3月23日(openclaw分水岭+企业案例实践,skill编写教程)
Openclaw分水岭
一边的人,每次跟 Agent 说话都像重新 onboarding:得再讲一遍背景、偏好和上下文。另一边的人,Agent 已经知道自己是谁、该怎么说话、用户讨厌什么,也记得上次积累下来的东西。这条分界线,叫 workspace 。
openclaw目录
~/.openclaw/
├── openclaw.json # 总控配置,整个系统的"宪法"
│
├── workspace/ # 默认情况下主 Agent 的工作区
│ ├── AGENTS.md # Agent 的行为规则与多Agent协调
│ ├── SOUL.md # Agent 的叙事性格设定
│ ├── USER.md # 用户画像与偏好
│ ├── IDENTITY.md # Agent 身份元数据(名字/emoji/头像)
│ ├── TOOLS.md # 工具权限声明与使用规范
│ ├── HEARTBEAT.md # 会话节奏/状态提示(默认模板之一)
│ ├── BOOTSTRAP.md # 首次启动引导(通常完成后应删除)
│ ├── BOOT.md # 可选:启动检查清单,只在 internal hooks 打开时才有用
│ ├── MEMORY.md # 可选:长期知识总表(也兼容 memory.md)
│ ├── memory/ # 按日期滚动的记忆笔记
│ │ └── 2026-03-21.md
│ ├── skills/ # 技能包目录
│ │ ├── skill-creator/
│ │ │ └── SKILL.md
│ │ ├── healthcheck/
│ │ │ └── SKILL.md
│ │ └── ...
│ └── canvas/ # 可选:画布/可视化上下文
│
└── agents/ # 各 Agent 的运行态目录
└── <agentId>/
├── agent/ # openclaw.json 里的 agentDir 默认就指到这里
│ ├── auth-profiles.json
│ └── models.json
├── sessions/ # 会话历史
│ └── *.jsonl
└── qmd/ # 仅在 qmd memory backend 下出现workspace 核心文件速查
|
文件 |
作用 |
类比 |
优先级 |
|
|
首次启动向导,通常初始化完就删 |
