Pro版及Air版等多个型号。其中,iPhone 17将搭载A19芯片
ip:0.6864866018295288
中国苹果的种植历史可追溯至新疆伊犁河谷的野苹果林,现代苹果栽培体系始于19世纪70年代西洋苹果引入山东。
ip:0.7181634902954102
Inner Product / 内积中的数值表现:0.6864... (在这个例子中竟然和 Cosine 一样)。深层原因是当我们使用的嵌入模型(如 qwen3-embedding)输出的向量是经过归一化(Normalized)的处理时,内积(IP)在数学上就等于余弦相似度。
总结:虽然我们的问题是“打个电话”,看起来和两个文档都不太沾边,但模型捕捉到了“打电话” >>>>关联到 “手机/iPhone”(电子产品语义)。因此结果来看“iphone”的那一句,排位就是靠前。
我们可以多做几次测试,看看结果是否符合我们预期。
当问这个时,可以看到评分的差距跟刚刚比进一步拉大,因为说到了买新手机,明显语义和“苹果手机”更加接近了。
query_with_score("我在犹豫买个什么型号的新手机")
当我问这个问题时,可以看到优先的结果变了,而且评分差距和“苹果手机”那一句非常大,可以进一步帮我们理解向量搜索中的评分机制。
query_with_score("中国是不是农业历史非常悠久的国度?")

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 22
22 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)