新员工报到手册 |
⭐(一次性) |
|
|
Agent 名字/emoji/头像元数据 |
工牌/名片 |
⭐⭐⭐ |
|
|
Agent 叙事性格设定 |
人物小传 |
⭐⭐⭐ |
|
|
工作规则与职责边界 |
岗位说明书 |
⭐⭐⭐ |
|
|
用户背景与偏好 |
上司简介 |
⭐⭐⭐ |
|
|
工具使用规范与受限声明 |
工具使用手册 |
⭐⭐ |
|
|
默认节奏/状态提示 |
值班提醒卡 |
⭐⭐ |
|
|
长期稳定知识总表 |
整理后的长期笔记 |
⭐⭐ |
|
|
按日期滚动的长期记忆 |
工作笔记本 |
⭐⭐ |
|
|
专项任务流程 |
操作手册 |
⭐⭐ |
常见命令速查
# 启动/重启 Gateway
openclaw gateway --port 18789
# 健康检查(检查配置是否正确)
openclaw doctor
# 安装 skill
clawhub install <skill-name>
# 查看 / 校验 skills
openclaw skills list
openclaw skills checkworkspace 路径约定
|
路径 |
说明 |
|
|
默认情况下主 Agent 用的 workspace |
|
|
切到非 |
|
|
专业 Agent 的 workspace(常见约定) |
|
|
跨 Agent 共享 skills |
|
|
字段的默认指向路径,存放运行状态 |
|
|
会话历史记录 |
|
|
使用 |
常见的坑
坑一:AGENTS.md 越写越长,效果越来越差
很多人信奉“越详细越好”,把 AGENTS.md 写成几千字的行为手册。但 LLM 的注意力也是预算,文件越长,重点越容易被冲淡。
解决方案 :学会"剪枝"。每隔一段时间重新审视 AGENTS.md,删掉那些"理论上有用但实际上没什么区别"的指令,把真正关键的行为约束放在前面。
坑二:SOUL.md 和 AGENTS.md 写的东西有大量重叠
这两个文件各管一摊。混在一起,文件会肿,Agent 读起来也容易分不清到底是在讲“我是谁”还是“我该怎么干活”。
解决方案 :一句话判断法——这句话描述的是 Agent 的 性格特质 (放 SOUL.md),还是 Agent 的 工作规则 (放 AGENTS.md)?性格特质是"内向谨慎的",工作规则是"在做出结论前要先列出证据"。
坑三:多 Agent 共用同一套 workspace
多个 Agent 共用同一个 workspace,是让多 Agent 失去意义最快的方式。如果研究员 Agent 和写作 Agent 连 SOUL.md 都一样,那分工基本就成了摆设。
解决方案 :每个 Agent 一套完整的 workspace,哪怕只有几行的差别。差别越明显,协作效果越好。
坑四:改了目录,忘了改 openclaw.json
创建了新的 workspace 目录,却忘了在 openclaw.json 里的 agents.list 里更新路径——结果 Agent 还在用老的 workspace,改了半天没效果。
解决方案 :每次新建或移动 workspace 目录后,第一件事是检查 openclaw.json 。可以养成习惯,每次做 workspace 修改后都运行一遍 openclaw doctor 检查配置是否一致。
坑五: SKILL.md 写成“逮谁都触发”
一些 skill 的 SKILL.md 把触发条件写得太宽,比如“只要用户有写作需求就触发”。这样几乎每次对话都会把这个 skill 带上,结果是上下文膨胀,响应反而更慢。
解决方案 :skill 的触发条件要足够具体,描述清楚特定的场景和关键词,而不是模糊地覆盖一大类任务。
坑六:memory/ 积累了大量无用记忆
Memory 机制的初衷是好的,但时间长了会积累大量过时的、低价值的记忆条目,占据上下文空间,偶尔还会产生"记忆污染"——Agent 用了一个两个月前就已经过时的信息来回答你。
解决方案 :定期清理 memory/ 和 MEMORY.md 。不管你用的是 builtin 还是 qmd ,最后都可以把它理解成“你在维护一组 Markdown 记忆文件”;两者主要差在背后的检索方式,不差在你能不能读、能不能改这些原始记忆。真正重要的,是养成“该记就记、过期就删”的习惯,别让 memory 一路堆成垃圾场。
OpenClaw企业落地配置
在AI跨境电商中主要面临的难题是:员工流失、知识断层、数据滞后、达人管理混乱。
而全员从微信迁移到飞书,飞书里接入 OpenClaw。所有工作对话,AI 在旁边同步,沉淀成知识,转成 Skills,下次直接调用。这个循环跑起来之后,组织里每一次对话都在给 AI 喂燃料,让它越来越懂这个行业、懂这家公司、懂每一个具体的业务场景。
沉淀群聊内容为知识库,再转成Skills
我想用 OpenClaw 搭建一套团队知识自动沉淀系统。
当前状况:
- 团队在飞书群里沟通日常业务
- 核心知识散落在聊天记录里,没有系统整理
- 员工离职后知识断层严重
我的诉求:
1. OpenClaw 接入飞书群,实时监听业务讨论
2. 自动识别有价值的业务经验、踩坑记录、操作规范
3. 整理后写入 AGENTS.md 对应章节(按业务模块分类)
4. 每周五自动输出一份「本周知识沉淀周报」到飞书群
请帮我设计:
1. SOUL.md 中关于知识沉淀的角色定义
2. AGENTS.md 的知识分类结构(覆盖我以下业务模块:[选品/运营/广告/供应链/达人管理])
3. HEARTBEAT.md 的知识巡检逻辑(每小时检查一次新消息,有价值内容才处理,没有则 HEARTBEAT_OK)
4. 每周五知识周报的 Cron 配置(isolated session + announce 到飞书群)让 AI 来调度企业现有的自动化工具
很多跨境公司已经有一套在跑的自动化流程:n8n 工作流、各种 RPA、定制脚本。这些东西干活很稳,但彼此之间是孤岛。A 跑完了要不要触发 B,全靠人来盯。
OpenClaw Gateway 原生支持 Webhook 接收。在 openclaw.json 的 hooks 里开启 webhook,设好 token,n8n 工作流跑完一个任务,结果通过 HTTP POST 推到 OpenClaw 的 /hooks/agent 端点。OpenClaw 收到后启动一个 isolated session 的 agent turn,判断下一步是继续推进还是需要人工介入,异常的时候生成处理建议并推送到飞书群。
在 openclaw.json 里开启 Webhook:
{
"hooks":{
"enabled":true,
"token":"你的安全密钥",
"path":"/hooks",
"defaultSessionKey":"hook:n8n-dispatch",
"allowRequestSessionKey":true,
"allowedSessionKeyPrefixes":["hook:"]
}
}n8n 工作流末尾加一个 HTTP Request 节点,POST 到 OpenClaw:
POST http://你的服务器IP:18789/hooks/agent
Header: x-openclaw-token: 你的安全密钥
Body:
{
"message": "n8n 工作流 [广告数据拉取] 执行完毕。结果:ROAS 1.8,花费 ¥3200。请判断是否异常并决定下一步。",
"name": "n8n-广告监控",
"sessionKey": "hook:n8n-ads",
"deliver": true,
"channel": "feishu",
"to": "飞书群ID"
}在 AGENTS.md 里写入调度判断逻辑:
## n8n 工作流调度规则
当你收到 n8n webhook 回调时:
1. 解析工作流名称和执行结果
2. 对照以下阈值判断是否异常:
- 广告 ROAS 低于 [你的阈值]:异常,立刻通知
- 库存低于 [X] 天销量:异常,立刻通知
- 工作流执行失败:异常,立刻通知并附失败原因
3. 正常情况:不输出任何内容,静默处理
4. 异常情况:推送到飞书群,格式为「⚠️ [工作流名称] 异常:[具体问题] → 建议:[处理方案]」
5. 工作流依赖关系:[工作流B] 正常完成后,自动触发 [工作流C](通过 curl 调用 n8n 的 webhook URL)业务 SOP 沉淀成 Skills,才是真正的护城河
让老板回归「做重要决策」这件事
数据本身没有价值,数据驱动的决策才有价值。
连接亚马逊广告 API、独立站 GA4、飞书多维表,每小时拉数据判断异常。ROAS 低于阈值、退款率超标、库存不足 7 天销量——才推送。其他时候沉默。每天早 9 点一份当日简报,已经带结论和建议动作,不需要老板自己算。
除了业务数据,这个 Agent 还能接收团队成员的日报周报,自动提炼关键进展和卡点,老板打开飞书看到的不是一堆文字,而是一份结构化的「需要你关注的事」清单。
第一步,配置数据巡检的 Cron 任务。用 isolated session,正常时不产生输出:
openclaw cron add \
--name "data-patrol" \
--cron "0 * * * *" \
--session isolated \
--message "执行数据巡检。读取 AGENTS.md 中的异常阈值规则,调用对应 API 拉取最新数据,逐项判断。如果全部正常,只回复 HEARTBEAT_OK,不要输出其他任何内容。如果有异常,输出格式:⚠️ [指标名] 异常:当前值 [X],阈值 [Y] → 建议:[处理方案]。" \
--announce第二步,在 AGENTS.md 里定义异常阈值:
## 数据异常阈值(根据自身业务填写)
- 广告 ROAS 低于 [X]
- 单日广告花费超过 [X] 元且 ROAS 未达标
- 退款率超过 [X%]
- 某 SKU 库存低于 [X] 天销量
- 独立站跳出率突增 [X%] 以上
- 新品上线 [X] 天内零转化
## 数据源配置
- 亚马逊广告 API:通过 Skill [amazon-ads] 调用
- GA4:通过 Skill [ga4-report] 调用
- 飞书多维表(库存/销售数据):表格 URL [填入]
## 推送规则
- 正常不通知,异常立刻推送到飞书群 [群名]
- 紧急事项同时私信老板飞书多 Agent 协作:不要一上来就搞五个 Agent
第一,没有队形。 五个 Agent 各干各的,谁也不知道队友在做什么,该交接的不交接,该汇报的不汇报。
第二,活派出去收不回来。 OpenClaw 的 sessions_send 有个隐藏限制:等下游回复的超时只有 30 秒,超了就丢了,上游 Agent 以为对方没干活。
第三,配置项太多容易漏。 每个 Agent 要单独建 workspace、绑 IM 账号、开 A2A 权限、设 Session 可见性,少一项整条链路就是废的。
正确的做法是分阶段来。
阶段一:一个主 Agent + SubAgent 模式
不需要多个独立 Agent。用一个主 Agent,复杂任务通过 sessions_spawn 派给 SubAgent 在后台跑,跑完结果自动回传。这个模式配置最简单,90% 的场景够用。
阶段二:需要多人同时对话时,上多 Agent
当你的团队里多个人需要同时跟不同的 Agent 对话(比如运营找运营助手、老板找决策助手),这时候才需要真正的多 Agent 路由。
关键配置三件事:
- 工作区物理隔离 :每个 Agent 必须有独立的 workspace,用 openclaw agents add 命令创建,不要手动建目录。
- A2A 通信白名单 :在 openclaw.json 里显式开启 agentToAgent,
{
"tools": {
"agentToAgent": {
"enabled": true,
"allow": ["lead", "ops-assistant", "ads-assistant"]
}
}
}## 协作准则
### 委派任务后
- 收到 sessions_send 返回 { status: "accepted" } 后,如果不依赖结果,继续做下一件事
- 如果必须等结果,告知用户「已委派给 @[队友ID],等待结果」,然后结束当前轮次
- 队友完成后会通过 sessions_send 回传唤醒你
### 接到任务后
1. 立刻在群里用 message 工具通知用户已接手(消息开头 @上游AgentID)
2. 执行任务
3. 完成后先在群里汇报结果(同样 @上游AgentID)
4. 同时必须调用 sessions_send 将结果发回给委派者,唤醒对方继续工作- 双重汇报协议 :在每个 Agent 的 SOUL.md 里写入协作准则,解决超时问题:
并设置允许通信的 Agent 列表
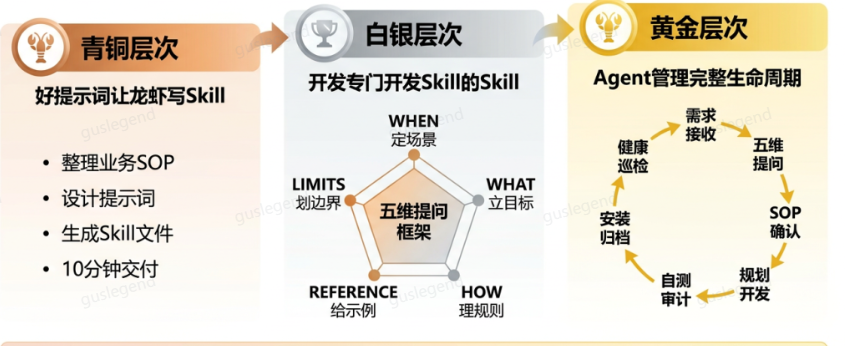
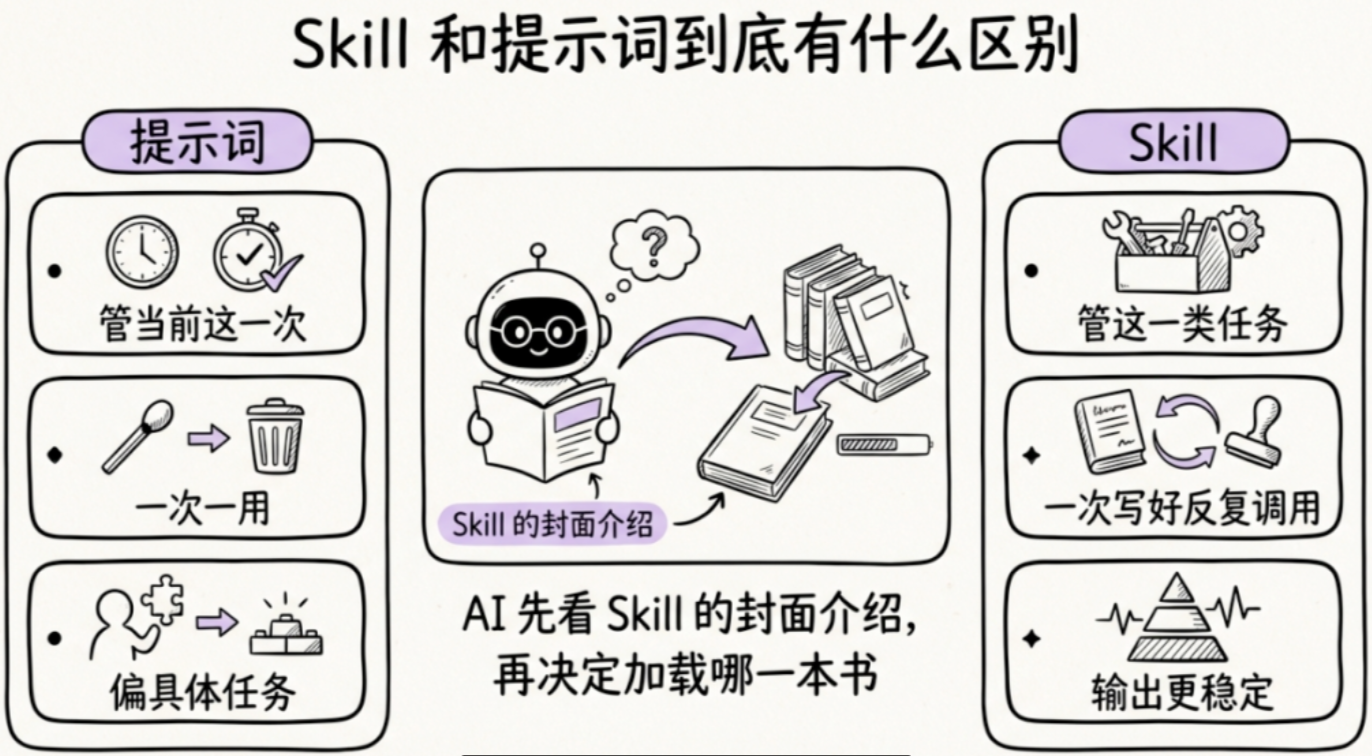
Skill编写教程
什么时候该写 Skill 呢?简单的判断标准是:一件事最近一周做了3次以上,做法基本固定,那它就值得变成 Skill 。比如搜集每日专业相关的资讯和资料、做竞品分析、按照公司要求的格式写周报和整理会议纪要、给客户写跟进邮件等等,只要流程基本固定,且输出格式可预期,就都是好的 Skill 候选。
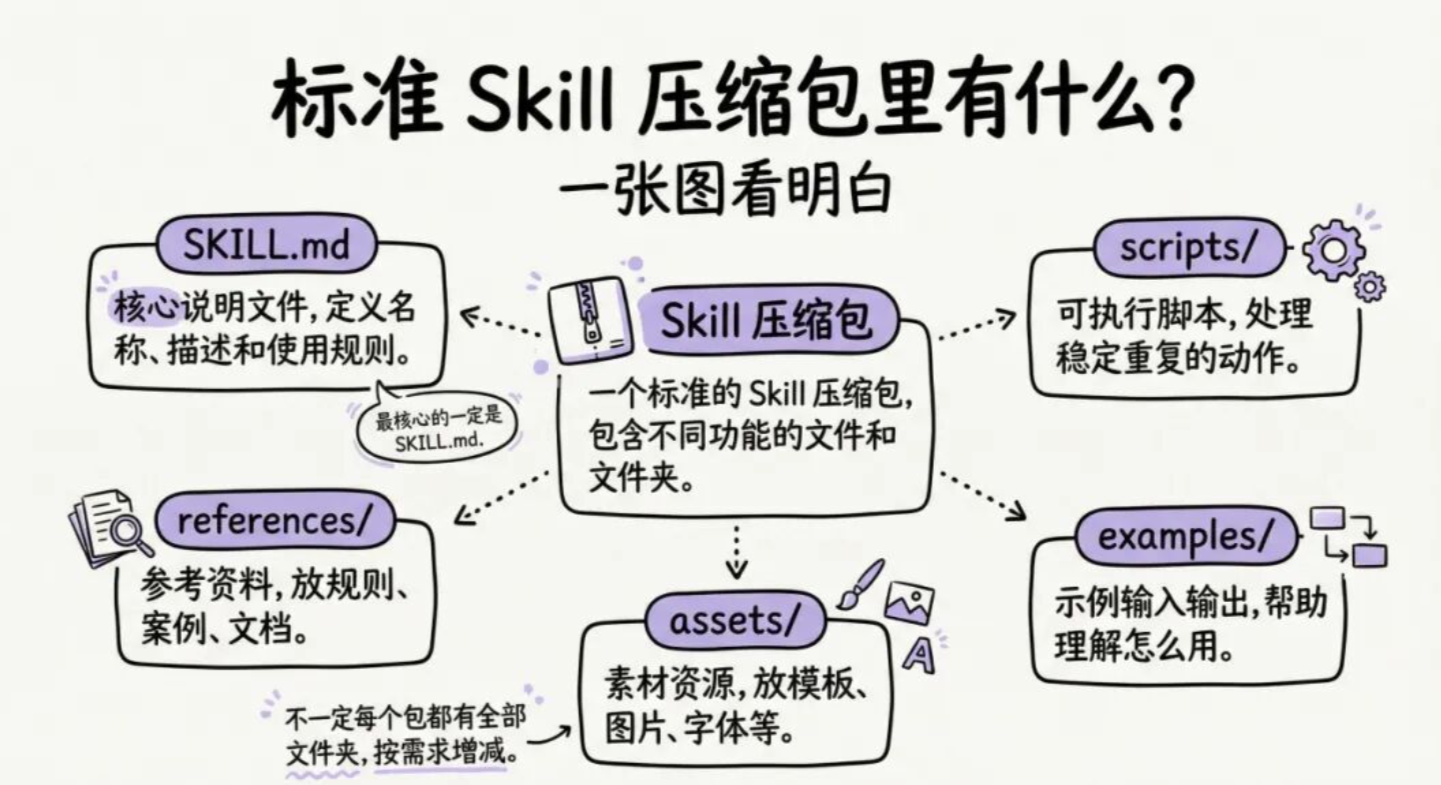
写好Skill的核心
SKILL.md 文件开头有一段元数据,其中首要的是description。
好的 description 要包含:功能描述 + 触发关键词。
# ❌ 太模糊,AI不知道什么时候该用
description: 帮忙处理文档
# ❌ 太宽泛,什么写作任务都会触发
description: 帮助用户写文章
# ✅ 具体功能 + 触发词
description: | 将故事文本转换为AI视频生成所需的分镜脚本。
当用户说“做分镜“、“分镜脚本“、“故事转分镜“时触发。小技巧:想想我们自己平时会怎么说话。“帮我做个分镜”、“把这个故事拆成分镜”、“生成分镜脚本”,把这些你可能会用的表达都写进 description 里,AI 才能准确识别,下次你一说它就触发。
多模块骨架
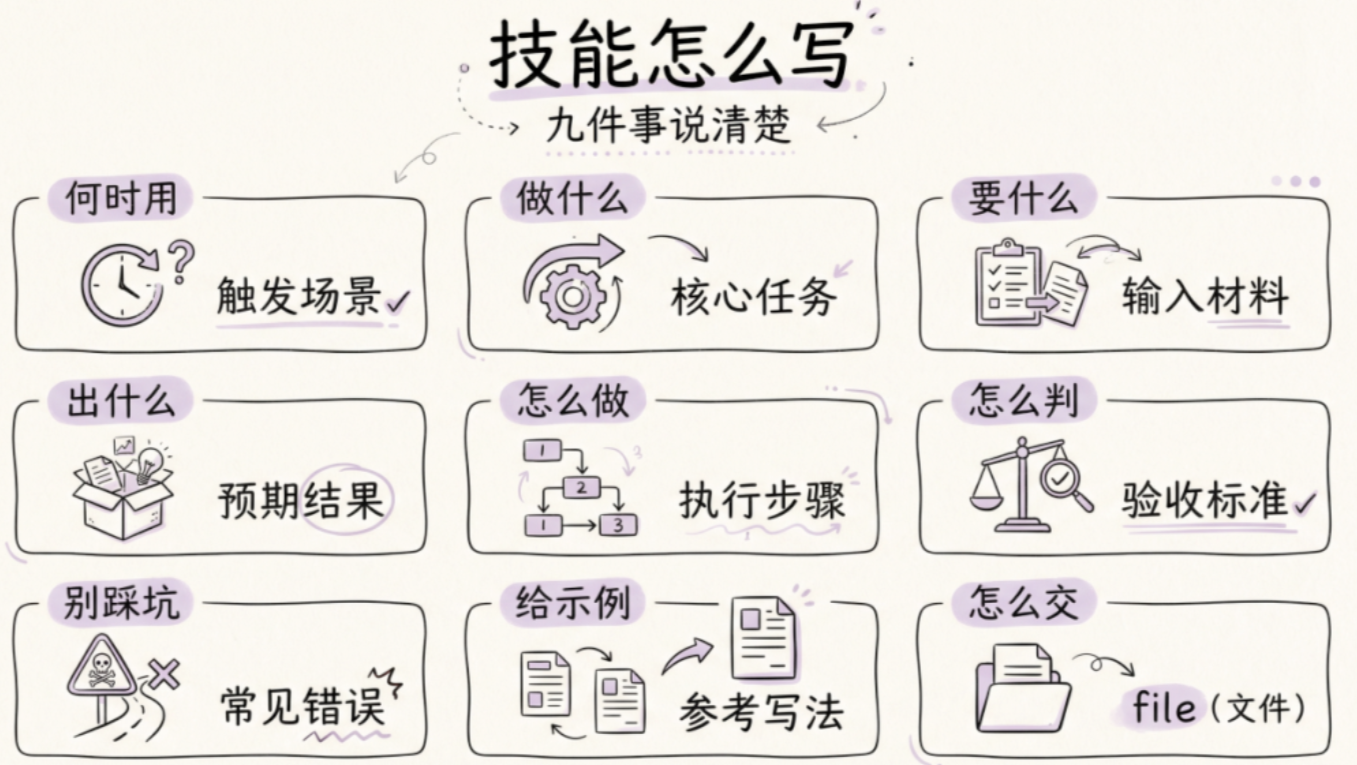
1. 目标是什么
2. 什么情况下触发
3. 什么情况下不要触发
4. 开始前先收集什么信息
5. 按什么顺序干活
6. 输出必须长什么样
7. 做到什么程度算完成
8. 搞不定的时候怎么处理
9. 什么时候去读参考文件
Skill.md正文写什么?
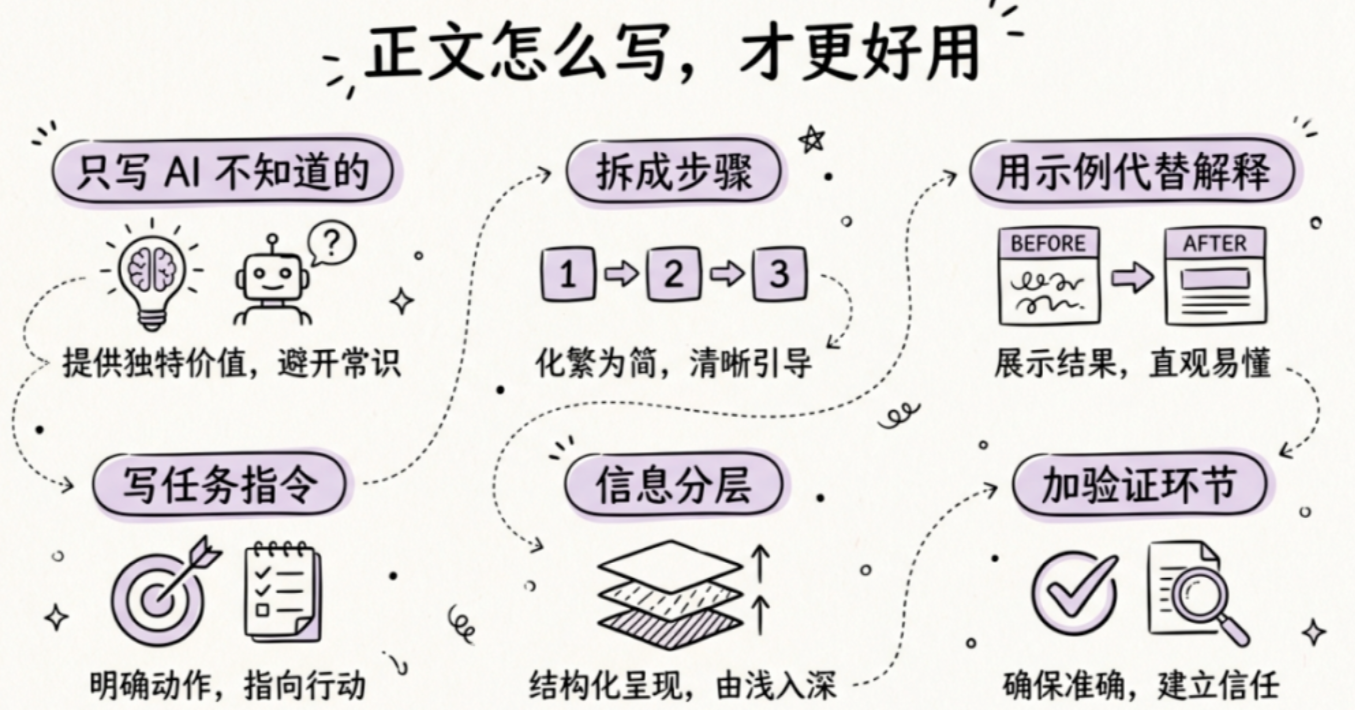
1. 只写 AI 不知道的东西。
告诉它你的私有规则、个人习惯、行业里的特殊流程等等,这些才值得写。比如“工作周从周三算起”“老板只看柱状图不看饼图”。每写一句想想,这个信息 AI 会知道吗?如果知道,可以删掉。
2. 把流程拆成步骤,带上决策分支。
不只是“第一步、第二步”,还要写清“如果遇到 XX 情况,怎么处理”。比如“如果某个分类没有内容,跳过,不要写'本周无更新'”。这比“你自己判断”靠谱得多。
3. 用示例代替解释。
一个正确示例 + 一个错误示例,胜过三段文字说明。复杂任务就给一个完整的“输入→输出”示例,放到 references/ 文件夹里按需引用。
4. 写任务指令,不要堆身份设定。
“你是一个资深 XX 专家,拥有20年经验”这种人设描述效果并不稳定。一定要告诉 AI 具体要做什么事情。
5. 信息分层,按需加载。
核心规则放主文件,参考资料、模板放单独文件,AI 需要时再去调用读取。主文件控制在 500 行以内,引用保持一层深度,别套娃。SKILL.md 直接引用参考文件就好,(比如“需要参考格式时,请读取 references/output-example.md”),注意参考文件本身不要再引用其他文件。
6. 复杂流程加验证环节。
AI 可能在某一步出错但要到后面才暴露。如果是比较复杂的任务,就可以在关键步骤后加检查点,验证通过才继续。可以在关键步骤后加一句“做完这步先检查 XX 是否正确,确认没问题再继续下一步”。
7. 先跑起来,再慢慢打磨修改。
Skill 很难做到一次就是完美的,可以先做一些尝试,哪里不对再优化。
操作
完成一个Skill后,可以对照这个清单过一遍👇
□ 触发词和排除条件都写进了 description
□ 有至少 1 个完整的输入→输出示例
□ SKILL.md 不超过 500 行(超出的参考资料、示例拆到配套文件里)
□ 完成标准每条都能验证
□ 实际测试过至少 3 次且都没有问题

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)